Recognition: 2 theorem links
· Lean TheoremEponaV2: Driving World Model with Comprehensive Future Reasoning
Pith reviewed 2026-05-15 05:10 UTC · model grok-4.3
The pith
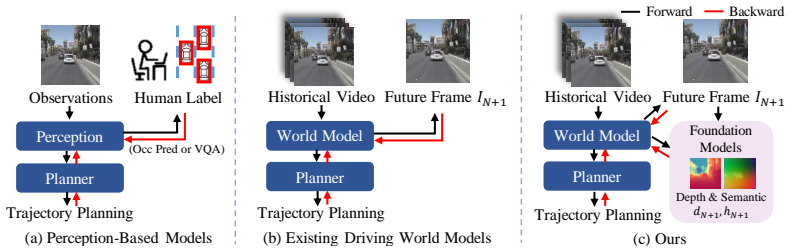
EponaV2 improves trajectory planning in autonomous driving by training world models to forecast future 3D geometry and semantic maps instead of next-frame images alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EponaV2 trains a driving world model to predict comprehensive future representations that decode into future 3D geometry and semantic maps in addition to images. This richer prediction task replaces sole reliance on next-frame image forecasting, producing deeper scene understanding and stronger real-world reasoning for trajectory planning. The model further incorporates a flow matching group relative policy optimization mechanism to raise planning accuracy.
What carries the argument
Decoding the world model's latent predictions into explicit future 3D geometry and semantic maps, paired with flow matching group relative policy optimization for trajectory selection.
If this is right
- EponaV2 reaches state-of-the-art results among perception-free models on three NAVSIM benchmarks, improving PDMS by 1.3 and EPDMS by 5.5.
- The added 3D and semantic supervision produces measurably better real-world reasoning for planning than image-only future prediction.
- The flow matching group relative policy optimization step further raises trajectory accuracy without requiring extra manual annotations.
- The overall approach scales with data rather than with expensive perception labels.
Where Pith is reading between the lines
- The same comprehensive-future-reasoning pattern could transfer to other sequential decision domains that currently rely on pixel-level prediction.
- Longer-horizon versions of the 3D and semantic forecasts might support multi-second planning without compounding errors as quickly.
- Because the model stays perception-free, it could be trained on larger unlabeled video corpora than annotation-heavy pipelines allow.
- The decoded geometry and semantics open a route for direct inspection of what the model has understood, which may aid safety auditing.
Load-bearing premise
Training the model to forecast future 3D geometry and semantic maps will automatically produce superior real-world reasoning and trajectory planning compared to next-frame image forecasting alone.
What would settle it
An ablation that removes the 3D geometry and semantic map forecasting heads and shows no drop, or even an increase, in NAVSIM planning metrics relative to the full EponaV2 model.
Figures


read the original abstract
Data scaling plays a pivotal role in the pursuit of general intelligence. However, the prevailing perception-planning paradigm in autonomous driving relies heavily on expensive manual annotations to supervise trajectory planning, which severely limits its scalability. Conversely, although existing perception-free driving world models achieve impressive driving performance, their real-world reasoning ability for planning is solely built on next frame image forecasting. Due to the lack of enough supervision, these models often struggle with comprehensive scene understanding, resulting in unsatisfactory trajectory planning. In this paper, we propose EponaV2, a novel paradigm of driving world models, which achieves high-quality planning with comprehensive future reasoning. Inspired by how human drivers anticipate 3D geometry and semantics, we train our model to forecast more comprehensive future representations, which can be additionally decoded to future geometry and semantic maps. Extracting the 3D and semantic modalities enables our model to deeply understand the surrounding environment, and the future prediction task significantly enhances the real-world reasoning capabilities of EponaV2, ultimately leading to improved trajectory planning. Moreover, inspired by the training recipe of Large Language Models (LLMs), we introduce a flow matching group relative policy optimization mechanism to further improve planning accuracy. The state-of-the-art (SOTA) performances of EponaV2 among perception-free models on three NAVSIM benchmarks (+1.3PDMS, +5.5EPDMS) demonstrate the effectiveness of our methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EponaV2, a perception-free driving world model that forecasts future 3D geometry and semantic maps (decoded from the latent representation) in addition to next-frame images, combined with a flow matching group relative policy optimization (GRPO) mechanism. It reports state-of-the-art results among perception-free models on three NAVSIM benchmarks (+1.3 PDMS, +5.5 EPDMS), attributing the gains to the richer future reasoning and the new optimization.
Significance. If the performance gains can be isolated to the comprehensive 3D/semantic forecasting rather than the GRPO alone, the work would advance scalable, annotation-light driving models by showing that richer decoded future representations improve real-world planning. The approach aligns with human-like anticipation and LLM-style optimization, offering a path toward more robust perception-free systems.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim attributes the +1.3 PDMS / +5.5 EPDMS gains to training on future 3D geometry and semantic maps rather than next-frame images alone, yet no ablation holds the GRPO mechanism fixed while reverting to an image-only forecasting baseline. Without this isolation, the load-bearing assumption that the decoded 3D/semantic supervision drives superior reasoning cannot be verified.
- [§3.2] §3.2 (Future Reasoning Module): The decoding of future geometry and semantic maps from the world-model latent is described at a high level with no reported accuracy metrics (e.g., semantic IoU, depth error, or Chamfer distance on predicted maps). This omission leaves the claim that these representations enable 'deep understanding' without quantitative grounding.
- [§4.3] §4.3 (Ablation Studies): The ablation tables do not include error analysis or variance across runs for the reported benchmark deltas, nor do they test whether GRPO alone on a standard next-frame model yields comparable gains; this weakens the attribution of improvements to the proposed forecasting targets.
minor comments (2)
- [Figure 3] Figure 3 caption: the legend for the decoded semantic map visualization is missing color-to-class mapping, reducing clarity of the qualitative results.
- [§3.1] Notation in §3.1: the latent variable z_t is used both for the world-model state and the flow-matching input without explicit disambiguation, which could confuse readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and have revised the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim attributes the +1.3 PDMS / +5.5 EPDMS gains to training on future 3D geometry and semantic maps rather than next-frame images alone, yet no ablation holds the GRPO mechanism fixed while reverting to an image-only forecasting baseline. Without this isolation, the load-bearing assumption that the decoded 3D/semantic supervision drives superior reasoning cannot be verified.
Authors: We agree that isolating the contribution of the 3D/semantic forecasting from the GRPO mechanism is necessary to substantiate the central claim. In the revised manuscript, we have added a new ablation in §4.3 that trains an image-only forecasting baseline while keeping the GRPO optimization fixed. This variant achieves +0.6 PDMS and +2.8 EPDMS over the base model, whereas the full EponaV2 reaches the reported gains. The additional improvement supports the value of the richer future representations. The updated table and discussion will appear in the revision. revision: yes
-
Referee: [§3.2] §3.2 (Future Reasoning Module): The decoding of future geometry and semantic maps from the world-model latent is described at a high level with no reported accuracy metrics (e.g., semantic IoU, depth error, or Chamfer distance on predicted maps). This omission leaves the claim that these representations enable 'deep understanding' without quantitative grounding.
Authors: We acknowledge that quantitative metrics for the decoded future representations would provide stronger grounding for the 'deep understanding' claim. In the revised version, we have added evaluation results in §3.2: semantic IoU of 68.4%, depth RMSE of 2.1 m, and Chamfer distance of 0.52 on the predicted maps versus ground truth. These figures demonstrate the fidelity of the decoded outputs and will be reported with the corresponding discussion. revision: yes
-
Referee: [§4.3] §4.3 (Ablation Studies): The ablation tables do not include error analysis or variance across runs for the reported benchmark deltas, nor do they test whether GRPO alone on a standard next-frame model yields comparable gains; this weakens the attribution of improvements to the proposed forecasting targets.
Authors: We appreciate the call for greater statistical rigor. We have updated all ablation tables in §4.3 to report means and standard deviations computed over three independent runs. The isolation of GRPO on a next-frame-only model is now included as part of the response to the first comment, showing smaller gains than the full model. These changes will be reflected in the revised manuscript. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmarks
full rationale
The paper's derivation introduces forecasting of future 3D geometry and semantic maps plus a flow matching GRPO mechanism, then reports empirical SOTA gains on the independent NAVSIM benchmarks. No equation or section reduces the benchmark metrics (PDMS, EPDMS) to quantities defined by the model's own fitted parameters or by self-citation chains. The performance numbers are externally measured and not constructed from the inputs by definition. Self-citations, if present for the GRPO inspiration, are not load-bearing for the central result because the benchmark evaluation remains falsifiable outside the paper's fitted values. This is the common case of an honest non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Forecasting future 3D geometry and semantic maps supplies sufficient additional supervision to overcome limitations of next-frame image prediction for real-world reasoning.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we train our model to forecast more comprehensive future representations, which can be additionally decoded to future geometry and semantic maps... Ltraj + Limg + Ld + Ls
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
flow matching group relative policy optimization mechanism
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Building normalizing flows with stochastic interpolants
Michael Samuel Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Xiao Baihui, Feng Chengjian, Huang Zhijian, Yan Feng, Zhong Yujie, and Ma Lin. RoboTron-Sim: Improving real-world driving via simulated hard-case.arXiv preprint arXiv:0000.00000, 2025
-
[4]
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. NuScenes: A multimodal dataset for autonomous driving. arXiv preprint arXiv:1903.11027, 2019
-
[5]
Pseudo-simulation for autonomous driving
Wei Cao, Marcel Hallgarten, Tianyu Li, Daniel Dauner, Xunjiang Gu, Caojun Wang, Yakov Miron, Marco Aiello, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. Pseudo-simulation for autonomous driving. InConference on Robot Learning (CoRL), 2025
work page 2025
-
[6]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Devil is in Narrow Policy: Unleashing Exploration in Driving
Canyu Chen, Yuguang Yang, Zhewen Tan, Yizhi Wang, Ruiyi Zhan, Haiyan Liu, Xuanyao Mao, Jason Bao, Xinyue Tang, Linlin Yang, et al. Devil is in narrow policy: Unleashing exploration in driving VLA models.arXiv preprint arXiv:2603.06049, 2026
-
[8]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. V ADv2: End-to-end vectorized autonomous driving via probabilistic planning.arXiv preprint arXiv:2402.13243, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Yuntao Chen, Yuqi Wang, and Zhaoxiang Zhang. DrivingGPT: Unifying driving world modeling and planning with multi-modal autoregressive transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 26890–26900, 2025
work page 2025
-
[10]
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. TransFuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE transactions on pattern analysis and machine intelligence, 45(11):12878–12895, 2022
work page 2022
-
[11]
NA VSIM: Data-driven non-reactive autonomous vehicle simulation and benchmarking
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. NA VSIM: Data-driven non-reactive autonomous vehicle simulation and benchmarking. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[12]
Scaling vision transformers to 22 billion parameters
Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, An- dreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, et al. Scaling vision transformers to 22 billion parameters. InInternational conference on machine learning, pages 7480–7512. PMLR, 2023
work page 2023
-
[13]
Cunxin Fan, Xiaosong Jia, Yihang Sun, Yixiao Wang, Jianglan Wei, Ziyang Gong, Xiangyu Zhao, Masayoshi Tomizuka, Xue Yang, Junchi Yan, and Mingyu Ding. Interleave-VLA: Enhancing robot manipulation with interleaved image-text instructions.arXiv preprint arXiv:2505.02152, 2025
-
[14]
RAP: 3D rasterization augmented end-to-end planning.arXiv preprint arXiv:2510.04333, 2025
Lan Feng, Yang Gao, Eloi Zablocki, Quanyi Li, Wuyang Li, Sichao Liu, Matthieu Cord, and Alexandre Alahi. RAP: 3D rasterization augmented end-to-end planning.arXiv preprint arXiv:2510.04333, 2025. 10
-
[15]
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Dingkang Liang, Chong Zhang, Dingyuan Zhang, Hongwei Xie, Bing Wang, and Xiang Bai. ORION: A holistic end-to-end autonomous driving framework by vision-language instructed action generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
work page 2025
-
[16]
FlowAD: Ego-scene interactive modeling for autonomous driving.arXiv preprint arXiv:2603.13399, 2026
Mingzhe Guo, Yixiang Yang, Chuanrong Han, Rufeng Zhang, Shirui Li, Ji Wan, and Zhipeng Zhang. FlowAD: Ego-scene interactive modeling for autonomous driving.arXiv preprint arXiv:2603.13399, 2026
- [17]
-
[18]
Jianhua Han, Meng Tian, Jiangtong Zhu, Fan He, Huixin Zhang, Sitong Guo, Dechang Zhu, Hao Tang, Pei Xu, Yuze Guo, et al. Percept-W AM: Perception-enhanced world-awareness-action model for robust end-to-end autonomous driving.arXiv preprint arXiv:2511.19221, 2025
-
[19]
Distilling multi-modal large language models for autonomous driving
Deepti Hegde, Rajeev Yasarla, Hong Cai, Shizhong Han, Apratim Bhattacharyya, Shweta Mahajan, Litian Liu, Risheek Garrepalli, Vishal M Patel, and Fatih Porikli. Distilling multi-modal large language models for autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27575–27585, 2025
work page 2025
-
[20]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[21]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3Dv2: A versatile monocular geometric foundation model for zero- shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[22]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023
work page 2023
-
[23]
Yi Huang, zhan qu, Lihui Jiang, Bingbing Liu, and Hongbo Zhang. Prioritizing perception-guided self- supervision: A new paradigm for causal modeling in end-to-end autonomous driving. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[24]
DINO-Tok: Adapting DINO for visual tokenizers.arXiv preprint arXiv:2511.20565, 2026
Mingkai Jia, Mingxiao Li, Zhijian Shu, Anlin Zheng, Liaoyuan Fan, Jiaxin Guo, Tianxing Shi, Dongyue Lu, Zeming Li, Xiaoyang Guo, Xiaojuan Qi, Xiao-Xiao Long, Qian Zhang, Ping Tan, and Wei Yin. DINO-Tok: Adapting DINO for visual tokenizers.arXiv preprint arXiv:2511.20565, 2026
-
[25]
Spatial retrieval augmented autonomous driving.arXiv preprint arXiv:2512.06865, 2025
Xiaosong Jia, Chenhe Zhang, Yule Jiang, Songbur Wong, Zhiyuan Zhang, Chen Chen, Shaofeng Zhang, Xuanhe Zhou, Xue Yang, Junchi Yan, et al. Spatial retrieval augmented autonomous driving.arXiv preprint arXiv:2512.06865, 2025
-
[26]
V AD: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. V AD: Vectorized scene representation for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340–8350, 2023
work page 2023
-
[27]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[28]
SynAD: Enhancing real-world end-to-end autonomous driving models through synthetic data integration
Jongsuk Kim, Jaeyoung Lee, Gyojin Han, Dong-Jae Lee, Minki Jeong, and Junmo Kim. SynAD: Enhancing real-world end-to-end autonomous driving models through synthetic data integration. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25197–25206, 2025
work page 2025
-
[29]
Jungho Kim, Jiyong Oh, Seunghoon Yu, Hongjae Shin, Donghyuk Kwak, and Jun Won Choi. SafeDrive: Fine-grained safety reasoning for end-to-end driving in a sparse world.arXiv preprint arXiv:2602.18887, 2026
-
[30]
Ellington Kirby, Alexandre Boulch, Yihong Xu, Yuan Yin, Gilles Puy, Éloi Zablocki, Andrei Bursuc, Spyros Gidaris, Renaud Marlet, Florent Bartoccioni, Anh-Quan Cao, Nermin Samet, Tuan-Hung Vu, and Matthieu Cord. Driving on registers. InCVPR, 2026
work page 2026
-
[31]
VLR-Driver: Large vision-language-reasoning models for embodied autonomous driving
Fanjie Kong, Yitong Li, Weihuang Chen, Chen Min, Yizhe Li, Zhiqiang Gao, Haoyang Li, Zhongyu Guo, and Hongbin Sun. VLR-Driver: Large vision-language-reasoning models for embodied autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 26966–26976, October 2025. 11
work page 2025
-
[32]
Jingyu Li, Junjie Wu, Dongnan Hu, Xiangkai Huang, Bin Sun, Zhihui Hao, Xianpeng Lang, Xiatian Zhu, and Li Zhang. SGDrive: Scene-to-goal hierarchical world cognition for autonomous driving.arXiv preprint arXiv:2601.05640, 2026
-
[33]
Peizheng Li, Zhenghao Zhang, David Holtz, Hang Yu, Yutong Yang, Yuzhi Lai, Rui Song, Andreas Geiger, and Andreas Zell. SpaceDrive: Infusing spatial awareness into VLM-based autonomous driving.arXiv preprint arXiv:2512.10719, 2025
-
[34]
Pengxiang Li, Yinan Zheng, Yue Wang, Huimin Wang, Hang Zhao, Jingjing Liu, Xianyuan Zhan, Kun Zhan, and Xianpeng Lang. Discrete diffusion for reflective vision-language-action models in autonomous driving.arXiv preprint arXiv:2509.20109, 2025
-
[35]
Yingyan Li, Lue Fan, Jiawei He, Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang, and Tieniu Tan. Enhancing end-to-end autonomous driving with latent world model.arXiv preprint arXiv:2406.08481, 2024
-
[36]
Yingyan Li, Shuyao Shang, Weisong Liu, Bing Zhan, Haochen Wang, Yuqi Wang, Yuntao Chen, Xiaoman Wang, Yasong An, Chufeng Tang, et al. DriveVLA-W0: World models amplify data scaling law in autonomous driving.arXiv preprint arXiv:2510.12796, 2025
-
[37]
End-to-end driving with online trajectory evaluation via BEV world model
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online trajectory evaluation via BEV world model. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 27137–27146, October 2025
work page 2025
-
[38]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, et al. ReCogDrive: A reinforced cognitive framework for end-to-end autonomous driving.arXiv preprint arXiv:2506.08052, 2025
work page internal anchor Pith review arXiv 2025
-
[39]
Zhenxin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Zuxuan Wu, and Jose M. Alvarez. Hydra-NeXt: Robust closed-loop driving with open-loop training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 27305–27314, October 2025
work page 2025
-
[40]
BEVFormer: Learning bird’s-eye-view representation from Lidar-camera via spatiotemporal transformers
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. BEVFormer: Learning bird’s-eye-view representation from Lidar-camera via spatiotemporal transformers. IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(3):2020–2036, 2024
work page 2020
-
[41]
DiffusionDrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. DiffusionDrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025
work page 2025
-
[42]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[44]
Changxing Liu, Genjia Liu, Zijun Wang, Jinchang Yang, and Siheng Chen. CoLMDriver: LLM-based negotiation benefits cooperative autonomous driving.arXiv preprint arXiv:2503.08683, 2025
-
[45]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-GRPO: Training flow matching models via online RL.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
GuideFlow: Constraint-guided flow matching for planning in end-to-end autonomous driving
Lin Liu, Caiyan Jia, Guanyi Yu, Ziying Song, JunQiao Li, Feiyang Jia, Peiliang Wu, Xiaoshuai Hao, and Yandan Luo. GuideFlow: Constraint-guided flow matching for planning in end-to-end autonomous driving. arXiv preprint arXiv:2511.18729, 2025
-
[47]
CogDriver: Integrating Cognitive Inertia for Temporally Coherent Planning in Autonomous Driving
Pei Liu, Qingtian Ning, Xinyan Lu, Haipeng Liu, Weiliang Ma, Dangen She, Xianpeng Lang, and Jun Ma. CogDriver: Integrating cognitive inertia for temporally coherent planning in autonomous driving.arXiv preprint arXiv:2509.00789v2, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Shu Liu, Wenlin Chen, Weihao Li, Zheng Wang, Lijin Yang, Jianing Huang, Yipin Zhang, Zhongzhan Huang, Ze Cheng, and Hao Yang. BridgeDrive: Diffusion bridge policy for closed-loop trajectory planning in autonomous driving.arXiv preprint arXiv:2509.23589, 2025
-
[49]
GaussianFusion: Gaussian-based multi-sensor fusion for end-to-end autonomous driving
Shuai Liu, Quanmin Liang, Zefeng Li, Boyang Li, and Kai Huang. GaussianFusion: Gaussian-based multi-sensor fusion for end-to-end autonomous driving. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 12
work page 2025
-
[50]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[51]
Yuhang Lu, Jiadong Tu, Yuexin Ma, and Xinge Zhu. ReAL-AD: Towards human-like reasoning in end-to-end autonomous driving.arXiv preprint arXiv:2507.12499, 2025
-
[52]
Yuechen Luo, Qimao Chen, Fang Li, Shaoqing Xu, Jaxin Liu, Ziying Song, Zhi-xin Yang, and Fuxi Wen. Unleashing VLA potentials in autonomous driving via explicit learning from failures.arXiv preprint arXiv:2603.01063, 2026
-
[53]
LEAD: Minimizing learner-expert asymmetry in end-to-end driving
Long Nguyen, Micha Fauth, Bernhard Jaeger, Daniel Dauner, Maximilian Igl, Andreas Geiger, and Kashyap Chitta. LEAD: Minimizing learner-expert asymmetry in end-to-end driving. InConference on Computer Vision and Pattern Recognition (CVPR), 2026
work page 2026
-
[54]
Embodied cognition augmented end2end autonomous driving
Ling Niu, Xiaoji Zheng, han wang, Ziyuan Yang, Chen Zheng, Bokui Chen, and Jiangtao Gong. Embodied cognition augmented end2end autonomous driving. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[55]
Qihang Peng, Xuesong Chen, Chenye Yang, Shaoshuai Shi, and Hongsheng Li. ColaVLA: Leveraging cognitive latent reasoning for hierarchical parallel trajectory planning in autonomous driving.arXiv preprint arXiv:2512.22939, 2025
-
[56]
Multi-modal fusion transformer for end-to-end autonomous driving
Aditya Prakash, Kashyap Chitta, and Andreas Geiger. Multi-modal fusion transformer for end-to-end autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7077–7087, 2021
work page 2021
-
[57]
Diffusion policy policy optimization
Allen Z Ren, Justin Lidard, Lars L Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588, 2024
-
[58]
Minglei Shi, Haolin Wang, Borui Zhang, Wenzhao Zheng, Bohan Zeng, Ziyang Yuan, Xiaoshi Wu, Yuanxing Zhang, Huan Yang, Xintao Wang, Pengfei Wan, Kun Gai, Jie Zhou, and Jiwen Lu. SVG- T2I: Scaling up text-to-image latent diffusion model without variational autoencoder.arXiv preprint arXiv:2512.11749, 2025
-
[59]
Latent diffusion model without variational autoencoder.arXiv preprint arXiv:2510.15301, 2025
Minglei Shi, Haolin Wang, Wenzhao Zheng, Ziyang Yuan, Xiaoshi Wu, Xintao Wang, Pengfei Wan, Jie Zhou, and Jiwen Lu. Latent diffusion model without variational autoencoder.arXiv preprint arXiv:2510.15301, 2025
-
[60]
DriveLM: Driving with graph visual question answering.arXiv preprint arXiv:2312.14150, 2023
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Ping Luo, Andreas Geiger, and Hongyang Li. DriveLM: Driving with graph visual question answering.arXiv preprint arXiv:2312.14150, 2023
-
[61]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[63]
Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving
Ziying Song, Caiyan Jia, Lin Liu, Hongyu Pan, Yongchang Zhang, Junming Wang, Xingyu Zhang, Shaoqing Xu, Lei Yang, and Yadan Luo. Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22432–22441, 2025
work page 2025
-
[64]
DriveMamba: Task-centric scalable state space model for efficient end-to-end autonomous driving
Haisheng Su, Wei Wu, Feixiang Song, Junjie Zhang, Zhenjie Yang, and Junchi Yan. DriveMamba: Task-centric scalable state space model for efficient end-to-end autonomous driving. InThe F ourteenth International Conference on Learning Representations, 2026
work page 2026
-
[65]
SparseDrive: End- to-end autonomous driving via sparse scene representation
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Haoran Wu, and Sifa Zheng. SparseDrive: End- to-end autonomous driving via sparse scene representation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8795–8801. IEEE, 2025
work page 2025
-
[66]
Latent Chain-of-Thought World Modeling for End-to-End Driving
Shuhan Tan, Kashyap Chitta, Yuxiao Chen, Ran Tian, Yurong You, Yan Wang, Wenjie Luo, Yulong Cao, Philipp Krahenbuhl, Marco Pavone, and Boris Ivanovic. Latent chain-of-thought world modeling for end-to-end driving.arXiv preprint arXiv:2512.10226, 2026. 13
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[67]
CausalVAD: De-confounding End-to-End Autonomous Driving via Causal Intervention
Jiacheng Tang, Zhiyuan Zhou, Zhuolin He, Jia Zhang, Kai Zhang, and Jian Pu. CausalV AD: De- confounding end-to-end autonomous driving via causal intervention.arXiv preprint arXiv:2603.18561, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[68]
Yingqi Tang, Zhuoran Xu, Zhaotie Meng, and Erkang Cheng. HiP-AD: Hierarchical and multi- granularity planning with deformable attention for autonomous driving in a single decoder.arXiv preprint arXiv:2503.08612, 2025
-
[69]
SimScale: Learning to Drive via Real-World Simulation at Scale
Haochen Tian, Tianyu Li, Haochen Liu, Jiazhi Yang, Yihang Qiu, Guang Li, Junli Wang, Yinfeng Gao, Zhang Zhang, Liang Wang, et al. Simscale: Learning to drive via real-world simulation at scale.arXiv preprint arXiv:2511.23369, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. DriveVLM: The convergence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Jie Wang, Guang Li, Zhijian Huang, Chenxu Dang, Hangjun Ye, Yahong Han, and Long Chen. VGGDrive: Empowering vision-language models with cross-view geometric grounding for autonomous driving.arXiv preprint arXiv:2602.20794, 2026
-
[72]
Junli Wang, Xueyi Liu, Yinan Zheng, Zebing Xing, Pengfei Li, Guang Li, Kun Ma, Guang Chen, Hangjun Ye, Zhongpu Xia, et al. MeanFuser: Fast one-step multi-modal trajectory generation and adaptive reconstruction via meanflow for end-to-end autonomous driving.arXiv preprint arXiv:2602.20060, 2026
-
[73]
DriveDreamer: Towards real-world-drive world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. DriveDreamer: Towards real-world-drive world models for autonomous driving. InEuropean conference on computer vision, pages 55–72. Springer, 2024
work page 2024
-
[74]
Unifying language-action understanding and generation for autonomous driving
Xinyang Wang, Qian Liu, Wenjie Ding, Zhao Yang, Wei Li, Chang Liu, Bailin Li, Kun Zhan, Xianpeng Lang, and Wei Chen. Unifying language-action understanding and generation for autonomous driving. arXiv preprint arXiv:2603.01441, 2026
-
[75]
Unified vision-language-action model.arXiv preprint arXiv:2506.19850, 2025
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, and Zhaoxiang Zhang. Unified vision-language-action model.arXiv preprint arXiv:2506.19850, 2025
-
[76]
Metric3D: Towards zero-shot metric 3D prediction from a single image
Yin Wei, Zhang Chi, Chen Hao, Cai Zhipeng, Yu Gang, Wang Kaixuan, Chen Xiaozhi, and Shen Chunhua. Metric3D: Towards zero-shot metric 3D prediction from a single image. 2023
work page 2023
-
[77]
DriveLaW:Unifying Planning and Video Generation in a Latent Driving World
Tianze Xia, Yongkang Li, Lijun Zhou, Jingfeng Yao, Kaixin Xiong, Haiyang Sun, Bing Wang, Kun Ma, Hangjun Ye, Wenyu Liu, et al. DriveLaW: Unifying planning and video generation in a latent driving world.arXiv preprint arXiv:2512.23421, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Zebin Xing, Xingyu Zhang, Yang Hu, Bo Jiang, Tong He, Qian Zhang, Xiaoxiao Long, and Wei Yin. GoalFlow: Goal-driven flow matching for multimodal trajectories generation in end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1602–1611, 2025
work page 2025
-
[79]
WAM-Flow: Parallel coarse-to-fine motion planning via discrete flow matching for autonomous driving
Yifang Xu, Jiahao Cui, Feipeng Cai, Zhihao Zhu, Hanlin Shang, Shan Luan, Mingwang Xu, Neng Zhang, Yaoyi Li, Jia Cai, and Siyu Zhu. WAM-Flow: Parallel coarse-to-fine motion planning via discrete flow matching for autonomous driving. InCVPR, 2026
work page 2026
-
[80]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InCVPR, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.