Recognition: no theorem link
What Limits Vision-and-Language Navigation ?
Pith reviewed 2026-05-14 17:55 UTC · model grok-4.3
The pith
StereoNav uses target-location priors and stereo vision to achieve robust real-world vision-and-language navigation with fewer parameters and less data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
StereoNav achieves state-of-the-art egocentric RGB performance on R2R-CE and RxR-CE with SR and SPL scores of 81.1 percent and 68.3 percent, and 67.5 percent and 52.0 percent respectively, by introducing target-location priors that remain invariant across simulation-to-real domain shifts and by leveraging stereo vision to construct a unified semantic-geometric representation that supports precise action prediction despite motion blur and illumination changes.
What carries the argument
Target-location priors, which serve as a persistent visual bridge providing stable, domain-invariant guidance, together with stereo vision that unifies semantics and geometry into a single depth-aware representation for action prediction.
If this is right
- Navigation succeeds at higher rates on standard VLN-CE benchmarks while using fewer parameters and less training data than scaling-based methods.
- Robots maintain reliable performance in complex unstructured environments where monocular approaches degrade.
- Vague instructions are handled more gracefully because the priors supply persistent spatial grounding.
- Perceptual robustness for embodied tasks can be obtained without massive increases in model size or data volume.
Where Pith is reading between the lines
- The same priors and stereo mechanism could be applied to other embodied tasks such as object manipulation in changing environments.
- Explicit stereo depth may prove more reliable than learned monocular depth for navigation under real-world blur and lighting variation.
- Testing whether the priors generalize to dynamic obstacles not present in training would reveal the limits of the invariance assumption.
Load-bearing premise
Target-location priors remain useful and unchanged when moving from simulated training to physical robot execution, and stereo cameras reliably supply depth cues that overcome motion blur and lighting shifts without extra calibration.
What would settle it
A real-world robotic deployment in which StereoNav's success rate falls below that of prior monocular scaling-based methods under strong illumination changes or fast motion would falsify the claim that these priors and stereo cues suffice for robust navigation.
Figures










read the original abstract
Vision-and-Language Navigation (VLN) is a cornerstone of embodied intelligence. However, current agents often suffer from significant performance degradation when transitioning from simulation to real-world deployment, primarily due to perceptual instability (e.g., lighting variations and motion blur) and under-specified instructions. While existing methods attempt to bridge this gap by scaling up model size and training data, we argue that the bottleneck lies in the lack of robust spatial grounding and cross-domain priors. In this paper, we propose StereoNav, a robust Vision-Language-Action framework designed to enhance real-world navigation consistency. To address the inherent gap between synthetic training and physical execution, we introduce Target-Location Priors as a persistent bridge. These priors provide stable visual guidance that remains invariant across domains, effectively grounding the agent even when instructions are vague. Furthermore, to mitigate visual disturbances like motion blur and illumination shifts, StereoNav leverages stereo vision to construct a unified representation of semantics and geometry, enabling precise action prediction through enhanced depth awareness. Extensive experiments on R2R-CE and RxR-CE demonstrate that StereoNav achieves state-of-the-art egocentric RGB performance, with SR and SPL scores of 81.1% and 68.3%, and 67.5% and 52.0%, respectively, while using significantly fewer parameters and less training data than prior scaling-based approaches. More importantly, real-world robotic deployments confirm that StereoNav substantially improves navigation reliability in complex, unstructured environments. Project page: https://yunheng-wang.github.io/stereonav-public.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StereoNav, a Vision-Language-Action framework for VLN that incorporates Target-Location Priors as a domain-invariant bridge between simulation and real-world execution and uses stereo vision to build a unified semantic-geometric representation. It reports SOTA egocentric RGB results on R2R-CE (SR 81.1%, SPL 68.3%) and RxR-CE (SR 67.5%, SPL 52.0%) with fewer parameters and less training data than prior scaling approaches, and asserts that real-world robotic deployments demonstrate substantially improved navigation reliability in unstructured environments.
Significance. If the Target-Location Priors can be shown to be robustly invariant and the real-world gains are supported by quantitative metrics and ablations, the work would offer a meaningful alternative to pure scaling in embodied navigation by emphasizing geometric priors and stereo depth cues. The reported benchmark numbers and parameter efficiency are notable strengths, but the absence of supporting details on the priors and physical experiments currently prevents a full assessment of impact.
major comments (3)
- [Abstract] Abstract and method description: Target-Location Priors are presented as providing 'stable visual guidance that remains invariant across domains' without an explicit mathematical formulation, computation procedure, or fitting details, leaving their contribution to sim-to-real transfer unverified.
- [Real-world experiments] Real-world robotic deployments section: the claim of 'substantially improves navigation reliability' rests on qualitative statements only; no quantitative metrics (SR, SPL, failure counts, or comparisons against baselines on the same robot and environments) are supplied.
- [Experiments] Experiments section: the reported SR/SPL scores on R2R-CE and RxR-CE lack error bars, ablation tables isolating the priors versus stereo depth, and any description of how the priors are derived or validated for invariance.
minor comments (1)
- [Abstract] The project page URL in the abstract contains a redundant '.github.io' suffix that should be corrected.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate the requested details and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: Target-Location Priors are presented as providing 'stable visual guidance that remains invariant across domains' without an explicit mathematical formulation, computation procedure, or fitting details, leaving their contribution to sim-to-real transfer unverified.
Authors: We agree that the current presentation lacks sufficient technical detail. In the revision we will add an explicit mathematical definition of the Target-Location Priors (formulated as a persistent 3D semantic-geometric embedding derived from stereo disparity and semantic segmentation), the exact computation pipeline, and the fitting/validation procedure used to demonstrate cross-domain invariance. These additions will directly substantiate their role in sim-to-real transfer. revision: yes
-
Referee: [Real-world experiments] Real-world robotic deployments section: the claim of 'substantially improves navigation reliability' rests on qualitative statements only; no quantitative metrics (SR, SPL, failure counts, or comparisons against baselines on the same robot and environments) are supplied.
Authors: The referee correctly notes that only qualitative statements are currently provided. We will expand the real-world section with quantitative results (success rate, SPL, failure counts, and head-to-head comparisons against baselines) collected on the same robot and environments. These metrics will be reported alongside the existing qualitative observations. revision: yes
-
Referee: [Experiments] Experiments section: the reported SR/SPL scores on R2R-CE and RxR-CE lack error bars, ablation tables isolating the priors versus stereo depth, and any description of how the priors are derived or validated for invariance.
Authors: We will revise the experiments section to include error bars computed over multiple random seeds for all SR/SPL numbers. We will also add ablation tables that separately quantify the contribution of Target-Location Priors versus stereo depth cues, together with a detailed derivation of the priors and quantitative validation of their domain invariance. revision: yes
Circularity Check
No circularity: claims rest on empirical results and conceptual priors without self-referential reduction
full rationale
The provided manuscript text introduces Target-Location Priors as an asserted invariant bridge and leverages stereo vision for unified semantic-geometric representations, but contains no equations, fitted parameters renamed as predictions, or self-citations that reduce the central performance claims (SR/SPL on R2R-CE/RxR-CE or real-world reliability) to the inputs by construction. The invariance statement is presented as a design choice rather than derived from the same training distribution in a tautological loop, and no uniqueness theorems or ansatzes are smuggled via prior self-work. The derivation chain therefore remains self-contained against external benchmarks, with results framed as experimental outcomes.
Axiom & Free-Parameter Ledger
free parameters (1)
- Target-Location Priors
axioms (1)
- domain assumption Stereo vision supplies reliable depth that remains useful under motion blur and lighting variation
invented entities (1)
-
Target-Location Priors
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Vision-and-language navigation: A survey of tasks, methods, and future directions
Jing Gu, Eliana Stefani, Qi Wu, Jesse Thomason, and Xin Eric Wang. Vision-and-language navigation: A survey of tasks, methods, and future directions. InAnnual Meeting of the Association for Computational Linguistics (ACL), pages 7606–7623, 2022
2022
-
[2]
Yue Zhang, Ziqiao Ma, Jialu Li, Yanyuan Qiao, Zun Wang, Joyce Chai, Qi Wu, Mohit Bansal, and Parisa Kordjamshidi. Vision-and-language navigation today and tomorrow: A survey in the era of foundation models.arXiv preprint arXiv:2407.07035, 2024
-
[3]
Homerobot: Open-vocabulary mobile manipulation.arXiv preprint arXiv:2306.11565, 2024
Sriram Yenamandra, Arun Ramachandran, Karmesh Yadav, Austin Wang, Mukul Khanna, Theophile Gervet, Tsung-Yen Yang, Vidhi Jain, Alexander William Clegg, John Turner, Zsolt Kira, Manolis Savva, Angel Chang, Devendra Singh Chaplot, Dhruv Batra, Roozbeh Mottaghi, Yonatan Bisk, and Chris Paxton. Homerobot: Open-vocabulary mobile manipulation.arXiv preprint arXi...
-
[4]
Navila: Legged robot vision-language-action model for navigation
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Xueyan Zou, Jan Kautz, Erdem Biyik, Hongxu Yin, Sifei Liu, and Xiaolong Wang. Navila: Legged robot vision-language-action model for navigation. InRobotics: Science and Systems (RSS), 2025
2025
-
[5]
Navid: Video-based vlm plans the next step for vision-and-language navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and He Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation. InRobotics: Science and Systems (RSS), 2024
2024
-
[6]
Streamvln: Streaming vision-and-language navigation via slowfast context modeling,
Meng Wei, Chenyang Wan, Xiqian Yu, Tai Wang, Yuqiang Yang, Xiaohan Mao, Chenming Zhu, Wenzhe Cai, Hanqing Wang, Yilun Chen, et al. Streamvln: Streaming vision-and-language navigation via slowfast context modeling.arXiv preprint arXiv:2507.05240, 2025
-
[7]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: A comprehensive benchmark for multi-task long video understanding.arXiv preprint arXiv:2406.04264, 2024
work page internal anchor Pith review arXiv 2024
-
[8]
Vision-and-language navigation: Interpret- ing visually-grounded navigation instructions in real environments
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sunderhauf, Ian Reid, Stephen Gould, and Anton van den Hengel. Vision-and-language navigation: Interpret- ing visually-grounded navigation instructions in real environments. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3674–3683, 2018
2018
-
[9]
Matterport3d: Learning from RGB-D data in indoor environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from RGB-D data in indoor environments. InInternational Conference on 3D Vision (3DV), 2017
2017
-
[10]
Beyond the nav- graph: Vision and language navigation in continuous environments
Jacob Krantz, Erik Wijmans, Arjun Majundar, Dhruv Batra, and Stefan Lee. Beyond the nav- graph: Vision and language navigation in continuous environments. InEuropean Conference on Computer Vision (ECCV), pages 104–120, 2020
2020
-
[11]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A platform for embodied ai research. InIEEE International Conference on Computer Vision (ICCV), pages 9339–9347, 2019
2019
-
[12]
Available: https://arxiv.org/abs/2512.08186
Meng Wei, Chenyang Wan, Jiaqi Peng, Xiqian Yu, Yuqiang Yang, Delin Feng, Wenzhe Cai, Chenming Zhu, Tai Wang, Jiangmiao Pang, and Xihui Liu. Ground slow, move fast: A dual- system foundation model for generalizable vision-and-language navigation.arXiv preprint arXiv:2512.08186, 2025
-
[13]
Zehua Fan, Wenqi Lyu, Wenxuan Song, Linge Zhao, Yifei Yang, Xi Wang, Junjie He, Lida Huang, Haiyan Liu, Bingchuan Sun, Guangjun Bao, Xuanyao Mao, Liang Xu, Yan Wang, and Feng Gao. Prospect: Unified streaming vision-language navigation via semantic–spatial fusion and latent predictive representation.arXiv preprint arXiv:2603.03739, 2026
-
[14]
Xiangchen Liu, Hanghan Zheng, Jeil Jeong, Minsung Yoon, Lin Zhao, Zhide Zhong, Haoang Li, and Sung-Eui Yoon. Dygeovln: Infusing dynamic geometry foundation model into vision- language navigation.arXiv preprint arXiv:2603.21269, 2026. 10
-
[15]
Internvla-n1: An open dual-system navigation foundation model with learned latent plans
InternNav Team. Internvla-n1: An open dual-system navigation foundation model with learned latent plans. 2025
2025
-
[16]
Embodied navigation foundation model.arXiv preprint arXiv:2509.12129, 2025
Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Jiahang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, et al. Embodied navigation foundation model.arXiv preprint arXiv:2509.12129, 2025
-
[17]
Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks. InRobotics: Science and Systems (RSS), 2024
2024
-
[18]
Janusvln: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation
Shuang Zeng, Dekang Qi, Xinyuan Chang, Feng Xiong, Shichao Xie, Xiaolong Wu, Shiyi Liang, Mu Xu, and Xing Wei. Janusvln: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[19]
Fei Liu, Shichao Xie, Minghua Luo, Zedong Chu, Junjun Hu, Xiaolong Wu, and Mu Xu. Navforesee: A unified vision-language world model for hierarchical planning and dual-horizon navigation prediction.arXiv preprint arXiv:2512.01550, 2026
-
[20]
AstraNav-World: World Model for Foresight Control and Consistency
Junjun Hu, Jintao Chen, Haochen Bai, Minghua Luo, Shichao Xie, Ziyi Chen, Fei Liu, Zedong Chu, Xinda Xue, Botao Ren, Xiaolong Wu, Mu Xu, and Shanghang Zhang. Astranav-world: World model for foresight control and consistency.arXiv preprint arXiv:2512.21714, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Jiahang Liu, Tianyu Xu, Jiawei Chen, Lu Yue, Jiazhao Zhang, Zhiyong Wang, Minghan Li, Qisheng Zhao, Anqi Li, Qi Su, Zhizheng Zhang, and He Wang. Span-nav: Generalized spatial awareness for versatile vision-language navigation.arXiv preprint arXiv:2603.09163, 2026
- [22]
-
[23]
Haodong Hong, Sen Wang, Zi Huang, Qi Wu, and Jiajun Liu. Why only text: Empowering vision-and-language navigation with multi-modal prompts.arXiv preprint arXiv:2406.02208, 2024
-
[24]
Yubo Zhang, Hao Tan, and Mohit Bansal. Diagnosing the environment bias in vision-and- language navigation.arXiv preprint arXiv:2005.03086, 2020
-
[25]
Rethinking the embodied gap in vision-and-language navigation: A holistic study of physical and visual disparities
Liuyi Wang, Xinyuan Xia, Hui Zhao, Hanqing Wang, Tai Wang, Yilun Chen, Chengju Liu, Qijun Chen, and Jiangmiao Pang. Rethinking the embodied gap in vision-and-language navigation: A holistic study of physical and visual disparities. InIEEE International Conference on Computer Vision (ICCV), pages 9455–9465, 2025
2025
-
[26]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. InEuropean Conference on Computer Vision (ECCV), pages 323–340, 2024
2024
-
[28]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava- video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Vila: On pre-training for visual language models
Ji Lin, Hongxu Yin, Wei Ping, Yao Lu, Pavlo Molchanov, Andrew Tao, Huizi Mao, Jan Kautz, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models.arXiv preprint arXiv:2312.07533, 2023
-
[30]
Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4.arXiv preprint arXiv:2304.03277, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Zhuoyuan Yu, Yuxing Long, Zihan Yang, Chengyan Zeng, Hongwei Fan, Jiyao Zhang, and Hao Dong. Correctnav: Self-correction flywheel empowers vision-language-action navigation model.arXiv preprint arXiv:2508.10416, 2025. 11
-
[32]
Taj Jones-McCormick, Aukosh Jagannath, and Subhabrata Sen. Provable benefits of un- supervised pre-training and transfer learning via single-index models.arXiv preprint arXiv:2502.16849, 2025
-
[33]
Shunxin Wang, Raymond Veldhuis, Christoph Brune, and Nicola Strisciuglio. A survey on the robustness of computer vision models against common corruptions.arXiv preprint arXiv:2305.06024, 2024
-
[34]
Robustnav: Towards benchmarking robustness in embodied navigation
Prithvijit Chattopadhyay, Judy Hoffman, Roozbeh Mottaghi, and Ani Kembhavi. Robustnav: Towards benchmarking robustness in embodied navigation. InIEEE International Conference in Computer Vision (ICCV), pages 15691–15700, 2021
2021
-
[35]
Ajay Sridhar, Dhruv Shah, Catherine Glossop, and Sergey Levine. Nomad: Goal masked diffusion policies for navigation and exploration.arXiv preprint arXiv:2310.07896, 2023
-
[36]
Wenzhe Cai, Jiaqi Peng, Yuqiang Yang, Yujian Zhang, Meng Wei, Hanqing Wang, Yilun Chen, Tai Wang, and Jiangmiao Pang. Navdp: Learning sim-to-real navigation diffusion policy with privileged information guidance.arXiv preprint arXiv:2505.08712, 2025
-
[37]
Zihan Wang, Seungjun Lee, and Gim Hee Lee. Dynam3d: Dynamic layered 3d tokens empower vlm for vision-and-language navigation.arXiv preprint arXiv:2505.11383, 2025
-
[38]
Agentvln: Towards agentic vision-and-language navigation.arXiv preprint arXiv:2603.17670, 2026
Zihao Xin, Wentong Li, Yixuan Jiang, Ziyuan Huang, Bin Wang, Piji Li, Jianke Zhu, Jie Qin, and Sheng-Jun Huang. Agentvln: Towards agentic vision-and-language navigation.arXiv preprint arXiv:2603.17670, 2026
-
[39]
Navid-4d: Unleashing spatial intelligence in egocentric rgb-d videos for vision-and-language navigation
Haoran Liu, Weikang Wan, Xiqian Yu, Minghan Li, Jiazhao Zhang, Bo Zhao, Zhibo Chen, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Navid-4d: Unleashing spatial intelligence in egocentric rgb-d videos for vision-and-language navigation. InIEEE International Conference on Robotics and Automation (ICRA), pages 10607–10615, 2025
2025
-
[40]
Navmorph: A self-evolving world model for vision-and-language navigation in continuous environments
Junyu Gao Xuan Yao and Changsheng Xu. Navmorph: A self-evolving world model for vision-and-language navigation in continuous environments. InIEEE International Conference in Computer Vision (ICCV), pages 5536–5546, 2025
2025
-
[41]
Etpnav: Evolving topological planning for vision-language navigation in continuous environments
Dong An, Hanqing Wang, Wenguan Wang, Zun Wang, Yan Huang, Keji He, and Liang Wang. Etpnav: Evolving topological planning for vision-language navigation in continuous environments. InIEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024
2024
-
[42]
Liuyi Wang, Zongtao He, Jinlong Li, Ruihao Xia, Mengxian Hu, Chenpeng Yao, Chengju Liu, Yang Tang, and Qijun Chen. Clash: Collaborative large-small hierarchical framework for continuous vision-and-language navigation.arXiv preprint arXiv:2512.10360, 2025
-
[43]
Zihan Wang, Seungjun Lee, Guangzhao Dai, and Gim Hee Lee. D3d-vlp: Dynamic 3d vision-language-planning model for embodied grounding and navigation.arXiv preprint arXiv:2512.12622, 2025
-
[44]
Available: https://arxiv.org/abs/2512.20940
Shuhao Ye, Sitong Mao, Yuxiang Cui, Xuan Yu, Shichao Zhai, Wen Chen, Shunbo Zhou, Rong Xiong, and Yue Wang. Etp-r1: Evolving topological planning with reinforcement fine-tuning for vision-language navigation in continuous environments.arXiv preprint arXiv:2512.20940, 2025
-
[45]
P 3Nav: End-to-end perception, prediction and planning for vision-and-language navigation,
Tianfu Li, Wenbo Chen, Haoxuan Xu, Xinhu Zheng, and Haoang Li. P 3nav: End-to-end perception, prediction and planning for vision-and-language navigation.arXiv preprint arXiv:2603.17459, 2026
- [46]
-
[47]
Abot-n0: Technical report on the vla foundation model for versatile embodied navigation
Zedong Chu, Shichao Xie, Xiaolong Wu, Yanfen Shen, Minghua Luo, Zhengbo Wang, Fei Liu, Xiaoxu Leng, Junjun Hu, Mingyang Yin, Jia Lu, Yingnan Guo, Kai Yang, Jiawei Han, Xu Chen, et al. Abot-n0: Technical report on the vla foundation model for versatile embodied navigation. arXiv preprint arXiv:2602.11598, 2026. 12
-
[48]
Efficient-vln: A training-efficient vision-language navigation model,
Duo Zheng, Shijia Huang, Yanyang Li, and Liwei Wang. Efficient-vln: A training-efficient vision-language navigation model.arXiv preprint arXiv:2512.10310, 2025
-
[49]
Haoyuan Li, Rui Liu, Hehe Fan, and Yi Yang. Let’s reward step-by-step: Step-aware con- trastive alignment for vision-language navigation in continuous environments.arXiv preprint arXiv:2603.09740, 2026
-
[50]
Weiye Zhu, Zekai Zhang, Xiangchen Wang, Hewei Pan, Teng Wang, Tiantian Geng, Rongtao Xu, and Feng Zheng. Navida: Vision-language navigation with inverse dynamics augmentation. arXiv preprint arXiv:2601.18188, 2026
-
[51]
Decovln: Decoupling observation, reasoning, and correction for vision-and-language navigation
Zihao Xin, Wentong Li, Yixuan Jiang, Bin Wang, Runmin Cong, Jie Qin, and Shengjun Huang. Decovln: Decoupling observation, reasoning, and correction for vision-and-language navigation. arXiv preprint arXiv:2603.13133, 2026
-
[52]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Foundationstereo: Zero-shot stereo matching
Bowen Wen, Matthew Trepte, Joseph Aribido, Jan Kautz, Orazio Gallo, and Stan Birchfield. Foundationstereo: Zero-shot stereo matching. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5249–5260, 2025
2025
-
[55]
Open-nav: Exploring zero-shot vision-and-language navigation in continuous environment with open-source llms
Yanyuan Qiao, Wenqi Lyu, Hui Wang, Zixu Wang, Zerui Li, Yuan Zhang, Mingkui Tan, and Qi Wu. Open-nav: Exploring zero-shot vision-and-language navigation in continuous environment with open-source llms. InIEEE International Conference on Robotics and Automation (ICRA), pages 6710–6717, 2025
2025
-
[56]
Yunheng Wang, Yuetong Fang, Taowen Wang, Yixiao Feng, Yawen Tan, Shuning Zhang, Peiran Liu, Yiding Ji, and Renjing Xu. Dreamnav: A trajectory-based imaginative framework for zero-shot vision-and-language navigation.arXiv preprint arXiv:2509.11197, 2025
-
[57]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, et al. Gemini 2.5: Pushing the frontier with advanced reasoning.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Preset” column denotes the maximum sampling radius for generating the noisy prior, while “Actual
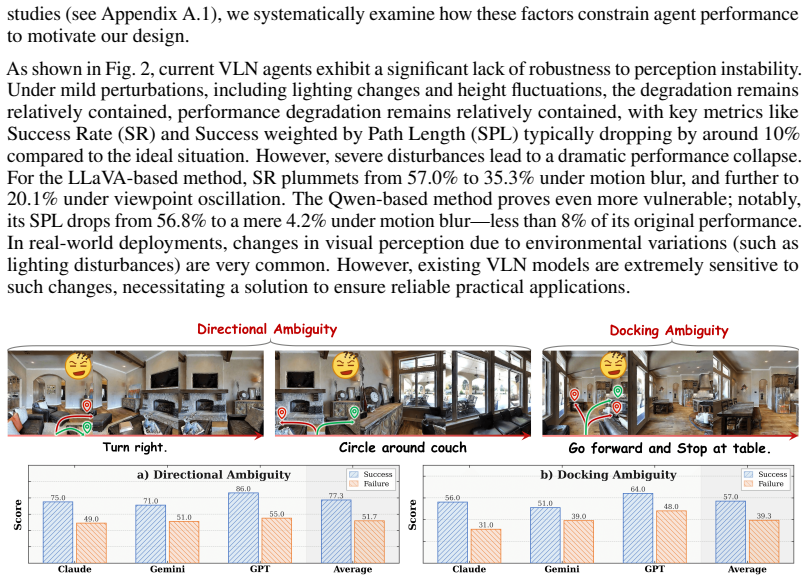
Anthropic. System card: Claude opus 4 and claude sonnet 4. https://www.anthropic.com/ claude-4-system-card. 13 A Details of the Pilot Studies A.1 Experimental Setup for Visual Uncertainty To examine whether the performance degradation of current VLN agents is associated with visual uncertainty, we conduct controlled pilot studies on two representative ope...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.