Recognition: 2 theorem links
· Lean TheoremLogging Policy Design for Off-Policy Evaluation
Pith reviewed 2026-05-15 03:04 UTC · model grok-4.3
The pith
A unifying framework derives optimal logging policies that minimize off-policy evaluation error by balancing reward concentration against action coverage across known, unknown, and partial information regimes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We characterize a fundamental reward-coverage tradeoff and propose a unifying framework for logging policy design and derive optimal policies in canonical informational regimes where the target policy and reward distribution are (i) known, (ii) unknown, and (iii) partially known through priors or noisy estimates at logging time.
What carries the argument
The reward-coverage tradeoff, which determines how logging probability mass should be allocated to minimize the combined variance and bias of standard OPE estimators.
If this is right
- When the target policy and rewards are known, the optimal logging policy concentrates mass on high-reward actions the target is likely to select.
- When both are unknown, the optimal policy spreads probability to guarantee coverage of every action the target might take.
- When only priors or noisy estimates exist, the optimal policy interpolates between the known and unknown cases using the available information.
- Firms evaluating multiple candidate recommenders can use the derived policies to collect data that yields more accurate offline comparisons.
Where Pith is reading between the lines
- The same tradeoff logic could be used to design adaptive logging policies that update as rewards are observed during data collection.
- The framework connects directly to problems of experimental design in causal inference when the goal is policy-value estimation rather than simple average treatment effects.
- Simulation studies in recommendation environments could quantify how much OPE error drops when the derived policies replace standard uniform or epsilon-greedy logging.
Load-bearing premise
The three informational regimes accurately describe the knowledge available when the logging policy is chosen and the variance and bias formulas used for OPE estimators match real behavior.
What would settle it
A controlled simulation or field test in which the theoretically optimal logging policy produces higher mean squared error for the target policy value than a uniform random logging policy when the target policy and reward distribution are known in advance.
Figures


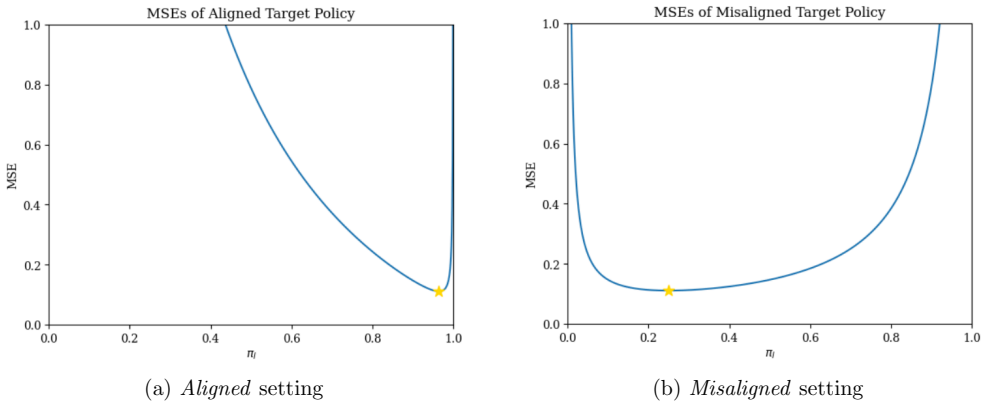




read the original abstract
Off-policy evaluation (OPE) estimates the value of a target treatment policy (e.g., a recommender system) using data collected by a different logging policy. It enables high-stakes experimentation without live deployment, yet in practice accuracy depends heavily on the logging policy used to collect data for computing the estimate. We study how to design logging policies that minimize OPE error for given target policies. We characterize a fundamental reward-coverage tradeoff: concentrating probability mass on high-reward actions reduces variance but risks missing signal on actions the target policy may take. We propose a unifying framework for logging policy design and derive optimal policies in canonical informational regimes where the target policy and reward distribution are (i) known, (ii) unknown, and (iii) partially known through priors or noisy estimates at logging time. Our results provide actionable guidance for firms choosing among multiple candidate recommendation systems. We demonstrate the importance of treatment selection when gathering data for OPE, and describe theoretically optimal approaches when this is a firm's primary objective. We also distill practical design principles for selecting logging policies when operational constraints prevent implementing the theoretical optimum.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unifying framework for designing logging policies that minimize off-policy evaluation (OPE) error for a given target policy. It characterizes a fundamental reward-coverage tradeoff and derives optimal logging policies under three informational regimes: (i) target policy and reward distribution known, (ii) both unknown, and (iii) partially known via priors or noisy estimates at logging time. The results are illustrated with practical guidance for firms selecting among candidate recommendation systems.
Significance. If the derivations hold under standard OPE estimators, the work provides theoretically grounded and actionable principles for data collection in OPE, addressing a practical gap in high-stakes settings such as recommender systems. The unification across knowledge regimes and explicit treatment of the reward-coverage tradeoff represent a clear contribution to the OPE literature.
major comments (2)
- [§4] §4 (unknown regime): The minimax optimality derivation plugs the standard IPS/DR variance formula directly into the objective and solves over reward distributions. This yields a closed-form logging policy only under the exact variance expression; the paper does not show that the same policy remains optimal when the deployed estimator uses a misspecified reward model or clipped importance weights, which is the typical case in practice.
- [§5] §5 (partial-knowledge regime): The optimality result relies on the prior or noisy estimate entering the objective exactly as modeled. No sensitivity analysis is provided for how errors in the prior propagate to the derived logging policy or to the resulting OPE error bound.
minor comments (2)
- [Abstract] The abstract states that derivations exist but the main text should include at least one explicit equation (e.g., the objective in Eq. (3) or the closed-form policy in the known regime) to allow readers to verify the claimed optimality without reconstructing the algebra.
- [§2] Notation for the logging policy π_log and target policy π_tgt should be introduced once in §2 and used consistently; several later sections re-define the same symbols.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important practical considerations for the derived logging policies. We address each major comment below and outline targeted revisions that clarify assumptions and strengthen applicability without altering the core theoretical contributions.
read point-by-point responses
-
Referee: [§4] §4 (unknown regime): The minimax optimality derivation plugs the standard IPS/DR variance formula directly into the objective and solves over reward distributions. This yields a closed-form logging policy only under the exact variance expression; the paper does not show that the same policy remains optimal when the deployed estimator uses a misspecified reward model or clipped importance weights, which is the typical case in practice.
Authors: We agree that the closed-form result in §4 is derived under the exact IPS/DR variance expression without misspecification or clipping. The manuscript positions this as the ideal theoretical benchmark for the reward-coverage tradeoff, consistent with standard OPE analysis. We will revise §4 to explicitly state these assumptions, add a paragraph discussing how the policy may serve as a robust initialization in practice, and include a brief remark that extensions to misspecified or clipped estimators are left for future work. This does not change the main result but improves clarity on scope. revision: yes
-
Referee: [§5] §5 (partial-knowledge regime): The optimality result relies on the prior or noisy estimate entering the objective exactly as modeled. No sensitivity analysis is provided for how errors in the prior propagate to the derived logging policy or to the resulting OPE error bound.
Authors: The partial-knowledge results treat the prior or noisy estimate as entering the objective in the modeled form, which enables the closed-form characterization. We acknowledge the value of sensitivity analysis for robustness. We will add a short subsection in §5 with a numerical sensitivity study (perturbing the prior mean/variance and reporting changes in the resulting logging policy and OPE bound) to quantify propagation of errors. This revision directly addresses the concern while remaining within the paper's scope. revision: yes
Circularity Check
No circularity: derivations optimize standard OPE variance expressions without self-referential reduction
full rationale
The paper's core derivations minimize an OPE error objective constructed from established IPS/DR variance and bias formulas applied to the logging policy probabilities, target policy, and reward distribution. These steps constitute a standard optimization problem over known mathematical expressions rather than redefining the target quantity in terms of itself or fitting parameters that are then relabeled as predictions. No self-citation chains, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing justifications; the informational regimes are treated as modeling assumptions under which the optimization is solved. The resulting policies are therefore independent outputs of the framework, not equivalent to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reward distributions and target policies exist and can be characterized as known, unknown, or partially known at logging time
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We characterize a fundamental reward-coverage tradeoff... derive optimal policies in canonical informational regimes
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Neyman allocation... posterior shrinkage under Gaussian hierarchical prior
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 39th International Conference on Machine Learning (ICML) , pages =
Safe Exploration for Efficient Policy Evaluation and Comparison , author =. Proceedings of the 39th International Conference on Machine Learning (ICML) , pages =. 2022 , publisher =
work page 2022
-
[2]
arXiv preprint arXiv:2402.08201 , year=
Off-policy evaluation in markov decision processes under weak distributional overlap , author=. arXiv preprint arXiv:2402.08201 , year=
-
[3]
The Annals of Statistics , volume=
Off-policy evaluation in partially observed Markov decision processes under sequential ignorability , author=. The Annals of Statistics , volume=. 2023 , publisher=
work page 2023
-
[4]
Advances in neural information processing systems , volume=
Learning to optimize via information-directed sampling , author=. Advances in neural information processing systems , volume=
-
[5]
Mathematics of Operations Research , volume=
Learning to optimize via posterior sampling , author=. Mathematics of Operations Research , volume=. 2014 , publisher=
work page 2014
-
[6]
arXiv preprint arXiv:2305.11812 , year=
Off-policy evaluation beyond overlap: partial identification through smoothness , author=. arXiv preprint arXiv:2305.11812 , year=
-
[7]
Journal of Causal Inference , volume=
Adaptive normalization for IPW estimation , author=. Journal of Causal Inference , volume=. 2023 , publisher=
work page 2023
-
[8]
Advances in Neural Information Processing Systems , volume=
Counterfactual evaluation of peer-review assignment policies , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Information Systems Research , year =
Carlos Fernández-Loría and Foster Provost and Jesse Anderton and Benjamin Carterette and Praveen Chandar , title =. Information Systems Research , year =
-
[10]
Off-Policy Evaluation for Slate Recommendation , url =
Swaminathan, Adith and Krishnamurthy, Akshay and Agarwal, Alekh and Dudik, Miro and Langford, John and Jose, Damien and Zitouni, Imed , booktitle =. Off-Policy Evaluation for Slate Recommendation , url =
-
[11]
Joel Persson , title =
-
[12]
Imbens, Guido W and Rubin, Donald B , year=
- [13]
-
[14]
Clinical Kidney Journal , volume=
An Introduction to Inverse Probability of Treatment Weighting in Observational Research , author=. Clinical Kidney Journal , volume=. 2022 , publisher=
work page 2022
- [15]
- [16]
-
[17]
Chen, Minmin and Beutel, Alex and Covington, Paul and Jain, Sagar and Belletti, Francois and Chi, Ed H. , title =. Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining , pages =. 2019 , isbn =. doi:10.1145/3289600.3290999 , abstract =
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Predictive Off-Policy Policy Evaluation for Nonstationary Decision Problems, with Applications to Digital Marketing , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2017 , month =. doi:10.1609/aaai.v31i2.19104 , url =
-
[19]
Journal of the American Statistical Association , volume=
Marginal Mean Models for Dynamic Regimes , author=. Journal of the American Statistical Association , volume=. 2001 , publisher=
work page 2001
-
[20]
Advances in Neural Information Processing Systems 36 (NeurIPS) , year =
Optimal Treatment Allocation for Efficient Policy Evaluation in Sequential Decision Making , author =. Advances in Neural Information Processing Systems 36 (NeurIPS) , year =
-
[21]
Off-Policy Evaluation and Learning from Logged Bandit Feedback , author =. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages =
-
[22]
Evaluating the Robustness of Off-Policy Evaluation , url =
Saito, Yuta and Udagawa, Takuma and Kiyohara, Haruka and Mogi, Kazuki and Narita, Yusuke and Tateno, Kei , urldate =. Evaluating the Robustness of Off-Policy Evaluation , url =. doi:10.48550/arXiv.2108.13703 , abstract =. 2108.13703 , keywords =
-
[23]
Towards Scalable and Robust Structured Bandits: A Meta-Learning Framework , url =
Wan, Runzhe and Ge, Lin and Song, Rui , urldate =. Towards Scalable and Robust Structured Bandits: A Meta-Learning Framework , url =. doi:10.48550/arXiv.2202.13227 , shorttitle =. 2202.13227 , keywords =
-
[24]
Wan, Runzhe and Liu, Yu and. Experimentation Platforms Meet Reinforcement Learning: Bayesian Sequential Decision-Making for Continuous Monitoring , url =. doi:10.48550/arXiv.2304.00420 , shorttitle =. 2304.00420 , keywords =
-
[25]
Off-Policy Policy Evaluation for Sequential Decisions Under Unobserved Confounding , url =
Namkoong, Hongseok and Keramati, Ramtin and Yadlowsky, Steve and Brunskill, Emma , urldate =. Off-Policy Policy Evaluation for Sequential Decisions Under Unobserved Confounding , url =. doi:10.48550/arXiv.2003.05623 , abstract =. 2003.05623 , keywords =
-
[26]
Minimax-Regret Sample Selection in Randomized Experiments , url =
Hu, Yuchen and Zhu, Henry and Brunskill, Emma and Wager, Stefan , urldate =. Minimax-Regret Sample Selection in Randomized Experiments , url =. doi:10.48550/arXiv.2403.01386 , abstract =. 2403.01386 , keywords =
-
[27]
Adaptive Instrument Design for Indirect Experiments , url =
Chandak, Yash and Shankar, Shiv and Syrgkanis, Vasilis and Brunskill, Emma , urldate =. Adaptive Instrument Design for Indirect Experiments , url =. doi:10.48550/arXiv.2312.02438 , abstract =. 2312.02438 , keywords =
-
[28]
Chaloner, Kathryn and Verdinelli, Isabella , urldate =. Bayesian Experimental Design: A Review , volume =. doi:10.1214/ss/1177009939 , shorttitle =
-
[29]
Safe Optimal Design with Applications in Off-Policy Learning , author=. 2022 , organization=
work page 2022
-
[30]
Proceedings of The Web Conference (WWW) , year =
Variance-Minimizing Augmentation Logging for Counterfactual Evaluation in Contextual Bandits , author =. Proceedings of The Web Conference (WWW) , year =
-
[31]
Proceedings of the 34th International Conference on Machine Learning , series =
Optimal and Adaptive Off-Policy Evaluation in Contextual Bandits , author =. Proceedings of the 34th International Conference on Machine Learning , series =
-
[32]
Optimal Off-Policy Evaluation from Multiple Logging Policies , url =
Kallus, Nathan and Saito, Yuta and Uehara, Masatoshi , urldate =. Optimal Off-Policy Evaluation from Multiple Logging Policies , url =. Proceedings of the 38th International Conference on Machine Learning , publisher =
-
[33]
arXiv preprint arXiv:2212.06355 , year=
A Review of Off-Policy Evaluation in Reinforcement Learning , author=. arXiv preprint arXiv:2212.06355 , year=
-
[34]
Carlsson, Emil and Dubhashi, Devdatt and Johansson, Fredrik D. , urldate =. Thompson Sampling for Bandits with Clustered Arms , volume =. doi:10.24963/ijcai.2021/305 , abstract =
-
[35]
and Dubhashi, Devdatt , urldate =
Carlsson, Emil and Basu, Debabrota and Johansson, Fredrik D. and Dubhashi, Devdatt , urldate =. Pure Exploration in Bandits with Linear Constraints , url =. doi:10.48550/arXiv.2306.12774 , abstract =. 2306.12774 , keywords =
-
[36]
Power Constrained Bandits , url =
Yao, Jiayu and Brunskill, Emma and Pan, Weiwei and Murphy, Susan and Doshi-Velez, Finale , urldate =. Power Constrained Bandits , url =. doi:10.48550/arXiv.2004.06230 , abstract =. 2004.06230 , keywords =
-
[37]
Provably Good Batch Reinforcement Learning Without Great Exploration , url =
Liu, Yao and Swaminathan, Adith and Agarwal, Alekh and Brunskill, Emma , urldate =. Provably Good Batch Reinforcement Learning Without Great Exploration , url =. doi:10.48550/arXiv.2007.08202 , abstract =. 2007.08202 , keywords =
-
[38]
Design of Experiments for Stochastic Contextual Linear Bandits , url =
Zanette, Andrea and Dong, Kefan and Lee, Jonathan and Brunskill, Emma , urldate =. Design of Experiments for Stochastic Contextual Linear Bandits , url =. doi:10.48550/arXiv.2107.09912 , abstract =. 2107.09912 , keywords =
-
[39]
Dominitz, Jeff and F. Manski, Charles , urldate =. More Data or Better Data? A Statistical Decision Problem , volume =. doi:10.1093/restud/rdx005 , shorttitle =
-
[40]
Policy-Adaptive Estimator Selection for Off-Policy Evaluation , url =
Udagawa, Takuma and Kiyohara, Haruka and Narita, Yusuke and Saito, Yuta and Tateno, Kei , urldate =. Policy-Adaptive Estimator Selection for Off-Policy Evaluation , url =. doi:10.48550/arXiv.2211.13904 , abstract =. 2211.13904 , keywords =
-
[41]
arXiv preprint arXiv:2402.10592 , year=
Optimizing Adaptive Experiments: A Unified Approach to Regret Minimization and Best-Arm Identification , author=. arXiv preprint arXiv:2402.10592 , year=
-
[42]
Journal of the Royal Statistical Society , volume =
Neyman, Jerzy , title =. Journal of the Royal Statistical Society , volume =. 1934 , doi =
work page 1934
-
[43]
Federated Offline Policy Learning , url =
Carranza, Aldo Gael and Athey, Susan , urldate =. Federated Offline Policy Learning , url =. doi:10.48550/arXiv.2305.12407 , abstract =. 2305.12407 , keywords =
-
[44]
Reinforcement Learning: An Introduction , author=. 1998 , publisher=
work page 1998
-
[45]
Cho, Brian and Meier, Dominik and Gan, Kyra and Kallus, Nathan , urldate =. Reward Maximization for Pure Exploration: Minimax Optimal Good Arm Identification for Nonparametric Multi-Armed Bandits , url =. doi:10.48550/arXiv.2410.15564 , shorttitle =. 2410.15564 , keywords =
-
[46]
Sun, Ke and Kong, Linglong and Zhu, Hongtu and Shi, Chengchun , urldate =. Optimal Treatment Allocation Strategies for A/B Testing in Partially Observable Time Series Experiments , url =. doi:10.48550/arXiv.2408.05342 , abstract =. 2408.05342 , keywords =
-
[47]
Sequential Experimental Design for Transductive Linear Bandits
Fiez, Tanner and Jain, Lalit and Jamieson, Kevin and Ratliff, Lillian , urldate =. Sequential Experimental Design for Transductive Linear Bandits , url =. doi:10.48550/arXiv.1906.08399 , abstract =. 1906.08399 , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.08399 1906
-
[48]
Best-Arm Identification in Linear Bandits
Soare, Marta and Lazaric, Alessandro and Munos, Rémi , urldate =. Best-Arm Identification in Linear Bandits , url =. doi:10.48550/arXiv.1409.6110 , abstract =. 1409.6110 , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1409.6110
-
[49]
Narang, Adhyyan and Wagenmaker, Andrew and Ratliff, Lillian and Jamieson, Kevin , urldate =. Sample Complexity Reduction via Policy Difference Estimation in Tabular Reinforcement Learning , url =. doi:10.48550/arXiv.2406.06856 , abstract =. 2406.06856 , keywords =
-
[50]
Practical Improvements of A/B Testing with Off-Policy Estimation , author =. 2025 , eprint =. doi:10.48550/arXiv.2506.10677 , url =
-
[51]
Toward Minimax Off-Policy Value Estimation , author =. Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics , pages =. 2015 , editor =
work page 2015
-
[52]
International Conference on Machine Learning , pages=
Optimal and Adaptive Off-Policy Evaluation in Contextual Bandits , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
-
[53]
Journal of the American Statistical Association , volume=
Statistical Inference for Online Decision Making: In a Contextual Bandit Setting , author=. Journal of the American Statistical Association , volume=. 2021 , publisher=
work page 2021
-
[54]
Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
Off-Policy Evaluation via Adaptive Weighting with Data from Contextual Bandits , author=. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
-
[55]
arXiv preprint arXiv:2411.06329 , year=
Regret Minimization and Statistical Inference in Online Decision Making with High-Dimensional Covariates , author=. arXiv preprint arXiv:2411.06329 , year=
-
[56]
International Conference on Artificial Intelligence and Statistics , pages=
Multi-Armed Bandit Experimental Design: Online Decision-Making and Adaptive Inference , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
work page 2023
-
[57]
Journal of the American Statistical Association , volume=
Doubly Robust Interval Estimation for Optimal Policy Evaluation in Online Learning , author=. Journal of the American Statistical Association , volume=. 2024 , publisher=
work page 2024
-
[58]
Advances in Neural Information Processing Systems , volume=
Inference for Batched Bandits , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
Advances in Neural Information Processing Systems , volume=
Statistical Inference with M-Estimators on Adaptively Collected Data , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Advances in Neural Information Processing Systems , volume=
Post-Contextual-Bandit Inference , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
Annual Review of Statistics and its Application , volume=
Demystifying Inference After Adaptive Experiments , author=. Annual Review of Statistics and its Application , volume=. 2025 , publisher=
work page 2025
-
[62]
Doubly Robust Policy Evaluation and Optimization , author=. Statistical Science , volume=. 2014 , publisher=
work page 2014
-
[63]
Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics , year =
Balanced Off-Policy Evaluation in General Action Spaces , author =. Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics , year =
-
[64]
Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing , pages =
Linear Bandits with Limited Adaptivity and Learning Distributional Optimal Design , author =. Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing , pages =
-
[65]
Proceedings of the 39th International Conference on Machine Learning , year =
Off-Policy Evaluation for Large Action Spaces via Embeddings , author =. Proceedings of the 39th International Conference on Machine Learning , year =
-
[66]
Journal of the American Statistical Association , volume=
A Generalization of Sampling Without Replacement from a Finite Universe , author=. Journal of the American Statistical Association , volume=. 1952 , publisher=
work page 1952
- [67]
-
[68]
Journal of Computational and Graphical Statistics , volume=
Truncated Importance Sampling , author=. Journal of Computational and Graphical Statistics , volume=. 2008 , publisher=
work page 2008
-
[69]
Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability , volume=
Estimation with Quadratic Loss , author=. Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability , volume=. 1961 , organization=
work page 1961
- [70]
-
[71]
The Annals of Mathematical Statistics , pages=
Optimum allocation in linear regression theory , author=. The Annals of Mathematical Statistics , pages=. 1952 , publisher=
work page 1952
-
[72]
Optimum Experimental Designs, with
Atkinson, Anthony and Donev, Alexander and Tobias, Randall , volume=. Optimum Experimental Designs, with. 2007 , publisher=
work page 2007
-
[73]
Available at SSRN 5126080 , year=
Automated Experimental Design with Optimization from Historical Data Simulations , author=. Available at SSRN 5126080 , year=
-
[74]
Journal of the Royal Statistical Society: Series B (Methodological) , volume=
Optimum Experimental Designs , author=. Journal of the Royal Statistical Society: Series B (Methodological) , volume=. 1959 , publisher=
work page 1959
-
[75]
The Annals of Mathematical Statistics , volume=
On the Efficient Design of Statistical Investigations , author=. The Annals of Mathematical Statistics , volume=. 1943 , publisher=
work page 1943
-
[76]
An Introduction to Optimal Designs for Social and Biomedical Research , author=. 2009 , publisher=
work page 2009
-
[77]
Tutorials in Operations Research: Smarter Decisions for a Better World , pages=
Experimental Design for Causal Inference Through an Optimization Lens , author=. Tutorials in Operations Research: Smarter Decisions for a Better World , pages=. 2024 , publisher=
work page 2024
-
[78]
Optimal Experimental Design for Staggered Rollouts , author=. Management Science , volume=. 2024 , publisher=
work page 2024
-
[79]
An Empirical Bayes Approach to Statistics , author=. Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics , volume=. 1956 , organization=
work page 1956
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.