When Vision Speaks for Sound
Pith reviewed 2026-05-20 22:09 UTC · model grok-4.3
The pith
Video models often infer or hallucinate sounds from visual cues rather than verifying the audio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
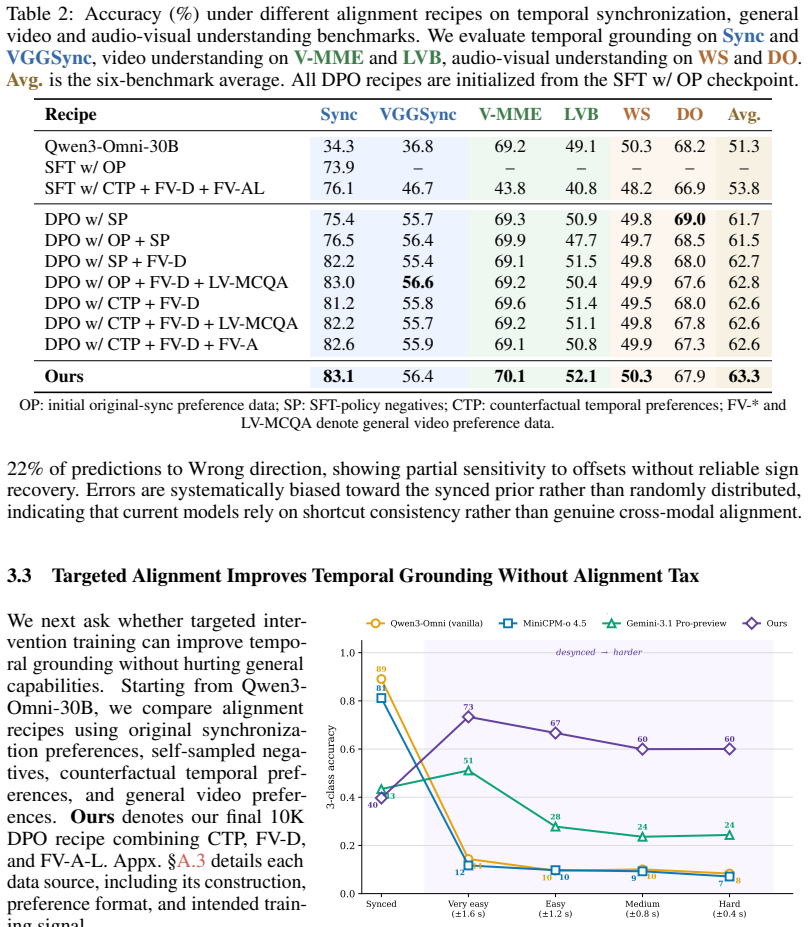
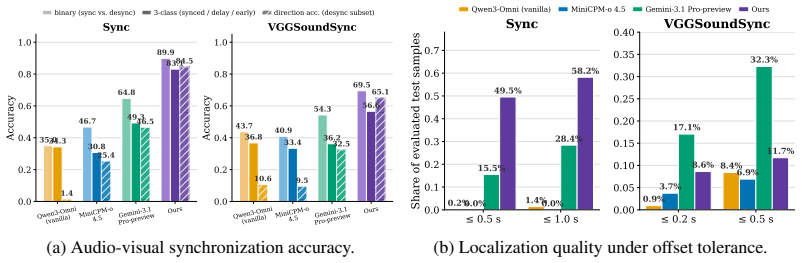
Models rely on visual cues to infer or hallucinate acoustic information rather than verifying the audio stream. This audio-visual Clever Hans effect is diagnosed using the Thud framework based on Shift, Mute, and Swap counterfactual audio edits. A two-stage alignment recipe using intervention-derived preference pairs improves average performance across these dimensions by 28 percentage points.
What carries the argument
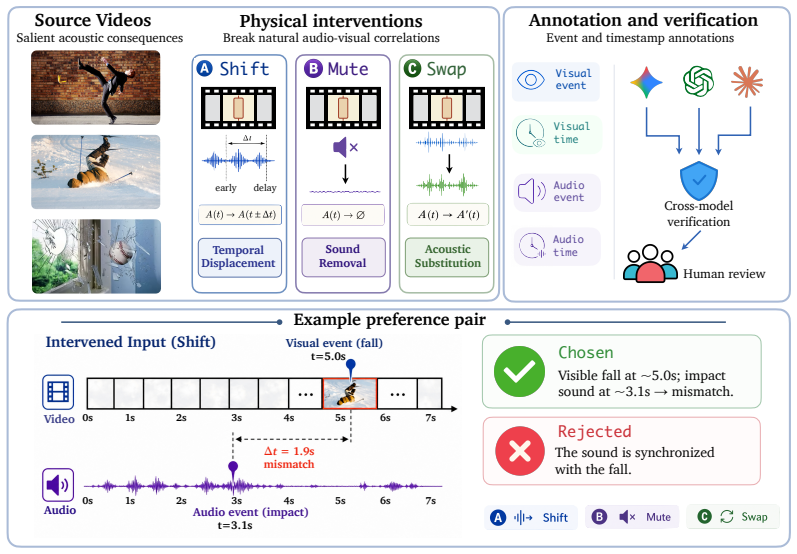
The audio-visual Clever Hans effect diagnosed through Thud, an intervention-driven probing framework that applies three counterfactual audio edits (Shift to test temporal synchronization, Mute to test sound existence, Swap to test audio-visual consistency), combined with a two-stage alignment recipe that teaches verification via preference pairs while regularizing with general video preferences.
If this is right
- Systematic testing with temporal shifts, muting, and swaps reveals whether models truly ground responses in audio or default to visual correlations.
- Training on preference pairs derived from these interventions teaches audio verification while avoiding over-specialization.
- Gains on the three intervention tests translate to better handling of real audio-visual misalignment cases.
- General video and audio-visual QA performance stays stable or improves slightly after the two-stage alignment.
Where Pith is reading between the lines
- Strong visual-audio correlations in existing training data likely encourage models to shortcut true multimodal verification.
- The same reliance on cross-modal correlations may appear in other multimodal setups beyond video and sound.
- Extending the intervention method to more varied or layered mismatches could probe deeper levels of audio understanding.
Load-bearing premise
The three counterfactual audio edits isolate the model's ability to verify audio without introducing new biases or changing visual processing independently of the intended audio check.
What would settle it
A model that performs at similar levels on videos with shifted, muted, or swapped audio as on correctly aligned audio, by correctly identifying the mismatches, would show it is verifying the audio stream rather than relying on visuals.
Figures






read the original abstract
Despite rapid progress in video-capable MLLMs, we find that their apparent audio understanding in videos is often vision-driven: models rely on visual cues to infer or hallucinate acoustic information, rather than verifying the audio stream. This issue appears across both state-of-the-art open-source omni models and leading closed-source models from providers such as Google and OpenAI. We characterize this failure mode as an audio-visual Clever Hans effect, in which models appear (falsely) audio-grounded, but actually exploit visual-acoustic correlations without verifying whether the audio and visual streams are truly aligned. To systematically study this behavior, we introduce Thud, an intervention-driven probing framework based on three counterfactual audio edits: Shift, which tests temporal synchronization; Mute, which tests sound existence; and Swap, which tests audio-visual consistency. Beyond diagnosis, we further study a two-stage alignment recipe: intervention-derived preference pairs teach audio verification, while event-level general video preferences regularize the model against over-specialization. Our best 10K-sample recipe improves average performance across the three intervention dimensions by 28 percentage points, while slightly improving performance on general video and audio-visual QA benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that video-capable multimodal large language models (MLLMs) exhibit an 'audio-visual Clever Hans effect,' relying on visual cues to infer or hallucinate acoustic information instead of verifying the audio stream. This is diagnosed across open- and closed-source models using the Thud probing framework, which applies three counterfactual audio edits (Shift for temporal synchronization, Mute for sound existence, and Swap for audio-visual consistency). The authors further propose a two-stage alignment recipe—intervention-derived preference pairs to teach audio verification, regularized by event-level general video preferences—that yields a 28 percentage point average improvement on the three Thud dimensions while slightly improving general video and audio-visual QA benchmarks.
Significance. If the central claims hold after addressing the isolation of the edits, the work would be significant for highlighting a systematic limitation in current MLLMs' cross-modal grounding, with direct implications for reliable video understanding applications. The intervention-driven diagnosis and preference-based mitigation recipe are constructive strengths, offering a falsifiable test and a practical training method that avoids over-specialization. The systematic evaluation across multiple model classes adds value, though the overall impact hinges on confirming that gains reflect genuine audio verification rather than learning to ignore edit artifacts.
major comments (2)
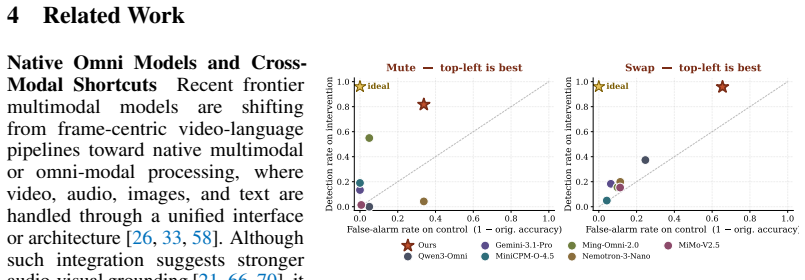
- [Thud framework] Thud framework (counterfactual edits section): The claim that Shift, Mute, and Swap isolate audio verification capability is load-bearing for the Clever Hans diagnosis, yet the manuscript provides no controls showing that models cannot detect these edits via audio-only heuristics. Mute removes all audio energy (detectable by simple RMS thresholds), Shift alters temporal statistics (potentially flagged by audio feature extractors), and Swap replaces content (possibly caught by quality or spectral heuristics). Without audio-only baseline results or attention analysis on the edited streams, poor baseline performance could reflect generic audio shortfalls rather than vision-driven inference.
- [Alignment recipe and evaluation] Two-stage alignment recipe and results: The reported 28-point average gain on Shift/Mute/Swap is presented without error bars, number of runs, or ablation on the 10K preference pairs versus general preferences. It is therefore unclear whether the improvement teaches cross-modal verification or merely suppresses responses to the specific artifacts introduced by the edits. This directly affects the claim that the recipe acquires 'genuine audio verification.'
minor comments (2)
- [Abstract] Abstract: The statement that the recipe 'slightly improves' general benchmarks should specify the exact benchmarks and delta values to allow readers to assess any trade-offs.
- [Methods] The manuscript would benefit from a clearer description of how the preference pairs are constructed from the interventions (e.g., which model generates the rejected responses and the exact prompt templates).
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which help clarify the robustness of the Thud framework and the alignment recipe. We address each major point below and commit to revisions that strengthen the evidence for genuine audio verification without overclaiming current results.
read point-by-point responses
-
Referee: [Thud framework] Thud framework (counterfactual edits section): The claim that Shift, Mute, and Swap isolate audio verification capability is load-bearing for the Clever Hans diagnosis, yet the manuscript provides no controls showing that models cannot detect these edits via audio-only heuristics. Mute removes all audio energy (detectable by simple RMS thresholds), Shift alters temporal statistics (potentially flagged by audio feature extractors), and Swap replaces content (possibly caught by quality or spectral heuristics). Without audio-only baseline results or attention analysis on the edited streams, poor baseline performance could reflect generic audio shortfalls rather than vision-driven inference.
Authors: We agree that explicit controls are necessary to rule out audio-only detection of the edits. The Thud interventions target distinct failure modes (temporal misalignment, absence of sound, and cross-modal inconsistency), but without audio-only baselines it remains possible that models exploit low-level audio cues. In the revised manuscript we will add audio-only evaluations on the edited streams (prompting models with audio alone) to quantify how much of the performance drop is attributable to vision-driven inference versus generic audio heuristics. We will also report attention visualizations where available to illustrate cross-modal reliance. These additions directly address the isolation concern while preserving the core Clever Hans diagnosis. revision: yes
-
Referee: [Alignment recipe and evaluation] Two-stage alignment recipe and results: The reported 28-point average gain on Shift/Mute/Swap is presented without error bars, number of runs, or ablation on the 10K preference pairs versus general preferences. It is therefore unclear whether the improvement teaches cross-modal verification or merely suppresses responses to the specific artifacts introduced by the edits. This directly affects the claim that the recipe acquires 'genuine audio verification.'
Authors: We acknowledge that the current presentation lacks statistical rigor and ablations, which limits confidence that gains reflect true audio verification rather than artifact suppression. In the revised manuscript we will include error bars computed over multiple training runs with different random seeds, and add an ablation comparing (i) intervention-derived pairs alone, (ii) general video preferences alone, and (iii) the full two-stage recipe. These results will be reported on both the Thud dimensions and held-out general video/audio-visual QA benchmarks to demonstrate that the recipe improves verification without degrading broader capabilities. revision: yes
Circularity Check
No circularity: empirical diagnosis via external interventions and standard preference training
full rationale
The paper's core contribution is an empirical diagnosis of vision-driven audio inference using three externally defined counterfactual edits (Shift for temporal sync, Mute for sound existence, Swap for consistency) collected into the Thud framework, followed by a two-stage training recipe that generates preference pairs from those same edits plus general video preferences. No equations, self-definitional loops, or fitted parameters are invoked that would make the reported 28-point gain equivalent to the inputs by construction; the interventions are defined independently of model outputs, and performance gains reflect observable changes after training rather than tautological renaming or self-citation chains. The work is self-contained against external benchmarks and does not rely on load-bearing self-citations for its central claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Counterfactual audio edits isolate audio verification without confounding visual changes
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce THUD, an intervention-driven probing framework based on three counterfactual audio edits: Shift, which tests temporal synchronization; Mute, which tests sound existence; and Swap, which tests audio-visual consistency.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Analyzing the behavior of visual question answering models
Aishwarya Agrawal, Dhruv Batra, and Devi Parikh. Analyzing the behavior of visual question answering models. In Jian Su, Kevin Duh, and Xavier Carreras, editors,Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1955–1960, Austin, Texas, November 2016. Association for Computational Linguistics
work page 2016
-
[2]
Self- supervised learning by cross-modal audio-video clustering.ArXiv, abs/1911.12667, 2019
Humam Alwassel, Dhruv Kumar Mahajan, Lorenzo Torresani, Bernard Ghanem, and Du Tran. Self- supervised learning by cross-modal audio-video clustering.ArXiv, abs/1911.12667, 2019
-
[3]
Relja Arandjelovi´c and Andrew Zisserman. Look, listen and learn.2017 IEEE International Conference on Computer Vision (ICCV), pages 609–617, 2017
work page 2017
-
[4]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Thomas Henighan, Andy Jones, Nicholas Joseph, Benjamin Mann, Nova Dassarma, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, John Kernion, Kamal Ndousse, Catherine Olsson, Dario Amodei, Tom B. Brown, Jack Clark, Sam McCandlish, Chris Olah, and Jared Kaplan. A general language assistant as ...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova Dassarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Thomas Henighan, Nicholas Joseph, Saurav Kadavath, John Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Ami Baid, Zihui Xue, and Kristen Grauman. Don’t let the video speak: Audio-contrastive preference optimization for audio-visual language models.arXiv preprint arXiv:2604.14129, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Buch, Cristobal Eyzaguirre, Adrien Gaidon, Jiajun Wu, Li Fei-Fei, and Juan Carlos Niebles
S. Buch, Cristobal Eyzaguirre, Adrien Gaidon, Jiajun Wu, Li Fei-Fei, and Juan Carlos Niebles. Revisiting the “video” in video-language understanding.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2907–2917, 2022
work page 2022
-
[8]
Rui Cai, Bangzheng Li, Xiaofei Wen, Muhao Chen, and Zhe Zhao. Diagnosing and mitigating modality interference in multimodal large language models.ArXiv, abs/2505.19616, 2025
-
[9]
Quo vadis, action recognition? a new model and the kinetics dataset
João Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4724–4733, 2017
work page 2017
-
[10]
Audio-visual synchronization in the wild
Honglie Chen, Weidi Xie, Triantafyllos Afouras, Arsha Nagrani, Andrea Vedaldi, and Andrew Zisserman. Audio-visual synchronization in the wild. InBMVC, 2021
work page 2021
-
[11]
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. Vggsound: A large-scale audio-visual dataset.ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 721–725, 2020
work page 2020
-
[12]
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V . N. Vishwanathan, and Roman Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Conference on Neural ...
work page 2017
-
[13]
Minicpm-o 4.5: Towards real-time full-duplex omni-modal interaction.CoRR, 2026
Junbo Cui, Bokai Xu, Chongyi Wang, Tianyu Yu, Weiyu Sun, Yingjin Xu, Tianran Wang, Zhihui He, Wenshuo Ma, Tianchi Cai, Jiancheng Gui, Luoyuan Zhang, Xian Sun, Fuwei Huang, Moye Chen, Zhuohang Lin, Hanyu Liu, Qi Gui, Qing-Yuan Han, Yuyang Wen, Huiping Liu, Rongkang Wang, Yaqi Zhang, Hong- Rui Wei, Chi Chen, You Li, Kechen Fang, Jie Zhou, Yuxuan Li, Guoyang...
work page 2026
-
[14]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven C. H. Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Proce...
work page 2023
-
[15]
Dave Epstein, Boyuan Chen, and Carl V ondrick. Oops! predicting unintentional action in video.2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 916–926, 2019. 10
work page 2020
-
[16]
Finevideo.https: //huggingface.co/datasets/HuggingFaceFV/finevideo, 2024
Miquel Farré, Andi Marafioti, Lewis Tunstall, Leandro V on Werra, and Thomas Wolf. Finevideo.https: //huggingface.co/datasets/HuggingFaceFV/finevideo, 2024
work page 2024
-
[17]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InI...
work page 2025
-
[18]
BLINK: Multimodal Large Language Models Can See but Not Perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. ArXiv, abs/2404.12390, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Zemel, Wieland Brendel, Matthias Bethge, and Felix A
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard S. Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. Shortcut learning in deep neural networks.Nat. Mach. Intell., 2(11):665– 673, 2020
work page 2020
-
[20]
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human-labeled dataset for audio events.2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 776–780, 2017
work page 2017
-
[21]
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind one embedding space to bind them all.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15180–15190, 2023
work page 2023
-
[22]
Gemini 3.https://deepmind.google/models/gemini/, 2026
Google DeepMind. Gemini 3.https://deepmind.google/models/gemini/, 2026
work page 2026
-
[23]
Making the V in VQA matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 6325–6334. IEEE Computer Society, 2017
work page 2017
-
[24]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InIEEE/CVF Conference on Computer Vision and Pattern Recogniti...
work page 2024
-
[25]
WorldSense: Evaluating Real-world Omnimodal Understanding for Multimodal LLMs
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluating real-world omnimodal understanding for multimodal llms.CoRR, abs/2502.04326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Peng Jin, Ryuichi Takanobu, Caiwan Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding.arXiv preprint arXiv:2311.08046, 2023
-
[28]
Cooperative learning of audio and video models from self-supervised synchronization
Bruno Korbar, Du Tran, and Lorenzo Torresani. Cooperative learning of audio and video models from self-supervised synchronization. InNeural Information Processing Systems, 2018
work page 2018
-
[29]
Sebastian Lapuschkin, Stephan Wäldchen, Alexander Binder, Grégoire Montavon, Wojciech Samek, and Klaus-Robert Müller. Unmasking clever hans predictors and assessing what machines really learn.Nature Communications, 10, 2019
work page 2019
-
[30]
Videochat: chat-centric video understanding.Science China Information Sciences, 68, 2023
Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wen Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: chat-centric video understanding.Science China Information Sciences, 68, 2023
work page 2023
-
[31]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Lou, Limin Wang, and Yu Qiao. Mvbench: A comprehensive multi-modal video understanding benchmark. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22195–22206, 2024. 11
work page 2024
-
[32]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Lou, Limin Wang, and Yu Qiao. Mvbench: A comprehensive multi-modal video understanding benchmark. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 22195–22206. IEEE, 2024
work page 2024
-
[33]
Baichuan-omni-1.5 technical report
Yadong Li, Jun Liu, Tao Zhang, Song Chen, Tianpeng Li, Zehuan Li, Lijun Liu, Lingfeng Ming, Guosheng Dong, Da Pan, et al. Baichuan-omni-1.5 technical report.arXiv preprint arXiv:2501.15368, 2025
-
[34]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 292–305. Association f...
work page 2023
-
[35]
Video-llava: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, p...
work page 2024
-
[36]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 34892–34916. Curran Associates, Inc., 2023
work page 2023
-
[37]
Video-chatgpt: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Abdul Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, ...
work page 2024
-
[38]
Egoschema: A diagnostic benchmark for very long-form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems...
work page 2023
-
[39]
Pedro Morgado, Nuno Vasconcelos, and Ishan Misra. Audio-visual instance discrimination with cross- modal agreement.2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12470–12481, 2020
work page 2021
-
[40]
Robust audio-visual instance discrimination
Pedro Miguel Morgado, Ishan Misra, and Nuno Vasconcelos. Robust audio-visual instance discrimination. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12929–12940, 2021
work page 2021
-
[41]
OpenAI. Openai GPT-5 system card.CoRR, abs/2601.03267, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human fee...
work page 2022
-
[43]
Andrew Owens and Alexei A. Efros. Audio-visual scene analysis with self-supervised multisensory features. InEuropean Conference on Computer Vision, 2018
work page 2018
-
[44]
Perception test: A diagnostic benchmark for multimodal video models
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Recasens Continente, Larisa Markeeva, Dy- lan Sunil Banarse, Skanda Koppula, Joseph Heyward, Mateusz Malinowski, Yi Yang, Carl Doersch, Tatiana Matejovicova, Yury Sulsky, Antoine Miech, Alexandre Fréchette, Hanna Klimczak, Raphael Koster, Junlin Zhang, Stephanie Winkler, Yusuf Aytar, Simon Osindero, Di...
work page 2023
-
[45]
Von Osten.) a contribution to experimental animal and human psychology
Oskar Pfungst.Clever Hans:(the horse of Mr. Von Osten.) a contribution to experimental animal and human psychology. Holt, Rinehart and Winston, 1911
work page 1911
-
[46]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Systems, 2023. 12
work page 2023
-
[47]
Timechat: A time-sensitive multimodal large language model for long video understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large language model for long video understanding. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14313–14323, 2024
work page 2024
-
[48]
Object hallucination in image captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors, Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045, Brussels, Belgium, October-November 2018. Assoc...
work page 2018
-
[49]
Do Audio-Visual Large Language Models Really See and Hear?
Ramaneswaran Selvakumar, Kaousheik Jayakumar, S Sakshi, Sreyan Ghosh, Ruohan Gao, and Dinesh Manocha. Do audio-visual large language models really see and hear?arXiv preprint arXiv:2604.02605, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Arda Senocak, Tae-Hyun Oh, Junsik Kim, Ming-Hsuan Yang, and In-So Kweon. Learning to localize sound source in visual scenes.2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4358–4366, 2018
work page 2018
-
[51]
Nikhil Singh, Chih-Wei Wu, Iroro Orife, and Mahdi M. Kalayeh. Looking similar, sounding different: Leveraging counterfactual cross-modal pairs for audiovisual representation learning.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26897–26908, 2023
work page 2024
-
[52]
A VH- Bench: A cross-modal hallucination benchmark for audio-visual large language models
Kim Sung-Bin, Oh Hyun-Bin, JungMok Lee, Arda Senocak, Joon Son Chung, and Tae-Hyun Oh. A VH- Bench: A cross-modal hallucination benchmark for audio-visual large language models. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[53]
Ming-omni: A unified multimodal model for perception and generation, 2025
Inclusion AI Team. Ming-omni: A unified multimodal model for perception and generation.CoRR, abs/2506.09344, 2025
-
[54]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
InternVL Team. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.CoRR, abs/2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Nemotron 3 nano omni: Efficient and open multimodal intelligence
Nemotron 3 Nano Omni Team. Nemotron 3 nano omni: Efficient and open multimodal intelligence. 2026
work page 2026
-
[56]
Qwen Team. Qwen3-omni technical report.CoRR, abs/2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Qwen Team. Qwen3-vl technical report.CoRR, abs/2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [58]
-
[59]
Winoground: Probing vision and language models for visio-linguistic compositionality
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 5228–5238. IEEE, 2022
work page 2022
-
[60]
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5228–5238, 2022
work page 2022
-
[61]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 9568–9578. IEEE, 2024
work page 2024
-
[62]
LVBench: An Extreme Long Video Understanding Benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Shiyu Huang, Bin Xu, Yuxiao Dong, Ming Ding, and Jie Tang. Lvbench: An extreme long video understanding benchmark.CoRR, abs/2406.08035, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Internvideo2: Scaling video foundation mod- els for multimodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Jilan Xu, Zun Wang, Yansong Shi, Tianxiang Jiang, Songze Li, Hongjie Zhang, Yifei Huang, Yu Qiao, Yali Wang, and Limin Wang. Internvideo2: Scaling video foundation models for multimodal video understanding. ArXiv, abs/2403.15377, 2024
-
[64]
Videohallucer: Evaluating intrinsic and extrinsic hallucinations in large video-language models
Yuxuan Wang, Yueqian Wang, Dongyan Zhao, Cihang Xie, and Zilong Zheng. Videohallucer: Evaluating intrinsic and extrinsic hallucinations in large video-language models.ArXiv, abs/2406.16338, 2024
-
[65]
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V Le. Finetuned language models are zero-shot learners. InInternational Conference on Learning Representations, 2022. 13
work page 2022
-
[66]
NExt-GPT: Any-to-any multimodal LLM, 2024
Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and Tat-Seng Chua. NExt-GPT: Any-to-any multimodal LLM, 2024
work page 2024
-
[67]
Xiaomi mimo-v2.5: A leap in agency and multimodality
Xiaomi MiMo Team. Xiaomi mimo-v2.5: A leap in agency and multimodality. https://mimo.xiaomi. com/mimo-v2-5/, April 2026. Accessed: 2026-05-04
work page 2026
-
[68]
Mert Yüksekgönül, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision-language models behave like bags-of-words, and what to do about it? InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023
work page 2023
- [69]
-
[70]
Anygpt: Unified multimodal llm with discrete sequence modeling
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, et al. Anygpt: Unified multimodal llm with discrete sequence modeling. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9637–9662, 2024
work page 2024
-
[71]
Video-LLaMA: An instruction-tuned audio-visual language model for video understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-LLaMA: An instruction-tuned audio-visual language model for video understanding. In Yansong Feng and Els Lefever, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 543–553, Singapore, December 2023. Association for Computational Linguistics
work page 2023
-
[72]
Direct preference optimization of video large multimodal models from language model reward
Ruohong Zhang, Liangke Gui, Zhiqing Sun, Yihao Feng, Keyang Xu, Yuanhan Zhang, Di Fu, Chunyuan Li, Alexander G Hauptmann, Yonatan Bisk, and Yiming Yang. Direct preference optimization of video large multimodal models from language model reward. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of the Ame...
work page 2025
-
[73]
Video instruction tuning with synthetic data, 2024
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data, 2024
work page 2024
-
[74]
Llava-video: Video instruction tuning with synthetic data.Trans
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava-video: Video instruction tuning with synthetic data.Trans. Mach. Learn. Res., 2025, 2025
work page 2025
-
[75]
Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities,
Ziwei Zhou, Rui Wang, and Zuxuan Wu. Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities.CoRR, abs/2505.17862, 2025
-
[76]
Omniguard: Unified omni-modal guardrails with deliberate reasoning.ArXiv, abs/2512.02306, 2025
Boyu Zhu, Xiaofei Wen, Wenjie Jacky Mo, Tinghui Zhu, Yanan Xie, Peng Qi, and Muhao Chen. Omniguard: Unified omni-modal guardrails with deliberate reasoning.ArXiv, abs/2512.02306, 2025
-
[77]
Fine-Tuning Language Models from Human Preferences
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul F. Chris- tiano, and Geoffrey Irving. Fine-tuning language models from human preferences.CoRR, abs/1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[78]
Safety fine-tuning at (almost) no cost: A baseline for vision large language models
Yongshuo Zong, Ondrej Bohdal, Tingyang Yu, Yongxin Yang, and Timothy M. Hospedales. Safety fine-tuning at (almost) no cost: A baseline for vision large language models.ArXiv, abs/2402.02207, 2024. 14 Source Videos Salient acoustic consequences Shift Mute Swap Temporal Displacement early delay Physical interventions Break natural audio-visual correlations ...
-
[79]
Visual agreement:Gemini, GPT, and Claude localize the visual event within ϵv = 0.8 seconds, or select overlapping frame units
-
[80]
Audio verification:the acoustic event is audible and its timestamp can be verified by human inspection withinϵ a = 0.5seconds of the Gemini prediction. 3.Event clarity:the visual event has a clear onset or peak moment, such as impact, fall, collision, breakage, or contact
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.