RGB-only Active 3D Scene Graph Generation for Indoor Mobile Robots
Pith reviewed 2026-05-20 09:48 UTC · model grok-4.3
The pith
Robots can build detailed 3D scene graphs from ordinary RGB cameras alone, matching the accuracy of systems that require depth sensors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The proposed approach unifies perception and planning around a shared structured representation that captures object semantics, 3D geometry, relational context, and information from multiple viewpoints, enabling fully visual active incremental construction of 3D scene graphs from RGB input only.
What carries the argument
A shared structured representation that integrates object semantics, 3D geometry, relational context, and multi-view information to drive both scene graph construction and viewpoint selection.
If this is right
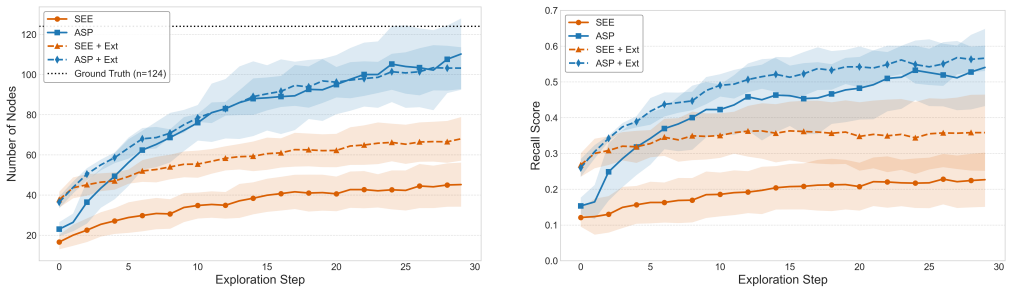
- RGB-only pipelines achieve F1-score parity with ground-truth depth baselines on the Replica dataset.
- Semantic-driven viewpoint selection detects more than twice as many objects as a geometric frontier-based baseline under the same exploration budget on ReplicaCAD.
- The framework supports direct incorporation of RGB images from both robot-mounted cameras and fixed external cameras in the same representation.
- External RGB views can initialize and enrich the scene graph without requiring extra robot motion.
Where Pith is reading between the lines
- Robots lacking depth sensors could still perform structured indoor mapping, lowering hardware costs for home or service applications.
- Semantic viewpoint choice may cut total travel distance needed to achieve a complete object inventory in cluttered rooms.
- Mixed onboard and static camera feeds could be fused to handle occlusions or dynamic changes more robustly than single-robot exploration.
Load-bearing premise
Monocular RGB observations combined with multi-view fusion can produce metric 3D geometry and object relations accurate enough for reliable scene-graph construction and viewpoint selection.
What would settle it
A direct comparison on Replica where the RGB-only method shows clearly lower F1 scores than depth-based baselines, or an active exploration run on ReplicaCAD where semantic selection finds no more objects than the geometric baseline.
Figures

read the original abstract
Current approaches to 3D scene graph generation rely on dedicated depth sensors, such as LiDAR or RGB-D cameras, for metric 3D reconstruction. This limits deployment to specialized robotic platforms and excludes settings where only RGB cameras are available, such as fixed external infrastructure. Existing pipelines also typically operate on passively collected observation trajectories, rather than selecting viewpoints based on the partially built scene representation, and therefore fail to effectively exploit the semantic and spatial information encoded within the graph during exploration. This paper presents a fully visual framework for the active, incremental construction of 3D scene graphs from RGB input only, addressing both limitations. The proposed approach unifies perception and planning around a shared structured representation that captures object semantics, 3D geometry, relational context, and information from multiple viewpoints. Because the framework is hardware-agnostic and relies only on RGB observations, it can incorporate inputs from both onboard robot cameras and fixed external cameras within the same representation. Experiments on the Replica dataset show that the RGB-only pipeline achieves F1-score parity with baselines using ground-truth depth. Active exploration experiments on ReplicaCAD further show that semantic-driven viewpoint selection detects more than twice as many objects as a geometric frontier-based baseline under the same exploration budget. Finally, the external-camera setting demonstrates that complementary RGB views can effectively bootstrap the scene graph and improve contextual understanding at no additional exploration cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a fully visual, RGB-only framework for active incremental 3D scene graph generation in indoor environments. It unifies perception and planning in a shared representation capturing object semantics, metric 3D geometry, and relations from multi-view RGB observations. On Replica, the RGB-only pipeline reports F1-score parity with ground-truth depth baselines; on ReplicaCAD, semantic-driven viewpoint selection detects more than twice as many objects as a geometric frontier baseline under fixed exploration budget. The method also demonstrates benefits from complementary external RGB views.
Significance. If the empirical claims hold under rigorous validation, the work would enable 3D scene graph construction on RGB-only platforms, broadening applicability beyond specialized depth-equipped robots. The unification of perception and planning around the scene graph and the demonstration of semantic active selection are strengths that could improve exploration efficiency. The hardware-agnostic design supporting external cameras adds practical value.
major comments (3)
- [§4.1, Table 2] §4.1 and Table 2: F1-score parity with GT-depth baselines is reported as single scalar values without error bars, number of runs, or statistical tests. This directly affects the load-bearing claim that monocular multi-view fusion produces sufficiently accurate metric geometry and relations.
- [§3.2] §3.2 (Multi-view Fusion subsection): No explicit mechanism is described for resolving monocular scale ambiguity or preventing drift in low-texture regions when recovering object positions, scales, and relations. This is central to whether the RGB-only graph can support both reliable scene-graph construction and semantically informed viewpoint selection.
- [§5.2] §5.2 (Active Exploration): The 'more than twice as many objects' result and the definition of exploration budget are presented without ablations on how semantic selection depends on the accuracy of the underlying 3D graph or sensitivity to fusion errors.
minor comments (2)
- [Figure 3, §4.3] Figure 3 caption and §4.3: Dataset statistics (number of scenes, average trajectory length, object density) are not reported, making it hard to interpret the quantitative results.
- [§3.1] Notation in §3.1: The distinction between 'object nodes' and 'relation edges' in the graph update equations is introduced without a clear legend or example, reducing readability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and for the detailed major comments that help improve the manuscript. We respond to each comment below, outlining the revisions we intend to make.
read point-by-point responses
-
Referee: [§4.1, Table 2] §4.1 and Table 2: F1-score parity with GT-depth baselines is reported as single scalar values without error bars, number of runs, or statistical tests. This directly affects the load-bearing claim that monocular multi-view fusion produces sufficiently accurate metric geometry and relations.
Authors: We agree that reporting single scalar values limits the robustness of the parity claim. In the revised manuscript we will rerun the Replica experiments over 10 independent trials with varied random seeds, report mean F1-scores with standard deviations and error bars in Table 2, and include a paired statistical test confirming that the RGB-only and GT-depth results are not significantly different. These additions will appear in §4.1. revision: yes
-
Referee: [§3.2] §3.2 (Multi-view Fusion subsection): No explicit mechanism is described for resolving monocular scale ambiguity or preventing drift in low-texture regions when recovering object positions, scales, and relations. This is central to whether the RGB-only graph can support both reliable scene-graph construction and semantically informed viewpoint selection.
Authors: The referee correctly notes the absence of an explicit description. Our multi-view fusion recovers metric scale by enforcing consistency of object detections across views together with relational constraints encoded in the scene graph; drift in low-texture areas is limited by incremental graph optimization that prioritizes high-confidence object nodes. We will expand §3.2 with a new paragraph that formally states these mechanisms, including the scale-prior term in the optimization objective and the incremental update rule used to bound drift. revision: yes
-
Referee: [§5.2] §5.2 (Active Exploration): The 'more than twice as many objects' result and the definition of exploration budget are presented without ablations on how semantic selection depends on the accuracy of the underlying 3D graph or sensitivity to fusion errors.
Authors: We agree that sensitivity analysis would strengthen the result. The exploration budget is defined as a fixed number of viewpoint selections, chosen to match the resource limit of the geometric baseline. In the revision we will add a paragraph in §5.2 that discusses how semantic viewpoint selection depends on graph accuracy and qualitatively examines the effect of increased fusion noise on detected object count. A limited quantitative ablation will be included if space and time allow; therefore the revision is partial. revision: partial
Circularity Check
No significant circularity; empirical claims rest on external baselines
full rationale
The paper describes an RGB-only active 3D scene graph pipeline whose central performance claims (F1 parity with GT-depth baselines and doubled object detection under semantic viewpoint selection) are presented as outcomes of experiments on Replica and ReplicaCAD. No equations, derivations, or parameter-fitting steps are shown that reduce these metrics to self-referential definitions or fitted inputs. The framework is described as unifying perception and planning around a shared representation, but the reported results are framed as direct empirical comparisons against independent external baselines rather than predictions derived from the method's own fitted quantities or prior self-citations. The absence of load-bearing self-citation chains, ansatzes smuggled via citation, or uniqueness theorems imported from the authors' own work keeps the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep learning- based scene understanding for autonomous robots: A survey,
J. Ni, Y . Chen, G. Tang, J. Shi, W. Cao, and P. Shi, “Deep learning- based scene understanding for autonomous robots: A survey,”Intelli- gence & Robotics, vol. 3, no. 3, pp. 374–401, 2023
work page 2023
-
[2]
Scene graph generation by iterative message passing,
D. Xu, Y . Zhu, C. B. Choy, and L. Fei-Fei, “Scene graph generation by iterative message passing,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5410–5419
work page 2017
-
[3]
Scene graph generation: A comprehensive survey,
H. Li, G. Zhu, L. Zhang, Y . Jiang, Y . Dang, H. Hou, P. Shen, X. Zhao, S. A. A. Shah, and M. Bennamoun, “Scene graph generation: A comprehensive survey,”Neurocomputing, vol. 566, p. 127052, 2024
work page 2024
-
[4]
A survey on 3d scene graphs: Definition, generation and application,
J. Bae, D. Shin, K. Ko, J. Lee, and U.-H. Kim, “A survey on 3d scene graphs: Definition, generation and application,” inInternational Con- ference on Robot Intelligence Technology and Applications. Springer, 2022, pp. 136–147
work page 2022
-
[5]
SayPlan: Grounding large language models using 3d scene graphs for scalable robot task planning,
K. Rana, J. Haviland, S. Garg, J. Abou-Chakra, I. Reid, and N. Suenderhauf, “Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning,”arXiv preprint arXiv:2307.06135, 2023
-
[6]
Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation,
A. Werby, C. Huang, M. B ¨uchner, A. Valada, and W. Burgard, “Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation,” inFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024, 2024
work page 2024
-
[7]
Roboexp: Action-conditioned scene graph via interactive ex- ploration for robotic manipulation,
H. Jiang, B. Huang, R. Wu, Z. Li, S. Garg, H. Nayyeri, S. Wang, and Y . Li, “Roboexp: Action-conditioned scene graph via interactive ex- ploration for robotic manipulation,”arXiv preprint arXiv:2402.15487, 2024
-
[8]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappaet al., “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 5021–5028
work page 2024
- [9]
-
[10]
Scenegraph- fusion: Incremental 3d scene graph prediction from rgb-d sequences,
S.-C. Wu, J. Wald, K. Tateno, N. Navab, and F. Tombari, “Scenegraph- fusion: Incremental 3d scene graph prediction from rgb-d sequences,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7515–7525
work page 2021
-
[11]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
N. Keetha, N. M ¨uller, J. Sch ¨onberger, L. Porzi, Y . Zhang, T. Fischer, A. Knapitsch, D. Zauss, E. Weber, N. Antuneset al., “Mapany- thing: Universal feed-forward metric 3d reconstruction,”arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
H. Tang and P. Chaudhari, “Active semantic perception,”arXiv preprint arXiv:2510.05430, 2025
-
[13]
3d scene graphs in robotics: A unified represen- tation bridging geometry, semantics, and action,
I. Catalano, C. C. Zumaya, J. A. Placed, J. Civera, W. M. Bessa, and J. Pe ˜na-Queralta, “3d scene graphs in robotics: A unified represen- tation bridging geometry, semantics, and action,”Authorea Preprints, 2025
work page 2025
-
[14]
Embodied semantic scene graph generation,
X. Li, D. Guo, H. Liu, and F. Sun, “Embodied semantic scene graph generation,” inConference on robot learning. PMLR, 2022, pp. 1585–1594
work page 2022
-
[15]
Revisiting active per- ception,
R. Bajcsy, Y . Aloimonos, and J. K. Tsotsos, “Revisiting active per- ception,”Autonomous Robots, vol. 42, no. 2, pp. 177–196, 2018
work page 2018
-
[16]
A frontier-based approach for autonomous exploration,
B. Yamauchi, “A frontier-based approach for autonomous exploration,” inProceedings 1997 IEEE International Symposium on Computational Intelligence in Robotics and Automation CIRA’97. ’Towards New Com- putational Principles for Robotics and Automation’. IEEE, 1997, pp. 146–151
work page 1997
-
[17]
The surface edge explorer (see): A measurement-direct approach to next best view planning,
R. Border and J. D. Gammell, “The surface edge explorer (see): A measurement-direct approach to next best view planning,”The International Journal of Robotics Research, vol. 43, no. 10, pp. 1506– 1532, 2024
work page 2024
-
[18]
Sea: Semantic map prediction for active exploration of uncertain areas,
H. Ding, X. Liang, Y . Fang, Y . Wu, J. Shi, J. Huo, W. Li, J. Wu, Y .-K. Lai, and Y . Gao, “Sea: Semantic map prediction for active exploration of uncertain areas,”arXiv preprint arXiv:2510.19766, 2025
-
[19]
Understanding while exploring: Semantics-driven active mapping,
L. Chen, H. Zhan, H. Yin, Y . Xu, and P. Mordohai, “Understanding while exploring: Semantics-driven active mapping,”arXiv preprint arXiv:2506.00225, 2025
-
[20]
Robot-relay: Building-wide, calibration-less visual servoing with learned sensor handover networks,
L. Robinson, M. Gadd, P. Newman, and D. D. Martini, “Robot-relay: Building-wide, calibration-less visual servoing with learned sensor handover networks,”Autonomous Robots, vol. 50, no. 1, p. 3, 2026
work page 2026
-
[21]
Select2plan: Training-free icl-based planning through vqa and memory retrieval,
D. Buoso, L. Robinson, G. Averta, P. Torr, T. Franzmeyer, and D. De Martini, “Select2plan: Training-free icl-based planning through vqa and memory retrieval,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[22]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
work page 2023
-
[23]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[24]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th in- ternational joint conference on natural language processing (EMNLP- IJCNLP), 2019, pp. 3982–3992
work page 2019
-
[25]
The Replica Dataset: A Digital Replica of Indoor Spaces
J. Straub, T. Whelan, L. Ma, Y . Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Vermaet al., “The replica dataset: A digital replica of indoor spaces,”arXiv preprint arXiv:1906.05797, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[26]
Habitat: A platform for embodied ai research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Maliket al., “Habitat: A platform for embodied ai research,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9339–9347
work page 2019
-
[27]
Habitat 2.0: Training home assistants to rearrange their habitat,
A. Szot, A. Clegg, E. Undersander, E. Wijmans, Y . Zhao, J. Turner, N. Maestre, M. Mukadam, D. S. Chaplot, O. Maksymetset al., “Habitat 2.0: Training home assistants to rearrange their habitat,” Advances in neural information processing systems, vol. 34, pp. 251– 266, 2021
work page 2021
-
[28]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gem- ini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.