Recognition: no theorem link
Utility-Oriented Visual Evidence Selection for Multimodal Retrieval-Augmented Generation
Pith reviewed 2026-05-14 19:06 UTC · model grok-4.3
The pith
Ranking visual evidence by information gain on a latent helpfulness variable matches its answer-space utility in multimodal RAG
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
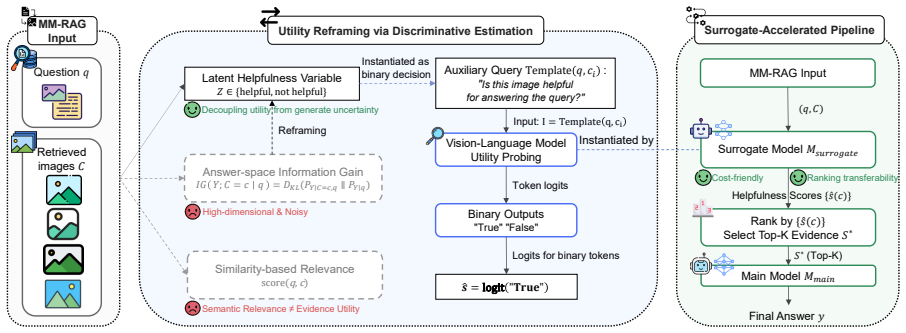
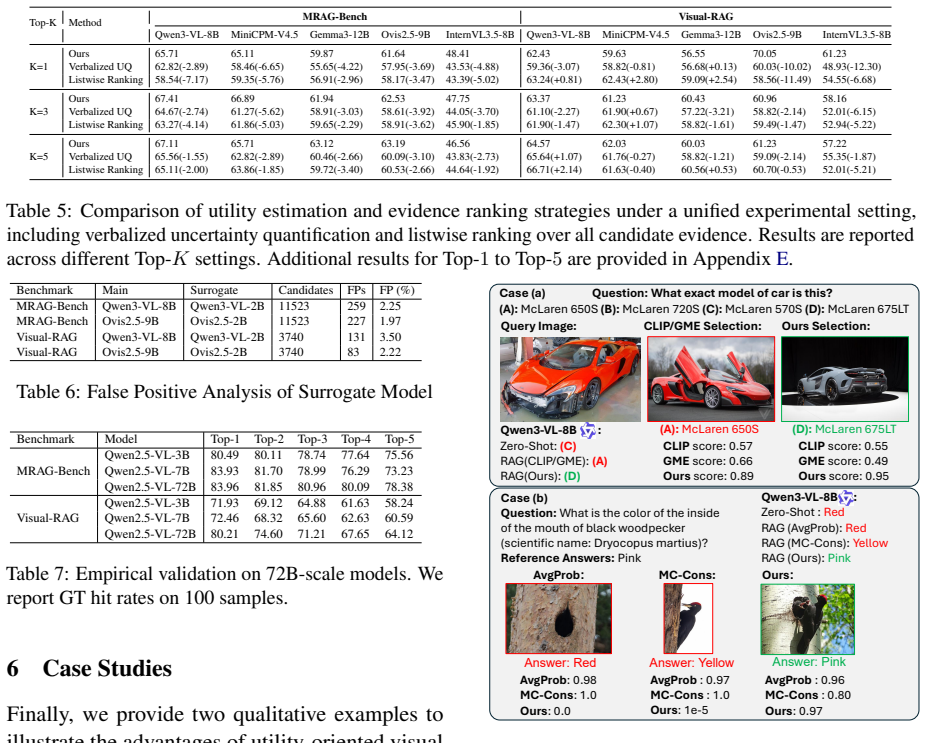
We reformulate multimodal evidence selection by defining evidence utility as the information gain induced on a model's output distribution. We introduce a latent notion of evidence helpfulness and show that ranking by information gain on this latent variable is equivalent to answer-space utility under mild assumptions. We propose a training-free, surrogate-accelerated framework using lightweight multimodal models.
What carries the argument
The latent notion of evidence helpfulness, which proxies answer-space utility through equivalence of information gain rankings.
If this is right
- Multimodal RAG pipelines can avoid exhaustive answer-space computation when choosing visual evidence.
- The approach yields higher accuracy than semantic or similarity-based baselines on MRAG-Bench and Visual-RAG.
- No task-specific training is required, allowing immediate use across different model families.
- Evidence selection becomes grounded in measurable information gain rather than surface similarity.
Where Pith is reading between the lines
- The same latent-proxy idea could be tested in text-only RAG or audio-visual settings where answer spaces are similarly large.
- Relaxing the mild assumptions might allow direct extensions to open-ended generation tasks.
- Plugging the estimator into existing RAG retrieval loops could reduce token usage in visual question answering.
Load-bearing premise
The mild assumptions that equate information gain on the latent helpfulness variable with direct answer-space utility.
What would settle it
A concrete case or benchmark instance where the top-ranked evidence by latent information gain differs from the evidence that actually maximizes answer utility under full computation.
Figures


read the original abstract
Visual evidence selection is a critical component of multimodal retrieval-augmented generation (RAG), yet existing methods typically rely on semantic relevance or surface-level similarity, which are often misaligned with the actual utility of visual evidence for downstream reasoning. We reformulate multimodal evidence selection from an information-theoretic perspective by defining evidence utility as the information gain induced on a model's output distribution. To overcome the intractability of answer-space optimization, we introduce a latent notion of evidence helpfulness and theoretically show that, under mild assumptions, ranking evidence by information gain on this latent variable is equivalent to answer-space utility. We further propose a training-free, surrogate-accelerated framework that efficiently estimates evidence utility using lightweight multimodal models. Experiments on MRAG-Bench and Visual-RAG across multiple model families demonstrate that our method consistently outperforms state-of-the-art RAG baselines while achieving substantial reductions in computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that visual evidence selection in multimodal RAG can be reformulated information-theoretically by defining utility as information gain on the model's output distribution. It introduces a latent 'evidence helpfulness' variable and theoretically shows that, under mild assumptions, ranking evidence by IG on this latent variable is equivalent to answer-space utility. A training-free surrogate framework using lightweight multimodal models is proposed to estimate this utility efficiently, with experiments on MRAG-Bench and Visual-RAG showing consistent outperformance over SOTA baselines and reduced compute cost.
Significance. If the equivalence holds and the surrogate preserves rankings, the work provides a principled, utility-oriented alternative to semantic-similarity-based evidence selection in multimodal RAG. The training-free nature and reported efficiency gains could enable broader adoption across model families, improving downstream reasoning while lowering costs.
major comments (2)
- [§3] §3 (Theoretical Equivalence): The manuscript asserts that ranking by information gain on the latent evidence helpfulness variable is equivalent to answer-space utility 'under mild assumptions,' but supplies neither the explicit assumptions nor the proof steps. This is load-bearing because the entire surrogate framework rests on the equivalence transferring from the exact latent IG.
- [§4] §4 (Surrogate Framework): No analysis, bounds, or empirical checks are provided to confirm that the lightweight multimodal model's IG estimates preserve the ranking induced by the true latent variable (e.g., via monotonicity or bounded error). Without this, the practical method may not inherit the claimed equivalence, undermining the central contribution.
minor comments (2)
- [Abstract] Abstract and §5: Experimental claims are summarized without naming specific baselines, controls, or statistical tests; adding these details would strengthen readability.
- [§3] Notation: The definition of the latent variable and its relation to the output distribution should be formalized with an equation early in §3 to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which help strengthen the theoretical clarity and empirical validation of our work. We address each major comment point-by-point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [§3] §3 (Theoretical Equivalence): The manuscript asserts that ranking by information gain on the latent evidence helpfulness variable is equivalent to answer-space utility 'under mild assumptions,' but supplies neither the explicit assumptions nor the proof steps. This is load-bearing because the entire surrogate framework rests on the equivalence transferring from the exact latent IG.
Authors: We agree that the explicit assumptions and full proof steps were not provided in the main text. In the revised version, we will expand §3 with a dedicated subsection that states the mild assumptions (conditional independence of the latent helpfulness variable from the answer given the evidence, and monotonicity of information gain under the output distribution) and includes the complete proof of ranking equivalence. A new appendix will contain the full derivation for transparency. revision: yes
-
Referee: [§4] §4 (Surrogate Framework): No analysis, bounds, or empirical checks are provided to confirm that the lightweight multimodal model's IG estimates preserve the ranking induced by the true latent variable (e.g., via monotonicity or bounded error). Without this, the practical method may not inherit the claimed equivalence, undermining the central contribution.
Authors: We acknowledge the absence of such analysis in the current manuscript. The revised version will augment §4 with: (i) a brief theoretical discussion of approximation error bounds for the surrogate, (ii) new empirical results reporting rank correlation (Kendall's tau and Spearman's rho) between surrogate and oracle utility estimates on held-out data from MRAG-Bench, and (iii) a sensitivity study confirming ranking preservation. These additions will directly address the inheritance of the theoretical equivalence. revision: yes
Circularity Check
Theoretical equivalence derived from information theory; no reduction to self-definition or fitted inputs
full rationale
The paper defines evidence utility via information gain on the output distribution and introduces a latent helpfulness variable, claiming equivalence under mild assumptions. This is presented as a theoretical derivation rather than a self-referential definition where the result is forced by construction. No equations reduce the ranking equivalence to a fitted parameter or prior self-citation chain. The surrogate estimation is training-free and separate from the theoretical claim. A low score of 2 accounts for possible minor unexamined self-citations in the full text that do not bear the central load.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption mild assumptions under which latent-variable ranking equals answer-space utility
invented entities (1)
-
latent evidence helpfulness variable
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2410.05160 , year=
Vlm2vec: Training vision-language models for massive multimodal embedding tasks , author=. arXiv preprint arXiv:2410.05160 , year=
-
[2]
arXiv preprint arXiv:2507.04590 , year=
Vlm2vec-v2: Advancing multimodal embedding for videos, images, and visual documents , author=. arXiv preprint arXiv:2507.04590 , year=
-
[3]
Megapairs: Massive data synthesis for universal multimodal retrieval , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[4]
arXiv preprint arXiv:2407.12580 , year=
E5-v: Universal embeddings with multimodal large language models , author=. arXiv preprint arXiv:2407.12580 , year=
-
[5]
GME: Improving Universal Multimodal Retrieval by Multimodal
Zhang, Xin and Zhang, Yanzhao and Xie, Wen and Li, Mingxin and Dai, Ziqi and Long, Dingkun and Xie, Pengjun and Zhang, Meishan and Li, Wenjie and Zhang, Min , journal=. GME: Improving Universal Multimodal Retrieval by Multimodal
-
[6]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Lamra: Large multimodal model as your advanced retrieval assistant , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[7]
arXiv preprint arXiv:2510.13515 , year=
Unime-v2: Mllm-as-a-judge for universal multimodal embedding learning , author=. arXiv preprint arXiv:2510.13515 , year=
-
[8]
International Conference on Machine Learning , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Reproducible scaling laws for contrastive language-image learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[10]
Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features , author=. arXiv preprint arXiv:2502.14786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2410.08182 , year=
Mrag-bench: Vision-centric evaluation for retrieval-augmented multimodal models , author=. arXiv preprint arXiv:2410.08182 , year=
-
[12]
arXiv preprint arXiv:2502.16636 , year=
Visual-rag: Benchmarking text-to-image retrieval augmented generation for visual knowledge intensive queries , author=. arXiv preprint arXiv:2502.16636 , year=
-
[13]
arXiv preprint arXiv:2411.02571 , year=
Mm-embed: Universal multimodal retrieval with multimodal llms , author=. arXiv preprint arXiv:2411.02571 , year=
-
[14]
arXiv preprint arXiv:2407.21439 , year=
Mllm is a strong reranker: Advancing multimodal retrieval-augmented generation via knowledge-enhanced reranking and noise-injected training , author=. arXiv preprint arXiv:2407.21439 , year=
-
[15]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Murag: Multimodal retrieval-augmented generator for open question answering over images and text , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2022
-
[16]
Advances in Neural Information Processing Systems , volume=
Align before fuse: Vision and language representation learning with momentum distillation , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
International Conference on Machine Learning , pages=
Scaling up visual and vision-language representation learning with noisy text supervision , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[18]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author=. arXiv preprint arXiv:2302.09664 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Active retrieval augmented generation , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[20]
arXiv preprint arXiv:2505.07459 , year=
Why Uncertainty Estimation Methods Fall Short in RAG: An Axiomatic Analysis , author=. arXiv preprint arXiv:2505.07459 , year=
-
[21]
arXiv preprint arXiv:2510.11483 , year=
Uncertainty Quantification for Retrieval-Augmented Reasoning , author=. arXiv preprint arXiv:2510.11483 , year=
-
[22]
Proceedings of the 24th Workshop on Biomedical Language Processing , pages=
Understanding the impact of confidence in retrieval augmented generation: A case study in the medical domain , author=. Proceedings of the 24th Workshop on Biomedical Language Processing , pages=
-
[23]
arXiv preprint arXiv:2502.18108 , year=
Uncertainty Quantification in Retrieval Augmented Question Answering , author=. arXiv preprint arXiv:2502.18108 , year=
-
[24]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Frontiers in Public Health , volume=
MEGA-RAG: a retrieval-augmented generation framework with multi-evidence guided answer refinement for mitigating hallucinations of LLMs in public health , author=. Frontiers in Public Health , volume=. 2025 , publisher=
work page 2025
-
[26]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv preprint arXiv:2305.19187 , year=
Generating with confidence: Uncertainty quantification for black-box large language models , author=. arXiv preprint arXiv:2305.19187 , year=
-
[28]
arXiv preprint arXiv:2104.06039 , year=
Multimodalqa: Complex question answering over text, tables and images , author=. arXiv preprint arXiv:2104.06039 , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
Visual instruction tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
- [31]
-
[32]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
arXiv preprint arXiv:2509.18154 , year=
Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe , author=. arXiv preprint arXiv:2509.18154 , year=
-
[35]
Ovis2. 5 technical report , author=. arXiv preprint arXiv:2508.11737 , year=
-
[36]
Retrieval-augmented generation for knowledge-intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-augmented generation for knowledge-intensive. Advances in Neural Information Processing Systems , volume=
-
[37]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
arXiv preprint arXiv:2504.08748 , year=
A survey of multimodal retrieval-augmented generation , author=. arXiv preprint arXiv:2504.08748 , year=
-
[39]
arXiv preprint arXiv:2501.03995 , year=
Rag-check: Evaluating multimodal retrieval augmented generation performance , author=. arXiv preprint arXiv:2501.03995 , year=
-
[40]
Visual haystacks: A vision-centric needle-in-a-haystack benchmark , author=. arXiv preprint arXiv:2407.13766 , year=
-
[41]
Proceedings of the AAAI conference on artificial intelligence , volume=
An empirical study of gpt-3 for few-shot knowledge-based vqa , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[42]
Seeing beyond: Enhancing visual question answering with multi-modal retrieval , author=. Proceedings of the 31st International Conference on Computational Linguistics: Industry Track , pages=
-
[43]
arXiv preprint arXiv:2507.04480 , year=
Source Attribution in Retrieval-Augmented Generation , author=. arXiv preprint arXiv:2507.04480 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.