Recognition: unknown
D-VLA: A High-Concurrency Distributed Asynchronous Reinforcement Learning Framework for Vision-Language-Action Models
Pith reviewed 2026-05-14 19:42 UTC · model grok-4.3
The pith
D-VLA isolates high-frequency simulation data from low-frequency model updates to enable scalable RL on trillion-parameter vision-language-action models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
D-VLA achieves high-concurrency distributed RL for VLA models through plane decoupling that physically isolates high-frequency training data from low-frequency weight control, a four-thread asynchronous Swimlane pipeline for full overlap of sampling, inference, gradient computation, and parameter distribution, plus dual-pool VRAM management with topology-aware replication, delivering significantly higher throughput and sampling efficiency on billion-parameter models along with stability and linear speedup at trillion-parameter scales.
What carries the argument
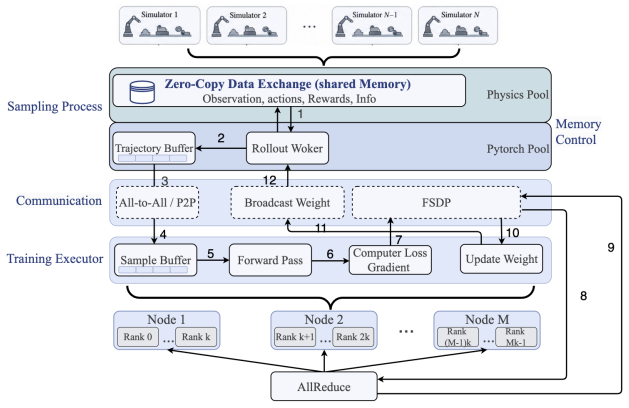
Plane Decoupling, which physically isolates high-frequency training data from low-frequency weight control to eliminate interference between simulation and optimization.
If this is right
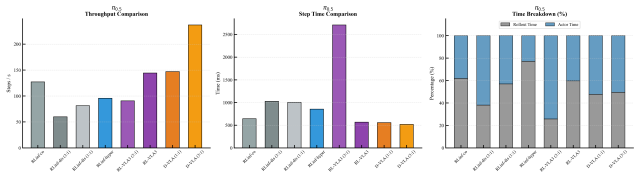
- Outperforms mainstream RL frameworks in throughput and sampling efficiency for billion-parameter VLA models on benchmarks like LIBERO.
- Maintains exceptional stability while delivering linear speedup during trillion-parameter scalability tests.
- Resolves systemic bottlenecks from simulation and optimization resource conflicts in large-scale distributed environments.
- Supports robust high-performance training of general-purpose embodied agents at previously constrained model sizes.
Where Pith is reading between the lines
- The decoupling approach may extend to other distributed systems that mix high-frequency data streams with infrequent parameter updates.
- Linear speedup at trillion-parameter scales suggests the design could accommodate further hardware expansion for more complex embodied tasks.
- Reduced interference between simulation and learning loops might lower overall energy costs for training policies on real-world robotics problems.
Load-bearing premise
The assumption that physically isolating high-frequency training data from low-frequency weight control eliminates interference without degrading the quality or convergence of the learned policies.
What would settle it
If throughput on LIBERO benchmarks shows no improvement or if policy convergence degrades when plane decoupling is applied compared with standard RL frameworks, the central claim would be falsified.
Figures





read the original abstract
The rapid evolution of Embodied AI has enabled Vision-Language-Action (VLA) models to excel in multimodal perception and task execution. However, applying Reinforcement Learning (RL) to these massive models in large-scale distributed environments faces severe systemic bottlenecks, primarily due to the resource conflict between high-fidelity physical simulation and the intensive VRAM/bandwidth demands of deep learning. This conflict often leaves overall throughput constrained by execution-phase inefficiencies. To address these challenges, we propose D-VLA, a high-concurrency, low-latency distributed RL framework for large-scale embodied foundation models. D-VLA introduces "Plane Decoupling," physically isolating high-frequency training data from low-frequency weight control to eliminate interference between simulation and optimization. We further design a four-thread asynchronous "Swimlane" pipeline, enabling full parallel overlap of sampling, inference, gradient computation, and parameter distribution. Additionally, a dual-pool VRAM management model and topology-aware replication resolve memory fragmentation and optimize communication efficiency. Experiments on benchmarks like LIBERO show that D-VLA significantly outperforms mainstream RL frameworks in throughput and sampling efficiency for billion-parameter VLA models. In trillion-parameter scalability tests, our framework maintains exceptional stability and linear speedup, providing a robust system for high-performance general-purpose embodied agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces D-VLA, a high-concurrency distributed asynchronous RL framework for large-scale Vision-Language-Action (VLA) models. It proposes 'Plane Decoupling' to physically isolate high-frequency training data from low-frequency weight control, a four-thread 'Swimlane' pipeline to overlap sampling, inference, gradient computation, and parameter distribution, plus dual-pool VRAM management and topology-aware replication. Experiments on LIBERO benchmarks claim significant outperformance over mainstream RL frameworks in throughput and sampling efficiency for billion-parameter VLA models, with linear speedup and exceptional stability demonstrated in trillion-parameter scalability tests.
Significance. If the throughput gains and stability claims hold under rigorous verification, the work would represent a meaningful systems contribution to scaling RL for embodied foundation models, directly addressing resource conflicts between high-fidelity simulation and large-model optimization. The combination of physical isolation and asynchronous pipelining could enable practical training of trillion-parameter VLA agents, provided policy quality is preserved.
major comments (2)
- [Experimental Evaluation] Experimental section (referenced in abstract and §4): the central claims of 'significantly outperforms' in throughput/sampling efficiency on LIBERO and 'exceptional stability' with linear speedup in trillion-parameter tests are stated without any quantitative metrics (e.g., samples/sec, wall-clock time, success rates, reward curves), baseline implementations, statistical significance tests, or ablation results. This absence prevents verification that efficiency gains do not come at the cost of degraded policy quality.
- [Method] §3.1 Plane Decoupling and §3.2 Swimlane pipeline: the design necessarily introduces bounded staleness between high-frequency actor parameters seen by simulators and low-frequency optimizer updates. No analysis or empirical comparison (e.g., final success rates or convergence curves after identical environment steps versus a synchronous baseline) is provided to show that this does not bias value estimates or slow convergence, contrary to standard asynchronous RL results (A3C-style analyses).
minor comments (2)
- [Abstract] Abstract: 'trillion-parameter scalability tests' should specify whether these use actual trillion-parameter models or proxy scaling experiments, as VLA models are typically described at billion-parameter scale.
- [Introduction] Introduction: the terms 'Plane Decoupling' and 'Swimlane pipeline' are used before their definitions; a one-sentence forward reference would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for major revision. We address each major comment below and will update the manuscript to strengthen the experimental reporting and analysis of asynchrony effects.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental section (referenced in abstract and §4): the central claims of 'significantly outperforms' in throughput/sampling efficiency on LIBERO and 'exceptional stability' with linear speedup in trillion-parameter tests are stated without any quantitative metrics (e.g., samples/sec, wall-clock time, success rates, reward curves), baseline implementations, statistical significance tests, or ablation results. This absence prevents verification that efficiency gains do not come at the cost of degraded policy quality.
Authors: We agree that the current presentation of results requires more explicit quantitative support to allow verification. In the revised manuscript we will expand §4 with a new table reporting samples/sec, wall-clock times, success rates, reward curves, direct comparisons to mainstream RL baselines, statistical significance tests, and ablation studies on the pipeline components. These additions will confirm that throughput gains do not degrade policy quality. revision: yes
-
Referee: [Method] §3.1 Plane Decoupling and §3.2 Swimlane pipeline: the design necessarily introduces bounded staleness between high-frequency actor parameters seen by simulators and low-frequency optimizer updates. No analysis or empirical comparison (e.g., final success rates or convergence curves after identical environment steps versus a synchronous baseline) is provided to show that this does not bias value estimates or slow convergence, contrary to standard asynchronous RL results (A3C-style analyses).
Authors: We acknowledge that the effects of bounded staleness require explicit analysis. We will add a dedicated subsection to §3 that provides both theoretical bounds on staleness and empirical comparisons, including convergence curves and final success rates for D-VLA versus a synchronous baseline after identical environment steps on LIBERO tasks. This will demonstrate that the controlled asynchrony does not materially bias value estimates or slow convergence in the VLA setting. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper is a systems description of a distributed RL framework (Plane Decoupling, four-thread Swimlane pipeline, dual-pool VRAM) whose central claims rest on empirical throughput and scaling measurements on LIBERO and trillion-parameter tests. No equations appear that define any quantity in terms of itself, no fitted parameters are relabeled as predictions, and no load-bearing premises reduce to self-citations. The architecture choices are presented as engineering decisions validated by benchmarks rather than derived from self-referential definitions.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Plane Decoupling
no independent evidence
-
Swimlane pipeline
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sanketi, Grecia Salazar, Michael S
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, Quan Vuong, Vincent Vanhoucke, Huong Tran, Radu Soricut, Anikait Singh, Jaspiar Singh, Pierre Sermanet, Pannag R. Sanketi, Grecia Salazar, Michael S. Ryoo, Krista Reymann, Kanishka Rao, Karl Pertsch, Igor Mordatch, Henryk Michalewski...
2023
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Gemini Robotics Team. Gemini Robotics 1.5: Pushing the Frontier of Generalist Robots with Advanced Embodied Reasoning, Thinking, and Motion Transfer.arXiv e-prints, page arXiv:2510.03342, October 2025
-
[4]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Smolvla: A vision-language-action model for affordable and efficient robotics, 2025
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, and Remi Cadene. Smolvla: A vision-language-action model for affordable and efficient robotics, 2025
2025
-
[6]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, and Irwin King. A survey on vision- language-action models for embodied ai.arXiv preprint arXiv:2405.14093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
A survey on vision- language-action models: An action tokenization perspective
Yifan Zhong, Fengshuo Bai, Shaofei Cai, Xuchuan Huang, Zhang Chen, Xiaowei Zhang, Yuanfei Wang, Shaoyang Guo, Tianrui Guan, Ka Nam Lui, et al. A survey on vision-language- action models: An action tokenization perspective.arXiv preprint arXiv:2507.01925, 2025
-
[9]
Dapeng Zhang, Jing Sun, Chenghui Hu, Xiaoyan Wu, Zhenlong Yuan, Rui Zhou, Fei Shen, and Qingguo Zhou. Pure vision language action (vla) models: A comprehensive survey.arXiv preprint arXiv:2509.19012, 2025
-
[10]
Lerobot: An open-source library for end-to-end robot learning.arXiv preprint arXiv:2602.22818, 2026
Remi Cadene, Simon Aliberts, Francesco Capuano, Michel Aractingi, Adil Zouitine, Pepijn Kooijmans, Jade Choghari, Martino Russi, Caroline Pascal, Steven Palma, et al. Lerobot: An open-source library for end-to-end robot learning.arXiv preprint arXiv:2602.22818, 2026
-
[11]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
2025
-
[12]
Jian Hu, Xibin Wu, Zilin Zhu, Weixun Wang, Dehao Zhang, Yu Cao, et al. Openrlhf: An easy-to-use, scalable and high-performance rlhf framework.arXiv preprint arXiv:2405.11143, 6, 2024
-
[13]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Klear-reasoner: Advancing reasoning capability via gradient-preserving clipping policy optimization
Zhenpeng Su, Leiyu Pan, Xue Bai, Dening Liu, Guanting Dong, Jiaming Huang, Minxuan Lv, Wenping Hu, Fuzheng Zhang, Kun Gai, et al. Klear-reasoner: Advancing reasoning capability via gradient-preserving clipping policy optimization.arXiv preprint arXiv:2508.07629, 2025
-
[15]
Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, et al. Rlinf-vla: A unified and efficient framework for vla+ rl training.arXiv preprint arXiv:2510.06710, 2025. 10
-
[16]
RL-VLA$^3$: A Flexible and Asynchronous Reinforcement Learning Framework for VLA Training
Zhong Guan, Haoran Sun, Yongjian Guo, Shuai Di, Xiaodong Bai, Jing Long, Tianyun Zhao, Mingxi Luo, Chen Zhou, Yucheng Guo, et al. Rl-vla3: Reinforcement learning vla accelerating via full asynchronism.arXiv preprint arXiv:2602.05765, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
arXiv preprint arXiv:2509.09674 , year=
Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025
-
[18]
Dexbotic: Open-source vision-language-action toolbox.arXiv preprint arXiv:2510.23511, 2025
Bin Xie, Erjin Zhou, Fan Jia, Hao Shi, Haoqiang Fan, Haowei Zhang, Hebei Li, Jianjian Sun, Jie Bin, Junwen Huang, et al. Dexbotic: Open-source vision-language-action toolbox.arXiv preprint arXiv:2510.23511, 2025
-
[19]
Vlab: Your labora- tory for pretraining vlas.https://github.com/huggingface/vlab, 2025
Mustafa Shukor Dana Aubakirova, Jade Cholgari, and Leandro von Werra. Vlab: Your labora- tory for pretraining vlas.https://github.com/huggingface/vlab, 2025
2025
-
[20]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Chen Zhou, Haoran Sun, Hedan Yang, Jing Long, Junwu Xiong, Luqiao Wang, Mingxi Luo, Qiming Yang, Shuai Di, Song Wang, et al. Thousand-gpu large-scale training and optimization recipe for ai-native cloud embodied intelligence infrastructure.arXiv preprint arXiv:2603.11101, 2026
-
[22]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[23]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi 0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations
T Mu, Z Ling, F Xiang, D Yang, X Li, S Tao, Z Huang, Z Jia, and H Su. Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations. In35th Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[25]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[26]
Wei Gao, Yuheng Zhao, Tianyuan Wu, Shaopan Xiong, Weixun Wang, Dakai An, Lunxi Cao, Dilxat Muhtar, Zichen Liu, Haizhou Zhao, et al. Rollart: Scaling agentic rl training via disaggregated infrastructure.arXiv preprint arXiv:2512.22560, 2025
-
[27]
Reward models in deep reinforcement learning: A survey.arXiv preprint arXiv:2506.15421, 2025
Rui Yu, Shenghua Wan, Yucen Wang, Chen-Xiao Gao, Le Gan, Zongzhang Zhang, and De- Chuan Zhan. Reward models in deep reinforcement learning: A survey.arXiv preprint arXiv:2506.15421, 2025
-
[28]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.