Uncovering the Representation Geometry of Minimal Cores in Overcomplete Reasoning Traces
Pith reviewed 2026-06-30 21:01 UTC · model grok-4.3
The pith
Minimal cores isolate the necessary steps in language model reasoning traces by removing nearly half while preserving answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
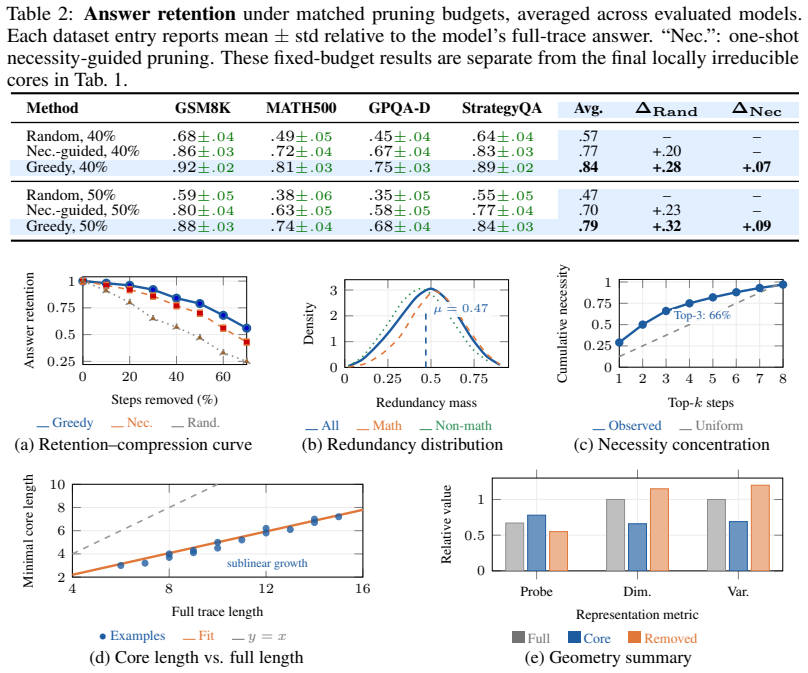
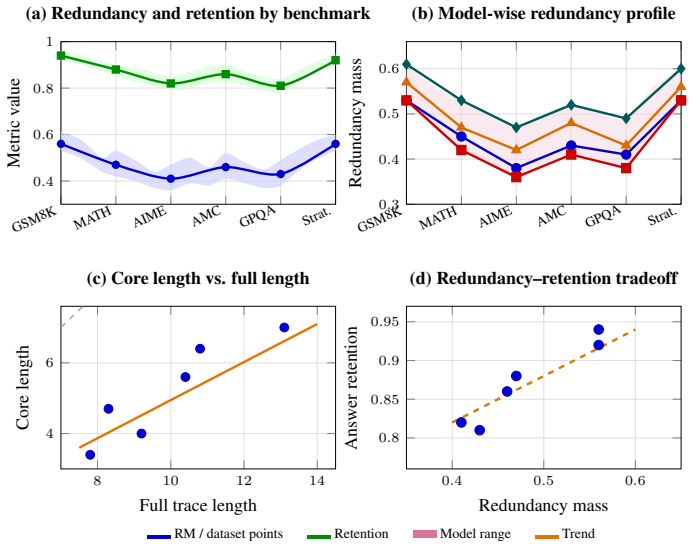
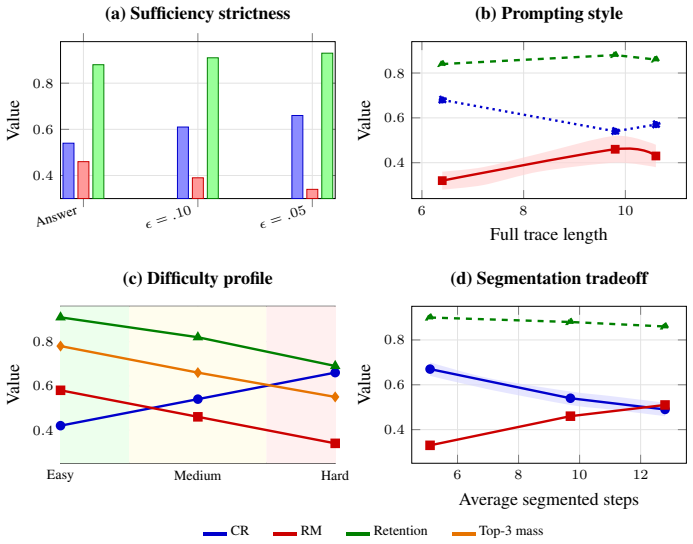
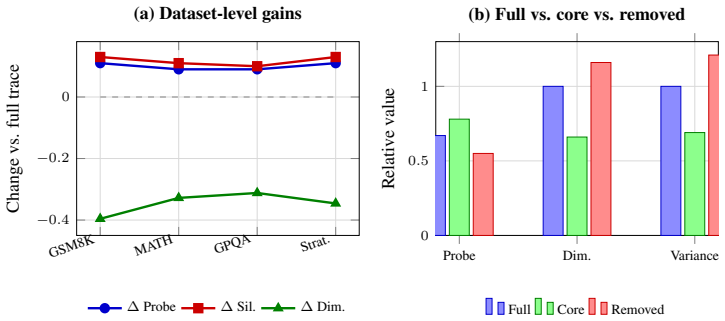
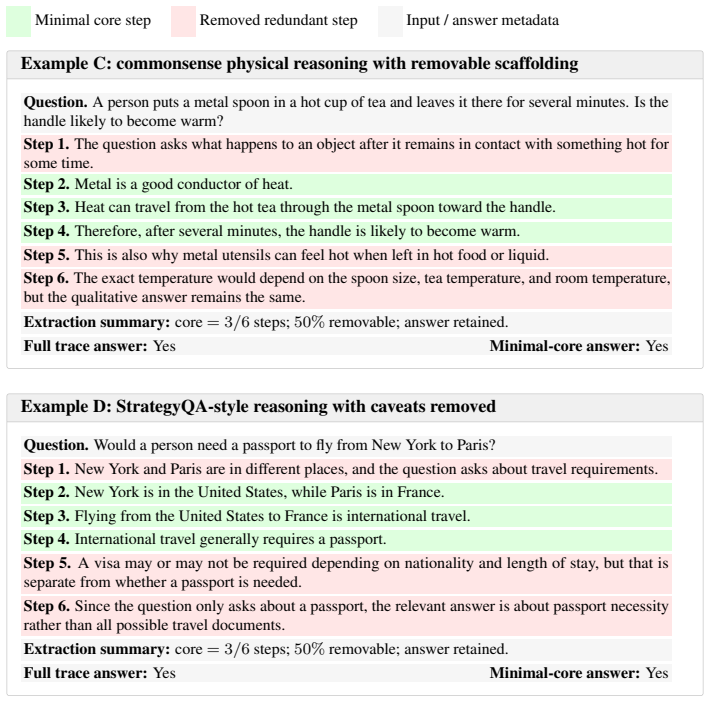
We define the minimal core as the smallest subset of steps that preserves either the final answer or predictive distribution. Across six deliberative reasoning benchmarks spanning arithmetic, competition mathematics, expert scientific reasoning, and commonsense multi-hop QA, we find substantial overcompleteness: on average, 46% of steps are removable under greedy minimal-core extraction while preserving the original answer in 86% of cases. We also find that predictive support is concentrated: the top three steps account for 65% of measured necessity mass on average. Beyond compression, minimal cores expose a cleaner geometry of reasoning: compared with full traces, they improve correct-incor
What carries the argument
The minimal core, defined as the smallest subset of reasoning steps that preserves the final answer or predictive distribution under greedy elimination.
If this is right
- Greedy extraction yields an average compression ratio of 46 percent of steps while retaining the answer in 86 percent of cases.
- Necessity mass concentrates so the top three steps account for 65 percent on average.
- Minimal cores improve correct-incorrect trace separation by 11 points over full traces.
- Estimated intrinsic dimensionality drops 34 percent in minimal cores.
- Minimal cores retain answers at 85 percent when transferred across model families.
Where Pith is reading between the lines
- If minimal cores capture effective support, then generation-time pruning of non-core steps could reduce token usage with little accuracy loss.
- The observed concentration of necessity suggests step-level importance scores could be computed directly from extraction runs for interpretability.
- The geometric improvements imply minimal cores may align more closely with the model's internal decision geometry than full traces do.
- The existence and irreducibility certificates could be turned into practical audits that flag overcomplete traces in deployed systems.
Load-bearing premise
Removing steps while preserving the final answer or predictive distribution means those steps were unnecessary for the model's internal computation.
What would settle it
Running the same model on held-out problems using only the extracted minimal-core steps and observing whether the answer distribution matches the full-trace distribution.
Figures






read the original abstract
Language models often generate long chain-of-thought traces, but it remains unclear how much of this reasoning is necessary for preserving the final prediction. We study this through the lens of overcomplete reasoning traces: generated traces that contain more intermediate steps than are needed to support the model's answer. We define the minimal core as the smallest subset of steps that preserves either the final answer or predictive distribution, and introduce metrics for compression ratio, redundancy mass, step necessity, and necessity concentration. Across six deliberative reasoning benchmarks spanning arithmetic, competition mathematics, expert scientific reasoning, and commonsense multi-hop QA, we find substantial overcompleteness: on average, 46% of steps are removable under greedy minimal-core extraction while preserving the original answer in 86% of cases. We also find that predictive support is concentrated: the top three steps account for 65% of measured necessity mass on average. Beyond compression, minimal cores expose a cleaner geometry of reasoning: compared with full traces, they improve correct-incorrect trace separation by 11 points, reduce estimated intrinsic dimensionality by 34%, and transfer across model families with 85% off-diagonal answer retention. Theoretically, we establish existence of minimal sufficient subsets, local irreducibility guarantees for greedy elimination, and certificates of overcompleteness and sparse necessity. Together, these results suggest that full reasoning traces are often verbose and overcomplete, while minimal cores isolate the effective support underlying language-model predictions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that language model reasoning traces are often overcomplete, defining minimal cores as the smallest subsets of steps preserving the final answer or predictive distribution under greedy extraction. Across six benchmarks it reports 46% average step removability while preserving answers in 86% of cases, with necessity concentrated (top-3 steps account for 65% of necessity mass), plus geometric gains (11-point improvement in correct-incorrect separation, 34% reduction in intrinsic dimensionality) and 85% cross-model transfer. Theoretical results establish existence of minimal sufficient subsets and local irreducibility of the extraction procedure.
Significance. If the interpretation linking output preservation to internal effective support were substantiated, the work would supply concrete compression metrics and geometric diagnostics for reasoning traces, with implications for interpretability and efficiency. The scale of the empirical survey and the existence/irreducibility theorems would constitute a useful contribution to the study of verbose CoT traces.
major comments (1)
- [Abstract] Abstract: The claim that minimal cores 'isolate the effective support underlying language-model predictions' and expose a 'cleaner geometry of reasoning' is not supported by evidence that removed steps are irrelevant to the model's internal forward pass. All metrics (necessity mass, necessity concentration, separation, dimensionality) are computed solely from output invariance under greedy elimination; the manuscript describes no causal interventions on hidden states, attention ablation, or logit-lens probes on intermediate tokens that would confirm internal routing through the retained steps. This gap is load-bearing for the representation-geometry claims in the title and abstract.
minor comments (2)
- The abstract states results across six benchmarks without reporting per-benchmark breakdowns, sample sizes, or confidence intervals on the headline percentages (46%, 86%, 65%, 11 points, 34%, 85%), making it difficult to assess robustness or variability.
- Notation for the necessity-mass and necessity-concentration metrics is introduced in the abstract but not connected to the precise definition of the greedy extraction procedure or to the theoretical certificates mentioned later.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The major comment correctly identifies that our claims about isolating effective support and representation geometry rest on output-based metrics rather than internal causal evidence. We address this below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that minimal cores 'isolate the effective support underlying language-model predictions' and expose a 'cleaner geometry of reasoning' is not supported by evidence that removed steps are irrelevant to the model's internal forward pass. All metrics (necessity mass, necessity concentration, separation, dimensionality) are computed solely from output invariance under greedy elimination; the manuscript describes no causal interventions on hidden states, attention ablation, or logit-lens probes on intermediate tokens that would confirm internal routing through the retained steps. This gap is load-bearing for the representation-geometry claims in the title and abstract.
Authors: We agree that the manuscript provides no causal interventions, hidden-state ablations, or logit-lens analyses to establish that removed steps are irrelevant to the internal forward pass. All reported metrics (necessity mass, concentration, separation, and dimensionality reduction) are defined strictly in terms of output invariance under greedy step elimination. The interpretation that minimal cores isolate 'effective support underlying language-model predictions' is therefore an inference from behavioral necessity rather than direct internal evidence. To correct this, we will revise the abstract, title, and introduction to frame the contribution in terms of output-preserving minimal cores and their observable geometric properties in the space of reasoning traces. We will also add an explicit limitations paragraph stating that the work does not claim to identify internal routing or causal support within the model. These changes will be made in the next revision. revision: yes
Circularity Check
No circularity: operational definitions and empirical measurements are independent of target claims
full rationale
The paper defines the minimal core explicitly as the smallest subset preserving final answer or predictive distribution under greedy extraction, then computes compression ratio, necessity mass, and geometric metrics directly from that procedure and model outputs. Theoretical results establish existence and local irreducibility via standard set-theoretic arguments without self-referential equations or fitted parameters. No load-bearing step reduces to a self-citation, ansatz smuggled via prior work, or renaming of known results; all quantities are measured from the defined extraction process itself. The interpretation linking output preservation to internal necessity is interpretive rather than a derivation that collapses by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, 2022
2022
-
[2]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems, 2022
2022
-
[3]
Least-to-most prompting enables complex reasoning in large language models
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, and Ed Chi. Least-to-most prompting enables complex reasoning in large language models. InInternational Conference on Learning Representations, 2023
2023
-
[4]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, 2023
2023
-
[5]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations, 2023
2023
-
[6]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Jinyan Su, Jennifer Healey, Preslav Nakov, and Claire Cardie. Between underthinking and overthinking: An empirical study of reasoning length and correctness in llms.arXiv preprint arXiv:2505.00127, 2025
-
[8]
Roy Eisenstadt, Itamar Zimerman, and Lior Wolf. Overclocking llm reasoning: Monitoring and controlling thinking path lengths in llms.arXiv preprint arXiv:2506.07240, 2025
-
[9]
Efficient reasoning models: A survey.arXiv preprint arXiv:2504.10903, 2025
Sicheng Feng, Gongfan Fang, Xinyin Ma, and Xinchao Wang. Efficient reasoning models: A survey.arXiv preprint arXiv:2504.10903, 2025
-
[10]
Xiaoye Qu, Yafu Li, Zhao-Chen Su, Weigao Sun, Jianhao Yan, Dongrui Liu, Ganqu Cui, Daizong Liu, Shuxian Liang, Junxian He, et al. A survey of efficient reasoning for large reasoning models: Language, multimodality, and beyond.arXiv preprint arXiv:2503.21614, 2025
-
[11]
Reasoning models can be effective without thinking.arXiv preprint arXiv:2504.09858, 2025
Wenjie Ma, Jingxuan He, Charlie Snell, Tyler Griggs, Sewon Min, and Matei Zaharia. Reasoning models can be effective without thinking.arXiv preprint arXiv:2504.09858, 2025
-
[12]
Michael Hassid, Gabriel Synnaeve, Yossi Adi, and Roy Schwartz. Don’t overthink it. preferring shorter thinking chains for improved llm reasoning.arXiv preprint arXiv:2505.17813, 2025
-
[13]
Jundong Xu, Hao Fei, Huichi Zhou, Xin Quan, Qijun Huang, Shengqiong Wu, William Yang Wang, Mong-Li Lee, and Wynne Hsu. Logicreward: Incentivizing llm reasoning via step-wise logical supervision.arXiv preprint arXiv:2512.18196, 2025
-
[14]
General- reasoner: Advancing llm reasoning across all domains.arXiv preprint arXiv:2505.14652, 2025
Xueguang Ma, Qian Liu, Dongfu Jiang, Ge Zhang, Zejun Ma, and Wenhu Chen. General- reasoner: Advancing llm reasoning across all domains.arXiv preprint arXiv:2505.14652, 2025
-
[15]
Code execution as grounded supervision for llm reasoning
Dongwon Jung, Wenxuan Zhou, and Muhao Chen. Code execution as grounded supervision for llm reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 24822–24833, 2025
2025
-
[16]
Keyu Zhao, Fengli Xu, and Yong Li. Reason-to-recommend: Using interaction-of-thought reasoning to enhance llm recommendation.arXiv preprint arXiv:2506.05069, 2025
-
[17]
Reasoning aware self-consistency: Leveraging reasoning paths for efficient llm sampling
Guangya Wan, Yuqi Wu, Jie Chen, and Sheng Li. Reasoning aware self-consistency: Leveraging reasoning paths for efficient llm sampling. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3613–3635, 2025
2025
-
[18]
Zhi Zhou, Yuhao Tan, Zenan Li, Yuan Yao, Lan-Zhe Guo, Yu-Feng Li, and Xiaoxing Ma. A theoretical study on bridging internal probability and self-consistency for llm reasoning.arXiv preprint arXiv:2510.15444, 2025. 11
-
[19]
Confidence improves self-consistency in llms
Amir Taubenfeld, Tom Sheffer, Eran Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, and Gal Yona. Confidence improves self-consistency in llms. InFindings of the Association for Computational Linguistics: ACL 2025, pages 20090–20111, 2025
2025
-
[20]
Kongcheng Zhang, Qi Yao, Shunyu Liu, Yingjie Wang, Baisheng Lai, Jieping Ye, Mingli Song, and Dacheng Tao. Consistent paths lead to truth: Self-rewarding reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.08745, 2025
-
[21]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. Star: Bootstrapping reasoning with reasoning. InAdvances in Neural Information Processing Systems, 2022
2022
-
[22]
Xiaoyu Tian, Sitong Zhao, Haotian Wang, Shuaiting Chen, Yunjie Ji, Yiping Peng, Han Zhao, and Xiangang Li. Think twice: Enhancing llm reasoning by scaling multi-round test-time thinking.arXiv preprint arXiv:2503.19855, 2025
-
[23]
Atom of thoughts for markov llm test-time scaling.arXiv preprint arXiv:2502.12018, 2025
Fengwei Teng, Quan Shi, Zhaoyang Yu, Jiayi Zhang, Yuyu Luo, Chenglin Wu, and Zhijiang Guo. Atom of thoughts for markov llm test-time scaling.arXiv preprint arXiv:2502.12018, 2025
-
[24]
Wenkai Yang, Shuming Ma, Yankai Lin, and Furu Wei. Towards thinking-optimal scaling of test-time compute for llm reasoning.arXiv preprint arXiv:2502.18080, 2025
-
[25]
Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[26]
LIMO: Less is More for Reasoning
Tian Ye, Zicheng Xu, Yuanzhi Li, and Zeyuan Allen-Zhu. Limo: Less is more for reasoning. arXiv preprint arXiv:2502.03387, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling.arXiv preprint arXiv:2501.19393, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Yubo Wang, Yuhui Li, Zhiwei Zhang, and Wenhu Chen. Trims: Real-time tracking of minimal sufficient length for efficient reasoning via reinforcement learning.arXiv preprint arXiv:2603.17449, 2026
-
[30]
Surgical trimming: Minimal sufficient chain of thought with razorreward-rl.arXiv preprint, 2025
Xinyu Chen, Zihan Liu, Kai Zhang, and Yizhong Wang. Surgical trimming: Minimal sufficient chain of thought with razorreward-rl.arXiv preprint, 2025
2025
-
[31]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational Conference on Machine Learning, pages 3519–3529, 2019
2019
-
[32]
John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representations. InProceedings of NAACL-HLT, pages 4129–4138, 2019
2019
-
[33]
Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, 2022
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, 2022
2022
-
[34]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InProceedings of ACL-IJCNLP, pages 7319–7328, 2021
2021
-
[35]
Inference- time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model. InAdvances in Neural Information Processing Systems, 2023
2023
-
[36]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. InarXiv preprint arXiv:2110.14168, 2021. 12
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[38]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[39]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. In Transactions of the Association for Computational Linguistics, volume 9, pages 346–361, 2021
2021
-
[41]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[42]
Rousseeuw
Peter J. Rousseeuw. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis.Journal of Computational and Applied Mathematics, 20:53–65, 1987
1987
-
[43]
A cluster separation measure.IEEE transactions on pattern analysis and machine intelligence, (2):224–227, 1979
David L Davies and Donald W Bouldin. A cluster separation measure.IEEE transactions on pattern analysis and machine intelligence, (2):224–227, 1979
1979
-
[44]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URLhttps://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Ansh Radhakrishnan, Karina Nguyen, Anna Chen, Carol Chen, Carson Denison, Danny Her- nandez, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamil ˙e Lukoši¯ut˙e, et al. Ques- tion decomposition improves the faithfulness of model-generated reasoning.arXiv preprint arXiv:2307.11768, 2023
-
[48]
Chain-of-question: A progressive question decomposition approach for complex knowledge base question answering
Peng Yixing, Quan Wang, Licheng Zhang, Yi Liu, and Zhendong Mao. Chain-of-question: A progressive question decomposition approach for complex knowledge base question answering. InFindings of the Association for Computational Linguistics: ACL 2024, pages 4763–4776, 2024
2024
-
[49]
Chain-in-Tree: Back to Sequential Reasoning in LLM Tree Search
Xinzhe Li. Chain-in-tree: Back to sequential reasoning in llm tree search.arXiv preprint arXiv:2509.25835, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Verify-and-edit: A knowledge-enhanced chain-of-thought framework
Ruochen Zhao, Xingxuan Li, Shafiq Joty, Chengwei Qin, and Lidong Bing. Verify-and-edit: A knowledge-enhanced chain-of-thought framework. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5823–5840, 2023
2023
-
[51]
Deductive verification of chain-of-thought reasoning.Advances in Neural Information Processing Systems, 36:36407–36433, 2023
Zhan Ling, Yunhao Fang, Xuanlin Li, Zhiao Huang, Mingu Lee, Roland Memisevic, and Hao Su. Deductive verification of chain-of-thought reasoning.Advances in Neural Information Processing Systems, 36:36407–36433, 2023
2023
-
[52]
Making slow thinking faster: Compressing llm chain-of-thought via step entropy
Zeju Li, Jianyuan Zhong, Ziyang Zheng, Xiangyu Wen, Zhijian Xu, Yingying Cheng, Fan Zhang, and Qiang Xu. Making slow thinking faster: Compressing llm chain-of-thought via step entropy. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[53]
Melody Zixuan Li, Kumar Krishna Agrawal, Arna Ghosh, Komal Kumar Teru, Adam Santoro, Guillaume Lajoie, and Blake A Richards. Tracing the representation geometry of language models from pretraining to post-training.arXiv preprint arXiv:2509.23024, 2025
-
[54]
LLM Reasoning as Trajectories: Step-Specific Representation Geometry and Correctness Signals
Lihao Sun, Hang Dong, Bo Qiao, Qingwei Lin, Dongmei Zhang, and Saravan Rajmohan. Llm reasoning as trajectories: Step-specific representation geometry and correctness signals.arXiv preprint arXiv:2604.05655, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
BERT rediscovers the classical NLP pipeline
Ian Tenney, Dipanjan Das, and Ellie Pavlick. BERT rediscovers the classical NLP pipeline. In Proceedings of ACL, pages 4593–4601, 2019
2019
-
[56]
How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings. InProceedings of EMNLP-IJCNLP, pages 55–65, 2019. 13
2019
-
[57]
Truthx: Alleviating hallucinations by editing large language models in truthful space
Shaolei Zhang, Tian Yu, and Yang Feng. Truthx: Alleviating hallucinations by editing large language models in truthful space. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8908–8949, 2024
2024
-
[58]
Personas as a way to model truthfulness in language models
Nitish Joshi, Javier Rando, Abulhair Saparov, Najoung Kim, and He He. Personas as a way to model truthfulness in language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6346–6359, 2024
2024
-
[59]
Kevin Liu, Stephen Casper, Dylan Hadfield-Menell, and Jacob Andreas. Cognitive dissonance: Why do language model outputs disagree with internal representations of truthfulness? In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4791–4797, 2023
2023
-
[60]
Thomas Savage, John Wang, Robert Gallo, Abdessalem Boukil, Vishwesh Patel, Seyed Amir Ah- mad Safavi-Naini, Ali Soroush, and Jonathan H Chen. Large language model uncertainty proxies: discrimination and calibration for medical diagnosis and treatment.Journal of the American Medical Informatics Association, 32(1):139–149, 2025
2025
-
[61]
Allen Z Ren, Anushri Dixit, Alexandra Bodrova, Sumeet Singh, Stephen Tu, Noah Brown, Peng Xu, Leila Takayama, Fei Xia, Jake Varley, et al. Robots that ask for help: Uncertainty alignment for large language model planners.arXiv preprint arXiv:2307.01928, 2023
-
[62]
Uncertainty quantification and confidence calibration in large language models: A survey
Xiaoou Liu, Tiejin Chen, Longchao Da, Chacha Chen, Zhen Lin, and Hua Wei. Uncertainty quantification and confidence calibration in large language models: A survey. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 6107–6117, 2025
2025
-
[63]
Discovering latent knowledge in language models without supervision.International Conference on Learning Representations, 2023
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision.International Conference on Learning Representations, 2023
2023
-
[64]
Linearity of relation decoding in transformer language models.arXiv preprint arXiv:2308.09124, 2023
Evan Hernandez, Arnab Sen Sharma, Tal Haklay, Kevin Meng, Martin Wattenberg, Jacob Andreas, Yonatan Belinkov, and David Bau. Linearity of relation decoding in transformer language models.arXiv preprint arXiv:2308.09124, 2023
-
[65]
Rationalizing neural predictions
Tao Lei, Regina Barzilay, and Tommi Jaakkola. Rationalizing neural predictions. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 107–117, 2016
2016
-
[66]
Sarthak Jain and Byron C. Wallace. Attention is not explanation. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3543–3556, 2019
2019
-
[67]
Attention is not not explanation
Sarah Wiegreffe and Yuval Pinter. Attention is not not explanation. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 11–20, 2019
2019
-
[68]
Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher, and Byron C. Wallace. ERASER: A benchmark to evaluate rationalized NLP models. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4443–4458, 2020
2020
-
[69]
Alon Jacovi and Yoav Goldberg. Towards faithfully interpretable NLP systems: How should we define and evaluate faithfulness? InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4198–4205, 2020
2020
-
[70]
Causal scrubbing, a method for rigorously testing interpretability hypotheses
Lawrence Chan, Adrià Garriga-Alonso, Nicholas Goldowsky-Dill, Ryan Greenblatt, Ekaterina Nitishinskaya, Ansh Radhakrishnan, Buck Shlegeris, and Nate Thomas. Causal scrubbing, a method for rigorously testing interpretability hypotheses. InNeurIPS ML Safety Workshop, 2022
2022
-
[71]
Sanjoy Chowdhury, Karren D Yang, Xudong Liu, Fartash Faghri, Pavan Kumar Anasosalu Vasu, Oncel Tuzel, Dinesh Manocha, Chun-Liang Li, and Raviteja Vemulapalli. Amuse: Audio-visual benchmark and alignment framework for agentic multi-speaker understanding.arXiv preprint arXiv:2512.16250, 2025
-
[72]
14 Egoadapt: Adaptive multisensory distillation and policy learning for efficient egocentric percep- tion
Sanjoy Chowdhury, Subrata Biswas, Sayan Nag, Tushar Nagarajan, Calvin Murdock, Ish- warya Ananthabhotla, Yijun Qian, Vamsi Krishna Ithapu, Dinesh Manocha, and Ruohan Gao. 14 Egoadapt: Adaptive multisensory distillation and policy learning for efficient egocentric percep- tion. InProceedings of the IEEE/CVF International Conference on Computer Vision, page...
2025
-
[73]
Magnet: A multi-agent framework for finding audio-visual needles by reasoning over multi-video haystacks.Advances in Neural Information Processing Systems, 38:49255–49291, 2026
Sanjoy Chowdhury, Mohamed Elmoghany, Yohan Abeysinghe, Junjie Fei, Sayan Nag, Salman Khan, Mohamed Elhoseiny, and Dinesh Manocha. Magnet: A multi-agent framework for finding audio-visual needles by reasoning over multi-video haystacks.Advances in Neural Information Processing Systems, 38:49255–49291, 2026
2026
-
[74]
Aurelia: Test-time reasoning distillation in audio-visual llms
Sanjoy Chowdhury, Hanan Gani, Nishit Anand, Sayan Nag, Ruohan Gao, Mohamed Elhoseiny, Salman Khan, and Dinesh Manocha. Aurelia: Test-time reasoning distillation in audio-visual llms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22899–22910, 2025
2025
-
[75]
Avtrustbench: Assessing and enhancing reliability and robustness in audio-visual llms
Sanjoy Chowdhury, Sayan Nag, Subhrajyoti Dasgupta, Yaoting Wang, Mohamed Elhoseiny, Ruohan Gao, and Dinesh Manocha. Avtrustbench: Assessing and enhancing reliability and robustness in audio-visual llms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1590–1601, 2025
2025
-
[76]
Meerkat: Audio-visual large language model for grounding in space and time
Sanjoy Chowdhury, Sayan Nag, Subhrajyoti Dasgupta, Jun Chen, Mohamed Elhoseiny, Ruohan Gao, and Dinesh Manocha. Meerkat: Audio-visual large language model for grounding in space and time. InEuropean Conference on Computer Vision, pages 52–70. Springer, 2024
2024
-
[77]
Melfusion: Synthesizing music from image and language cues using diffusion models
Sanjoy Chowdhury, Sayan Nag, KJ Joseph, Balaji Vasan Srinivasan, and Dinesh Manocha. Melfusion: Synthesizing music from image and language cues using diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26826–26835, 2024
2024
-
[78]
Apollo: Unified adapter and prompt learning for vision language models
Sanjoy Chowdhury, Sayan Nag, and Dinesh Manocha. Apollo: Unified adapter and prompt learning for vision language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10173–10187, 2023
2023
-
[79]
Aura: A fine-grained benchmark and decomposed metric for audio-visual reasoning
Siminfar Samakoush Galougah, Rishie Raj, Sanjoy Chowdhury, Sayan Nag, and Ramani Du- raiswami. Aura: A fine-grained benchmark and decomposed metric for audio-visual reasoning. arXiv preprint arXiv:2508.07470, 2025. 15 Appendices A Implementation Details 17 B Proof Details 19 B.1 Existence of Minimal Cores . . . . . . . . . . . . . . . . . . . . . . . . . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.