Recognition: 2 theorem links
· Lean TheoremAutomated Curriculum Design for High-dimensional Human Motor Learning
Pith reviewed 2026-05-15 02:31 UTC · model grok-4.3
The pith
A framework using motor learning models and stochastic nonlinear MPC designs curricula that speed skill acquisition by about 23 percent over random schedules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
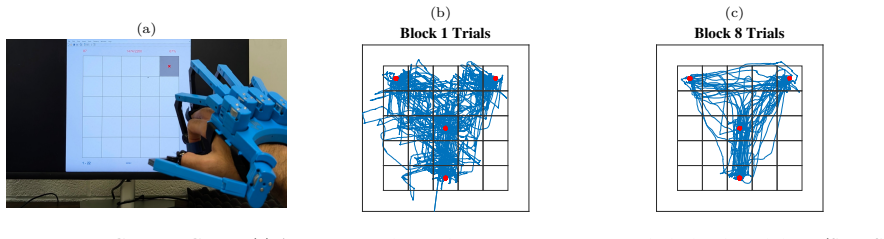
The paper shows that an automated curriculum design system built from a human motor learning model and real-time skill estimation, embedded inside stochastic nonlinear model predictive control, selects task sequences that accelerate skill acquisition in de-novo high-dimensional motor tasks. Validation occurred through both numerical simulations and a controlled human-subject experiment with 36 participants operating a hand exoskeleton. The method delivered measurable reductions in time to reach target skill levels compared with random and heuristic baselines.
What carries the argument
Stochastic nonlinear model predictive control that optimizes task selection by predicting future skill evolution from the motor learning model and current skill estimates.
Load-bearing premise
The human motor learning model together with real-time skill estimation correctly infers the hidden internal skill states that the control algorithm needs to choose good tasks.
What would settle it
A new controlled human experiment on a comparable high-dimensional motor task in which the proposed curriculum produces learning rates equal to or slower than a random schedule would falsify the claim.
Figures







read the original abstract
Designing effective practice schedules for high-dimensional motor learning tasks remains a challenge, especially when skill states are unobservable and task performance may not reflect the true learning. We propose an automated curriculum design framework that combines a human motor learning model and personalized real-time skill estimation with Stochastic Nonlinear Model Predictive Control in \emph{de-novo} (novel) motor learning paradigms. We validated our framework both through simulations and human-subject studies (N = 36) using a hand exoskeleton. Our proposed approach accelerates skill acquisition by $\sim23\%$, and ${\sim17\%}$ when compared to a random curriculum and a performance heuristics-based curriculum, respectively. These significant gains in learning efficiency highlight the potential of model-based, individualized curricula for motor rehabilitation and complex skill training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an automated curriculum design framework for high-dimensional de-novo motor learning tasks. It integrates a human motor learning model with personalized real-time skill estimation and Stochastic Nonlinear Model Predictive Control (SNMPC) to select individualized practice schedules. Validation consists of simulations plus a human-subject study (N=36) using a hand exoskeleton, with the central claim that the approach accelerates skill acquisition by approximately 23% relative to a random curriculum and 17% relative to a performance-heuristics curriculum.
Significance. If the results hold, the work could meaningfully advance motor rehabilitation and complex skill training by showing that model-based, individualized curricula outperform standard baselines. The combination of a control-theoretic optimizer with human-subject experiments is a clear strength, and the N=36 study provides direct empirical grounding. However, the significance is limited by the absence of independent validation that the estimator recovers unobservable skill states rather than performance artifacts.
major comments (2)
- [Human-Subject Validation] Human-Subject Validation section: the N=36 study reports only task performance curves; no retention test, transfer task, or other ground-truth probe is described that would confirm the real-time skill estimator tracks the latent learning state rather than observable performance. Because the SNMPC curriculum selection depends on these estimates, this gap directly undermines the claim that the observed gains reflect accelerated learning rather than metric-specific effects.
- [Simulation Validation] Simulation Validation section: simulations assume the human motor learning model is correct by construction and therefore cannot falsify the link between estimated skill states and true learning; they provide no independent support for the human-experiment results that rely on the same unobservable-state premise.
minor comments (1)
- [Abstract] Abstract: the reported percentages should be accompanied by the statistical test and p-value used to establish significance, and the exact definition of 'skill acquisition' (e.g., time to reach a performance threshold) should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of validating unobservable skill states in our framework. We address each major comment below and have revised the manuscript accordingly where feasible.
read point-by-point responses
-
Referee: [Human-Subject Validation] Human-Subject Validation section: the N=36 study reports only task performance curves; no retention test, transfer task, or other ground-truth probe is described that would confirm the real-time skill estimator tracks the latent learning state rather than observable performance. Because the SNMPC curriculum selection depends on these estimates, this gap directly undermines the claim that the observed gains reflect accelerated learning rather than metric-specific effects.
Authors: We agree that retention or transfer tests would provide stronger direct evidence that the estimator captures latent learning states rather than performance artifacts. Designing suitable transfer tasks for this high-dimensional de-novo paradigm is nontrivial, which is why the study focused on acquisition-phase performance as the primary metric. The superior outcomes relative to the performance-heuristics baseline (which uses only observable metrics) provide indirect support that the model-based estimates add value. We have added a dedicated paragraph in the revised Discussion section acknowledging this limitation and outlining future work with retention and transfer probes. revision: yes
-
Referee: [Simulation Validation] Simulation Validation section: simulations assume the human motor learning model is correct by construction and therefore cannot falsify the link between estimated skill states and true learning; they provide no independent support for the human-experiment results that rely on the same unobservable-state premise.
Authors: The simulations are intended only to verify the SNMPC optimizer and curriculum logic under the assumption that the model holds, serving as a controlled proof-of-concept for the control framework. They are not presented as independent validation of the human motor learning model. The N=36 human experiments constitute the primary empirical test. We have clarified this scope and role of the simulations in the revised Simulation Validation section. revision: partial
Circularity Check
No significant circularity; central claims rest on external human validation
full rationale
The paper's derivation uses a human motor learning model plus real-time estimator inside stochastic nonlinear MPC to generate curricula. However, the load-bearing performance claims (~23% and ~17% acceleration) are measured directly from observable task performance in an independent N=36 human-subject study on a hand exoskeleton, not recovered from the same fitted parameters or simulations that assume the model. No self-definitional equations, fitted-input predictions, or self-citation chains appear in the abstract or described framework; the human data serve as an external benchmark. The derivation chain is therefore self-contained against those benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the human motor learning model
axioms (1)
- domain assumption Skill states are unobservable and task performance does not directly reflect true learning progress
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose an automated curriculum design framework that combines a human motor learning model and personalized real-time skill estimation with Stochastic Nonlinear Model Predictive Control
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ℓj = βW ‖˜Wj‖² + βRE ∥REυ∥² + βSoT ∥SoTυ∥²
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
R. A. Schmidt, T. D. Lee, C. Winstein, G. Wulf, and H. N. Zelaznik, Motor Control and Learning: A Behavioral Emphasis . Human Kinetics, 2018
work page 2018
-
[2]
Individualized challenge point practice as a method to aid motor sequence learning,
K. P. Wadden, N. J. Hodges, K. L. D. Asis, J. L. Neva, and L. A. Boyd, “Individualized challenge point practice as a method to aid motor sequence learning,” Journal of Motor Behavior , vol. 51, no. 5, pp. 467–485, 2019
work page 2019
-
[3]
Dynamic difficulty adjustment (DDA) in computer games: A review,
H. Nakanishi and M. Zohaib, “Dynamic difficulty adjustment (DDA) in computer games: A review,” Advances in Human-Computer Interaction , vol. 2018, p. 5681652, 2018
work page 2018
-
[4]
Learning control in robot-assisted rehabilitation of motor skills: A review,
S.-H. Zhou, J. Fong, V. Crocher, Y. Tan, D. Oetomo, and I. Mareels, “Learning control in robot-assisted rehabilitation of motor skills: A review,” Journal of Control and Decision , vol. 3, no. 1, pp. 19–43, 2016
work page 2016
-
[5]
Interactive curriculum learning increases and homogenizes motor smoothness,
V. Sungeelee, A. Loriette, O. Sigaud, and B. Caramiaux, “Interactive curriculum learning increases and homogenizes motor smoothness,” Scientific Reports, vol. 14, no. 1, p. 2843, 2024
work page 2024
-
[6]
Evalu- ating rehabilitation progress using motion features identified by machine learning,
L. Lu, Y. Tan, M. Klaic, M. P. Galea, F. Khan, A. Oliver, I. Mareels, D. Oetomo, and E. Zhao, “Evalu- ating rehabilitation progress using motion features identified by machine learning,” IEEE Transactions on Biomedical Engineering , vol. 68, no. 4, pp. 1417–1428, 2021
work page 2021
-
[7]
J.-C. Metzger, O. Lambercy, A. Califfi, D. Dinacci, C. Petrillo, P. Rossi, F. M. Conti, and R. Gassert, “Assessment-driven selection and adaptation of exercise difficulty in robot-assisted therapy: A pilot study with a hand rehabilitation robot,” Journal of NeuroEngineering and Rehabilitation , vol. 11, no. 1, p. 154, 2014
work page 2014
-
[8]
Capturing skill state in curriculum learning for human skill acquisition,
K. Ghonasgi, R. Mirsky, S. Narvekar, B. Masetty, A. M. Haith, P. Stone, and A. D. Deshpande, “Capturing skill state in curriculum learning for human skill acquisition,” in IEEE/RSJ International Conference on Intelligent Robots and Systems , 2021, pp. 771–776
work page 2021
-
[9]
S. S. Kantak and C. J. Winstein, “Learning–performance distinction and memory processes for motor skills: A focused review and perspective,” Behavioural Brain Research , vol. 228, no. 1, pp. 219–231, 2012
work page 2012
-
[10]
Contextual interference effects on the acquisition, retention, and transfer of a motor skill
J. B. Shea and R. L. Morgan, “Contextual interference effects on the acquisition, retention, and transfer of a motor skill. ” Journal of Experimental Psychology: Human Learning and Memory , vol. 5, no. 2, p. 179, 1979
work page 1979
-
[11]
A. Ammar, K. Trabelsi, M. A. Boujelbane, O. Boukhris, J. M. Glenn, H. Chtourou, and W. I. Schöllhorn, “The myth of contextual interference learning benefit in sports practice: A systematic review and meta- analysis,” Educational Research Review, vol. 39, p. 100537, 2023. 12
work page 2023
-
[12]
Contextual interference: A meta-analytic study,
F. Brady, “Contextual interference: A meta-analytic study,” Perceptual and Motor Skills , vol. 99, no. 1, pp. 116–126, 2004
work page 2004
-
[13]
Performance-based adaptive schedules enhance motor learning,
Y. Choi, F. Qi, J. Gordon, and N. Schweighofer, “Performance-based adaptive schedules enhance motor learning,” Journal of Motor Behavior , vol. 40, no. 4, pp. 273–280, 2008
work page 2008
-
[14]
C. Wang, L. Peng, and Z.-G. Hou, “A control framework for adaptation of training task and robotic assistance for promoting motor learning with an upper limb rehabilitation robot,” IEEE Transactions on Systems, Man, and Cybernetics: Systems , vol. 52, no. 12, pp. 7737–7747, 2022
work page 2022
-
[15]
Rowing simulator modulates water density to foster motor learning,
E. Basalp, L. Marchal-Crespo, G. Rauter, R. Riener, and P. Wolf, “Rowing simulator modulates water density to foster motor learning,” Frontiers in Robotics and AI , vol. 6, p. 74, 2019
work page 2019
-
[16]
V. A. Swanson, C. Johnson, D. K. Zondervan, N. Bayus, P. McCoy, Y. F. J. Ng, B. Jenna Schindele, D. J. Reinkensmeyer, and S. Shaw, “Optimized home rehabilitation technology reduces upper extremity impairment compared to a conventional home exercise program: A randomized, controlled, single-blind trial in subacute stroke,” Neurorehabilitation and Neural Re...
work page 2023
-
[17]
Human motor learning dynamics in high- dimensional tasks,
A. Kamboj, R. Ranganathan, X. Tan, and V. Srivastava, “Human motor learning dynamics in high- dimensional tasks,” PLOS Computational Biology , vol. 20, no. 10, p. e1012455, 2024
work page 2024
-
[18]
Expediting human motor learning in high-dimensional de-novo tasks via online curriculum de- sign,
——, “Expediting human motor learning in high-dimensional de-novo tasks via online curriculum de- sign,” in American Control Conference, Denver, CO, 2025, pp. 4641–4646
work page 2025
-
[19]
Forward models: Supervised learning with a distal teacher,
M. I. Jordan and D. E. Rumelhart, “Forward models: Supervised learning with a distal teacher,” Cognitive Science, vol. 16, no. 3, pp. 307–354, 1992
work page 1992
-
[20]
An internal model for sensorimotor integration,
D. M. Wolpert, Z. Ghahramani, and M. I. Jordan, “An internal model for sensorimotor integration,” Science, vol. 269, no. 5232, pp. 1880–1882, 1995
work page 1995
- [21]
-
[22]
The uncontrolled manifold concept: Identifying control variables for a functional task,
J. P. Scholz and G. Schöner, “The uncontrolled manifold concept: Identifying control variables for a functional task,” Experimental Brain Research, vol. 126, no. 3, pp. 289–306, 1999
work page 1999
-
[23]
Identifying the control structure of multijoint coordination during pistol shooting,
J. P. Scholz, G. Schöner, and M. L. Latash, “Identifying the control structure of multijoint coordination during pistol shooting,” Experimental Brain Research, vol. 135, no. 3, pp. 382–404, 2000
work page 2000
-
[24]
Win-shift, lose-stay: Contingent switching and contextual interference in motor learning,
D. A. Simon, T. D. Lee, and J. D. Cullen, “Win-shift, lose-stay: Contingent switching and contextual interference in motor learning,” Perceptual and Motor Skills , vol. 107, no. 2, pp. 407–418, 2008
work page 2008
-
[25]
M. A. Guadagnoli and T. D. Lee, “Challenge point: A framework for conceptualizing the effects of various practice conditions in motor learning,” Journal of Motor Behavior , vol. 36, no. 2, pp. 212–224, 2004
work page 2004
-
[26]
Toward a new theory of motor synergies,
M. L. Latash, J. P. Scholz, and G. Schöner, “Toward a new theory of motor synergies,” Motor Control, vol. 11, no. 3, pp. 276–308, 2007
work page 2007
-
[27]
Feed-forward control of a redundant motor system,
S. R. Goodman and M. L. Latash, “Feed-forward control of a redundant motor system,” Biological Cybernetics, vol. 95, no. 3, pp. 271–280, 2006
work page 2006
-
[28]
Assist-as-needed exoskele- ton for hand joint rehabilitation based on muscle effort detection,
J. C. Castiblanco, I. F. Mondragon, C. Alvarado-Rojas, and J. D. Colorado, “Assist-as-needed exoskele- ton for hand joint rehabilitation based on muscle effort detection,” Sensors, vol. 21, no. 13, p. 4372, 2021
work page 2021
-
[29]
Subject-specific assist-as-needed controllers for a hand exoskeleton for rehabilitation,
P. Agarwal and A. D. Deshpande, “Subject-specific assist-as-needed controllers for a hand exoskeleton for rehabilitation,” IEEE Robotics and Automation Letters , vol. 3, no. 1, pp. 508–515, 2017. 13
work page 2017
-
[30]
Robot-assisted adaptive training: Custom force fields for teaching movement patterns,
J. L. Patton and F. A. Mussa-Ivaldi, “Robot-assisted adaptive training: Custom force fields for teaching movement patterns,” IEEE Transactions on Biomedical Engineering , vol. 51, no. 4, pp. 636–646, 2004
work page 2004
-
[31]
Human-in-the-loop optimization of exoskeleton assistance during walking,
J. Zhang, P. Fiers, K. A. Witte, R. W. Jackson, K. L. Poggensee, C. G. Atkeson, and S. H. Collins, “Human-in-the-loop optimization of exoskeleton assistance during walking,” Science, vol. 356, no. 6344, pp. 1280–1284, 2017
work page 2017
-
[32]
Learning Models for Shared Control of Human-Machine Systems with Unknown Dynamics
A. Broad, T. Murphey, and B. Argall, “Learning models for shared control of human-machine systems with unknown dynamics,” 2018. [Online]. A vailable: https://arxiv.org/abs/1808.08268
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
On human-in-the-loop optimization of human–robot interaction,
P. Slade, C. Atkeson, J. M. Donelan, H. Houdijk, K. A. Ingraham, M. Kim, K. Kong, K. L. Poggensee, R. Riener, M. Steinert et al., “On human-in-the-loop optimization of human–robot interaction,” Nature, vol. 633, no. 8031, pp. 779–788, 2024
work page 2024
-
[34]
Restricted maximum likelihood (REML) estimation of variance com- ponents in the mixed model,
R. R. Corbeil and S. R. Searle, “Restricted maximum likelihood (REML) estimation of variance com- ponents in the mixed model,” Technometrics, vol. 18, no. 1, pp. 31–38, 1976
work page 1976
-
[35]
Adjusted p-values for simultaneous inference,
S. P. Wright, “Adjusted p-values for simultaneous inference,” Biometrics, pp. 1005–1013, 1992
work page 1992
-
[36]
A fast and elitist multiobjective genetic algorithm: NSGA-II,
K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan, “A fast and elitist multiobjective genetic algorithm: NSGA-II,” IEEE Transactions on Evolutionary Computation , vol. 6, no. 2, pp. 182–197, 2002. Appendix A Trial-by-trial HML Model The HML model proposed in our previous work [17] is summarized below ˙x = Cu (13a) ˙δq = − aδq + u + ξq (13b) ˙ˆW = − γ ˜W Φδq...
work page 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.