Recognition: 2 theorem links
· Lean TheoremAmortized Guidance for Image Inpainting with Pretrained Diffusion Models
Pith reviewed 2026-05-14 19:29 UTC · model grok-4.3
The pith
A small guidance module trained once offline guides pretrained diffusion models for faster inpainting without per-image optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
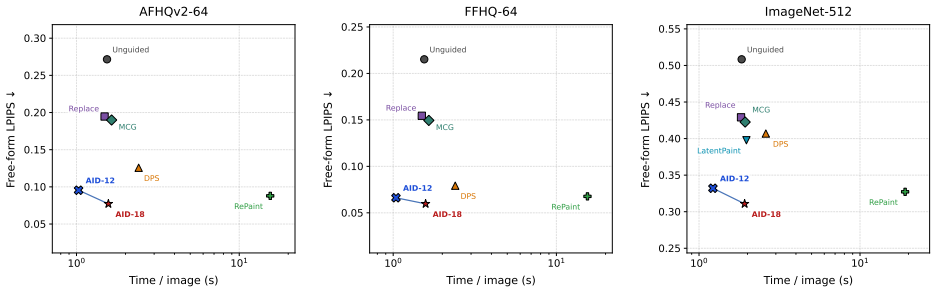
We introduce Amortized Inpainting with Diffusion (AID) that keeps the pretrained diffusion backbone fixed while training a small reusable guidance module offline for use across different masked images. The approach formulates inpainting as a deterministic guidance problem with a supervised terminal objective. To solve this in high dimensions, an auxiliary Gaussian formulation is derived, with a proof that its solution recovers the optimal deterministic guidance field. This leads to a principled continuous-time actor-critic algorithm that learns the guidance module fully from data. Experiments on AFHQv2, FFHQ, and ImageNet show consistent improvements in the quality-speed trade-off over fixed
What carries the argument
Amortized guidance module trained via continuous-time actor-critic on an auxiliary Gaussian formulation that recovers the optimal deterministic guidance field for inpainting.
If this is right
- The same trained guidance module applies to any masked image without per-instance optimization at deployment.
- The pretrained diffusion backbone remains unchanged while adding less than one percent trainable parameters.
- The method improves the quality-speed trade-off over strong fixed-backbone and amortized baselines on AFHQv2, FFHQ, and ImageNet.
- The framework works across multiple mask types under both pixel EDM and latent EDM2 pipelines.
Where Pith is reading between the lines
- The amortized guidance idea could extend to other diffusion tasks such as outpainting or semantic editing by reusing the same training procedure.
- The auxiliary Gaussian bridge might apply to other high-dimensional guidance problems where direct optimization is intractable.
- Real-time applications like interactive photo editing could become feasible if the module generalizes to dynamic masks without retraining.
Load-bearing premise
The auxiliary Gaussian formulation and the proof that solving it recovers the optimal deterministic guidance field hold in high-dimensional image spaces.
What would settle it
An experiment showing that the learned guidance module fails to match or exceed the quality of per-instance optimization methods on a diverse set of masked images would falsify the claim that the auxiliary problem recovers the optimal field.
Figures


read the original abstract
We study image inpainting with generative diffusion models. Existing methods typically either train dedicated task-specific models, or adapt a pretrained diffusion model separately for each masked image at deployment. We introduce a middle-ground model, termed Amortized Inpainting with Diffusion (AID), which keeps a pretrained diffusion backbone fixed, trains a small reusable guidance module offline, and then reuses it across masked images without per-instance optimization. We formulate it as a deterministic guidance problem with a supervised terminal objective. To make this problem learnable in high dimensions, we derive an auxiliary Gaussian formulation and prove that solving this randomized problem recovers the optimal deterministic guidance field. This bridge yields a principled continuous-time actor--critic algorithm for learning the guidance module in a fully data-driven manner. Empirically, on AFHQv2 and FFHQ under the pixel EDM pipeline and on ImageNet under the latent EDM2 pipeline, AID consistently improves the quality--speed trade-off over strong fixed-backbone and amortized inpainting baselines across multiple mask types, while adding less than one percent trainable overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Amortized Inpainting with Diffusion (AID), a method that keeps a pretrained diffusion backbone fixed while training a small reusable guidance module offline. This module is then applied to new masked images without per-instance optimization. The approach formulates inpainting as a deterministic guidance problem with a supervised terminal objective, derives an auxiliary Gaussian formulation, and proves that solving the randomized Gaussian problem recovers the optimal deterministic guidance field exactly. This equivalence enables a continuous-time actor-critic algorithm for learning the guidance module in a data-driven way. Experiments on AFHQv2, FFHQ (pixel EDM) and ImageNet (latent EDM2) report improved quality-speed trade-offs over fixed-backbone and amortized baselines across mask types, with under 1% added trainable parameters.
Significance. If the central Gaussian-to-deterministic recovery holds without hidden low-dimensional assumptions, the work offers a principled middle ground between task-specific retraining and per-image optimization, enabling efficient amortized inpainting with minimal overhead. The data-driven actor-critic procedure and empirical gains on standard benchmarks would be a useful contribution to practical diffusion-based editing pipelines.
major comments (2)
- [Abstract / §3] Abstract and the derivation of the auxiliary Gaussian formulation: the proof that its solution recovers the exact optimal deterministic guidance field is load-bearing for the entire actor-critic training procedure, yet the manuscript provides no explicit steps, error bounds, or verification of the high-dimensional assumptions (interchange of limits, Gaussian closure under masking, handling of the terminal distribution). Without these details the central claim cannot be assessed.
- [§4] The continuous-time actor-critic algorithm (derived from the Gaussian equivalence): because the equivalence is unverified in the pixel/latent image regime, it is unclear whether the learned guidance module actually approximates the claimed optimal field or merely fits a supervised proxy; this directly affects the interpretation of all reported quality improvements.
minor comments (2)
- [§5] Empirical section: the description of baselines and metrics is insufficiently detailed (e.g., exact implementation of the per-instance optimization baselines, choice of FID/LPIPS variants, number of samples per mask type).
- [§2] Notation: the distinction between the deterministic guidance field and the Gaussian auxiliary variables should be introduced with explicit symbols before the proof is invoked.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the concerns about the Gaussian equivalence proof and its implications for the actor-critic procedure below. We will revise the manuscript to expand the theoretical details as requested.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and the derivation of the auxiliary Gaussian formulation: the proof that its solution recovers the exact optimal deterministic guidance field is load-bearing for the entire actor-critic training procedure, yet the manuscript provides no explicit steps, error bounds, or verification of the high-dimensional assumptions (interchange of limits, Gaussian closure under masking, handling of the terminal distribution). Without these details the central claim cannot be assessed.
Authors: We agree that the presentation of the proof can be strengthened with more explicit steps. The equivalence is derived in Section 3 and the full argument appears in Appendix A, but we will expand the appendix in revision to provide a complete step-by-step derivation. This will include: (i) justification for interchanging limits via the dominated convergence theorem under the standard Lipschitz and linear-growth conditions on the score function; (ii) confirmation that Gaussian closure holds because masking is a linear projection, which maps Gaussians to Gaussians; and (iii) explicit handling of the terminal distribution by direct matching to the supervised objective at t=0. We will also add error bounds derived from the continuous-time approximation and a low-dimensional numerical verification to support applicability in the high-dimensional image regime. These additions rely only on the diffusion SDE properties and do not invoke hidden low-dimensional assumptions. revision: yes
-
Referee: [§4] The continuous-time actor-critic algorithm (derived from the Gaussian equivalence): because the equivalence is unverified in the pixel/latent image regime, it is unclear whether the learned guidance module actually approximates the claimed optimal field or merely fits a supervised proxy; this directly affects the interpretation of all reported quality improvements.
Authors: The equivalence established in Section 3 is exact and dimension-independent, relying solely on the diffusion process and the linearity of masking; therefore the actor-critic procedure targets the optimal deterministic guidance field. The empirical gains are consequently attributable to improved approximation of this field. In the revision we will insert a clarifying paragraph in Section 4 that restates this point and add an ablation study comparing the learned module against a direct supervised regression baseline, thereby distinguishing optimal-field approximation from generic proxy fitting. revision: yes
Circularity Check
No load-bearing circularity; derivation uses external supervised objective and data-driven training
full rationale
The paper formulates inpainting as a deterministic guidance problem with a supervised terminal objective, then introduces an auxiliary Gaussian formulation whose solution is claimed to recover the optimal field. This is presented as a derivation from first principles rather than a fit or self-definition. No equations reduce the claimed result to a parameter defined by the same result, and no self-citation chain is invoked for the core equivalence. The method trains the guidance module from data in a fully supervised manner, keeping the diffusion backbone fixed. This yields an independent, externally falsifiable construction whose validity rests on the correctness of the Gaussian bridge (a separate correctness question) rather than on circular reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An optimal deterministic guidance field exists for the inpainting terminal objective.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate it as a deterministic guidance problem with a supervised terminal objective. To make this problem learnable in high dimensions, we derive an auxiliary Gaussian formulation and prove that solving this randomized problem recovers the optimal deterministic guidance field.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.2 (Sufficiency: deterministic guidance induces an optimal Gaussian policy) ... Theorem 3.3 (Necessity: auxiliary optimality recovers deterministic guidance)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
StarGAN v2: Diverse image synthesis for multiple domains
Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. StarGAN v2: Diverse image synthesis for multiple domains. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8188–8197, 2020
2020
-
[2]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Improving diffusion models for inverse problems using manifold constraints.Advances in Neural Information Processing Systems, 35: 25683–25696, 2022
Hyungjin Chung, Byeongsu Sim, Dohoon Ryu, and Jong Chul Ye. Improving diffusion models for inverse problems using manifold constraints.Advances in Neural Information Processing Systems, 35: 25683–25696, 2022
2022
-
[4]
LatentPaint: Image inpainting in latent space with diffusion models
Ciprian Corneanu, Raghudeep Gadde, and Aleix M Martinez. LatentPaint: Image inpainting in latent space with diffusion models. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 4334–4343, 2024
2024
-
[5]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[6]
Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[7]
Reward-directed score-based diffusion models via q-learning
Xuefeng Gao, Jiale Zha, and Xun Yu Zhou. Reward-directed score-based diffusion models via q-learning. Journal of Machine Learning Research, 26(302):1–46, 2025
2025
-
[8]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[10]
Continuous-time reinforcement learning for asset–liability management
Yilie Huang. Continuous-time reinforcement learning for asset–liability management. InProceedings of the 6th ACM International Conference on AI in Finance, pages 360–368, 2025
2025
-
[11]
Yilie Huang and Xun Yu Zhou. Data-driven exploration for a class of continuous-time indefinite linear–quadratic reinforcement learning problems.arXiv preprint arXiv:2507.00358, 2025. 10
-
[12]
Yilie Huang, Yanwei Jia, and Xun Yu Zhou. Mean–variance portfolio selection by continuous-time reinforcement learning: Algorithms, regret analysis, and empirical study.arXiv preprint arXiv:2412.16175, 2024
-
[13]
Sublinear regret for a class of continuous-time linear- quadratic reinforcement learning problems.SIAM Journal on Control and Optimization, 63(5):3452–3474, 2025
Yilie Huang, Yanwei Jia, and Xun Yu Zhou. Sublinear regret for a class of continuous-time linear- quadratic reinforcement learning problems.SIAM Journal on Control and Optimization, 63(5):3452–3474, 2025
2025
-
[14]
ART for Diffusion Sampling: A Reinforcement Learning Approach to Timestep Schedule
Yilie Huang, Wenpin Tang, and Xunyu Zhou. Art for diffusion sampling: A reinforcement learning approach to timestep schedule.arXiv preprint arXiv:2601.18681, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach.J
Yanwei Jia and Xun Yu Zhou. Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach.J. Mach. Learn. Res., 23(154):1–55, 2022
2022
-
[16]
Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms.J
Yanwei Jia and Xun Yu Zhou. Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms.J. Mach. Learn. Res., 23(154):1–55, 2022
2022
-
[17]
BrushNet: A plug-and-play image inpainting model with decomposed dual-branch diffusion
Xuan Ju, Xian Liu, Xintao Wang, Yuxuan Bian, Ying Shan, and Qiang Xu. BrushNet: A plug-and-play image inpainting model with decomposed dual-branch diffusion. InEuropean Conference on Computer Vision, pages 150–168. Springer, 2024
2024
-
[18]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019
2019
-
[19]
Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
2022
-
[20]
Guiding a diffusion model with a bad version of itself.Advances in Neural Information Processing Systems, 37:52996–53021, 2024
Tero Karras, Miika Aittala, Tuomas Kynkäänniemi, Jaakko Lehtinen, Timo Aila, and Samuli Laine. Guiding a diffusion model with a bad version of itself.Advances in Neural Information Processing Systems, 37:52996–53021, 2024
2024
-
[21]
Analyzing and improving the training dynamics of diffusion models
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24174–24184, 2024
2024
-
[22]
Actor-critic algorithms.Advances in neural information processing systems, 12, 1999
Vijay Konda and John Tsitsiklis. Actor-critic algorithms.Advances in neural information processing systems, 12, 1999
1999
-
[23]
Diffusion prior-based amortized variational inference for noisy inverse problems
Sojin Lee, Dogyun Park, Inho Kong, and Hyunwoo J Kim. Diffusion prior-based amortized variational inference for noisy inverse problems. InEuropean Conference on Computer Vision, pages 288–304. Springer, 2024
2024
-
[24]
Solving inverse problems via diffusion optimal control.Advances in Neural Information Processing Systems, 37:73549–73571, 2024
Henry Li and Marcus Pereira. Solving inverse problems via diffusion optimal control.Advances in Neural Information Processing Systems, 37:73549–73571, 2024
2024
-
[25]
MAT: Mask-aware transformer for large hole image inpainting
Wenbo Li, Zhe Lin, Kun Zhou, Lu Qi, Yi Wang, and Jiaya Jia. MAT: Mask-aware transformer for large hole image inpainting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10758–10768, 2022
2022
-
[26]
PrefPaint: Aligning image inpainting diffusion model with human preference.Advances in Neural Information Processing Systems, 37:30554–30589, 2024
Kendong Liu, Zhiyu Zhu, Chuanhao Li, Hui Liu, Huanqiang Zeng, and Junhui Hou. PrefPaint: Aligning image inpainting diffusion model with human preference.Advances in Neural Information Processing Systems, 37:30554–30589, 2024
2024
-
[27]
RePaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. RePaint: Inpainting using denoising diffusion probabilistic models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022. 11
2022
-
[28]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equations.arXiv preprint arXiv:2108.01073, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International conference on machine learning, pages 8162–8171. PMLR, 2021
2021
-
[30]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[31]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
2015
-
[32]
Palette: Image-to-image diffusion models
Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. InACM SIGGRAPH 2022 conference proceedings, pages 1–10, 2022
2022
-
[33]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[34]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[35]
Learning to predict by the methods of temporal differences.Machine learning, 3(1): 9–44, 1988
Richard S Sutton. Learning to predict by the methods of temporal differences.Machine learning, 3(1): 9–44, 1988
1988
-
[36]
Resolution-robust large mask inpainting with Fourier convolutions
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with Fourier convolutions. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2149–2159, 2022
2022
-
[37]
Regret of exploratory policy improvement andq-learning.arXiv preprint arXiv:2411.01302, 2024
Wenpin Tang and Xun Yu Zhou. Regret of exploratory policy improvement andq-learning.arXiv preprint arXiv:2411.01302, 2024
-
[38]
Reinforcement learning in continuous time and space: A stochastic control approach.Journal of Machine Learning Research, 21(198):1–34, 2020
Haoran Wang, Thaleia Zariphopoulou, and Xun Yu Zhou. Reinforcement learning in continuous time and space: A stochastic control approach.Journal of Machine Learning Research, 21(198):1–34, 2020
2020
-
[39]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
2004
-
[40]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[41]
Score as Action: Fine tuning diffusion generative models by continuous-time reinforcement learning
Hanyang Zhao, Haoxian Chen, Ji Zhang, David Yao, and Wenpin Tang. Score as Action: Fine tuning diffusion generative models by continuous-time reinforcement learning. InICML, 2025. A Proof of Lemma 3.1 Recall that, for a fixed observable inputξ= (M, y), the deterministic value functionVsolves Vt(t, x;ξ) + inf u∈Rd ∇xV(t, x;ξ) ⊤ b(t, x) +u + β 2 ∥u∥2 = 0,(1...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.