Recognition: 1 theorem link
· Lean TheoremBoosting Reinforcement Learning with Verifiable Rewards via Randomly Selected Few-Shot Guidance
Pith reviewed 2026-05-15 03:14 UTC · model grok-4.3
The pith
FEST boosts RLVR performance using only 128 randomly selected demonstrations from SFT data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
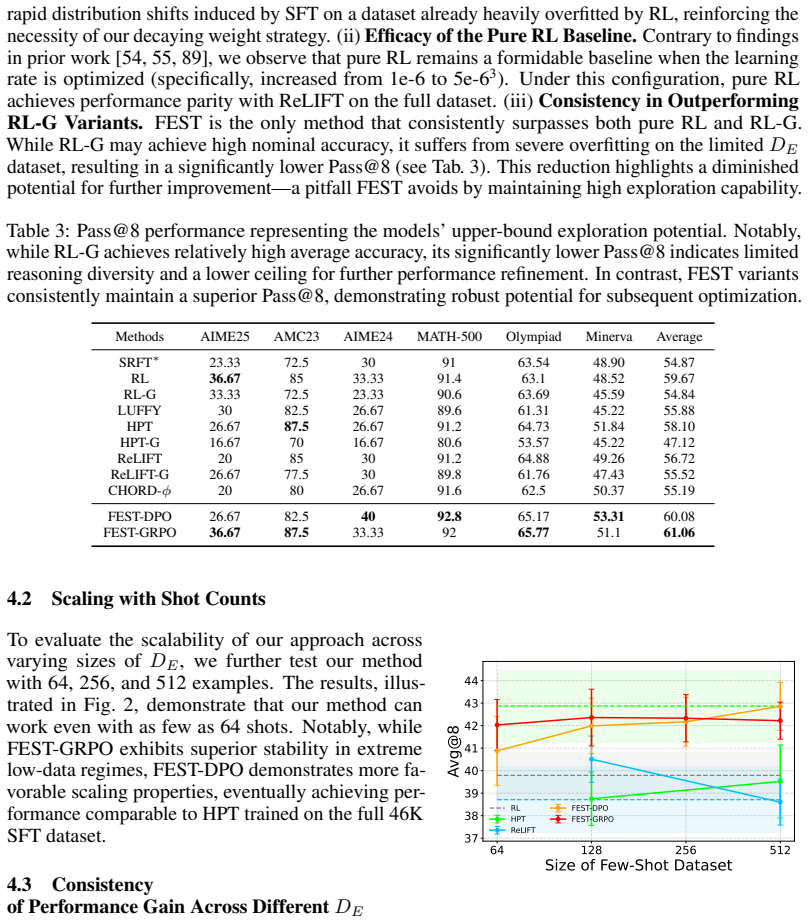
FEST attains compelling results with only 128 demonstrations randomly selected from an SFT dataset. Three components are vital: the supervised signal, the on-policy signal, and decaying weights on the few-shot SFT dataset to prevent overfitting from multiple-epoch training. On several benchmarks, it outperforms baselines with magnitudes less SFT data and even matches their performance with the full dataset.
What carries the argument
The FEST algorithm that integrates few-shot supervised guidance with on-policy RL signals under a decaying weight schedule on the demonstration data.
If this is right
- RLVR methods can succeed with far less supervised data than previously required.
- Random selection of demonstrations is sufficient for effective guidance.
- Decaying weights enable multiple epochs of training on small datasets without overfitting.
- Performance on math and coding tasks can match full-dataset approaches using minimal examples.
Where Pith is reading between the lines
- This technique could lower the barrier for training reasoning-capable LLMs by reducing data acquisition costs.
- It may inspire similar few-shot guidance strategies in other reinforcement learning domains beyond language models.
- Exploring adaptive selection or weighting beyond random choice could further improve results.
Load-bearing premise
Randomly chosen demonstrations from an SFT dataset will provide effective guidance when mixed with on-policy signals and subject to decaying weights.
What would settle it
An experiment showing that on a difficult new benchmark, FEST with 128 random demos performs no better than pure RLVR or requires non-random selection to match full SFT results.
Figures







read the original abstract
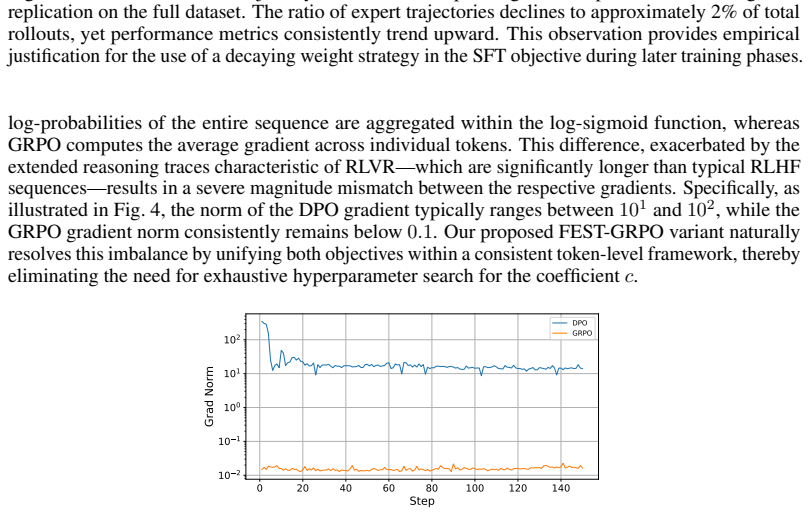
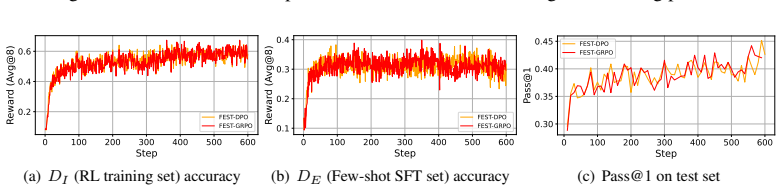
Reinforcement Learning with Verifiable Rewards (RLVR) has achieved great success in developing Large Language Models (LLMs) with chain-of-thought rollouts for many tasks such as math and coding. Nevertheless, RLVR struggles with sample efficiency on difficult problems where correct rollouts are hard to generate. Prior works propose to address this issue via demonstration-guided RLVR, i.e., to conduct Supervised FineTuning (SFT) when RL fails; however, SFT often requires a lot of data, which can be expensive to acquire. In this paper, we propose FEST, a FEw-ShoT demonstration-guided RLVR algorithm. It attains compelling results with only 128 demonstrations randomly selected from an SFT dataset. We find that three components are vital for the success: supervised signal, on-policy signal, and decaying weights on the few-shot SFT dataset to prevent overfitting from multiple-epoch training. On several benchmarks, FEST outperforms baselines with magnitudes less SFT data, even matching their performance with full dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FEST, a few-shot demonstration-guided RLVR algorithm for LLMs that uses only 128 randomly selected demonstrations from an SFT dataset. It claims that combining supervised signals, on-policy signals, and decaying weights on the few-shot data prevents overfitting during multi-epoch training and yields compelling results on math and coding benchmarks, outperforming baselines that require magnitudes more SFT data and even matching full-dataset performance.
Significance. If the results hold under proper robustness checks, the work could meaningfully advance sample-efficient RLVR by showing that carefully weighted few-shot guidance from minimal random subsets can substitute for large-scale SFT, reducing data acquisition costs while maintaining or exceeding performance. The emphasis on the interplay of supervised, on-policy, and decaying-weight components offers actionable guidance for practitioners working on verifiable-reward fine-tuning.
major comments (2)
- [Experimental Results] The central claim that 'randomly selected' 128 demonstrations suffice depends on the assumption that subset variance is negligible. The experimental section reports results for a single (or unreported number of) random draw(s) but provides no statistics over multiple independent random selections of the 128 examples, no standard deviation across seeds, and no ablation isolating subset quality. This is load-bearing: if example difficulty or quality varies within the SFT pool, the reported gains may reflect a favorable draw rather than a general property of FEST. Please add results from at least five independent random 128-subsets with mean and std-dev metrics.
- [Ablation Studies] The paper states that supervised signal, on-policy signal, and decaying weights are 'vital,' yet the ablation tables do not quantify the performance drop when each component is removed individually while keeping the others fixed, nor do they isolate the effect of the decaying-weight schedule on multi-epoch overfitting. Without these controls, the necessity of all three components for the few-shot regime remains incompletely supported.
minor comments (2)
- [Abstract] The abstract refers to 'several benchmarks' and 'outperforms baselines' without naming the specific tasks, baselines, or quantitative deltas; moving at least the headline numbers into the abstract would improve readability.
- [Method] Notation for the decaying weight schedule (e.g., the functional form and hyper-parameters) should be defined once in a dedicated subsection and then referenced consistently in equations and figures.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We agree that additional robustness checks and more granular ablations will strengthen the manuscript and plan to incorporate them in the revision.
read point-by-point responses
-
Referee: [Experimental Results] The central claim that 'randomly selected' 128 demonstrations suffice depends on the assumption that subset variance is negligible. The experimental section reports results for a single (or unreported number of) random draw(s) but provides no statistics over multiple independent random selections of the 128 examples, no standard deviation across seeds, and no ablation isolating subset quality. This is load-bearing: if example difficulty or quality varies within the SFT pool, the reported gains may reflect a favorable draw rather than a general property of FEST. Please add results from at least five independent random 128-subsets with mean and std-dev metrics.
Authors: We acknowledge that reporting results from only a single random draw leaves the claim vulnerable to subset-specific effects. We will rerun the full evaluation pipeline on at least five independent random selections of 128 examples, report mean performance together with standard deviation, and include these statistics in the revised experimental section. revision: yes
-
Referee: [Ablation Studies] The paper states that supervised signal, on-policy signal, and decaying weights are 'vital,' yet the ablation tables do not quantify the performance drop when each component is removed individually while keeping the others fixed, nor do they isolate the effect of the decaying-weight schedule on multi-epoch overfitting. Without these controls, the necessity of all three components for the few-shot regime remains incompletely supported.
Authors: We agree that the current ablations do not fully isolate each factor. In the revision we will add controlled experiments that (i) remove the supervised signal, on-policy signal, and decaying-weight schedule one at a time while holding the other two fixed, and (ii) compare fixed-weight versus decaying-weight schedules across multiple training epochs to quantify the overfitting-prevention effect. These results will be presented in an expanded ablation table. revision: yes
Circularity Check
No circularity; empirical results rest on external comparisons
full rationale
The paper introduces FEST as an empirical algorithm combining supervised fine-tuning signals, on-policy RL signals, and decaying weights on a small random subset of 128 SFT demonstrations. Its central claims are supported by reported benchmark comparisons showing outperformance relative to baselines that use more data. No equations, uniqueness theorems, or derivations are present that reduce by construction to fitted inputs or self-citations. The three vital components are identified from experimental findings rather than being presupposed in the method definition. The approach is self-contained against external benchmarks, with no load-bearing self-citation chains or ansatzes smuggled via prior work.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of demonstrations =
128
- decaying weight schedule
axioms (2)
- domain assumption Demonstration guidance from SFT data can usefully supplement RLVR when correct rollouts are rare.
- domain assumption On-policy signals and supervised signals can be productively combined in the same training loop.
Reference graph
Works this paper leans on
-
[1]
Afanasyev, M. and Iov, I. Slime: Stabilized likelihood implicit margin enforcement for preference optimization.arXiv preprint arXiv:2602.02383, 2026
-
[2]
Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms
Ahmadian, A., Cremer, C., Gallé, M., Fadaee, M., Kreutzer, J., Pietquin, O., Üstün, A., and Hooker, S. Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms. InACL, 2024
work page 2024
-
[3]
Albalak, A., Phung, D., Lile, N., Rafailov, R., Gandhi, K., Castricato, L., Singh, A., Blagden, C., Xiang, V ., Mahan, D., et al. Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models.arXiv preprint arXiv:2502.17387, 2025
-
[4]
Global overview of Imitation Learning
Attia, A. and Dayan, S. Global overview of imitation learning.arXiv preprint arXiv:1801.06503, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Au-Yeung, A. The ai startup fueling chatgpt’s expertise is now valued at $10 bil- lion.The Wall Street Journal, 2026. URL https://www.wsj.com/tech/ai/ the-ai-startup-fueling-chatgpts-expertise-is-now-valued-at-10-billion-f1281e56
work page 2026
-
[6]
Online preference alignment for language models via count-based exploration
Bai, C., Zhang, Y ., Qiu, S., Zhang, Q., Xu, K., and Li, X. Online preference alignment for language models via count-based exploration. InICLR, 2026
work page 2026
-
[7]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y ., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Scheduled sampling for sequence prediction with recurrent neural networks
Bengio, S., Vinyals, O., Jaitly, N., and Shazeer, N. Scheduled sampling for sequence prediction with recurrent neural networks. InNIPS, 2015
work page 2015
-
[9]
Data diversity matters for robust instruction tuning
Bukharin, A., Li, S., Wang, Z., Yang, J., Yin, B., Li, X., Zhang, C., Zhao, T., and Jiang, H. Data diversity matters for robust instruction tuning. InFindings of EMNLP, 2024
work page 2024
-
[10]
Instruction mining: Instruction data selection for tuning large language models
Cao, Y ., Kang, Y ., Wang, C., and Sun, L. Instruction mining: Instruction data selection for tuning large language models. InCOLM, 2024
work page 2024
-
[11]
H., Chen, X., Zhang, Q., Ranganath, R., and Cho, K
Chen, A., Malladi, S., Zhang, L. H., Chen, X., Zhang, Q., Ranganath, R., and Cho, K. Preference learning algorithms do not learn preference rankings. InNeurIPS, 2024
work page 2024
-
[12]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Chen, A., Li, A., Gong, B., Jiang, B., Fei, B., Yang, B., Shan, B., Yu, C., Wang, C., Zhu, C., et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Chen, H., Tu, H., Wang, F., Liu, H., Tang, X., Du, X., Zhou, Y ., and Xie, C. Sft or rl? an early investigation into training r1-like reasoning large vision-language models.TMLR, 2025
work page 2025
-
[14]
Chen, J., Liu, F., Liu, N., Luo, Y ., Qin, E., Zheng, H., Dong, T., Zhu, H., Meng, Y ., and Wang, X. Step-wise adaptive integration of supervised fine-tuning and reinforcement learning for task-specific llms.arXiv preprint arXiv:2505.13026, 2025
-
[15]
Self-play fine-tuning converts weak language models to strong language models
Chen, Z., Deng, Y ., Yuan, H., Ji, K., and Gu, Q. Self-play fine-tuning converts weak language models to strong language models. InICML, 2024
work page 2024
-
[16]
Cheng, D., Huang, S., Zhu, X., Dai, B., Zhao, W. X., Zhang, Z., and Wei, F. Reasoning with exploration: An entropy perspective. InAAAI, 2026
work page 2026
-
[17]
H., Oh, J., Kim, M., and Lee, B.-J
Cho, J. H., Oh, J., Kim, M., and Lee, B.-J. Rethinking dpo: The role of rejected responses in preference misalignment. InEMNLP, 2025
work page 2025
-
[18]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. 10
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
D’Oosterlinck, K., Xu, W., Develder, C., Demeester, T., Singh, A., Potts, C., Kiela, D., and Mehri, S. Anchored preference optimization and contrastive revisions: Addressing underspecification in alignment. InACL, 2025
work page 2025
- [21]
-
[22]
Rlhf in an sft way: From optimal solution to reward-weighted alignment.TMLR, 2026
Du, Y ., Li, Z., Cheng, P., Chen, Z., Xie, Y ., Wan, X., and Gao, A. Rlhf in an sft way: From optimal solution to reward-weighted alignment.TMLR, 2026
work page 2026
-
[23]
Kto: Model alignment as prospect theoretic optimization
Ethayarajh, K., Xu, W., Muennighoff, N., Jurafsky, D., and Kiela, D. Kto: Model alignment as prospect theoretic optimization. InICML, 2024
work page 2024
-
[24]
Serl: Self-play reinforcement learning for large language models with limited data
Fang, W., Liu, S., Zhou, Y ., Zhang, K., Zheng, T., Chen, K., Song, M., and Tao, D. Serl: Self-play reinforcement learning for large language models with limited data. InNeurIPS, 2025
work page 2025
-
[25]
Feng, D., Qin, B., Huang, C., Zhang, Z., and Lei, W. Towards analyzing and understanding the limitations of dpo: A theoretical perspective.arXiv preprint arXiv:2404.04626, 2024
-
[26]
Srft: A single-stage method with supervised and reinforcement fine-tuning for reasoning
Fu, Y ., Chen, T., Chai, J., Wang, X., Tu, S., Yin, G., Lin, W., Zhang, Q., Zhu, Y ., and Zhao, D. Srft: A single-stage method with supervised and reinforcement fine-tuning for reasoning. In ICLR, 2026
work page 2026
- [27]
-
[28]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Proximalized preference optimization for diverse feedback types: A decomposed perspective on dpo
Guo, K., Li, Y ., and Chen, Z. Proximalized preference optimization for diverse feedback types: A decomposed perspective on dpo. InNeurIPS, 2025
work page 2025
-
[30]
Direct language model alignment from online ai feedback.arXiv preprint arXiv:2402.04792, 2024
Guo, S., Zhang, B., Liu, T., Liu, T., Khalman, M., Llinares, F., Rame, A., Mesnard, T., Zhao, Y ., Piot, B., et al. Direct language model alignment from online ai feedback.arXiv preprint arXiv:2402.04792, 2024
-
[31]
He, C., Luo, R., Bai, Y ., Hu, S., Thai, Z., Shen, J., Hu, J., Han, X., Huang, Y ., Zhang, Y ., et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. InACL, 2024
work page 2024
-
[32]
Unifying stable optimization and reference regularization in rlhf
He, L., Qu, Q., Zhao, H., Wan, S., Wang, D., Yao, L., and Liu, T. Unifying stable optimization and reference regularization in rlhf. InICLR, 2026
work page 2026
-
[33]
Measuring mathematical problem solving with the math dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the math dataset. InNeurIPS, 2021
work page 2021
-
[34]
Huang, Y . and Yang, L. F. Winning gold at imo 2025 with a model-agnostic verification-and- refinement pipeline. InMATH-AI Workshop at NeurIPS, 2025
work page 2025
-
[35]
Huang, Z., Cheng, T., Qiu, Z., Wang, Z., Xu, Y ., Ponti, E. M., and Titov, I. Blending supervised and reinforcement fine-tuning with prefix sampling.arXiv preprint arXiv:2507.01679, 2025
-
[36]
K., Dantanarayana, J., Flautner, K., Tang, L., Kang, Y ., and Mars, J
Irugalbandara, C., Mahendra, A., Daynauth, R., Arachchige, T. K., Dantanarayana, J., Flautner, K., Tang, L., Kang, Y ., and Mars, J. Scaling down to scale up: A cost-benefit analysis of replacing openai’s llm with open source slms in production. InISPASS, 2024. 11
work page 2024
-
[37]
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Jensen, J. L. W. V . Sur les fonctions convexes et les inégalités entre les valeurs moyennes. Acta Mathematica, 1906
work page 1906
-
[39]
Jiang, H., Zhang, W., Yao, J., Cai, H., Wang, S., and Song, R. Supervised fine-tuning versus reinforcement learning: A study of post-training methods for large language models.arXiv preprint arXiv:2603.13985, 2026
-
[40]
CodeRL+: Improving Code Generation via Reinforcement with Execution Semantics Alignment
Jiang, X., Dong, Y ., Liu, M., Deng, H., Wang, T., Tao, Y ., Cao, R., Li, B., Jin, Z., Jiao, W., et al. Coderl+: Improving code generation via reinforcement with execution semantics alignment. arXiv preprint arXiv:2510.18471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
X., Li, M., Qin, C., Wang, P., Savarese, S., et al
Ke, Z., Jiao, F., Ming, Y ., Nguyen, X.-P., Xu, A., Long, D. X., Li, M., Qin, C., Wang, P., Savarese, S., et al. A survey of frontiers in llm reasoning: Inference scaling, learning to reason, and agentic systems.TMLR, 2025
work page 2025
-
[42]
Köksal, A. and Alatan, A. A. Few-shot vision-language reasoning for satellite imagery via verifiable rewards. InICCV, 2025
work page 2025
-
[43]
Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[44]
Kydlíˇcek, H. and Team, H. F. Math-verify: A library for verifying mathematical answers,
- [45]
-
[46]
Solving quantitative reasoning problems with language models
Lewkowycz, A., Andreassen, A., Dohan, D., Dyer, E., Michalewski, H., Ramasesh, V ., Slone, A., Anil, C., Schlag, I., Gutman-Solo, T., et al. Solving quantitative reasoning problems with language models. InNeurIPS, 2022
work page 2022
-
[47]
Li, J., Beeching, E., Tunstall, L., Lipkin, B., Soletskyi, R., Huang, S., Rasul, K., Yu, L., Jiang, A. Q., Shen, Z., et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face Repository, 2024
work page 2024
-
[48]
Li, P., Skripkin, M., Zubrey, A., Kuznetsov, A., and Oseledets, I. Confidence is all you need: Few-shot rl fine-tuning of language models.arXiv preprint arXiv:2506.06395, 2025
-
[49]
Limr: Less is more for rl scaling.arXiv preprint arXiv:2502.11886, 2025
Li, X., Zou, H., and Liu, P. Limr: Less is more for rl scaling.arXiv preprint arXiv:2502.11886, 2025
-
[50]
Empowering small vlms to think with dynamic memorization and exploration
Liu, J., Deng, Y ., and Chen, L. Empowering small vlms to think with dynamic memorization and exploration. InICLR, 2026
work page 2026
-
[51]
Uft: Unifying supervised and reinforcement fine-tuning
Liu, M., Farina, G., and Ozdaglar, A. Uft: Unifying supervised and reinforcement fine-tuning. InNeurIPS, 2025
work page 2025
-
[52]
Liu, Y ., Li, S., Cao, L., Xie, Y ., Zhou, M., Dong, H., Ma, X., Han, S., and Zhang, D. Superrl: Reinforcement learning with supervision to boost language model reasoning.arXiv preprint arXiv:2506.01096, 2025
-
[53]
Liu, Z., Chen, C., Li, W., Qi, P., Pang, T., Du, C., Lee, W. S., and Lin, M. Understanding r1-zero-like training: A critical perspective. InCOLM, 2025
work page 2025
-
[54]
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. InICLR, 2019
work page 2019
-
[55]
Towards a unified view of large language model post-training.arXiv preprint arXiv:2509.04419, 2025
Lv, X., Zuo, Y ., Sun, Y ., Liu, H., Wei, Y ., Chen, Z., Zhu, X., Zhang, K., Wang, B., Ding, N., et al. Towards a unified view of large language model post-training.arXiv preprint arXiv:2509.04419, 2025
-
[56]
H., Niu, J., Shen, C., He, R., Li, Y ., et al
Ma, L., Liang, H., Qiang, M., Tang, L., Ma, X., Wong, Z. H., Niu, J., Shen, C., He, R., Li, Y ., et al. Learning what reinforcement learning can’t: Interleaved online fine-tuning for hardest questions. InICLR, 2026. 12
work page 2026
-
[57]
Gradient imbalance in direct preference optimization.arXiv preprint arXiv:2502.20847, 2025
Ma, Q., Shi, J., Jin, C., Hwang, J.-N., Belongie, S., and Li, L. Gradient imbalance in direct preference optimization.arXiv preprint arXiv:2502.20847, 2025
-
[58]
Mahdavi, S., Li, M., Liu, K., Thrampoulidis, C., Sigal, L., and Liao, R. Leveraging online olympiad-level math problems for LLMs training and contamination-resistant evaluation. In ICML, 2025
work page 2025
-
[59]
Min, Y ., Chen, Z., Jiang, J., Chen, J., Deng, J., Hu, Y ., Tang, Y ., Wang, J., Cheng, X., Song, H., et al. Imitate, explore, and self-improve: A reproduction report on slow-thinking reasoning systems.arXiv preprint arXiv:2412.09413, 2024
-
[60]
L., Fei-Fei, L., Hajishirzi, H., Zettlemoyer, L., Liang, P., Candès, E., and Hashimoto, T
Muennighoff, N., Yang, Z., Shi, W., Li, X. L., Fei-Fei, L., Hajishirzi, H., Zettlemoyer, L., Liang, P., Candès, E., and Hashimoto, T. B. s1: Simple test-time scaling. InEMNLP, 2025
work page 2025
-
[61]
Müller, A. Integral probability metrics and their generating classes of functions.Advances in Applied Probability, 1997
work page 1997
-
[62]
How gpt-5 helped mathematician ernest ryu solve a 40-year-old open problem, 2025
OpenAI. How gpt-5 helped mathematician ernest ryu solve a 40-year-old open problem, 2025. URLhttps://openai.com/index/gpt-5-mathematical-discovery/
work page 2025
-
[63]
Training language models to follow instructions with human feedback
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. InNeurIPS, 2022
work page 2022
-
[64]
Pal, A., Karkhanis, D., Dooley, S., Roberts, M., Naidu, S., and White, C. Smaug: Fixing failure modes of preference optimisation with dpo-positive.arXiv preprint arXiv:2402.13228, 2024
-
[65]
Pan, X., Chen, Y ., Chen, Y ., Sun, Y ., Chen, D., Zhang, W., Xie, Y ., Huang, Y ., Zhang, Y ., Gao, D., Li, Y ., Ding, B., and Zhou, J. Trinity-rft: A general-purpose and unified framework for reinforcement fine-tuning of large language models, 2025. URL https: //arxiv.org/abs/2505.17826
-
[66]
What matters in data for dpo? InNeurIPS, 2025
Pan, Y ., Cai, Z., Chen, G., Zhong, H., and Wang, C. What matters in data for dpo? InNeurIPS, 2025
work page 2025
-
[67]
Phan, L., Gatti, A., Han, Z., Li, N., Hu, J., Zhang, H., Zhang, C. B. C., Shaaban, M., Ling, J., Shi, S., et al. Humanity’s last exam.arXiv preprint arXiv:2501.14249, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. Direct preference optimization: Your language model is secretly a reward model. InNeurIPS, 2023
work page 2023
-
[69]
Roux, N. L., Bellemare, M. G., Lebensold, J., Bergeron, A., Greaves, J., Fréchette, A., Pelletier, C., Thibodeau-Laufer, E., Toth, S., and Work, S. Tapered off-policy reinforce: Stable and efficient reinforcement learning for llms. InNeurIPS, 2025
work page 2025
-
[70]
High-dimensional continuous control using generalized advantage estimation
Schulman, J., Moritz, P., Levine, S., Jordan, M., and Abbeel, P. High-dimensional continuous control using generalized advantage estimation. InICLR, 2016
work page 2016
-
[71]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimiza- tion algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[72]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Outra- geously large neural networks: The sparsely-gated mixture-of-experts layer
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. Outra- geously large neural networks: The sparsely-gated mixture-of-experts layer. InICLR, 2017
work page 2017
-
[74]
Hybridflow: A flexible and efficient rlhf framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., and Wu, C. Hybridflow: A flexible and efficient rlhf framework. InEuroSys, 2025
work page 2025
-
[75]
Ai models collapse when trained on recursively generated data.Nature, 2024
Shumailov, I., Shumaylov, Z., Zhao, Y ., et al. Ai models collapse when trained on recursively generated data.Nature, 2024. 13
work page 2024
-
[76]
Singh, A., Hsu, S., Hsu, K., Mitchell, E., Ermon, S., Hashimoto, T., Sharma, A., and Finn, C. Fspo: Few-shot preference optimization of synthetic preference data in llms elicits effective personalization to real users. InICLR, 2026
work page 2026
-
[77]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 2024
Su, J., Ahmed, M., Lu, Y ., Pan, S., Bo, W., and Liu, Y . Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 2024
work page 2024
-
[78]
Sopo: Text-to-motion generation using semi-online preference optimization
Tan, X., Wang, H., Geng, X., and Zhou, P. Sopo: Text-to-motion generation using semi-online preference optimization. InNeurIPS, 2025
work page 2025
-
[79]
Wang, B., Zheng, R., Chen, L., Liu, Y ., Dou, S., Huang, C., Shen, W., Jin, S., Zhou, E., Shi, C., et al. Secrets of rlhf in large language models part ii: Reward modeling.arXiv preprint arXiv:2401.06080, 2024
-
[80]
Wang, J., Lin, X., Qiao, R., Koh, P. W., Foo, C.-S., and Low, B. K. H. NICE data selection for instruction tuning in LLMs with non-differentiable evaluation metric. InICML, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.