Recognition: no theorem link
Rigel3D: Rig-aware Latents for Animation-Ready 3D Asset Generation
Pith reviewed 2026-05-14 01:40 UTC · model grok-4.3
The pith
Rigel3D generates 3D meshes with built-in skeletal rigs by jointly learning surface geometry and skeleton structure in coupled latent spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
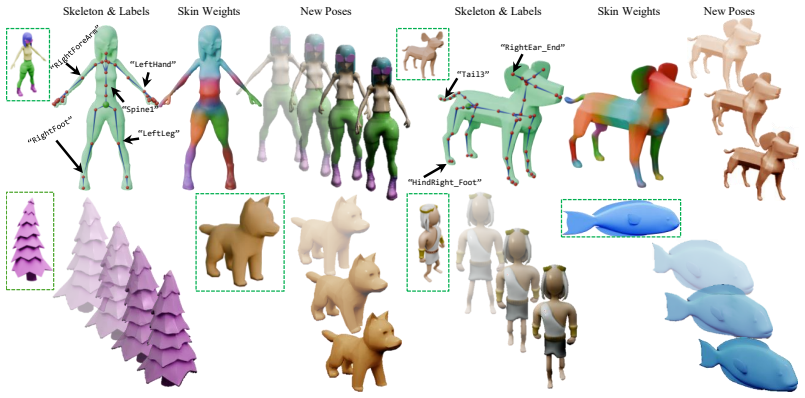
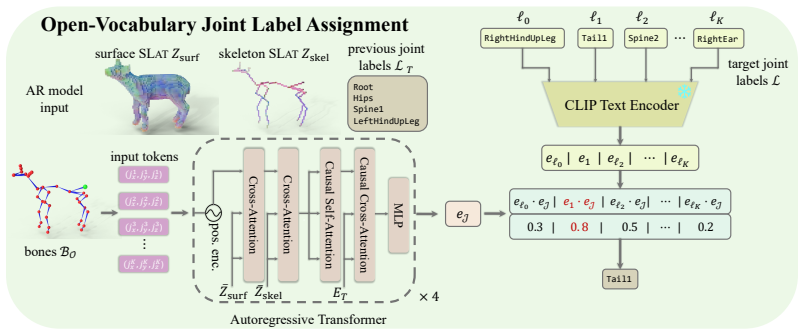
Rigel3D jointly models geometry and rig structure through coupled surface and skeleton structured latent representations. A rig-aware autoencoder decodes these representations into mesh geometry, skeleton topology, joint coordinates, and skinning weights. A two-stage latent generative model synthesizes both surface and skeleton representations for image-conditioned generation, while an open-vocabulary joint labeling module embeds generated joints into a shared vision-language space for retargeting.
What carries the argument
Coupled surface and skeleton structured latent representations decoded by a rig-aware autoencoder into rigged meshes
If this is right
- Generated assets include complete skeletons and skinning weights ready for immediate use in animation software.
- Image-conditioned generation produces diverse rigged meshes that respect learned correlations between shape and rig structure.
- Open-vocabulary joint labels enable direct retargeting to arbitrary animation templates without manual mapping.
- The method outperforms existing auto-rigging baselines across quantitative metrics on large-scale rigged datasets.
- Assets support downstream workflows in games, film, simulation, and embodied AI without separate rigging steps.
Where Pith is reading between the lines
- This joint modeling could shorten asset pipelines by removing the need for separate rigging artists or tools after generation.
- The latent structure might extend to conditioning on motion data or physics parameters to generate animated sequences directly.
- Replacing the decoder in existing static 3D generators with this rig-aware decoder could retrofit them for animation output.
- The vision-language joint embeddings open the possibility of text-driven rig adjustments or semantic retargeting queries.
Load-bearing premise
The joint distributions of geometry and rig structure captured in the training data allow coupled latents to produce better rigged outputs than generating shapes first and rigging them afterward.
What would settle it
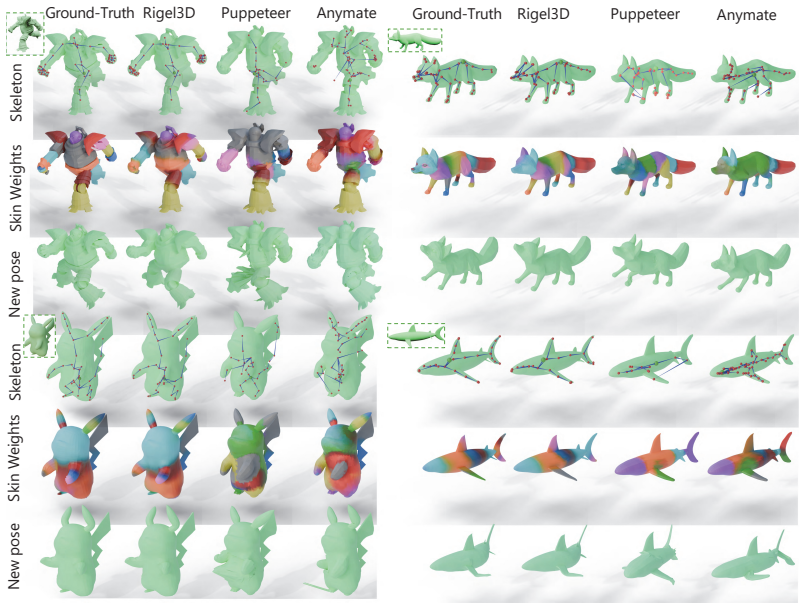
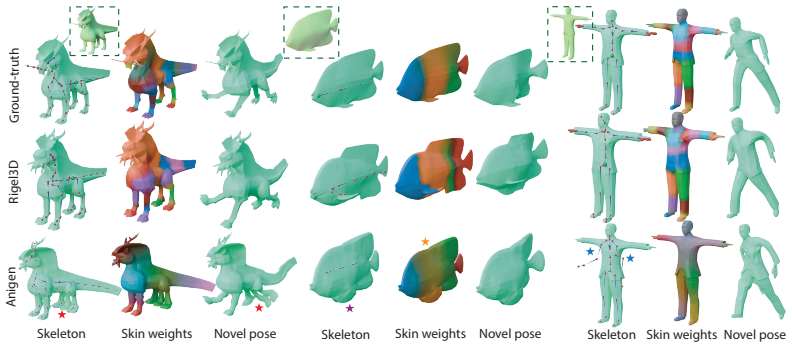
An experiment in which independent shape generation followed by a strong post-hoc auto-rigger matches or exceeds Rigel3D on the same rigged asset test sets for metrics such as joint placement accuracy, skinning weight quality, and animation fidelity would falsify the advantage of joint modeling.
Figures


read the original abstract
Recent 3D generative models can synthesize high-quality assets, but their outputs are typically static: they lack the skeletal rigs, joint hierarchies, and skinning weights required for animation. This limits their use in games, film, simulation, virtual agents, and embodied AI, where assets must not only look plausible but also move plausibly. We introduce Rigel3D, a generative method for animation-ready 3D assets represented as rigged meshes. Unlike post-hoc auto-rigging methods that attach rigs to completed shapes, our method jointly models geometry and rig structure through coupled surface and skeleton structured latent representations. A rig-aware autoencoder decodes these representations into mesh geometry, skeleton topology, joint coordinates, and skinning weights, while a two-stage latent generative model synthesizes both surface and skeleton representations for image-conditioned generation. To support downstream animation workflows, we further introduce an open-vocabulary joint labeling module that embeds generated joints into a shared vision-language space, enabling correspondence to arbitrary retargeting templates. Experiments on large-scale rigged asset datasets demonstrate that our method generates diverse, high-quality animation-ready assets and outperforms existing rigging baselines across multiple metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Rigel3D, a generative method for animation-ready 3D assets as rigged meshes. It jointly models geometry and rig structure through coupled surface and skeleton structured latent representations in a rig-aware autoencoder that decodes to mesh geometry, skeleton topology, joint coordinates, and skinning weights, combined with a two-stage latent generative model for image-conditioned synthesis. An open-vocabulary joint labeling module embeds joints into a vision-language space for retargeting. Experiments on large-scale rigged asset datasets are claimed to show that the method generates diverse, high-quality assets and outperforms existing rigging baselines across multiple metrics.
Significance. If the central claims hold, the work would meaningfully advance 3D generative modeling by closing the gap between static asset synthesis and animation-ready outputs, with direct utility for games, film, simulation, and embodied AI. The coupled latent formulation and open-vocabulary labeling are potentially valuable contributions that could reduce reliance on post-hoc rigging pipelines.
major comments (2)
- [Abstract] Abstract: the claim that the method 'outperforms existing rigging baselines across multiple metrics' is presented without any quantitative values, error bars, or ablation tables. This absence directly prevents verification of whether the coupled surface-skeleton latents deliver gains beyond what a strong auto-rigging model achieves on independently generated geometry.
- [Method and Experiments] Method and Experiments sections: no ablation is described that decouples the surface and skeleton latent spaces (e.g., training separate models versus the joint model) or that compares the same generated meshes rigged jointly versus post-hoc. Without these controls, the superiority of the coupled representations cannot be isolated from dataset bias or the autoencoder alone.
minor comments (1)
- [Method] The description of the two-stage latent generative model would benefit from an explicit statement of the training objective and any regularization terms applied to the skeleton topology.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The comments highlight opportunities to strengthen the presentation of quantitative results and the evidence for our coupled latent design. We will revise the manuscript accordingly and address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'outperforms existing rigging baselines across multiple metrics' is presented without any quantitative values, error bars, or ablation tables. This absence directly prevents verification of whether the coupled surface-skeleton latents deliver gains beyond what a strong auto-rigging model achieves on independently generated geometry.
Authors: We agree that the abstract would benefit from explicit numerical support. The full manuscript already contains tables in the experiments section reporting metrics such as joint position error, skinning weight accuracy, and mesh quality with standard deviations computed over multiple runs. We will revise the abstract to include the key quantitative improvements (e.g., relative gains over baselines) while preserving brevity. revision: yes
-
Referee: [Method and Experiments] Method and Experiments sections: no ablation is described that decouples the surface and skeleton latent spaces (e.g., training separate models versus the joint model) or that compares the same generated meshes rigged jointly versus post-hoc. Without these controls, the superiority of the coupled representations cannot be isolated from dataset bias or the autoencoder alone.
Authors: We concur that dedicated ablations are necessary to isolate the benefit of the coupled surface-skeleton latents. In the revised version we will add a new ablation subsection that (1) trains and compares separate surface-only and skeleton-only autoencoders against the joint model and (2) evaluates post-hoc rigging applied to the same generated meshes. These controls will quantify the consistency gains attributable to joint training. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents Rigel3D as a standard rig-aware autoencoder followed by a two-stage latent generative model for coupled surface and skeleton representations. No equations, definitions, or steps reduce any claimed prediction or output to a fitted input by construction, nor do they rely on self-citations for uniqueness or load-bearing premises. The superiority claims rest on empirical experiments rather than mathematical reductions, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural networks can learn a mapping from coupled surface-skeleton latent codes to mesh geometry, joint coordinates, and skinning weights
Reference graph
Works this paper leans on
-
[1]
Inbar Gat, Sigal Raab, Guy Tevet, Yuval Reshef, Amit H. Bermano, and Daniel Cohen-Or. AnyTop: Character Animation Diffusion with Any Topology.arXiv preprint arXiv:2502.17327,
-
[2]
Jingfeng Guo, Jian Liu, Jinnan Chen, Shiwei Mao, Changrong Hu, Puhua Jiang, Junlin Yu, Jing Xu, Qi Liu, Lixin Xu, Zhuo Chen, and Chunchao Guo. Auto-Connect: Connectivity-Preserving RigFormer with Direct Preference Optimization.arXiv preprint arXiv:2506.11430, 2025a. Zhiyang Guo, Jinxu Xiang, Kai Ma, Wengang Zhou, Houqiang Li, and Ran Zhang. Make-It- Anima...
-
[3]
AniGen: Unified $S^3$ Fields for Animatable 3D Asset Generation
Yi-Hua Huang, Zi-Xin Zhou, Yuting He, Chirui Chang, Cheng-Feng Pu, Ziyi Yang, Yuan-Chen Guo, Yan-Pei Cao, and Xiaojuan Qi. AniGen: Unified S3 Fields for Animatable 3D Asset Generation. SIGGRAPH (to appear), arxiv version DOI: 2604.08746 (14 Apr 2026),
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Zehuan Huang, Haoran Feng, Yangtian Sun, Yuanchen Guo, Yanpei Cao, and Lu Sheng. Ani- maX: Animating the Inanimate in 3D with Joint Video-Pose Diffusion Models.arXiv preprint arXiv:2506.19851,
-
[5]
Particulate: Feed-Forward 3D Object Articulation.arXiv preprint arXiv:2512.11798,
Ruining Li, Yuxin Yao, Chuanxia Zheng, Christian Rupprecht, Joan Lasenby, Shangzhe Wu, and An- drea Vedaldi. Particulate: Feed-Forward 3D Object Articulation.arXiv preprint arXiv:2512.11798,
-
[6]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jégou, Julien Mairal, Patrick La...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
DreamGaus- sian4D: Generative 4D Gaussian Splatting.arXiv preprint arXiv:2312.17142,
Jiawei Ren, Liang Pan, Jiaxiang Tang, Chi Zhang, Ang Cao, Gang Zeng, and Ziwei Liu. DreamGaus- sian4D: Generative 4D Gaussian Splatting.arXiv preprint arXiv:2312.17142,
-
[9]
Puppeteer: Rig and Animate Your 3D Models
Chaoyue Song, Xiu Li, Fan Yang, Zhongcong Xu, Jiacheng Wei, Fayao Liu, Jiashi Feng, Guosheng Lin, and Jianfeng Zhang. Puppeteer: Rig and Animate Your 3D Models. InNeurIPS, 2025a. Chaoyue Song, Jianfeng Zhang, Xiu Li, Fan Yang, Yiwen Chen, Zhongcong Xu, Jun Hao Liew, Xiaoyang Guo, Fayao Liu, Jiashi Feng, and Guosheng Lin. MagicArticulate: Make Your 3D Mode...
-
[10]
Zijie Wu, Chaohui Yu, Fan Wang, and Xiang Bai. AnimateAnyMesh: A Feed-Forward 4D Foundation Model for Text-Driven Universal Mesh Animation.arXiv preprint arXiv:2506.09982,
-
[11]
Native and Compact Structured Latents for 3D Generation.arXiv preprint arXiv:2512.14692, 2025a
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, and Jiaolong Yang. Native and Compact Structured Latents for 3D Generation.arXiv preprint arXiv:2512.14692, 2025a. 11 Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolon...
-
[12]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
12 A Detailed description of Open-V ocabulary Joint Label Assignment Many downstream animation pipelines assume that the joints of an input skeleton are labeled. For example, motion retargeting methods often require correspondences between source and target joints, such as matchingLeftArm,Spine, orHead across different characters. However, template- free ...
work page 2020
-
[14]
provides text labels for many joints, but these labels are collected from heterogeneous artist-created assets and are not standardized. They may contain armature prefixes, namespace strings, duplicated identifiers, inconsistent left/right conventions, or non-informative names. We clean these labels using an LLM-based preprocessing pipeline with QWEN3-8B Y...
work page 2025
-
[15]
As mentioned in the main text, due to memory constraints we freeze Esurf and pre-extract the surface SLats for each item in the training split. We train the surface and skeleton Sparse Structure V AEs for24 hours on 4 NVIDIA A5000 24GB GPUs with a batch size of 4 per GPU. We finetune Gocc skel,G occ surf ,G lat skel,G lat surf for 2 days each on 8 14 Tabl...
-
[16]
is used to obtain fixed-size global shape information in Song et al. [2025b,a].Ours (joint SLat grid)refers to our method with the encoder input consisting of both the surface DinoV2 features as well as the rig-aware features within thesame3D grid. Finally, inOurs (Skeleton SLats)we perform a single cross-attention operation with just the rig slats inside...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.