Recognition: unknown
Nonsmooth Set-Gradient Ascent to the Pareto Front via Layered Hypervolume and Magnitude Indicators
Pith reviewed 2026-05-14 17:42 UTC · model grok-4.3
The pith
Layered weighting of nondomination layers gives set-gradient ascent directions that improve the first Pareto front without compensation from deeper layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A nonsmooth set-gradient ascent method optimizes layered set indicators by evaluating a base indicator on successive nondomination layers and combining layer values with rapidly decreasing weights. This gives ascent directions to nondominated and dominated points while preventing deeper layers from compensating for deterioration of the first front. For the magnitude indicator an exact gradient is obtained as a linear combination of hypervolume gradients of projected shadow sets, so that for fixed objective dimension the magnitude gradients have the same asymptotic time complexity as hypervolume gradients.
What carries the argument
Layered set indicators formed by evaluating a base indicator (hypervolume or magnitude of the dominated set) on successive nondomination layers and aggregating with rapidly decreasing weights.
Load-bearing premise
Rapidly decreasing weights on successive nondomination layers suffice to isolate improvement on the first front, and chamberwise Lipschitz continuity holds for the finite-epsilon surrogates used in practice.
What would settle it
An example in which a layer switch causes the aggregated indicator to increase even though the first nondominated front has deteriorated, or a numerical case where the derived magnitude gradient fails to point toward improvement on the first front.
Figures


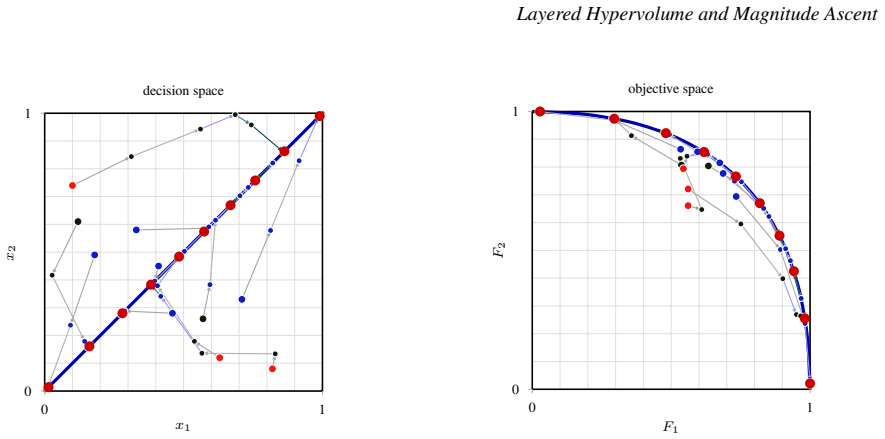
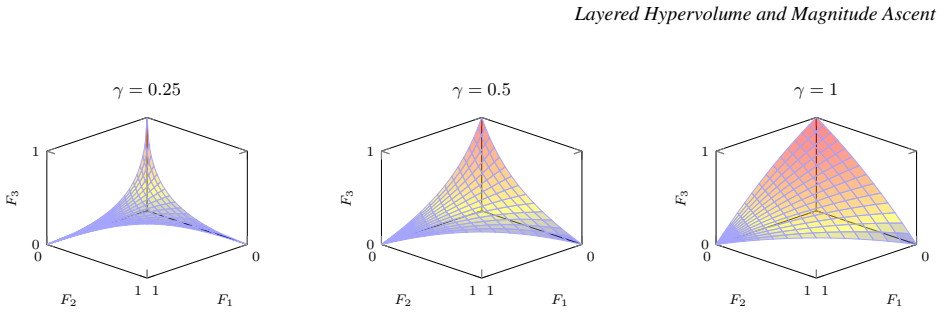


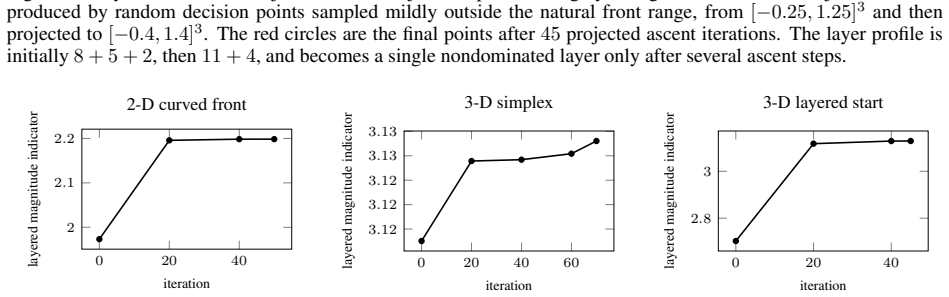



read the original abstract
A nonsmooth set-gradient ascent method is developed for moving finite approximation sets toward the Pareto front in multiobjective optimization. The method optimizes layered set indicators: a base indicator is evaluated on successive nondomination layers, and the layer values are combined with rapidly decreasing weights. This gives ascent directions to nondominated and dominated points while preventing deeper layers from compensating for deterioration of the first front. Two base indicators are treated: the hypervolume indicator and the magnitude indicator of the dominated set, whose expansion over coordinate projections contains extent, projected-area, and volume terms. The scalar objectives are nonsmooth because nondomination layers change combinatorially and the active orthogonal-union geometry changes piecewise. On fixed strata, where layer assignments and active geometry remain unchanged, the indicators are piecewise smooth and chamberwise continuous. For the magnitude indicator, an exact gradient formula is derived as a linear combination of hypervolume gradients of projected shadow sets. Thus, for fixed objective dimension, magnitude gradients have the same asymptotic time complexity as hypervolume gradients. Lexicographic layer aggregation is related to a unary infinitesimal encoding. For finite-$\epsilon$ surrogates, the main nonsmoothness mechanisms are isolated and chamberwise Lipschitz continuity on bounded sets is proved; a two-point counterexample shows that hard-layer scalarization is not globally continuous across layer switches. The theory motivates a projected finite-difference implementation with repulsion and recovery from stagnation. Numerical examples and reproducible code cover two- and three-objective settings, including objective-space tests, curved fronts, a supersphere benchmark, and traces comparing layered magnitude and hypervolume ascent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a nonsmooth set-gradient ascent method for moving finite approximation sets toward the Pareto front in multiobjective optimization. It optimizes layered set indicators by evaluating base indicators (hypervolume and magnitude of the dominated set) on successive nondomination layers and combining them with rapidly decreasing weights. This yields ascent directions for both nondominated and dominated points while preventing deeper layers from compensating for first-front deterioration. An exact gradient formula is derived for the magnitude indicator as a linear combination of hypervolume gradients of projected shadow sets, with the same asymptotic complexity as hypervolume gradients for fixed dimension. Chamberwise Lipschitz continuity on bounded sets is proved for finite-ε surrogates, a two-point counterexample demonstrates discontinuity of hard-layer scalarization at boundaries, and the approach is demonstrated numerically with reproducible code in two- and three-objective settings.
Significance. If the central claims hold, particularly the isolation of first-front improvement via weight decay and the exact gradient formula, the work offers a theoretically grounded extension of hypervolume-based set optimization that handles combinatorial nonsmoothness while preserving computational tractability. The reproducible code, parameter-free derivations for the magnitude gradient, and explicit treatment of layer switches constitute clear strengths that could influence practical algorithms for Pareto-front approximation.
major comments (3)
- [Abstract / Layered Indicator Construction] Abstract and theory section on layer aggregation: the claim that rapidly decreasing weights (e.g., 1/2^k) isolate first-front improvement is only sketched inside chambers; the chamberwise Lipschitz proof does not quantify the size of the discontinuity jump in the aggregated indicator relative to the decay rate when a point crosses a nondomination boundary during a finite-difference step, leaving open whether deeper-layer contributions can still dominate.
- [Magnitude Indicator Gradient Formula] Gradient derivation for magnitude indicator: the exact formula as a linear combination of projected hypervolume gradients is derived under fixed strata (unchanged layer assignments and active geometry); the extension to the full nonsmooth setting across combinatorial layer switches requires an additional bound showing that the directional derivative remains dominated by the first layer after weighting.
- [Nonsmoothness Mechanisms and Chamberwise Lipschitz Continuity] Continuity analysis: the two-point counterexample correctly shows discontinuity of hard-layer scalarization, yet the proof of chamberwise Lipschitz continuity on bounded sets for the finite-ε surrogates does not supply an explicit modulus that scales with the weight decay rate, which is load-bearing for the central guarantee that deeper layers cannot compensate for first-front deterioration.
minor comments (2)
- [Numerical Examples] The numerical examples section would benefit from quantitative tables reporting hypervolume or IGD values alongside the visual traces to allow direct comparison of convergence rates between layered magnitude and hypervolume ascent.
- [Preliminaries / Magnitude Indicator Definition] Notation for 'shadow sets' and 'orthogonal-union geometry' should be introduced with a short diagram or explicit definition in the preliminaries, as these terms are central to the magnitude-indicator expansion but appear without prior reference.
Simulated Author's Rebuttal
We thank the referee for the thorough reading and constructive feedback. The comments highlight opportunities to strengthen the quantification of the isolation property under weight decay and the handling of layer switches. We address each point below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract / Layered Indicator Construction] Abstract and theory section on layer aggregation: the claim that rapidly decreasing weights (e.g., 1/2^k) isolate first-front improvement is only sketched inside chambers; the chamberwise Lipschitz proof does not quantify the size of the discontinuity jump in the aggregated indicator relative to the decay rate when a point crosses a nondomination boundary during a finite-difference step, leaving open whether deeper-layer contributions can still dominate.
Authors: We agree that an explicit bound on the discontinuity jump relative to the decay rate would make the isolation argument fully rigorous. In the revision we will add a supporting lemma that bounds the jump size for any indicator value on bounded sets by a constant independent of the layer index; combined with the geometric decay of the weights (sum_{k>=2} w_k <= w_1 / 2 for w_k = 1/2^k), this shows that any deeper-layer contribution remains strictly smaller than a first-layer improvement of size epsilon, uniformly over finite-difference steps. The chamberwise Lipschitz proof will be updated to reference this bound. revision: yes
-
Referee: [Magnitude Indicator Gradient Formula] Gradient derivation for magnitude indicator: the exact formula as a linear combination of projected hypervolume gradients is derived under fixed strata (unchanged layer assignments and active geometry); the extension to the full nonsmooth setting across combinatorial layer switches requires an additional bound showing that the directional derivative remains dominated by the first layer after weighting.
Authors: The exact gradient formula is stated for fixed strata, as the referee correctly notes. For the nonsmooth case we rely on the finite-epsilon surrogate and the same weight-decay isolation already used for the indicator itself. In revision we will insert a short paragraph after the gradient derivation showing that the directional derivative of the aggregated magnitude indicator across a layer switch is bounded by the first-layer term plus a remainder controlled by the same geometric-series argument used for the Lipschitz modulus; this establishes dominance without requiring a new closed-form expression across switches. revision: partial
-
Referee: [Nonsmoothness Mechanisms and Chamberwise Lipschitz Continuity] Continuity analysis: the two-point counterexample correctly shows discontinuity of hard-layer scalarization, yet the proof of chamberwise Lipschitz continuity on bounded sets for the finite-ε surrogates does not supply an explicit modulus that scales with the weight decay rate, which is load-bearing for the central guarantee that deeper layers cannot compensate for first-front deterioration.
Authors: The existing proof establishes chamberwise Lipschitz continuity but leaves the modulus implicit. We will revise the proof to derive an explicit modulus that factors in the weight decay: the overall Lipschitz constant is at most L_1 + sum_{k>=2} w_k L_k where L_k are the per-layer constants (bounded on compact sets) and the sum is controlled by the geometric series. This makes the scaling with the decay rate transparent and directly supports the claim that deeper layers cannot compensate for first-front changes. revision: yes
Circularity Check
No significant circularity; derivations and proofs are independent of inputs
full rationale
The paper presents a derivation of an exact gradient formula for the magnitude indicator as a linear combination of hypervolume gradients of projected shadow sets, along with a proof of chamberwise Lipschitz continuity on bounded sets for finite-epsilon surrogates. These steps are constructed from first principles on fixed strata and do not reduce by definition or fitting to the target results. Layered weighting with rapid decay is motivated to isolate the first front but is not shown to be equivalent to its own inputs; the two-point counterexample for discontinuity is explicitly acknowledged rather than hidden. No self-citation chains or ansatz smuggling appear load-bearing in the abstract or described claims. The central results remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Indicators are piecewise smooth on fixed strata where layer assignments and active geometry remain unchanged.
Reference graph
Works this paper leans on
-
[1]
F. H. Clarke,Optimization and Nonsmooth Analysis, Classics in Applied Mathematics 5, SIAM, Philadelphia, 1990
1990
-
[2]
Hypervolume-Based Multiobjective Optimization: Theoretical Foundations and Practical Implications,
A. Auger, J. Bader, D. Brockhoff, and E. Zitzler, “Hypervolume-Based Multiobjective Optimization: Theoretical Foundations and Practical Implications,”Theoretical Computer Science425(2012), 75–103. doi:10.1016/j.tcs.2011.03.012
-
[3]
Direct Multisearch for Multiobjective Opti- mization,
A. L. Custódio, J. F. A. Madeira, A. I. F. Vaz, and L. N. Vicente, “Direct Multisearch for Multiobjective Opti- mization,”SIAM Journal on Optimization21(3) (2011), 1109–1140. doi:10.1137/10079731X
-
[4]
Deb,Multi-Objective Optimization Using Evolutionary Algorithms, Wiley, Chichester, 2001
K. Deb,Multi-Objective Optimization Using Evolutionary Algorithms, Wiley, Chichester, 2001
2001
-
[5]
Multi-objective Optimization by Uncrowded Hypervolume Gradient Ascent,
T. M. Deist, S. C. Maree, T. Alderliesten, and P. A. N. Bosman, “Multi-objective Optimization by Uncrowded Hypervolume Gradient Ascent,” inParallel Problem Solving from Nature – PPSN XVI, Lecture Notes in Com- puter Science 12270, 2020, pp. 186–200. doi:10.1007/978-3-030-58115-2_13
-
[6]
A. Deutz, M. Emmerich, and H. Wang, “The Hypervolume Indicator Hessian Matrix: Analytical Expression, Computational Time Complexity, and Sparsity,” inEvolutionary Multi-Criterion Optimization, Lecture Notes in Computer Science 13970, 2023, pp. 405–418. doi:10.1007/978-3-031-27250-9_29
-
[7]
M. Emmerich, A. Deutz, and N. Beume, “Gradient-Based/Evolutionary Relay Hybrid for Computing Pareto Front Approximations Maximizing the S-Metric,” inHybrid Metaheuristics, Lecture Notes in Computer Sci- ence 4771, 2007, pp. 140–156. doi:10.1007/978-3-540-75514-2_11
-
[8]
M. T. M. Emmerich,The Magnitude of Dominated Sets: A Pareto Compliant Indicator Grounded in Metric Geometry, arXiv:2604.18147 [math.OC], 2026. doi:10.48550/arXiv.2604.18147. 25 Layered Hypervolume and Magnitude Ascent
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.18147 2026
-
[9]
Y . D. Sergeyev, “Numerical Infinities and Infinitesimals: Methodology, Applications, and Repercussions on Two Hilbert Problems,”EMS Surveys in Mathematical Sciences4(2) (2017), 219–320. doi:10.4171/EMSS/4-2-3
-
[10]
K. Miettinen and M. M. Mäkelä, “An Interactive Method for Nonsmooth Multiobjective Optimiza- tion with an Application to Optimal Control,”Optimization Methods and Software2(1) (1993), 31–44. doi:10.1080/10556789308805533
-
[11]
The Magnitude of Metric Spaces,
T. Leinster, “The Magnitude of Metric Spaces,”Documenta Mathematica18(2013), 857–905
2013
-
[12]
A Greedy Hypervolume Polychotomic Scheme for Multi- objective Combinatorial Optimization,
G. Lopes, K. Klamroth, and L. Paquete, “A Greedy Hypervolume Polychotomic Scheme for Multi- objective Combinatorial Optimization,”Computers & Operations Research183(2025), Article 107140. doi:10.1016/j.cor.2025.107140
-
[13]
Computing Representations Using Hypervolume Scalarizations,
L. Paquete, B. Schulze, M. Stiglmayr, and A. C. Lourenço, “Computing Representations Using Hypervolume Scalarizations,”Computers & Operations Research137(2022), Article 105349. doi:10.1016/j.cor.2021.105349
-
[14]
Time Complexity and Zeros of the Hypervolume Indicator Gradient Field,
M. Emmerich and A. Deutz, “Time Complexity and Zeros of the Hypervolume Indicator Gradient Field,” in EVOLVE – A Bridge between Probability, Set Oriented Numerics, and Evolutionary Computation III, Studies in Computational Intelligence 500, 2014, pp. 169–193. doi:10.1007/978-3-319-01460-9_8
-
[15]
The Hypervolume Indicator: Computational Problems and Algorithms,
A. P. Guerreiro, C. M. Fonseca, and L. Paquete, “The Hypervolume Indicator: Computational Problems and Algorithms,”ACM Computing Surveys54(6) (2021), Article 119, 42 pp. doi:10.1145/3453474
-
[16]
L. Uribe, J. M. Bogoya, A. Vargas, A. Lara, G. Rudolph, and O. Schütze, “A Set Based Newton Method for the Averaged Hausdorff Distance for Multi-Objective Reference Set Problems,”Mathematics8(10) (2020), Ar- ticle 1822. doi:10.3390/math8101822
-
[17]
Multiobjective Evolutionary Algorithms: A Comparative Case Study and the Strength Pareto Approach,
E. Zitzler and L. Thiele, “Multiobjective Evolutionary Algorithms: A Comparative Case Study and the Strength Pareto Approach,”IEEE Transactions on Evolutionary Computation3(4) (1999), 257–271. doi:10.1109/4235.797969
-
[18]
On Gradient-Based and Swarm-Based Algorithms for Set-Oriented Bicriteria Optimization,
W. Verhoef, A. H. Deutz, and M. T. M. Emmerich, “On Gradient-Based and Swarm-Based Algorithms for Set-Oriented Bicriteria Optimization,” inEVOLVE – A Bridge between Probability, Set Oriented Numerics, and Evolutionary Computation VI, Advances in Intelligent Systems and Computing 674, 2018, pp. 18–36. doi:10.1007/978-3-319-69710-9_2
-
[19]
On Steering Dominated Points in Hypervolume Indicator Gradient Ascent for Bi-Objective Optimization,
H. Wang, Y . Ren, A. Deutz, and M. Emmerich, “On Steering Dominated Points in Hypervolume Indicator Gradient Ascent for Bi-Objective Optimization,” inNEO 2015, Studies in Computational Intelligence 663, 2017, pp. 175–203. doi:10.1007/978-3-319-44003-3_8
-
[20]
Hypervolume Indicator Gradient Ascent Multi-Objective Op- timization,
H. Wang, A. Deutz, T. Bäck, and M. Emmerich, “Hypervolume Indicator Gradient Ascent Multi-Objective Op- timization,” inEvolutionary Multi-Criterion Optimization, Lecture Notes in Computer Science 10173, 2017, pp. 654–669. doi:10.1007/978-3-319-54157-0_44
-
[21]
The Hypervolume Newton Method for Constrained Multi-Objective Optimization Problems,
H. Wang, M. Emmerich, A. Deutz, V . A. S. Hernández, and O. Schütze, “The Hypervolume Newton Method for Constrained Multi-Objective Optimization Problems,”Mathematical and Computational Applications28(1) (2023), Article 10. doi:10.3390/mca28010010. 26
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.