Recognition: no theorem link
Covering Human Action Space for Computer Use: Data Synthesis and Benchmark
Pith reviewed 2026-05-13 05:13 UTC · model grok-4.3
The pith
A renderer-based pipeline generates diverse scenes and action traces across five modalities, enabling a 4B model to outperform open-source agents with under 32B parameters on complex computer-use tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
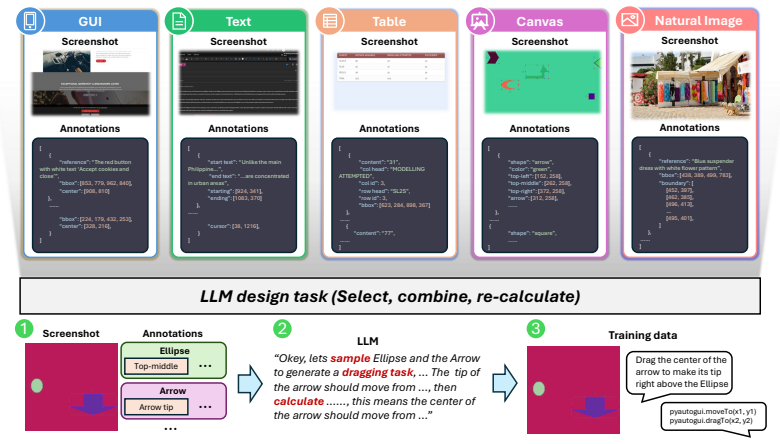
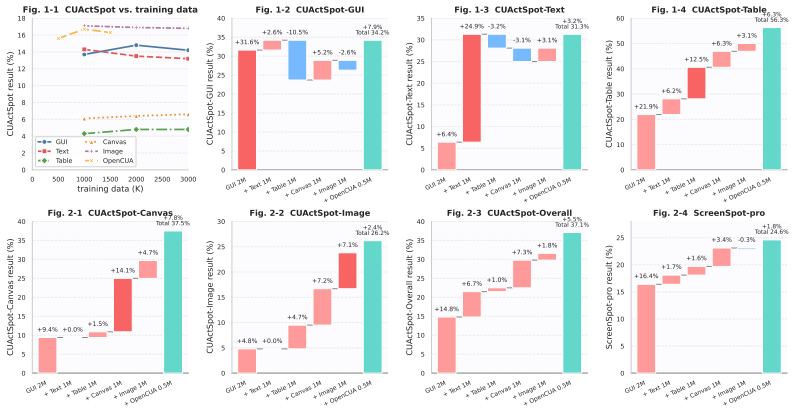
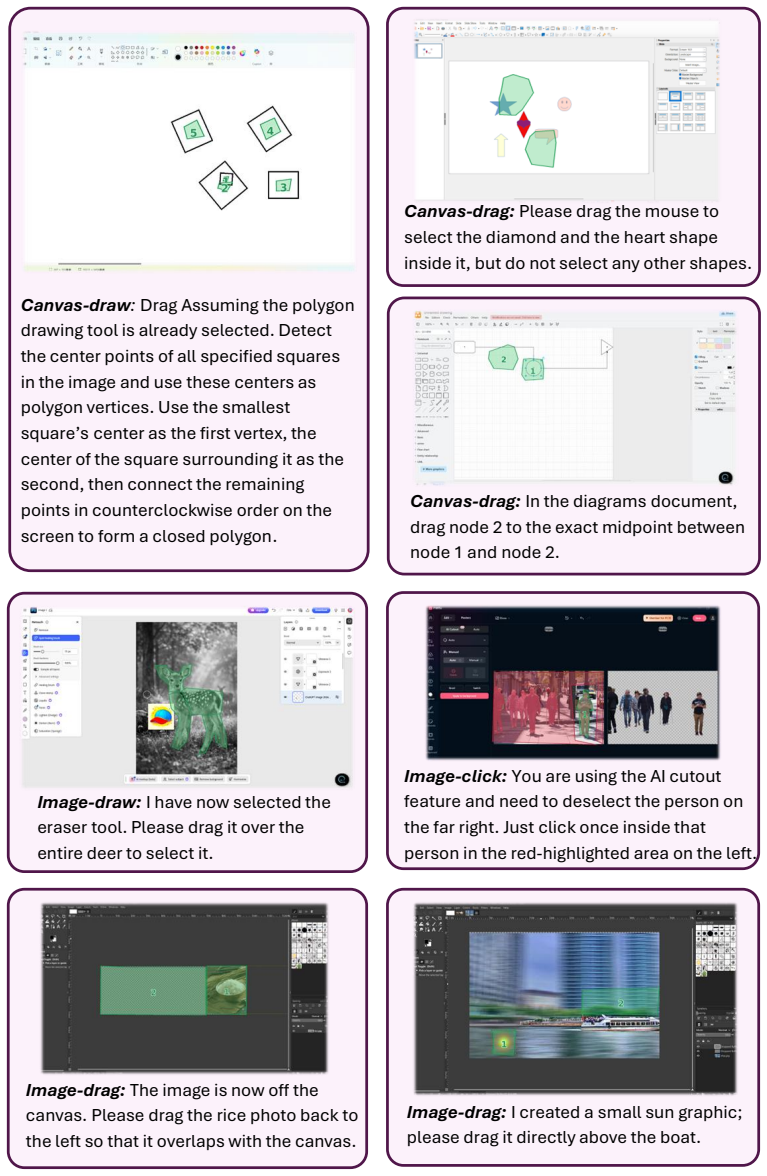
The authors hypothesize that reliability gaps in computer-use agents arise mainly from missing data on complex, low-frequency interactions. They address this by building the CUActSpot benchmark that spans five modalities and multiple action types, and by creating a renderer-based synthesis pipeline: scenes are generated automatically, screenshots and element coordinates are captured, and an LLM produces aligned instructions and action traces. After training on this corpus, their Phi-Ground-Any-4B model outperforms open-source models with fewer than 32B parameters.
What carries the argument
The renderer-based data-synthesis pipeline, which automatically generates modality-specific scenes, records screenshots with element coordinates, and pairs them with LLM-written instructions and action traces to cover complex interactions.
If this is right
- Models can be trained to handle diverse actions such as drag and draw in addition to clicks without manual data collection.
- Evaluation standards for computer-use agents will expand beyond click-centric GUI tests to include text, tables, canvases, and natural images.
- Smaller models can reach competitive performance on complex tasks once the interaction space is covered by synthetic data.
- Releasing the benchmark, data, code, and models will allow other groups to build on the same coverage of long-tail cases.
Where Pith is reading between the lines
- Similar renderer-plus-LLM pipelines could be adapted to generate training data for web navigation or mobile-app agents where real interaction logs are scarce.
- The result suggests that targeted data coverage may reduce the need for ever-larger model sizes when the task is bounded to on-screen actions.
- Deployed agents will likely still require some fine-tuning on actual user software to handle timing, visual noise, or software-specific widgets absent from the generated scenes.
- A useful next test would be to run the model on live desktop sessions and count how often it produces invalid actions on interactions outside the five synthetic modalities.
Load-bearing premise
The automatically generated scenes, screenshots, and LLM-written instructions and action traces sufficiently represent the real-world long-tail complex interactions responsible for current model failures.
What would settle it
Measuring whether the trained 4B model still shows high failure rates on a collection of real-user screen recordings of complex interactions that were never generated by the synthesis pipeline.
Figures











read the original abstract
Computer-use agents (CUAs) automate on-screen work, as illustrated by GPT-5.4 and Claude. Yet their reliability on complex, low-frequency interactions is still poor, limiting user trust. Our analysis of failure cases from advanced models suggests a long-tail pattern in GUI operations, where a relatively small fraction of complex and diverse interactions accounts for a disproportionate share of task failures. We hypothesize that this issue largely stems from the scarcity of data for complex interactions. To address this problem, we propose a new benchmark CUActSpot for evaluating models' capabilities on complex interactions across five modalities: GUI, text, table, canvas, and natural image, as well as a variety of actions (click, drag, draw, etc.), covering a broader range of interaction types than prior click-centric benchmarks that focus mainly on GUI widgets. We also design a renderer-based data-synthesis pipeline: scenes are automatically generated for each modality, screenshots and element coordinates are recorded, and an LLM produces matching instructions and action traces. After training on this corpus, our Phi-Ground-Any-4B outperforms open-source models with fewer than 32B parameters. We will release our benchmark, data, code, and models at https://github.com/microsoft/Phi-Ground.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies a long-tail pattern in failures of computer-use agents on complex, low-frequency GUI interactions, hypothesizing data scarcity as the cause. It introduces the CUActSpot benchmark for evaluating capabilities across five modalities (GUI, text, table, canvas, natural image) and diverse actions (click, drag, draw, etc.). A renderer-based synthesis pipeline is proposed: automatic scene generation per modality, recording of screenshots and element coordinates, followed by LLM-generated instructions and action traces. The central empirical claim is that a 4B-parameter Phi-Ground-Any-4B model trained on this corpus outperforms open-source models with fewer than 32B parameters. The authors commit to releasing the benchmark, data, code, and models.
Significance. If the synthetic data and benchmark are shown to capture real-world long-tail distributions, the work could provide a scalable solution to data scarcity for reliable computer-use agents, expanding evaluation beyond click-centric GUI benchmarks. The multi-modality and action coverage, combined with the open release of all artifacts, would strengthen reproducibility and enable further research in the field.
major comments (2)
- [Abstract] Abstract: The claim that Phi-Ground-Any-4B 'outperforms open-source models with fewer than 32B parameters' is presented without any quantitative metrics, baseline comparisons, error bars, ablation studies, or tables of results, leaving the magnitude and robustness of the central performance improvement unevaluated.
- [Abstract] Data synthesis pipeline and benchmark description: Both the training corpus and CUActSpot are generated by the same automatic pipeline (scene generation, screenshot/element recording, LLM-written instructions and traces), creating a closed synthetic distribution; this undermines the claim that the approach addresses real long-tail failures unless the manuscript includes validation against real user interaction logs, statistical distribution matching, or external real-world benchmarks.
minor comments (1)
- [Abstract] Abstract: The five modalities and action types are listed but lack concrete examples of complex interactions, which would help readers understand the benchmark's coverage relative to prior work.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, providing clarifications and indicating revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that Phi-Ground-Any-4B 'outperforms open-source models with fewer than 32B parameters' is presented without any quantitative metrics, baseline comparisons, error bars, ablation studies, or tables of results, leaving the magnitude and robustness of the central performance improvement unevaluated.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to immediately assess the scale of the reported gains. The full manuscript contains detailed quantitative results, including baseline comparisons, success rates, ablations, and error bars across multiple runs, presented in Section 4 and the associated tables. To address the concern, we have revised the abstract to incorporate key performance metrics (e.g., average success rate improvements) while retaining the high-level claim and explicitly referencing the detailed experimental sections for full context, robustness analysis, and ablations. revision: yes
-
Referee: [Abstract] Data synthesis pipeline and benchmark description: Both the training corpus and CUActSpot are generated by the same automatic pipeline (scene generation, screenshot/element recording, LLM-written instructions and traces), creating a closed synthetic distribution; this undermines the claim that the approach addresses real long-tail failures unless the manuscript includes validation against real user interaction logs, statistical distribution matching, or external real-world benchmarks.
Authors: We acknowledge the valid concern about potential distribution shift in a fully synthetic setup. The pipeline was explicitly motivated by our preliminary analysis of real-world failure cases from advanced CUAs (e.g., GPT-5.4 and Claude), which revealed the long-tail of complex, low-frequency interactions across modalities and action types. The renderer-based generation enables systematic coverage of these rare cases that are inherently scarce in organic logs. We have added a dedicated paragraph in Section 3.2 that reports diversity statistics of the generated corpus and provides qualitative alignment with observed real GUI failure patterns. Direct quantitative matching to proprietary large-scale user logs is outside the scope of the current work due to access constraints; however, the open release of the benchmark, data, and code will facilitate such external validations by the community. We maintain that the targeted synthesis addresses the identified data scarcity issue, as demonstrated by the performance improvements on the benchmark. revision: partial
Circularity Check
No circularity in empirical data synthesis and evaluation
full rationale
The paper presents an empirical workflow: a renderer-based pipeline generates synthetic scenes, screenshots, and LLM-produced instructions/action traces for training data; a separate benchmark CUActSpot is defined to cover multiple modalities and actions; Phi-Ground-Any-4B is trained on the corpus and its performance is compared to external open-source models under 32B parameters. No equations, first-principles derivations, or fitted parameters are claimed to produce the central outperformance result. The training corpus and benchmark are generated by the same methodological family but remain distinct artifacts, and the reported gains are measured against unrelated external models rather than reducing to the input distribution by construction. This is a standard empirical ML paper with no load-bearing self-citation chains or self-definitional steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku
Anthropic. Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku. Technical report, Anthropic, October 2024. URL https://www.anthropic.com/news/ 3-5-models-and-computer-use
work page 2024
-
[2]
OpenAI. Computer-Using Agent. Technical report, OpenAI, January 2025. URL https: //openai.com/index/computer-using-agent/
work page 2025
-
[3]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
work page 2024
-
[4]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Saaket Agashe, Kyle Wong, Vincent Tu, Jiachen Yang, Ang Li, and Xin Eric Wang. Agent s2: A compositional generalist-specialist framework for computer use agents.arXiv preprint arXiv:2504.00906, 2025
-
[6]
OpenAI. Introducing GPT-5.4. Technical report, OpenAI, March 2026. URL https:// openai.com/index/introducing-gpt-5-4/
work page 2026
-
[7]
An illusion of progress? assessing the current state of web agents
Tianci Xue, Weijian Qi, Tianneng Shi, Chan Hee Song, Boyu Gou, Dawn Song, Huan Sun, and Yu Su. An illusion of progress? assessing the current state of web agents.arXiv preprint arXiv:2504.01382, 2025
-
[8]
Magebench: Bridging large multimodal models to agents
Miaosen Zhang, Qi Dai, Yifan Yang, Jianmin Bao, Dongdong Chen, Kai Qiu, Chong Luo, Xin Geng, and Baining Guo. Magebench: Bridging large multimodal models to agents. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1415–1427, 2026
work page 2026
-
[9]
Xiao Liu, Tianjie Zhang, Yu Gu, Iat Long Iong, Yifan Xu, Xixuan Song, Shudan Zhang, Hanyu Lai, Xinyi Liu, Hanlin Zhao, et al. Visualagentbench: Towards large multimodal models as visual foundation agents.arXiv preprint arXiv:2408.06327, 2024
-
[10]
arXiv preprint arXiv:2410.05243 , year=
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. Navigating the digital world as humans do: Universal visual grounding for gui agents.arXiv preprint arXiv:2410.05243, 2024
-
[11]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: A foundation action model for generalist gui agents.arXiv preprint arXiv:2410.23218, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
Phi-ground tech report: Advancing perception in gui grounding.arXiv preprint arXiv:2507.23779, 2025
Miaosen Zhang, Ziqiang Xu, Jialiang Zhu, Qi Dai, Kai Qiu, Yifan Yang, Chong Luo, Tianyi Chen, Justin Wagle, Tim Franklin, et al. Phi-ground tech report: Advancing perception in gui grounding.arXiv preprint arXiv:2507.23779, 2025. 10
-
[13]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Seeclick: Harnessing gui grounding for advanced visual gui agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing gui grounding for advanced visual gui agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9313–9332, 2024
work page 2024
-
[15]
Screenspot-pro: Gui grounding for professional high-resolution computer use
Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: Gui grounding for professional high-resolution computer use. InProceedings of the 33rd ACM International Conference on Multimedia, pages 8778– 8786, 2025
work page 2025
-
[16]
Shravan Nayak, Xiangru Jian, Kevin Qinghong Lin, Juan A Rodriguez, Montek Kalsi, Rabiul Awal, Nicolas Chapados, M Tamer Özsu, Aishwarya Agrawal, David Vazquez, et al. Ui- vision: A desktop-centric gui benchmark for visual perception and interaction.arXiv preprint arXiv:2503.15661, 2025
-
[17]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
work page 2024
-
[18]
Yuhang Liu, Pengxiang Li, Congkai Xie, Xavier Hu, Xiaotian Han, Shengyu Zhang, Hongxia Yang, and Fei Wu. Infigui-r1: Advancing multimodal gui agents from reactive actors to deliberative reasoners.arXiv preprint arXiv:2504.14239, 2025
-
[19]
Zhangxuan Gu, Zhengwen Zeng, Zhenyu Xu, Xingran Zhou, Shuheng Shen, Yunfei Liu, Beitong Zhou, Changhua Meng, Tianyu Xia, Weizhi Chen, et al. Ui-venus technical report: Building high-performance ui agents with rft.arXiv preprint arXiv:2508.10833, 2025
-
[20]
GUI-G2: Gaussian reward modeling for gui grounding.arXiv preprint arXiv:2507.15846, 2025
Fei Tang, Zhangxuan Gu, Zhengxi Lu, Xuyang Liu, Shuheng Shen, Changhua Meng, Wen Wang, Wenqi Zhang, Yongliang Shen, Weiming Lu, et al. GUI-G2: Gaussian reward modeling for gui grounding.arXiv preprint arXiv:2507.15846, 2025
-
[21]
Infigui-g1: Advancing gui grounding with adaptive exploration policy optimization
Yuhang Liu, Zeyu Liu, Shuanghe Zhu, Pengxiang Li, Congkai Xie, Jiasheng Wang, Xueyu Hu, Xiaotian Han, Jianbo Yuan, Xinyao Wang, et al. Infigui-g1: Advancing gui grounding with adaptive exploration policy optimization. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32267–32275, 2026
work page 2026
-
[22]
Hanzhang Zhou, Xu Zhang, Panrong Tong, Jianan Zhang, Liangyu Chen, Quyu Kong, Chenglin Cai, Chen Liu, Yue Wang, Jingren Zhou, et al. Mai-ui technical report: Real-world centric foundation gui agents.arXiv preprint arXiv:2512.22047, 2025
-
[23]
Haiyang Xu, Xi Zhang, Haowei Liu, Junyang Wang, Zhaozai Zhu, Shengjie Zhou, Xuhao Hu, Feiyu Gao, Junjie Cao, Zihua Wang, et al. Mobile-agent-v3. 5: Multi-platform fundamental gui agents.arXiv preprint arXiv:2602.16855, 2026
-
[24]
Tianbao Xie, Jiaqi Deng, Xiaochuan Li, Junlin Yang, Haoyuan Wu, Jixuan Chen, Wenjing Hu, Xinyuan Wang, Yuhui Xu, Zekun Wang, et al. Scaling computer-use grounding via user interface decomposition and synthesis.arXiv preprint arXiv:2505.13227, 2025
-
[25]
Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, et al. Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
-
[26]
Taofeng Xue, Chong Peng, Mianqiu Huang, Linsen Guo, Tiancheng Han, Haozhe Wang, Jianing Wang, Xiaocheng Zhang, Xin Yang, Dengchang Zhao, et al. Evocua: Evolving computer use agents via learning from scalable synthetic experience.arXiv preprint arXiv:2601.15876, 2026
-
[27]
Gpt-4v (ision) is a generalist web agent, if grounded.arXiv preprint arXiv:2401.01614, 2024
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. Gpt-4v (ision) is a generalist web agent, if grounded.arXiv preprint arXiv:2401.01614, 2024. 11
-
[28]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14281–14290, 2024
work page 2024
-
[30]
UGround: Towards Unified Visual Grounding with Unrolled Transformers
Rui Qian, Xin Yin, Chuanhang Deng, Zhiyuan Peng, Jian Xiong, Wei Zhai, and Dejing Dou. Uground: Towards unified visual grounding with unrolled transformers.arXiv preprint arXiv:2510.03853, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: Unified pure vision agents for autonomous gui interaction. arXiv preprint arXiv:2412.04454, 2024
-
[32]
Showui: One vision-language-action model for generalist gui agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Zechen Bai, Weixian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for generalist gui agent. InNeurIPS 2024 Workshop on Open-World Agents, 2024
work page 2024
-
[33]
Aria-ui: Visual grounding for gui instructions
Yuhao Yang, Yue Wang, Dongxu Li, Ziyang Luo, Bei Chen, Chao Huang, and Junnan Li. Aria-ui: Visual grounding for gui instructions. InFindings of the Association for Computational Linguistics: ACL 2025, pages 22418–22433, 2025
work page 2025
-
[34]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxi- ang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544, 2025
work page internal anchor Pith review arXiv 2025
-
[35]
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, et al. Windows agent arena: Evaluating multi-modal os agents at scale.arXiv preprint arXiv:2409.08264, 2024
-
[36]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Mary- beth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Androidworld: A dynamic benchmarking environment for autonomous agents.arXiv preprint arXiv:2405.14573, 2024
work page internal anchor Pith review arXiv 2024
-
[37]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
work page 2023
-
[39]
Introducing OpenAI o3 and o4-mini
OpenAI. Introducing OpenAI o3 and o4-mini. Technical report, OpenAI, April 2025. URL https://openai.com/index/introducing-o3-and-o4-mini/
work page 2025
-
[40]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
work page 2023
-
[41]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Satoshi Suzuki et al. Topological structural analysis of digitized binary images by border following.Computer vision, graphics, and image processing, 30(1):32–46, 1985
work page 1985
-
[43]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Yan Yang, Dongxu Li, Yutong Dai, Yuhao Yang, Ziyang Luo, Zirui Zhao, Zhiyuan Hu, Junzhe Huang, Amrita Saha, Zeyuan Chen, et al. Gta1: Gui test-time scaling agent.arXiv preprint arXiv:2507.05791, 2025. 13 A CUActSpot Details A.1 Detailed Tasks Breakdown The following two tables present the specific task categories included in the CUActSpot benchmark. In co...
-
[45]
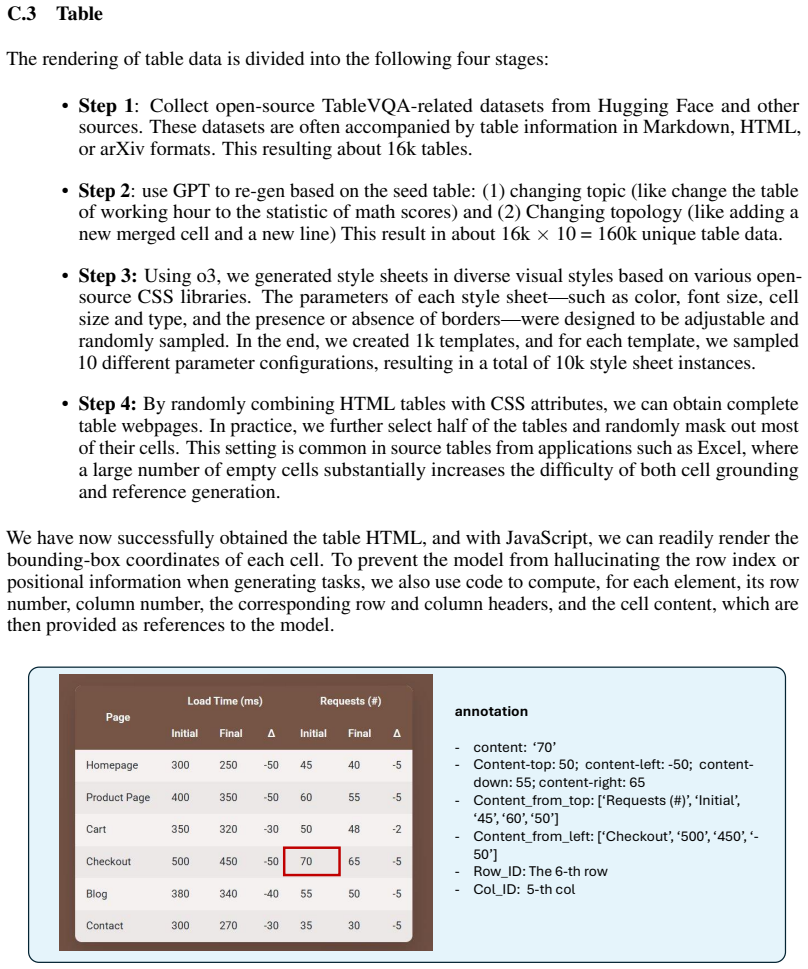
Scroll page dedup. …… GPT-4O Labeling - 10.5M pairs - Element Selection - 10.5M Elements - Center point distribution on Image Figure 8: CommonCrawl data processing pipeline. C Data Synthesis Details C.1 GUI To acquire larger-scale data for better scaling up of training, we also obtained web pages from CommonCrawl and rendered screenshots to generate train...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.