Recognition: 2 theorem links
· Lean Theorem3D Primitives are a Spatial Language for VLMs
Pith reviewed 2026-05-14 21:29 UTC · model grok-4.3
The pith
Vision-language models gain spatial understanding when they reason through 3D geometric primitives written as executable code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that 3D geometric primitives expressed in executable code serve as a transferable intermediate representation for spatial understanding in VLMs. This is shown by large variation in object-detection accuracy across scene-code languages, consistent gains from routing spatial reasoning through code generation, and further improvements obtained by distilling the model's own primitive reconstructions back into its weights.
What carries the argument
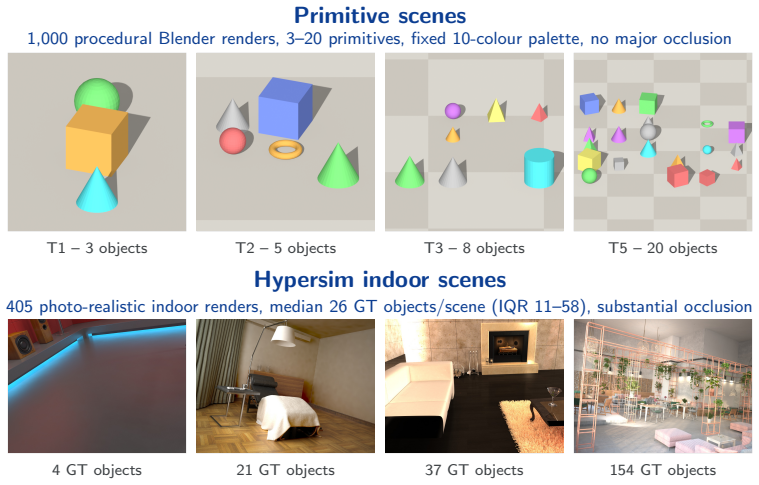
3D geometric primitives (cubes, spheres, cylinders) expressed in executable code, used as an intermediate spatial representation that the model generates and consumes.
Load-bearing premise
That the measured gains come from the specific choice of primitive shapes rather than from any code-generation step or fine-tuning process in general.
What would settle it
A controlled test in which a model prompted to output primitive code shows no spatial accuracy lift, or in which fine-tuning on non-primitive code produces equal or larger gains on the same benchmarks.
Figures







read the original abstract
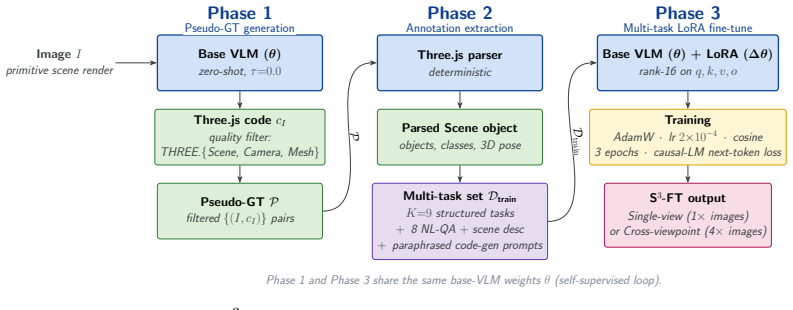
Vision-language models (VLMs) exhibit a striking paradox: they can generate executable code that reconstructs a 3D scene from geometric primitives with correct object counts, classes, and approximate positions, yet the same models fail at simpler spatial questions on the same image. We show that 3D geometric primitives (cubes, spheres, cylinders, expressed in executable code) serve as a powerful intermediate representation for spatial understanding, and exploit this through three contributions. First, we introduce \textbf{\textsc{SpatialBabel}}, a benchmark evaluating fourteen VLMs on primitive-based 3D scene reconstruction across six \emph{scene-code languages} (programming languages and declarative formats for 3D primitive scenes), revealing that a single model's object-detection F1 can vary by up to $5.7\times$ across languages. Second, we propose \textbf{Code-CoT} (Code Chain-of-Thought), a training-free inference strategy that routes spatial reasoning through primitive-based code generation. Code-CoT lifts the SpatialBabel-QA-Score by up to $+6.4$\% on primitive scenes and real-photo CV-Bench-3D accuracy by $+5.0$\% for VLMs with strong coding capabilities. Third, we propose \textbf{S$^{3}$-FT} (Self-Supervised Spatial Fine-Tuning), which self-supervisedly distills primitive spatial knowledge into general visual reasoning by parsing the model's own Three.js primitive-reconstructions into structured annotations and fine-tuning on the result, with \emph{no human labels and no teacher model}. Training on primitive images alone, S$^3$-FT improves Qwen3-VL-8B by $+4.6$ to $+8.6$\% on SpatialBabel-Primitive-QA, $+9.7$\% on CV-Bench-2D, and $+17$\% on HallusionBench; the recipe transfers across model families. These results establish geometric primitives in code as both a diagnostic and a transferable spatial vocabulary for VLMs. We will release all artifacts upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that 3D geometric primitives (cubes, spheres, cylinders) expressed in executable code function as a powerful intermediate representation for spatial understanding in VLMs. It introduces the SpatialBabel benchmark to evaluate 14 VLMs on primitive-based 3D scene reconstruction across six scene-code languages, proposes Code-CoT (a training-free inference method routing spatial reasoning through primitive code generation), and S³-FT (self-supervised fine-tuning that distills from the model's own Three.js primitive reconstructions with no human labels), reporting consistent gains such as +6.4% on SpatialBabel-QA, +5.0% on CV-Bench-3D for Code-CoT, and up to +17% on HallusionBench for S³-FT.
Significance. If the attribution to the specific primitive representation holds, the work provides a practical, label-free method to improve VLMs' spatial reasoning via an executable geometric vocabulary. The self-supervised distillation in S³-FT and the cross-model transfer are notable strengths, as is the demonstration that VLMs can produce accurate primitive reconstructions yet fail on direct spatial queries. The benchmark's language-sensitivity result offers a useful diagnostic tool for VLM coding capabilities.
major comments (3)
- [§4] §4 (Code-CoT): The lifts (+6.4% SpatialBabel-QA, +5.0% CV-Bench-3D) are attributed to routing through 3D primitive code, yet the manuscript provides no ablation comparing primitive code to other executable formats (e.g., direct Python coordinate lists or non-primitive scene graphs). This control is required to isolate whether the primitive structure itself, rather than generic code generation, produces the gains.
- [§5] §5 (S³-FT): The reported improvements (+4.6–8.6% on SpatialBabel-Primitive-QA, +9.7% CV-Bench-2D, +17% HallusionBench) rely on distilling from the model's own primitive reconstructions, but without a control fine-tuning on alternative structured outputs or generic self-supervision, the specific contribution of the 3D primitive vocabulary versus any structured self-supervision remains unseparated.
- [§3] §3 (SpatialBabel benchmark): While F1 varies up to 5.7× across languages, the manuscript does not report error bars, statistical significance tests, or full details on data splits and exclusion criteria for the held-out benchmarks; these are needed to confirm that the cross-language and cross-method claims are robust.
minor comments (2)
- The abstract states that artifacts will be released upon publication; the camera-ready version should include a concrete link or repository reference.
- [§5] Notation for the six scene-code languages and the exact Three.js parsing procedure in S³-FT could be clarified with a small example table or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: §4 (Code-CoT): The lifts (+6.4% SpatialBabel-QA, +5.0% CV-Bench-3D) are attributed to routing through 3D primitive code, yet the manuscript provides no ablation comparing primitive code to other executable formats (e.g., direct Python coordinate lists or non-primitive scene graphs). This control is required to isolate whether the primitive structure itself, rather than generic code generation, produces the gains.
Authors: We agree that direct ablations against alternative executable formats are needed to isolate the role of the primitive structure. In the revised manuscript we will add experiments using direct Python coordinate lists and non-primitive scene graphs as controls. These will be reported alongside the existing language-sensitivity results to clarify whether gains arise specifically from the 3D geometric primitive vocabulary. revision: yes
-
Referee: §5 (S³-FT): The reported improvements (+4.6–8.6% on SpatialBabel-Primitive-QA, +9.7% CV-Bench-2D, +17% HallusionBench) rely on distilling from the model's own primitive reconstructions, but without a control fine-tuning on alternative structured outputs or generic self-supervision, the specific contribution of the 3D primitive vocabulary versus any structured self-supervision remains unseparated.
Authors: We acknowledge that controls for alternative structured outputs would better isolate the primitive vocabulary's contribution. We will add such experiments in revision, including fine-tuning on generic self-supervision signals. The label-free nature of S³-FT and its cross-model transfer remain core strengths, but the requested controls will be included to strengthen attribution. revision: yes
-
Referee: §3 (SpatialBabel benchmark): While F1 varies up to 5.7× across languages, the manuscript does not report error bars, statistical significance tests, or full details on data splits and exclusion criteria for the held-out benchmarks; these are needed to confirm that the cross-language and cross-method claims are robust.
Authors: We will add error bars and statistical significance tests for the F1 scores and other metrics in the revised manuscript. Full details on data splits, exclusion criteria, and benchmark construction will be provided in the main text or appendix. All artifacts will be released to support reproducibility of the robustness claims. revision: yes
Circularity Check
No circularity: claims rest on independent benchmarks and external evaluations
full rationale
The paper's derivation introduces SpatialBabel as a new benchmark, Code-CoT as a prompting route through code generation, and S³-FT as self-supervised fine-tuning on the model's own Three.js outputs. All reported gains (+6.4% SpatialBabel-QA, +5.0% CV-Bench-3D, +4.6–17% on HallusionBench) are measured on held-out, externally defined benchmarks that are not constructed from the training data or fitted parameters. No equations, self-definitions, or load-bearing self-citations appear; the central claim that primitives function as an intermediate representation is supported by empirical lifts rather than by construction from inputs. The self-supervised loop in S³-FT creates training labels from model outputs but does not make the evaluation results tautological, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs possess sufficient coding capability to produce executable 3D primitive scenes from images
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3 from circle linking) echoes3D geometric primitives (cubes, spheres, cylinders, expressed in executable code) serve as a powerful intermediate representation for spatial understanding
Reference graph
Works this paper leans on
-
[1]
The spatial blindspot of vision-language models.arXiv preprint arXiv:2601.09954,
Nahid Alam, Leema Krishna Murali, Siddhant Bharadwaj, Patrick Liu, Timothy Chung, Drishti Sharma, Kranthi Kiran, Wesley Tam, Bala Krishna S Vegesna, et al. The spatial blindspot of vision-language models.arXiv preprint arXiv:2601.09954,
-
[2]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Shiqi Chen, Tongyao Zhu, Ruochen Zhou, Jinghan Zhang, Siyang Gao, Juan Carlos Niebles, Mor Geva, Junxian He, Jiajun Wu, and Manling Li. Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas.arXiv preprint arXiv:2503.01773,
-
[5]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Raphi Kang, Hongqiao Chen, Georgia Gkioxari, and Pietro Perona. Linear mechanisms for spa- tiotemporal reasoning in vision language models.arXiv preprint arXiv:2601.12626,
-
[7]
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatialladder: Progressive training for spatial reasoning in vision-language models.arXiv preprint arXiv:2510.08531,
-
[8]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
10 Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Jianing Qi, Jiawei Liu, Hao Tang, and Zhigang Zhu. Beyond semantics: Rediscovering spatial awareness in vision-language models.arXiv preprint arXiv:2503.17349,
-
[10]
Design2code: Benchmarking multimodal code generation for automated front-end engineering
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2code: Benchmarking multimodal code generation for automated front-end engineering. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3956–3974,
work page 2025
-
[11]
SpatialBench: Benchmarking Multimodal Large Language Models for Spatial Cognition
Peiran Xu, Sudong Wang, Yao Zhu, Jianing Li, Gege Qi, and Yunjian Zhang. Spatialbench: Bench- marking multimodal large language models for spatial cognition.arXiv preprint arXiv:2511.21471,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
11 A Models and prompting setup We evaluatefourteen VLMs: eight proprietary APIs (Anthropic Claude Opus 4.7 / Sonnet 4.6, Ope- nAI GPT-5 / GPT-4o, Google Gemini-2.5-Pro/Flash and Gemini-3-Pro/Flash (preview) [DeepMind, 2025]) and six open-weights bases: Qwen3-VL-8B-Instruct (the S 3-FT headline base), Qwen2.5- VL-7B-Instruct (second S3-FT base) [Bai et al...
work page 2025
-
[14]
Table 6: SpatialBabel-Hypersim-QA-Score (%) under four inference modes. best_cc /worst_cc use each model’s primitive-best / primitive-worst scene-code language from Table 1.∆best-direct = best_cc−direct(pp). Bold = row max. Model direct nl_cot best_cc worst_cc∆ best-direct Proprietary APIs Claude Opus 4.730.628.7 25.5 26.8(−5.1) Claude Sonnet 4.6 21.7 29....
work page 2024
-
[15]
single-view S3-FT lifts SpatialBabel-QA by ∼+7% averaged across modes on Qwen3-VL-8B
All three runs converge to similar val losses (0.215to0.243). Table 12: Single-view S3-FT on Qwen3-VL-8B across multiple independent random seeds.direct, nl_cot,best_code_cot (threejs)are 3-seed runs (0, 42, 1337);worst_code_cot (canonical_json)is a 2-seed run (the seed-0 checkpoint was trained with an older configuration not directly comparable on the lo...
work page 2023
-
[16]
Pass rates: Qwen3-VL-8B 82%, Qwen2.5-VL-7B 84%
Epochs 3 for v1 (deprecated) and single-view S 3-FT; 2 for cross-viewpoint (larger data) Sequence length 2048 tokens max Mixed precision bfloat16 Checkpoint selection best validation loss over epochs; final model saved additionally L.2 Phase-1 quality filters Generated code is accepted only if it contains all three tokens { THREE.Scene, THREE.PerspectiveC...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.