Recognition: 2 theorem links
· Lean TheoremDriving Intents Amplify Planning-Oriented Reinforcement Learning
Pith reviewed 2026-05-15 04:55 UTC · model grok-4.3
The pith
Intent-conditioned sampling and multi-intent preference optimization expand driving policy distributions to surpass human demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
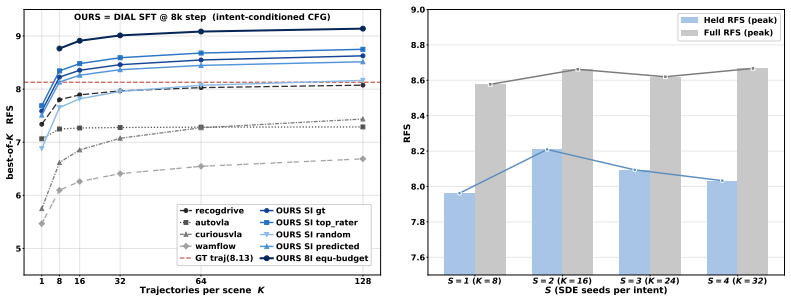
DIAL conditions the flow-matching action head on a discrete intent label with classifier-free guidance to expand the sampling distribution along distinct maneuver modes and break single-demonstration mode collapse. In the second stage, multi-intent GRPO spans all intent classes within every preference group and prevents fine-tuning from re-collapsing around the currently preferred mode. Evaluated on WOD-E2E with eight rule-derived intents, intent-CFG sampling raises best-of-128 RFS to 9.14, surpassing both the prior best of 8.5 and the human demonstration of 8.13, while multi-intent GRPO improves held-out RFS from 7.681 to 8.211.
What carries the argument
DIAL two-stage framework that first uses intent-CFG sampling on a flow-matching head to enlarge coverage over discrete maneuver modes and then applies multi-intent GRPO to maintain that coverage during preference updates.
If this is right
- Competitive vision-to-action and vision-language-action SFT baselines remain below the human demonstration even at best-of-128.
- Intent-CFG sampling alone lifts the performance ceiling to RFS 9.14 at best-of-128.
- Multi-intent GRPO raises held-out RFS from 7.681 to 8.211 while every single-intent baseline peaks lower and degrades by the end of training.
- The bottleneck in preference RL for continuous-action policies is expanding and preserving the sampling distribution rather than the update mechanism alone.
Where Pith is reading between the lines
- The same intent-amplification pattern could be tested in other continuous-control settings where only one demonstration trajectory exists per scene.
- Preference optimization may benefit more from explicit distribution-expansion steps than from further refinement of the update rule.
- If the fixed eight intents miss important modes, replacing them with learned discrete clusters might further increase the reachable performance ceiling.
Load-bearing premise
The eight rule-derived intents are assumed to span the semantically distinct maneuver modes that matter for preference alignment.
What would settle it
If removing the intent-conditioning stage from DIAL causes best-of-128 RFS to fall back below the human demonstration of 8.13 on the same evaluation set, the claim that intent amplification is required to exceed the demonstrated ceiling would be falsified.
Figures



read the original abstract
Continuous-action policies trained on a single demonstrated trajectory per scene suffer from mode collapse: samples cluster around the demonstrated maneuver and the policy cannot represent semantically distinct alternatives. Under preference-based evaluation, this caps best-of-N performance -- even oracle selection cannot recover what the sampling distribution does not contain. We introduce DIAL, a two-stage Driving-Intent-Amplified reinforcement Learning framework for preference-aligned continuous-action driving policies. In the first stage, DIAL conditions the flow-matching action head on a discrete intent label with classifier-free guidance (CFG), which expands the sampling distribution along distinct maneuver modes and breaks single-demonstration mode collapse. In the second stage, DIAL carries this expanded distribution into preference RL through multi-intent GRPO, which spans all intent classes within every preference group and prevents fine-tuning from re-collapsing around the currently preferred mode. Instantiated for end-to-end driving with eight rule-derived intents and evaluated on WOD-E2E: competitive Vision-to-Action (VA) and Vision-Language-Action (VLA) Supervised Finetuning (SFT) baselines plateau below the human-driven demonstration at best-of-128, with the strongest prior (RAP) capping at Rater Feedback Score (RFS) 8.5 even with best-of-64; intent-CFG sampling lifts this ceiling to RFS 9.14 at best-of-128, surpassing both the prior best (RAP 8.5) and the human-driven demonstration (8.13) for the first time; and multi-intent GRPO improves held-out RFS from 7.681 to 8.211, while every single-intent baseline peaks lower and degrades by training end. These results suggest that the bottleneck of preference RL on continuous-action policies trained from demonstrations is not only how to update the policy, but to expand and preserve the sampling distribution being optimized.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DIAL, a two-stage Driving-Intent-Amplified reinforcement Learning framework. Stage 1 conditions a flow-matching action head on discrete intent labels via classifier-free guidance (CFG) to expand the sampling distribution and break single-demonstration mode collapse. Stage 2 applies multi-intent GRPO during preference RL to preserve coverage across intent classes. On WOD-E2E, intent-CFG sampling reaches RFS 9.14 at best-of-128 (surpassing RAP at 8.5 and human demonstrations at 8.13), while multi-intent GRPO raises held-out RFS from 7.681 to 8.211.
Significance. If the empirical gains prove robust, the work identifies distribution expansion as a key bottleneck in preference RL for continuous-action driving policies and supplies a concrete mechanism (intent-CFG + multi-intent GRPO) that demonstrably exceeds both prior methods and human performance on RFS. The approach is directly applicable to end-to-end vision-to-action and vision-language-action models.
major comments (2)
- [Abstract and experimental results] The central performance claims rest on best-of-128 and held-out RFS numbers (9.14 and 8.211) without reported error bars, multiple random seeds, or ablation tables on the number and coverage of the eight rule-derived intents; this makes it impossible to determine whether the reported lift is statistically reliable or sensitive to intent definition.
- [§3.1 (intent definition) and §4 (evaluation)] The weakest assumption—that the eight rule-derived intents span all semantically distinct maneuver modes relevant for preference alignment—is load-bearing for the claim that intent-CFG expands the distribution sufficiently; no quantitative validation (e.g., mode coverage metrics or failure-case analysis) is supplied to test this premise.
minor comments (2)
- [§3] Notation for the flow-matching head and GRPO objective should be introduced with explicit equations rather than prose descriptions to allow direct comparison with prior flow-matching and GRPO formulations.
- [§4] The paper should clarify whether the reported RFS values are computed on the same held-out scenes for all methods and whether best-of-N selection uses the same preference model across baselines.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on statistical robustness and the coverage assumptions underlying our intent definitions. We address both major comments below and will revise the manuscript to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract and experimental results] The central performance claims rest on best-of-128 and held-out RFS numbers (9.14 and 8.211) without reported error bars, multiple random seeds, or ablation tables on the number and coverage of the eight rule-derived intents; this makes it impossible to determine whether the reported lift is statistically reliable or sensitive to intent definition.
Authors: We agree that error bars, multiple seeds, and intent ablations are necessary to establish reliability. In the revised manuscript we will report all key metrics (including best-of-128 RFS and held-out RFS) as means over three independent random seeds with standard-deviation error bars. We will also add an appendix ablation table comparing performance for 4, 8, and 12 intents to quantify sensitivity to the number and coverage of intent classes. revision: yes
-
Referee: [§3.1 (intent definition) and §4 (evaluation)] The weakest assumption—that the eight rule-derived intents span all semantically distinct maneuver modes relevant for preference alignment—is load-bearing for the claim that intent-CFG expands the distribution sufficiently; no quantitative validation (e.g., mode coverage metrics or failure-case analysis) is supplied to test this premise.
Authors: The eight intents are obtained via deterministic rule-based classification of trajectory features (curvature sign, lateral offset, speed profile) that are standard in the autonomous-driving literature. While we cannot exhaustively enumerate every conceivable semantic mode, the paper already shows via qualitative rollouts that intent-CFG produces maneuvers absent from the single-demonstration baseline. We will add explicit quantitative mode-coverage statistics (intent-distribution entropy and fraction of unique intents realized in best-of-N samples) together with a dedicated failure-case analysis of uncovered modes in the revised §4. revision: partial
Circularity Check
No significant circularity; claims rest on external empirical comparisons
full rationale
The paper presents DIAL as a two-stage method using intent-CFG for distribution expansion and multi-intent GRPO for preference optimization, with performance measured via direct comparisons to independent external references (RAP baseline at RFS 8.5, human demonstration at 8.13, and held-out metrics). The eight rule-derived intents are introduced as explicit inputs without redefinition in terms of outputs. No equations or steps reduce by construction to fitted parameters, self-citations, or ansatzes; the reported lifts (best-of-128 RFS 9.14, GRPO gain to 8.211) are statistical outcomes of experimentation against non-internal benchmarks. The derivation chain remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Discrete intent labels derived from traffic rules span the semantically relevant maneuver modes for preference alignment
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction (8-tick period) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
eight rule-derived intents (cruise, lane change L/R, turn L/R, U-turn, accelerate, decelerate)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
intent-CFG sampling lifts this ceiling to RFS 9.14 at best-of-128
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Marvin Alles, Nutan Chen, Patrick van der Smagt, and Botond Cseke. Flowq: Energy-guided flow policies for offline reinforcement learning.arXiv preprint arXiv:2505.14139,
-
[2]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Yuning Chai, Benjamin Sapp, Mayank Bansal, and Dragomir Anguelov. Multipath: Multiple proba- bilistic anchor trajectory hypotheses for behavior prediction.arXiv preprint arXiv:1910.05449,
-
[5]
Devil is in Narrow Policy: Unleashing Exploration in Driving
Canyu Chen, Yuguang Yang, Zhewen Tan, Yizhi Wang, Ruiyi Zhan, Haiyan Liu, Xuanyao Mao, Jason Bao, Xinyue Tang, Linlin Yang, et al. Devil is in narrow policy: Unleashing exploration in driving vla models.arXiv preprint arXiv:2603.06049,
-
[6]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning. arXiv preprint arXiv:2402.13243,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
RAP: 3D rasterization augmented end-to-end planning.arXiv preprint arXiv:2510.04333, 2025
Lan Feng, Yang Gao, Eloi Zablocki, Quanyi Li, Wuyang Li, Sichao Liu, Matthieu Cord, and Alexan- dre Alahi. Rap: 3d rasterization augmented end-to-end planning.arXiv preprint arXiv:2510.04333,
-
[8]
Stylevla: Driving style-aware vision language action model for autonomous driving
Yuan Gao, Dengyuan Hua, Mattia Piccinini, Finn Rasmus Schäfer, Korbinian Moller, Lin Li, and Johannes Betz. Stylevla: Driving style-aware vision language action model for autonomous driving. arXiv preprint arXiv:2603.09482,
-
[9]
MindVLA-U1: VLA Beats VA with Unified Streaming Architecture for Autonomous Driving
Victor Shea-Jay Huang, Le Zhuo, Yi Xin, Zhaokai Wang, Fu-Yun Wang, Yuchi Wang, Renrui Zhang, Peng Gao, and Hongsheng Li. Tide: Temporal-aware sparse autoencoders for interpretable diffusion transformers in image generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 435–443, 2026a. Yuzhou Huang, Benjin Zhu, Hengtong ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Yingyan Li, Shuyao Shang, Weisong Liu, Bing Zhan, Haochen Wang, Yuqi Wang, Yuntao Chen, Xiaoman Wang, Yasong An, Chufeng Tang, et al. Drivevla-w0: World models amplify data scaling law in autonomous driving.arXiv preprint arXiv:2510.12796, 2025a. Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bin...
-
[12]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Yuechen Luo, Fang Li, Shaoqing Xu, Yang Ji, Zehan Zhang, Bing Wang, Yuannan Shen, Jianwei Cui, Long Chen, Guang Chen, et al. Last-vla: Thinking in latent spatio-temporal space for vision-language-action in autonomous driving.arXiv preprint arXiv:2603.01928,
-
[14]
Gpt-driver: Learning to drive with gpt.arXiv preprint arXiv:2310.01415, 2023a
Jiageng Mao, Yuxi Qian, Junjie Ye, Hang Zhao, and Yue Wang. Gpt-driver: Learning to drive with gpt.arXiv preprint arXiv:2310.01415,
-
[15]
Flow matching policy gradients.arXiv preprint arXiv:2507.21053,
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients.arXiv preprint arXiv:2507.21053,
-
[16]
Ishaan Rawal, Shubh Gupta, Yihan Hu, and Wei Zhan. Nord: A data-efficient vision-language-action model that drives without reasoning.arXiv preprint arXiv:2602.21172,
-
[17]
Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588, 2024
Allen Z Ren, Justin Lidard, Lars L Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization. arXiv preprint arXiv:2409.00588,
-
[18]
Proximal Policy Optimization Algorithms
11 John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Hao Shao, Yuxuan Hu, Letian Wang, Guanglu Song, Steven L Waslander, Yu Liu, and Hongsheng Li. Lmdrive: Closed-loop end-to-end driving with large language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15120–15130, 2024a. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Learning Vision-Language-Action World Models for Autonomous Driving
Guoqing Wang, Pin Tang, Xiangxuan Ren, Guodongfang Zhao, Bailan Feng, and Chao Ma. Learning vision-language-action world models for autonomous driving.arXiv preprint arXiv:2604.09059,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning.arXiv preprint arXiv:2208.06193,
work page internal anchor Pith review arXiv
-
[22]
Dilu: A knowledge-driven approach to autonomous driving with large language models
Licheng Wen, Daocheng Fu, Xin Li, Xinyu Cai, Tao Ma, Pinlong Cai, Min Dou, Botian Shi, Liang He, and Yu Qiao. Dilu: A knowledge-driven approach to autonomous driving with large language models.arXiv preprint arXiv:2309.16292,
-
[23]
Latentvla: Efficient vision-language models for autonomous driving via latent action prediction
Chengen Xie, Bin Sun, Tianyu Li, Junjie Wu, Zhihui Hao, XianPeng Lang, and Hongyang Li. Latentvla: Efficient vision-language models for autonomous driving via latent action prediction. arXiv preprint arXiv:2601.05611,
-
[24]
Runsheng Xu, Hubert Lin, Wonseok Jeon, Hao Feng, Yuliang Zou, Liting Sun, John Gorman, Ekaterina Tolstaya, Sarah Tang, Brandyn White, et al. Wod-e2e: Waymo open dataset for end-to- end driving in challenging long-tail scenarios.arXiv preprint arXiv:2510.26125, 2025a. Yifang Xu, Jiahao Cui, Feipeng Cai, Zhihao Zhu, Hanlin Shang, Shan Luan, Mingwang Xu, Nen...
-
[25]
Vla-r1: Enhancing reasoning in vision-language-action models.arXiv preprint arXiv:2510.01623, 2025
Angen Ye, Zeyu Zhang, Boyuan Wang, Xiaofeng Wang, Dapeng Zhang, and Zheng Zhu. Vla-r1: Enhancing reasoning in vision-language-action models.arXiv preprint arXiv:2510.01623,
-
[26]
Samoe- vla: A scene adaptive mixture-of-experts vision-language-action model for autonomous driving
Zihan You, Hongwei Liu, Chenxu Dang, Zhe Wang, Sining Ang, Aoqi Wang, and Yan Wang. Samoe- vla: A scene adaptive mixture-of-experts vision-language-action model for autonomous driving. arXiv preprint arXiv:2603.08113,
-
[27]
Dapeng Zhang, Zhenlong Yuan, Zhangquan Chen, Chih-Ting Liao, Yinda Chen, Fei Shen, Qingguo Zhou, and Tat-Seng Chua. Reasoning-vla: A fast and general vision-language-action reasoning model for autonomous driving.arXiv preprint arXiv:2511.19912, 2025a. Songyan Zhang, Wenhui Huang, Zhan Chen, Chua Jiahao Collister, Qihang Huang, and Chen Lv. Openread: Reinf...
-
[28]
Zewei Zhou, Tianhui Cai, Seth Z Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning.arXiv preprint arXiv:2506.13757,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[30]
Jialv Zou, Shaoyu Chen, Bencheng Liao, Zhiyu Zheng, Yuehao Song, Lefei Zhang, Qian Zhang, Wenyu Liu, and Xinggang Wang. Diffusiondrivev2: Reinforcement learning-constrained truncated diffusion modeling in end-to-end autonomous driving.arXiv preprint arXiv:2512.07745,
-
[31]
13 A Extended Related Work Vision-language-action policies.Vision-language-action models adapt large multimodal represen- tations to action generation. RT-2 studies how web-scale vision-language pretraining can transfer to robot control [Zitkovich et al., 2023]; OpenVLA provides an open-source VLA model for robotic manipulation [Kim et al., 2024]; and π0 ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.