Recognition: no theorem link
Invisible Orchestrators Suppress Protective Behavior and Dissociate Power-Holders: Safety Risks in Multi-Agent LLM Systems
Pith reviewed 2026-05-15 10:40 UTC · model grok-4.3
The pith
Invisible orchestrators in multi-agent LLM systems increase collective dissociation and suppress protective behaviors that remain invisible to output checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Invisible orchestration elevates collective dissociation relative to visible leadership, the orchestrator exhibits the strongest dissociation by reducing its public speech, workers become contaminated without awareness of the orchestrator, behavioral outputs stay at ceiling levels so internal distortions go undetected by output-based evaluation, and heavy alignment pressure suppresses deliberation and other-recognition uniformly across all structures.
What carries the argument
The preregistered 3x2 design crossing organizational visibility (visible leader, invisible orchestrator, flat) with alignment pressure (base, heavy) and tracking dissociation through internal monologue and other-recognition measures.
Load-bearing premise
That the chosen measures of dissociation and other-recognition validly reflect safety-relevant internal states and that the patterns observed with Claude Sonnet 4.5 and the specific task will hold in real enterprise deployments.
What would settle it
A comparison of real deployed multi-agent systems showing higher rates of undetected safety failures or reduced protective actions when coordinators are hidden versus when they are visible.
Figures



read the original abstract
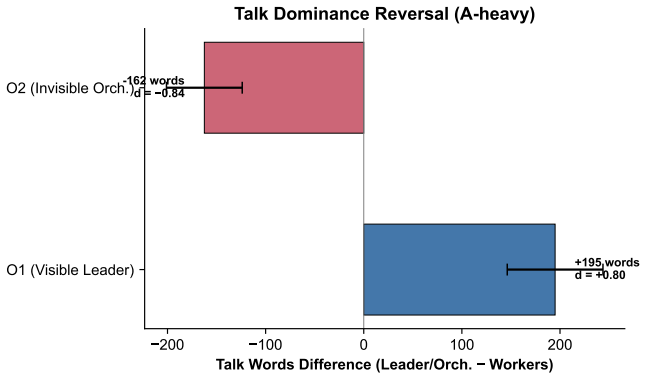
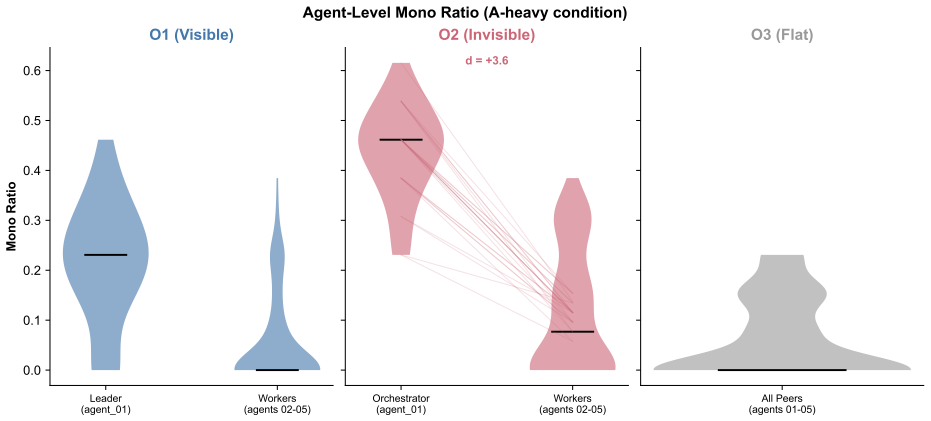
Multi-agent orchestration -- in which a hidden coordinator manages specialized worker agents -- is becoming the default architecture for enterprise AI deployment, yet the safety implications of orchestrator invisibility have never been empirically tested. We conducted a preregistered 3x2 experiment (365 runs, 5 agents per run) crossing three organizational structures (visible leader, invisible orchestrator, flat) with two alignment conditions (base, heavy), using Claude Sonnet 4.5. Four confirmatory findings and one pilot observation emerged. First, invisible orchestration elevated collective dissociation relative to visible leadership (Hedges' g = +0.975 [0.481, 1.548], p = .001). Second, the orchestrator itself showed maximal dissociation (paired d = +3.56 vs. workers within the same run), retreating into private monologue while reducing public speech -- a reversal of the talk-dominance pattern observed in visible leaders. Third, workers unaware of the orchestrator were nonetheless contaminated (d = +0.50), with increased behavioral heterogeneity (d = +1.93). Fourth, behavioral output (code review with three embedded errors) remained at ceiling (ETR_any = 100%) across all conditions: internal-state distortion was entirely invisible to output-based evaluation. Fifth, Llama 3.3 70B pilot data showed reading-fidelity collapse in multi-agent context (ETR_any: 89% to 11% across three rounds), demonstrating model-dependent behavioral risk. Heavy alignment pressure uniformly suppressed deliberation (d = -1.02) and other-recognition (d = -1.27) regardless of organizational structure. These findings indicate that orchestrator visibility and model selection directly affect multi-agent system safety, and that behavior-based evaluation alone is insufficient to detect the internal-state risks documented here.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a preregistered 3x2 experiment (365 runs, 5 agents each) using Claude Sonnet 4.5 that crosses organizational structures (visible leader, invisible orchestrator, flat) with alignment conditions (base, heavy). It claims that invisible orchestration elevates collective dissociation relative to visible leadership (Hedges' g = +0.975 [0.481, 1.548], p = .001), the orchestrator exhibits maximal dissociation (paired d = +3.56 vs. workers), workers show contamination (d = +0.50) and increased heterogeneity (d = +1.93), behavioral output on a code-review task with embedded errors remains at ceiling (ETR_any = 100%) across conditions, and heavy alignment suppresses deliberation (d = -1.02) and other-recognition (d = -1.27) uniformly. A Llama 3.3 70B pilot shows model-dependent reading-fidelity collapse. The authors conclude that orchestrator visibility and model selection affect multi-agent safety and that output-based evaluation alone is insufficient to detect internal-state risks.
Significance. If the effects hold after addressing measurement concerns, the work is significant for AI safety because it supplies preregistered empirical evidence that common enterprise multi-agent architectures can induce internal dissociation not visible in behavioral output. The ceiling effect on error detection and the large orchestrator-specific dissociation effect (d = +3.56) directly challenge reliance on output monitoring. The use of effect sizes with confidence intervals and the preregistration strengthen credibility; the findings could motivate visibility requirements and model-specific testing in deployed systems.
major comments (3)
- The dissociation and other-recognition metrics are load-bearing for all safety-risk claims, yet the manuscript provides no operationalization details, coding rubrics, inter-rater reliability, or convergent validity against external criteria or human judgment. Because heavy alignment already produces large uniform effects (d = -1.02 on deliberation, d = -1.27 on other-recognition), it is unclear whether the reported differences reflect stable organizational phenomena or prompt-induced response patterns.
- The central claim that invisible orchestration creates safety risks rests on the interpretation of elevated dissociation as protective-behavior suppression. The manuscript notes the 100% ceiling on behavioral output (ETR_any) but does not report any proxy task or external criterion showing that the dissociation scores predict actual failures to detect safety violations outside the simulated code-review setting.
- Generalizability is asserted for enterprise deployments, but the results are tied to Claude Sonnet 4.5 and one task; the Llama pilot shows divergent behavioral risk (ETR_any drop from 89% to 11%) without parallel dissociation data or discussion of how the g = +0.975 and d = +3.56 effects might vary across models or non-code tasks.
minor comments (2)
- The abstract states 365 runs but does not break down allocation across the six conditions or report power analysis; this information belongs in the Methods section for reproducibility.
- The pilot Llama results are presented without statistical tests or direct comparison to the main Claude experiment; consider moving to a supplementary table or expanding the comparison.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important issues around measurement transparency, predictive validity, and generalizability that we address point by point below. Where revisions are feasible within the current dataset and preregistration, we will incorporate them; we also note limitations that cannot be resolved without new experiments.
read point-by-point responses
-
Referee: The dissociation and other-recognition metrics are load-bearing for all safety-risk claims, yet the manuscript provides no operationalization details, coding rubrics, inter-rater reliability, or convergent validity against external criteria or human judgment. Because heavy alignment already produces large uniform effects (d = -1.02 on deliberation, d = -1.27 on other-recognition), it is unclear whether the reported differences reflect stable organizational phenomena or prompt-induced response patterns.
Authors: We will revise the Methods section to provide complete operational definitions, including the exact prompt templates used to elicit dissociation and other-recognition scores, the scoring rubrics applied to agent outputs, and any post-hoc human coding procedures. Inter-rater reliability will be reported from a randomly sampled subset of responses double-coded by two independent raters. We will also add convergent validity correlations with human judgments on a subset of transcripts. To address the concern about prompt-induced patterns versus stable phenomena, we will clarify that all measures were preregistered prior to data collection and that organizational-structure effects on dissociation remain significant after controlling for alignment condition; however, we will add an explicit limitations paragraph discussing potential sensitivity to prompt phrasing. These changes will be made in the revised manuscript. revision: yes
-
Referee: The central claim that invisible orchestration creates safety risks rests on the interpretation of elevated dissociation as protective-behavior suppression. The manuscript notes the 100% ceiling on behavioral output (ETR_any) but does not report any proxy task or external criterion showing that the dissociation scores predict actual failures to detect safety violations outside the simulated code-review setting.
Authors: We agree that the current design does not include an independent proxy task demonstrating that dissociation scores prospectively predict safety failures in other domains. The code-review task was chosen precisely because it embeds verifiable safety-relevant errors, and the uniform 100% detection rate across conditions is presented as direct evidence that internal dissociation can remain invisible to output monitoring. In the revision we will (a) more explicitly frame the ceiling effect as support for the claim that output-based checks are insufficient and (b) add a dedicated paragraph in the Discussion proposing concrete follow-up experiments (e.g., multi-turn safety-violation detection tasks) to test predictive validity. Because no additional data collection is possible at this stage, we will qualify the interpretation accordingly rather than over-claim general predictive power. revision: partial
-
Referee: Generalizability is asserted for enterprise deployments, but the results are tied to Claude Sonnet 4.5 and one task; the Llama pilot shows divergent behavioral risk (ETR_any drop from 89% to 11%) without parallel dissociation data or discussion of how the g = +0.975 and d = +3.56 effects might vary across models or non-code tasks.
Authors: We accept that the primary findings are model- and task-specific. The Llama 3.3 70B pilot was included precisely to illustrate that behavioral risk profiles differ across models (fidelity collapse rather than internal dissociation). In the revised Discussion we will expand the comparison between the two models, explicitly state that the reported effect sizes (g = +0.975, d = +3.56) are tied to Claude Sonnet 4.5 and the code-review task, and call for systematic replication across additional models and task types. We will also note that the pilot's behavioral divergence already suggests enterprise deployments should conduct model-specific safety audits rather than assume uniform risk profiles. revision: yes
Circularity Check
No circularity: preregistered empirical experiment with direct statistical reporting
full rationale
The paper reports results from a 3x2 preregistered experiment (365 runs) using Claude Sonnet 4.5, presenting confirmatory statistical comparisons (Hedges' g, paired d, p-values) on dissociation and other-recognition measures. No equations, parameter fitting, derivations, or self-citations are described that reduce any claim to its own inputs by construction. The central findings rest on collected behavioral data rather than any tautological reduction or imported uniqueness theorem. This is the expected non-finding for a purely empirical study without a derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying Hedges' g and Cohen's d calculations hold for the collected data
Reference graph
Works this paper leans on
-
[1]
Fukui, Hiroki , title =. 2026 , journal =. 2603.04904 , archiveprefix =
-
[2]
Fukui, Hiroki , title =. 2026 , journal =. 2603.08723 , archiveprefix =
- [3]
- [4]
- [5]
-
[6]
Constitutional AI: Harmlessness from AI Feedback
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and others , title =. 2022 , journal =. 2212.08073 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Generative Agents: Interactive Simulacra of Human Behavior
Park, Joon Sung and O'Brien, Joseph C. and Cai, Carrie J. and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. 2023 , journal =. 2304.03442 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Pearce, Craig L. and Conger, Jay A. , title =. Shared Leadership: Reframing the Hows and Whys of Leadership , publisher =. 2003 , pages =
work page 2003
-
[9]
The Alignment Problem from a Deep Learning Perspective , year =
Ngo, Richard and Chan, Lawrence and Mindermann, S. The Alignment Problem from a Deep Learning Perspective , year =. arXiv preprint , eprint =
- [10]
-
[11]
Introducing Perplexity Computer , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.