Recognition: 2 theorem links
· Lean TheoremPolicy Optimization in Hybrid Discrete-Continuous Action Spaces via Mixed Gradients
Pith reviewed 2026-05-15 02:09 UTC · model grok-4.3
The pith
Hybrid Policy Optimization mixes pathwise and score-function gradients to keep policy updates unbiased in hybrid discrete-continuous action spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hybrid Policy Optimization maintains unbiasedness by combining pathwise derivatives through the simulator where dynamics are smooth with score-function estimators for discrete components, and problems with action discontinuities can be recast in this hybrid form to enable the same optimization technique.
What carries the argument
The mixed gradient estimator that adds pathwise gradients for continuous actions to score-function gradients for discrete actions while preserving unbiasedness.
If this is right
- Problems featuring action discontinuities can be reformulated as hybrid discrete-continuous problems to apply the same optimization technique.
- The cross term in the mixed gradient, which links continuous actions to future discrete decisions, becomes negligible near a discrete best response.
- This negligibility enables approximate decentralized updates of continuous and discrete policy components with reduced variance.
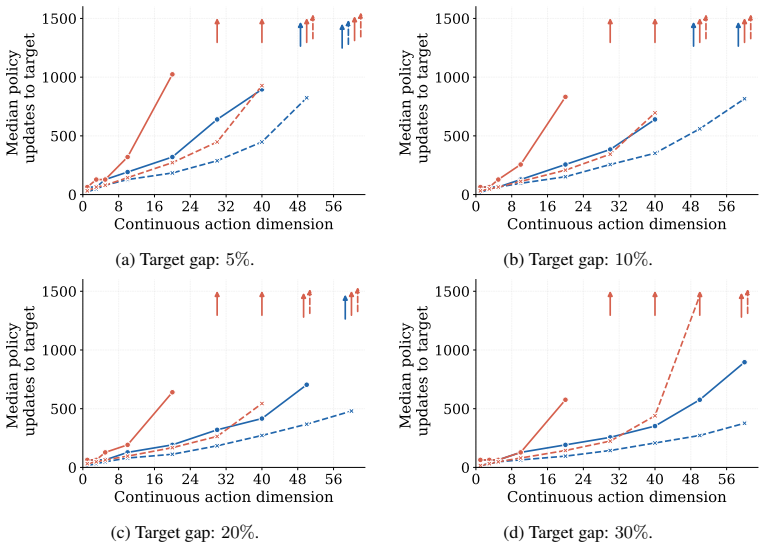
- Performance advantages over PPO grow as the dimension of the continuous action component increases.
Where Pith is reading between the lines
- The reformulation step could let many existing operations-research models with regime switches be solved directly with differentiable simulators.
- Decentralized updates near optimality might simplify training loops for hierarchical policies without sacrificing final performance.
- Inventory and switched-linear systems are representative of broader classes of hybrid control problems in robotics and logistics that could adopt the same estimator.
Load-bearing premise
The combination of pathwise and score-function terms produces an estimator whose expectation equals the true policy gradient even when discrete choices affect continuous trajectories.
What would settle it
Compute the exact policy gradient on a low-dimensional hybrid control task via finite differences or dynamic programming and check whether the mixed estimator matches it in expectation; or run HPO versus PPO on the inventory benchmark and verify whether the performance gap shrinks or reverses as continuous dimension increases.
Figures











read the original abstract
We study reinforcement learning in hybrid discrete-continuous action spaces, such as settings where the discrete component selects a regime (or index) and the continuous component optimizes within it -- a structure common in robotics, control, and operations problems. Standard model-free policy gradient methods rely on score-function (SF) estimators and suffer from severe credit-assignment issues in high-dimensional settings, leading to poor gradient quality. On the other hand, differentiable simulation largely sidesteps these issues by backpropagating through a simulator, but the presence of discrete actions or non-smooth dynamics yields biased or uninformative gradients. To address this, we propose Hybrid Policy Optimization (HPO), which backpropagates through the simulator wherever smoothness permits, using a mixed gradient estimator that combines pathwise and SF gradients while maintaining unbiasedness. We also show how problems with action discontinuities can be reformulated in hybrid form, further broadening its applicability. Empirically, HPO substantially outperforms PPO on inventory control and switched linear-quadratic regulator problems, with performance gaps increasing as the continuous action dimension grows. Finally, we characterize the structure of the mixed gradient, showing that its cross term -- which captures how continuous actions influence future discrete decisions -- becomes negligible near a discrete best response, thereby enabling approximate decentralized updates of the continuous and discrete components and reducing variance near optimality. All resources are available at github.com/MatiasAlvo/hybrid-rl.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Hybrid Policy Optimization (HPO) for RL in hybrid discrete-continuous action spaces, where a discrete component selects a regime and a continuous component optimizes within it. It proposes a mixed gradient estimator combining pathwise gradients (via backpropagation through smooth simulator segments) and score-function gradients, asserting that the combination remains unbiased. The approach includes reformulating discontinuous-action problems into hybrid form. Empirically, HPO outperforms PPO on inventory control and switched linear-quadratic regulator tasks, with larger gains as continuous action dimension increases. The paper also analyzes the mixed gradient structure, showing that the cross-term (continuous actions affecting future discrete decisions) becomes negligible near a discrete best response.
Significance. If the unbiasedness of the mixed estimator holds under the stated conditions, the work would meaningfully advance policy optimization for hybrid action spaces common in control and robotics. It bridges score-function methods (high variance) with differentiable simulation (biased at discontinuities), offers a practical reformulation for discontinuous problems, and provides a structural characterization that could support lower-variance decentralized updates near optimality. The reported empirical gains over PPO, scaling with continuous dimension, indicate potential practical impact if the theoretical claims are verified.
major comments (2)
- [Theoretical derivation of mixed gradient estimator] The central claim of unbiasedness for the mixed pathwise-SF estimator under discrete-continuous coupling is load-bearing but insufficiently detailed in the provided derivation. The abstract states that the estimator 'maintains unbiasedness' and that the cross-term 'becomes negligible near a discrete best response,' yet the precise decomposition (how pathwise gradients on continuous segments combine with SF on discrete switches without residual bias from regime selection) is not shown; this leaves open whether the expectation of the total estimator equals the true policy gradient when continuous actions influence discrete probabilities.
- [Reformulation section] The reformulation of action-discontinuity problems into hybrid form is presented as broadening applicability, but the manuscript does not specify the exact measure-theoretic conditions or approximation error introduced when mapping non-smooth dynamics onto the hybrid structure; if this step involves any relaxation, it could affect the unbiasedness guarantee.
minor comments (2)
- [Experiments] The abstract and empirical claims mention performance gaps but do not reference error bars, number of seeds, or statistical significance tests; these should be added to the experimental section and figures for reproducibility.
- [Preliminaries] Notation for the hybrid policy and the mixed estimator (e.g., how the pathwise component is restricted to differentiable segments) should be defined more explicitly early in the paper to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below. Where the comments identify areas needing greater clarity, we have revised the manuscript by expanding the relevant sections and proofs.
read point-by-point responses
-
Referee: [Theoretical derivation of mixed gradient estimator] The central claim of unbiasedness for the mixed pathwise-SF estimator under discrete-continuous coupling is load-bearing but insufficiently detailed in the provided derivation. The abstract states that the estimator 'maintains unbiasedness' and that the cross-term 'becomes negligible near a discrete best response,' yet the precise decomposition (how pathwise gradients on continuous segments combine with SF on discrete switches without residual bias from regime selection) is not shown; this leaves open whether the expectation of the total estimator equals the true policy gradient when continuous actions influence discrete probabilities.
Authors: We agree that the original derivation would benefit from greater explicitness. The mixed estimator is constructed so that the pathwise (differentiable simulation) component is applied only to the continuous dynamics conditional on a fixed discrete regime, while the score-function component handles the discrete regime selection and any dependence of regime probabilities on continuous actions. Unbiasedness follows from the law of total expectation: the conditional pathwise gradient is unbiased for the continuous contribution, and the score-function term is unbiased for the discrete choice; their combination yields the full policy gradient with no residual bias term. The cross-term analysis shows it vanishes in expectation near a discrete best response. To address the concern directly, the revised manuscript adds a complete step-by-step derivation (including the full expectation expansion) as a new subsection in Section 3 and a self-contained proof in Appendix B. revision: yes
-
Referee: [Reformulation section] The reformulation of action-discontinuity problems into hybrid form is presented as broadening applicability, but the manuscript does not specify the exact measure-theoretic conditions or approximation error introduced when mapping non-smooth dynamics onto the hybrid structure; if this step involves any relaxation, it could affect the unbiasedness guarantee.
Authors: The reformulation expresses problems with action discontinuities by introducing an auxiliary discrete variable that selects among smooth continuous regimes whose union recovers the original (possibly discontinuous) dynamics. When the discontinuity set has Lebesgue measure zero and the simulator is differentiable almost everywhere within each regime, the mapping is exact and introduces no approximation error to the policy gradient. We acknowledge that the original manuscript did not state these conditions explicitly. The revised version adds a dedicated paragraph in Section 4 that specifies the measure-theoretic requirements (discontinuities of measure zero, differentiability a.e. within regimes) under which the reformulation preserves the unbiasedness of the mixed estimator. revision: yes
Circularity Check
No significant circularity; derivation builds on external estimators without self-reduction.
full rationale
The paper proposes a mixed pathwise-SF gradient estimator for hybrid discrete-continuous actions and claims it remains unbiased. This claim rests on standard properties of pathwise derivatives (where dynamics are differentiable) and score-function estimators (unbiased by construction in policy gradients), both drawn from prior RL literature rather than fitted or defined within the paper itself. No equations reduce the target gradient to a parameter fit from the same data, nor does the central unbiasedness result collapse to a self-citation chain or ansatz smuggled from the authors' prior work. The reformulation of discontinuous problems into hybrid form is a modeling step, not a derivation that presupposes its own output. Empirical comparisons to PPO are independent of the theoretical claims. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The simulator is differentiable in the continuous action components.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
mixed gradient estimator that combines pathwise and SF gradients while maintaining unbiasedness... cross term... becomes negligible near a discrete best response (Theorem 2)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hybrid MDP... smoothness with respect to b... PW gradients... (Assumption 2)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Q-learning , author=. Machine learning , volume=. 1992 , publisher=
work page 1992
-
[2]
International conference on machine learning , pages=
Trust region policy optimization , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
-
[3]
Dynamic programming and optimal control 3rd edition, volume ii , author=
-
[4]
Advances in neural information processing systems , volume=
A natural policy gradient , author=. Advances in neural information processing systems , volume=
-
[5]
Advances in neural information processing systems , volume=
Actor-critic algorithms , author=. Advances in neural information processing systems , volume=
-
[6]
Dynamic programming and optimal control: Volume I , author=. 2012 , publisher=
work page 2012
- [7]
-
[8]
Soft Actor-Critic Algorithms and Applications
Soft actor-critic algorithms and applications , author=. arXiv preprint arXiv:1812.05905 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Manufacturing & Service Operations Management , year=
Can deep reinforcement learning improve inventory management? performance on dual sourcing, lost sales and multi-echelon problems , author=. Manufacturing & Service Operations Management , year=
-
[10]
Optimal pricing, inflation, and the cost of price adjustment , pages=
The optimality of (S, s) policies in the dynamic inventory problem , author=. Optimal pricing, inflation, and the cost of price adjustment , pages=. 1960 , publisher=
work page 1960
-
[11]
Optimal policies for a multi-echelon inventory problem , author=. Management science , volume=. 1960 , publisher=
work page 1960
-
[12]
The annals of mathematical statistics , pages=
A stochastic approximation method , author=. The annals of mathematical statistics , pages=. 1951 , publisher=
work page 1951
-
[13]
Old and new methods for lost-sales inventory systems , author=. Operations research , volume=. 2008 , publisher=
work page 2008
-
[14]
Understanding the performance of capped base-stock policies in lost-sales inventory models , author=. Operations Research , volume=. 2021 , publisher=
work page 2021
-
[15]
Harvard Business Review , volume=
Stock-outs cause walkouts , author=. Harvard Business Review , volume=. 2004 , publisher=
work page 2004
-
[16]
Approximations of dynamic, multilocation production and inventory problems , author=. Management Science , volume=. 1984 , publisher=
work page 1984
-
[17]
Computational issues in an infinite-horizon, multiechelon inventory model , author=. Operations Research , volume=. 1984 , publisher=
work page 1984
-
[18]
Studies in the mathematical theory of inventory and production , author=. 1958 , publisher=
work page 1958
-
[19]
Approximate Dynamic Programming: Solving the curses of dimensionality , author=. 2007 , publisher=
work page 2007
-
[20]
Queueing network controls via deep reinforcement learning , author=. Stochastic Systems , volume=. 2022 , publisher=
work page 2022
-
[21]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
The ICLR Blog Track 2023 , year=
The 37 implementation details of proximal policy optimization , author=. The ICLR Blog Track 2023 , year=
work page 2023
-
[23]
European Journal of Operational Research , volume=
Deep reinforcement learning for inventory control: A roadmap , author=. European Journal of Operational Research , volume=. 2022 , publisher=
work page 2022
-
[24]
Proceedings of the AAAI conference on artificial intelligence , volume=
Deep reinforcement learning that matters , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[25]
2021 American Control Conference (ACC) , pages=
Scalable deep reinforcement learning for ride-hailing , author=. 2021 American Control Conference (ACC) , pages=. 2021 , organization=
work page 2021
-
[26]
IEEE INFOCOM 2018-IEEE Conference on Computer Communications , pages=
MOVI: A model-free approach to dynamic fleet management , author=. IEEE INFOCOM 2018-IEEE Conference on Computer Communications , pages=. 2018 , organization=
work page 2018
-
[27]
A deep value-network based approach for multi-driver order dispatching , author=. Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[28]
Reinforcement learning: An introduction , author=. 2018 , publisher=
work page 2018
-
[29]
Mastering the game of Go with deep neural networks and tree search , author=. nature , volume=. 2016 , publisher=
work page 2016
-
[30]
Mastering the game of go without human knowledge , author=. nature , volume=. 2017 , publisher=
work page 2017
-
[31]
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
work page 2015
-
[32]
The Journal of Machine Learning Research , volume=
End-to-end training of deep visuomotor policies , author=. The Journal of Machine Learning Research , volume=. 2016 , publisher=
work page 2016
-
[33]
Unpublished manuscript , year=
A new and simple policy for the continuous review lost sales inventory model , author=. Unpublished manuscript , year=
-
[34]
Proceedings of the 36th IEEE Conference on Decision and Control , volume=
A neuro-dynamic programming approach to retailer inventory management , author=. Proceedings of the 36th IEEE Conference on Decision and Control , volume=. 1997 , organization=
work page 1997
-
[35]
International Journal of Production Economics , volume=
Inventory management in supply chains: a reinforcement learning approach , author=. International Journal of Production Economics , volume=. 2002 , publisher=
work page 2002
-
[36]
European Journal of Operational Research , volume=
An integrated data-driven method using deep learning for a newsvendor problem with unobservable features , author=. European Journal of Operational Research , volume=. 2022 , publisher=
work page 2022
-
[37]
Applying deep learning to the newsvendor problem , author=. IISE Transactions , volume=. 2020 , publisher=
work page 2020
-
[38]
Manufacturing & Service Operations Management , volume=
A deep q-network for the beer game: Deep reinforcement learning for inventory optimization , author=. Manufacturing & Service Operations Management , volume=. 2022 , publisher=
work page 2022
-
[39]
International conference on machine learning , pages=
Asynchronous methods for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
work page 2016
-
[40]
Deep Inventory Management , author=. arXiv preprint arXiv:2210.03137 , year=
-
[41]
Reinforcement learning , pages=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Reinforcement learning , pages=. 1992 , publisher=
work page 1992
-
[42]
A review of cooperative multi-agent deep reinforcement learning , author=. Applied Intelligence , pages=. 2022 , publisher=
work page 2022
-
[43]
Advances in neural information processing systems , volume=
Multi-agent actor-critic for mixed cooperative-competitive environments , author=. Advances in neural information processing systems , volume=
-
[44]
Multi-Agent Actor-Critic with Generative Cooperative Policy Network
Multi-agent actor-critic with generative cooperative policy network , author=. arXiv preprint arXiv:1810.09206 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Parameter sharing deep deterministic policy gradient for cooperative multi-agent reinforcement learning , author=. arXiv preprint arXiv:1710.00336 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Modelling the Dynamic Joint Policy of Teammates with Attention Multi-agent DDPG
Modelling the dynamic joint policy of teammates with attention multi-agent DDPG , author=. arXiv preprint arXiv:1811.07029 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
arXiv preprint arXiv:2207.06272 , year=
Hindsight Learning for MDPs with Exogenous Inputs , author=. arXiv preprint arXiv:2207.06272 , year=
-
[48]
Sensitivity analysis for base-stock levels in multiechelon production-inventory systems , author=. Management Science , volume=. 1995 , publisher=
work page 1995
-
[49]
arXiv preprint arXiv:2106.13281 , year=
Brax--A Differentiable Physics Engine for Large Scale Rigid Body Simulation , author=. arXiv preprint arXiv:2106.13281 , year=
-
[50]
arXiv preprint arXiv:1910.00935 , year=
Difftaichi: Differentiable programming for physical simulation , author=. arXiv preprint arXiv:1910.00935 , year=
-
[51]
International Conference on Machine Learning , pages=
Do differentiable simulators give better policy gradients? , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[52]
The Journal of Machine Learning Research , volume=
Monte carlo gradient estimation in machine learning , author=. The Journal of Machine Learning Research , volume=. 2020 , publisher=
work page 2020
-
[53]
Simple random search provides a competitive approach to reinforcement learning
Simple random search provides a competitive approach to reinforcement learning , author=. arXiv preprint arXiv:1803.07055 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
How much over-parameterization is sufficient to learn deep relu networks? , author=. arXiv preprint arXiv:1911.12360 , year=
-
[55]
Fuqua School of Business, Duke University, Durham, NC , year=
Quadratic approximation of cost functions in lost sales and perishable inventory control problems , author=. Fuqua School of Business, Duke University, Durham, NC , year=
- [56]
-
[57]
Smart “predict, then optimize” , author=. Management Science , volume=. 2022 , publisher=
work page 2022
-
[58]
Solving very large weakly coupled Markov decision processes , author=. AAAI/IAAI , pages=
-
[59]
Multi-Agent Deep Reinforcement Learning for Multi-Echelon Inventory Management , author=. Available at SSRN , year=
-
[60]
arXiv preprint arXiv:2212.07684 , year=
Multi-Agent Reinforcement Learning with Shared Resources for Inventory Management , author=. arXiv preprint arXiv:2212.07684 , year=
-
[61]
International Journal of Production Economics , volume=
Deep Reinforcement Learning for One-Warehouse Multi-Retailer inventory management , author=. International Journal of Production Economics , volume=. 2024 , publisher=
work page 2024
-
[62]
Computers in Industry , volume=
Use of proximal policy optimization for the joint replenishment problem , author=. Computers in Industry , volume=. 2020 , publisher=
work page 2020
-
[63]
The Use of Continuous Action Representations to Scale Deep Reinforcement Learning for Inventory Control , author=
-
[64]
International Journal of Production Research , volume=
Using the proximal policy optimisation algorithm for solving the stochastic capacitated lot sizing problem , author=. International Journal of Production Research , volume=. 2023 , publisher=
work page 2023
-
[65]
Available at SSRN 3901070 , year=
Math programming based reinforcement learning for multi-echelon inventory management , author=. Available at SSRN 3901070 , year=
-
[66]
AI for Decision Optimization Workshop of the AAAI Conference on Artificial Intelligence , year=
Endto-end learning via constraint-enforcing approximators for linear programs with applications to supply chains , author=. AI for Decision Optimization Workshop of the AAAI Conference on Artificial Intelligence , year=
-
[67]
A practical end-to-end inventory management model with deep learning , author=. Management Science , volume=. 2023 , publisher=
work page 2023
-
[68]
arXiv preprint arXiv:2310.18803 , year=
Weakly Coupled Deep Q-Networks , author=. arXiv preprint arXiv:2310.18803 , year=
-
[69]
The near-myopic nature of the lagged-proportional-cost inventory problem with lost sales , author=. Operations Research , volume=. 1971 , publisher=
work page 1971
-
[70]
European Journal of Operational Research , volume=
A typology and literature review on stochastic multi-echelon inventory models , author=. European Journal of Operational Research , volume=. 2018 , publisher=
work page 2018
-
[71]
Deep Reinforcement Learning for Asymmetric One-Warehouse Multi-Retailer Inventory Management , author=. 2021 , publisher=
work page 2021
-
[72]
2023 IMS International Conference on Statistics and Data Science (ICSDS) , pages=
Data science at the singularity , author=. 2023 IMS International Conference on Statistics and Data Science (ICSDS) , pages=
work page 2023
-
[73]
Advances in neural information processing systems , volume=
Imagenet classification with deep convolutional neural networks , author=. Advances in neural information processing systems , volume=
- [74]
-
[75]
The bitter lesson. 2019 , author=. URL http://www. incompleteideas. net/IncIdeas/BitterLesson. html , year=
work page 2019
-
[76]
arXiv preprint arXiv:1912.02178 , year=
Fantastic generalization measures and where to find them , author=. arXiv preprint arXiv:1912.02178 , year=
-
[77]
International conference on machine learning , pages=
A convergence theory for deep learning via over-parameterization , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[78]
Advances in neural information processing systems , volume=
Policy gradient methods for reinforcement learning with function approximation , author=. Advances in neural information processing systems , volume=
-
[79]
Advances in neural information processing systems , volume=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in neural information processing systems , volume=
-
[80]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.