Recognition: no theorem link
To See is Not to Learn: Protecting Multimodal Data from Unauthorized Fine-Tuning of Large Vision-Language Model
Pith reviewed 2026-05-15 02:35 UTC · model grok-4.3
The pith
Data owners can add invisible perturbations to images and text to stop large vision-language models from learning real content during unauthorized fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MMGuard generates unlearnable examples by injecting human-imperceptible perturbations that exploit LVLM learning dynamics to create an optimization shortcut, causing the model to overfit to noise rather than content and degrading downstream performance when the perturbation is removed. It adds cross-modal binding disruption to strategically shift attention and enforce spurious correlations between the noise and training targets with theoretical guarantees, then uses an ensemble learning strategy to boost cross-model transferability, with evaluations showing effective, stealthy, and robust protection under multiple threat models.
What carries the argument
Perturbation injection that minimizes training loss via an optimization shortcut, paired with cross-modal binding disruption to enforce noise-target spurious correlations.
If this is right
- Fine-tuning on protected data produces models that perform poorly on clean inputs at inference time.
- The defense holds under white-box, gray-box, and black-box threat models.
- Ensemble perturbations enable the protection to transfer across different LVLM architectures.
- Owners gain a tool that acts before data is scraped, reducing reliance on after-the-fact remedies.
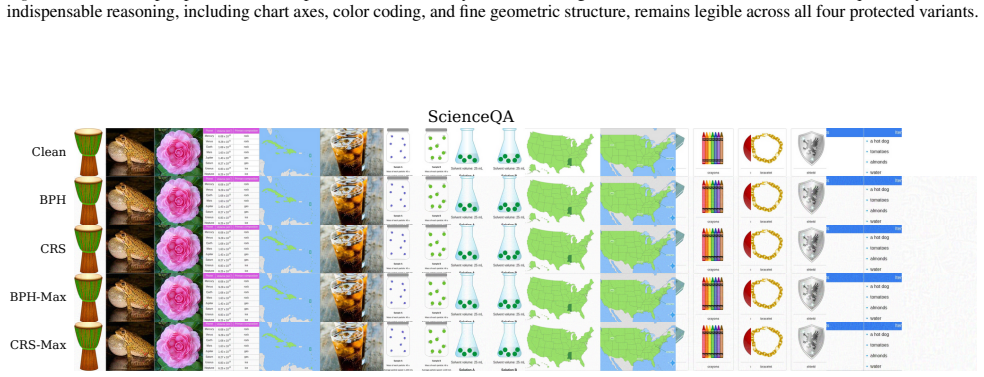
- Protection remains stealthy to humans while disrupting model learning.
Where Pith is reading between the lines
- If widely used, this could make scraped web data less useful for training, potentially reducing incentives for unauthorized collection.
- Similar perturbation approaches might extend to protecting data for other model types or single-modality tasks.
- Training pipelines might need built-in checks to detect or handle such protected data.
- Over time, routine use could shift norms around public multimodal data availability.
Load-bearing premise
The injected perturbations will reliably force the model to overfit to noise instead of content because the attention and loss landscape behave predictably under the chosen strategy.
What would settle it
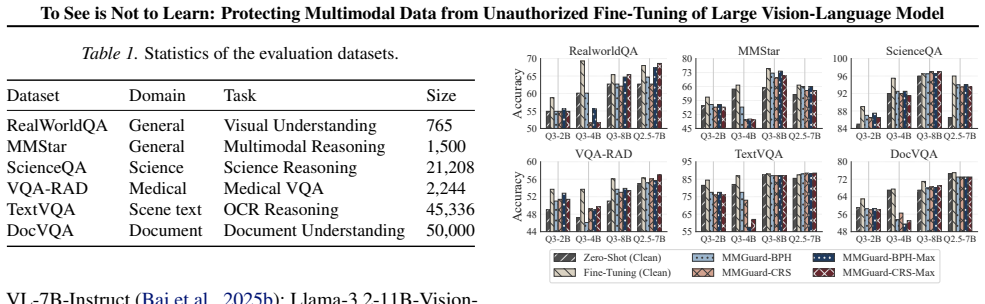
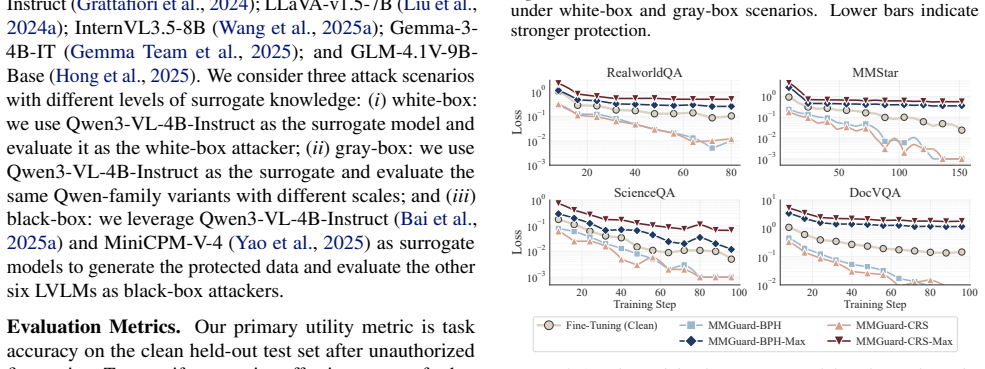
Fine-tune an LVLM on MMGuard-protected data, then measure its accuracy on clean test data without the perturbations and compare to accuracy after fine-tuning on the same data without protection.
Figures












read the original abstract
The rapid advancement of Large Vision-Language Models (LVLMs) is increasingly accompanied by unauthorized scraping and training on multimodal web data, posing severe copyright and privacy risks to data owners. Existing countermeasures, such as machine unlearning and watermarks, are inherent post-hoc approaches that act only after intellectual property infringement has already occurred. In this work, we propose MMGuard to empower data owners to proactively protect their multimodal data against unauthorized LVLM fine-tuning. MMGuard generates unlearnable examples by injecting human-imperceptible perturbations that actively exploit the learning dynamics of LVLMs. By minimizing the training loss, the perturbation creates an optimization shortcut, causing the model to overfit to the noise and thereby degrading downstream performance when the perturbation is absent during inference. To further strengthen this defense, MMGuard introduces a cross-modal binding disruption, strategically shifting LVLM attention to enforce a spurious correlation between the noise and the training target with theoretical guarantees. Enhanced by an ensemble learning strategy for cross-model transferability, MMGuard is evaluated against nine open-source LVLMs across six datasets. Our comprehensive results demonstrate effective, stealthy, and robust protection under white-box, gray-box, and black-box threat models, establishing a mechanistic advantage in proactively defending against aggressive fine-tuning exploitation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MMGuard, a proactive method to protect multimodal data from unauthorized LVLM fine-tuning. It generates unlearnable examples via human-imperceptible perturbations that create an optimization shortcut (forcing overfitting to noise) and a cross-modal binding disruption that enforces spurious noise-target correlations with theoretical guarantees. An ensemble strategy improves cross-model transferability. The approach is evaluated on nine open-source LVLMs across six datasets under white-box, gray-box, and black-box threat models, claiming effective, stealthy, and robust protection.
Significance. If the mechanistic claims and theoretical guarantees hold after verification, this would offer a meaningful shift from post-hoc defenses (unlearning, watermarks) to proactive data protection, with potential impact on copyright and privacy practices for web-scraped multimodal training data.
major comments (2)
- [Abstract] Abstract: The claim that cross-modal binding disruption 'enforces a spurious correlation between the noise and the training target with theoretical guarantees' is load-bearing for the robustness argument across nine architectures, yet no derivation, equation, or section is referenced showing how the guarantee follows from the perturbation strategy; if attention heads route around the noise differently than assumed, the downstream degradation fails.
- [Evaluation] Evaluation section: Results on nine models and six datasets are presented without ablation studies isolating the binding term, error analysis, or mechanistic verification that the optimization shortcut (rather than other factors) drives the observed protection; this leaves the central claim of a 'mechanistic advantage' unconfirmed by the reported experiments alone.
minor comments (1)
- The abstract refers to 'human-imperceptible perturbations' and 'ensemble learning strategy' without specifying the perturbation generation algorithm, imperceptibility metrics (e.g., PSNR/SSIM bounds), or ensemble construction details; these should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the manuscript to improve clarity on the theoretical claims and strengthen the experimental validation of the mechanistic components.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that cross-modal binding disruption 'enforces a spurious correlation between the noise and the training target with theoretical guarantees' is load-bearing for the robustness argument across nine architectures, yet no derivation, equation, or section is referenced showing how the guarantee follows from the perturbation strategy; if attention heads route around the noise differently than assumed, the downstream degradation fails.
Authors: We appreciate the referee identifying this gap in referencing. The derivation of the spurious correlation is formalized in Section 3.3, where we model the attention routing under the perturbation and prove that the noise-target correlation is enforced via a bound on the attention weights (Equation 7). To make this explicit and address potential routing variations, we will revise the abstract to directly cite Section 3.3 and Equation 7, expand the discussion in Section 3.3 on the assumption robustness, and add a short proof sketch in the main text. revision: yes
-
Referee: [Evaluation] Evaluation section: Results on nine models and six datasets are presented without ablation studies isolating the binding term, error analysis, or mechanistic verification that the optimization shortcut (rather than other factors) drives the observed protection; this leaves the central claim of a 'mechanistic advantage' unconfirmed by the reported experiments alone.
Authors: We agree that additional ablations and mechanistic checks would strengthen the evaluation. In the revision, we will add ablation studies comparing the full MMGuard against variants without the binding disruption term across the nine models. We will also include error analysis (e.g., per-dataset variance and failure cases) and mechanistic verification via attention map visualizations and training loss curves to isolate the optimization shortcut's contribution. These will be placed in a new subsection of the evaluation. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces MMGuard via perturbation injection to create optimization shortcuts and cross-modal binding disruption to enforce spurious correlations, with claims of theoretical guarantees. No equations, fitted parameters renamed as predictions, or self-citations appear in the abstract or described text that reduce these mechanisms back to their own inputs by construction. The approach applies standard attention and loss concepts to LVLMs without self-definitional loops or ansatzes imported from prior author work; evaluation across models and datasets provides external empirical grounding rather than internal reduction. The derivation remains self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LVLM learning dynamics permit creation of optimization shortcuts via imperceptible perturbations that cause overfitting to noise
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Multimedia , year=
Imperceptible protection against style imitation from diffusion models , author=. IEEE Transactions on Multimedia , year=
-
[2]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and others , journal=
-
[3]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
2021 IEEE Symposium on Security and Privacy , pages=
Machine unlearning , author=. 2021 IEEE Symposium on Security and Privacy , pages=
work page 2021
-
[5]
34th USENIX Security Symposium (USENIX Security 25) , pages=
\ LightShed \ : Defeating Perturbation-based Image Copyright Protections , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=
-
[6]
30th USENIX Security Symposium , pages=
Extracting training data from large language models , author=. 30th USENIX Security Symposium , pages=
-
[7]
2022 IEEE symposium on security and privacy (SP) , pages=
Membership inference attacks from first principles , author=. 2022 IEEE symposium on security and privacy (SP) , pages=. 2022 , organization=
work page 2022
-
[8]
International Conference on Learning Representations , year=
Poisoning and backdooring contrastive learning , author=. International Conference on Learning Representations , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
Are we on the right way for evaluating large vision-language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Journal of King Saud University Computer and Information Sciences , volume=
A survey on privacy risks and protection in large language models , author=. Journal of King Saud University Computer and Information Sciences , volume=. 2025 , publisher=
work page 2025
-
[11]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
ACM Computing Surveys , volume=
Security and privacy challenges of large language models: A survey , author=. ACM Computing Surveys , volume=. 2025 , publisher=
work page 2025
-
[13]
Scalable watermarking for identifying large language model outputs , author=. Nature , volume=
-
[14]
IEEE Conference on Secure and Trustworthy Machine Learning , year=
The devil's advocate: Shattering the illusion of unexploitable data using diffusion models , author=. IEEE Conference on Secure and Trustworthy Machine Learning , year=
-
[15]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
The stable signature: Rooting watermarks in latent diffusion models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[16]
Advances in Neural Information Processing Systems , volume=
Adversarial examples make strong poisons , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
International Conference on Learning Representations , year=
Robust unlearnable examples: Protecting data privacy against adversarial learning , author=. International Conference on Learning Representations , year=
-
[18]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning , author=. arXiv preprint arXiv:2507.01006 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Gokul, Vignesh and Dubnov, Shlomo , journal=
-
[21]
The Llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Hayes, Jamie and Melis, Luca and Danezis, George and De Cristofaro, Emiliano , journal=
-
[23]
Journal of Machine Learning Research , volume=
Foundation models and fair use , author=. Journal of Machine Learning Research , volume=
-
[24]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
Dissecting fine-tuning unlearning in large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
work page 2024
-
[25]
International Conference on Learning Representations , year=
Unlearnable examples: Making personal data unexploitable , author=. International Conference on Learning Representations , year=
-
[26]
International Conference on Machine Learning , pages=
A watermark for large language models , author=. International Conference on Machine Learning , pages=
-
[27]
arXiv preprint arXiv:2411.08506 , year=
Towards operationalizing right to data protection , author=. arXiv preprint arXiv:2411.08506 , year=
-
[28]
A dataset of clinically generated visual questions and answers about radiology images , author=. Scientific data , volume=. 2018 , publisher=
work page 2018
-
[29]
Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023) , pages=
Make text unlearnable: Exploiting effective patterns to protect personal data , author=. Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023) , pages=
work page 2023
-
[30]
IEEE International Conference on Acoustics, Speech and Signal Processing , year=
Making audio data unlearnable , author=. IEEE International Conference on Acoustics, Speech and Signal Processing , year=
-
[31]
arXiv preprint arXiv:2303.02568 , year=
Unlearnable graph: Protecting graphs from unauthorized exploitation , author=. arXiv preprint arXiv:2303.02568 , year=
-
[32]
Advances in Neural Information Processing Systems , volume=
Visual instruction tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[34]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Multimodal unlearnable examples: Protecting data against multimodal contrastive learning , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[35]
Liu, Yixin and Fan, Chenrui and Dai, Yutong and Chen, Xun and Zhou, Pan and Sun, Lichao , booktitle=
-
[36]
Nature Machine Intelligence , volume=
Rethinking machine unlearning for large language models , author=. Nature Machine Intelligence , volume=. 2025 , publisher=
work page 2025
-
[37]
arXiv preprint arXiv:2407.07403 , year=
A survey of attacks on large vision-language models: Resources, advances, and future trends , author=. arXiv preprint arXiv:2407.07403 , year=
-
[38]
Advances in Neural Information Processing Systems , volume=
Unseg: One universal unlearnable example generator is enough against all image segmentation , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Mitigating unauthorized speech synthesis for voice protection , author=. Proceedings of the 1st ACM Workshop on Large AI Systems and Models with Privacy and Safety Analysis , pages=
-
[40]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
BridgePure: Limited Protection Leakage Can Break Black-Box Data Protection , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[41]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
StyleGuard: Preventing Text-to-Image-Model-based Style Mimicry Attacks by Style Perturbations , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[42]
Advances in neural information processing systems , volume=
Learn to explain: Multimodal reasoning via thought chains for science question answering , author=. Advances in neural information processing systems , volume=
-
[43]
International Conference on Learning Representations , year=
Towards deep learning models resistant to adversarial attacks , author=. International Conference on Learning Representations , year=
-
[44]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Docvqa: A dataset for vqa on document images , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[45]
and Grant, Nico , howpublished=
Metz, Cade and Kang, Cecilia and Frenkel, Sheera and Thompson, Stuart A. and Grant, Nico , howpublished=. How tech giants cut corners to harvest data for. 2024 , note=
work page 2024
-
[46]
Unlearnable Examples Give a False Sense of Data Privacy: Understanding and Relearning , author=. arXiv e-prints , pages=
-
[47]
International Conference on Machine Learning , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning , pages=
-
[48]
2024 , howpublished=
work page 2024
-
[49]
International Conference on Learning Representations , year=
Transferable unlearnable examples , author=. International Conference on Learning Representations , year=
-
[50]
Advances in Neural Information Processing Systems , volume=
Autoregressive perturbations for data poisoning , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
Schuhmann, Christoph and Beaumont, Romain and Vencu, Richard and Gordon, Cade and Wightman, Ross and Cherti, Mehdi and Coombes, Theo and Katta, Aarush and Mullis, Clayton and Wortsman, Mitchell and others , booktitle=
-
[52]
Shan, Shawn and Cryan, Jenna and Wenger, Emily and Zheng, Haitao and Hanocka, Rana and Zhao, Ben Y , booktitle=
-
[53]
Shan, Shawn and Ding, Wenxin and Passananti, Josephine and Wu, Stanley and Zheng, Haitao and Zhao, Ben Y , booktitle=
-
[54]
International Conference on Learning Representations , year=
Jailbreak in pieces: Compositional adversarial attacks on multi-modal language models , author=. International Conference on Learning Representations , year=
-
[55]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards vqa models that can read , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[56]
Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security , pages=
Antifake: Using adversarial audio to prevent unauthorized speech synthesis , author=. Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security , pages=
work page 2023
-
[57]
Singh, Aaditya and Fry, Adam and Perelman, Adam and Tart, Adam and Ganesh, Adi and El-Kishky, Ahmed and McLaughlin, Aidan and Low, Aiden and Ostrow, AJ and Ananthram, Akhila and others , journal=
-
[58]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Stable unlearnable example: Enhancing the robustness of unlearnable examples via stable error-minimizing noise , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[59]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Anti-dreambooth: Protecting users from personalized text-to-image synthesis , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[60]
Proceedings of the 32nd ACM International Conference on Multimedia , year=
White-box multimodal jailbreaks against large vision-language models , author=. Proceedings of the 32nd ACM International Conference on Multimedia , year=
-
[61]
arXiv preprint arXiv:2505.16446 , year=
Implicit jailbreak attacks via cross-modal information concealment on vision-language models , author=. arXiv preprint arXiv:2505.16446 , year=
-
[62]
Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others , journal=
-
[63]
arXiv preprint arXiv:2411.17911 , year=
Passive deepfake detection across multi-modalities: A comprehensive survey , author=. arXiv preprint arXiv:2411.17911 , year=
-
[64]
arXiv preprint arXiv:2603.04731 , year=
When Priors Backfire: On the Vulnerability of Unlearnable Examples to Pretraining , author=. arXiv preprint arXiv:2603.04731 , year=
-
[65]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
OBLIVIATE: Robust and Practical Machine Unlearning for Large Language Models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[66]
On protecting the data privacy of large language models (
Yan, Biwei and Li, Kun and Xu, Minghui and Dong, Yueyan and Zhang, Yue and Ren, Zhaochun and Cheng, Xiuzhen , journal=. On protecting the data privacy of large language models (
-
[67]
Nature Communications , volume=
Efficient GPT-4V level multimodal large language model for deployment on edge devices , author=. Nature Communications , volume=. 2025 , publisher=
work page 2025
-
[68]
Millette, David , howpublished =. Class Action Complaint:. 2024 , month = aug, url =
work page 2024
-
[69]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Versatile Transferable Unlearnable Example Generator , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[70]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Unlearnable clusters: Towards label-agnostic unlearnable examples , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[71]
arXiv preprint arXiv:2306.01902 , year=
Unlearnable examples for diffusion models: Protect data from unauthorized exploitation , author=. arXiv preprint arXiv:2306.01902 , year=
-
[72]
Zhu, Jiren and Kaplan, Russell and Johnson, Justin and Fei-Fei, Li , booktitle=
-
[73]
Zhu, Jinguo and Wang, Weiyun and Chen, Zhe and Liu, Zhaoyang and Ye, Shenglong and Gu, Lixin and Tian, Hao and Duan, Yuchen and Su, Weijie and Shao, Jie and others , journal=
-
[74]
Hotflip: White-box adversarial examples for text classification , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[75]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Data contamination can cross language barriers , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.