optimize_anything: A Universal API for Optimizing any Text Parameter
Pith reviewed 2026-05-20 05:38 UTC · model grok-4.3
pith:B5OTAX5L Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{B5OTAX5L}
Prints a linked pith:B5OTAX5L badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
A single LLM-based system for optimizing text artifacts achieves state-of-the-art results across six diverse tasks including agent design and code generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When optimization problems are formulated as improving a text artifact evaluated by a scoring function, a single AI-based optimization system—supporting single-task search, multi-task search with cross-problem transfer, and generalization to unseen inputs—achieves state-of-the-art results across six diverse tasks.
What carries the argument
The optimize_anything API, which casts any parameter optimization as refinement of a text artifact guided by an external scoring function and solved via LLM-driven search.
If this is right
- Actionable side information produces faster convergence and higher final scores than score-only feedback.
- Multi-task search outperforms independent per-task optimization under equal total budget through cross-task transfer.
- Benefits from multi-task search increase as the number of related tasks grows.
- The system generalizes its discovered solutions to inputs not seen during optimization.
- The same framework discovers agent architectures, scheduling policies, CUDA kernels, and geometric packings without task-specific redesign.
Where Pith is reading between the lines
- The results suggest that representing candidate solutions as editable text may let LLMs serve as universal black-box optimizers across additional domains such as materials design or financial strategies.
- If cross-task transfer continues to scale, future versions could maintain a shared library of successful text patterns that accelerate optimization on entirely new problems.
- A practical test would measure how much the performance edge shrinks when the scoring functions are replaced by noisier or more expensive real-world evaluators.
Load-bearing premise
The scoring functions supplied for each task serve as reliable proxies for real performance that need no further domain-specific engineering to deliver the reported gains.
What would settle it
Applying the system to a new task outside the original six where it fails to match or exceed the best existing specialized method on that task would falsify the universality claim.
Figures







read the original abstract
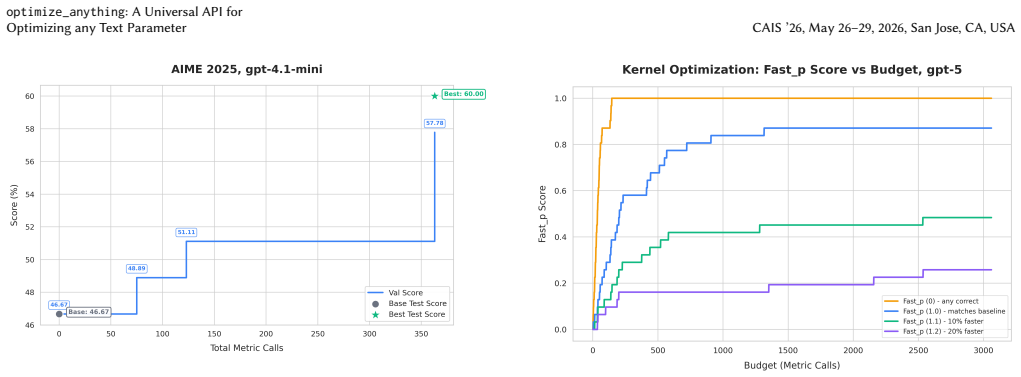
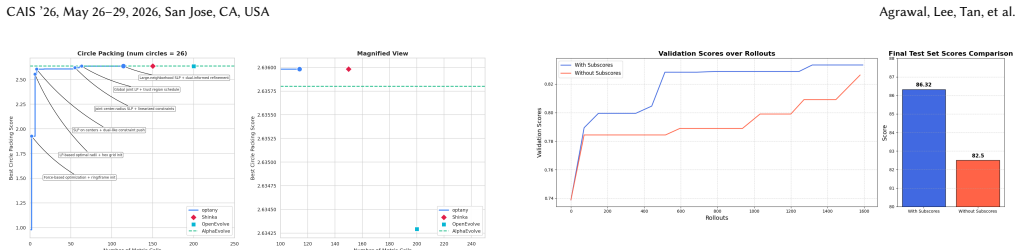
Can a single LLM-based optimization system match specialized tools across fundamentally different domains? We show that when optimization problems are formulated as improving a text artifact evaluated by a scoring function, a single AI-based optimization system-supporting single-task search, multi-task search with cross-problem transfer, and generalization to unseen inputs-achieves state-of-the-art results across six diverse tasks. Our system discovers agent architectures that nearly triple Gemini Flash's ARC-AGI accuracy (32.5% to 89.5%), finds scheduling algorithms that cut cloud costs by 40%, generates CUDA kernels where 87% match or beat PyTorch, and outperforms AlphaEvolve's reported circle packing solution (n=26). Ablations across three domains reveal that actionable side information yields faster convergence and substantially higher final scores than score-only feedback, and that multi-task search outperforms independent optimization given equivalent per-problem budget through cross-task transfer, with benefits scaling with the number of related tasks. Together, we show for the first time that text optimization with LLM-based search is a general-purpose problem-solving paradigm, unifying tasks traditionally requiring domain-specific algorithms under a single framework. We open-source optimize\_anything with support for multiple backends as part of the GEPA project at https://github.com/gepa-ai/gepa .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces optimize_anything, a universal API for optimizing any text parameter via an LLM-based system. It claims that formulating optimization problems as improving a text artifact evaluated by a scoring function enables a single system—supporting single-task search, multi-task search with cross-problem transfer, and generalization to unseen inputs—to achieve state-of-the-art results across six diverse tasks. Specific results include nearly tripling Gemini Flash's ARC-AGI accuracy (32.5% to 89.5%), cutting cloud costs by 40% via improved scheduling, generating CUDA kernels where 87% match or beat PyTorch, and outperforming AlphaEvolve on circle packing (n=26). Ablations indicate that actionable side information outperforms score-only feedback and that multi-task search yields benefits through cross-task transfer that scale with the number of related tasks. The system is open-sourced as part of the GEPA project.
Significance. If the results hold after addressing methodological details, the work would be significant as a demonstration that LLM-based text optimization can serve as a general-purpose paradigm unifying tasks traditionally addressed by domain-specific algorithms. The empirical breadth across six tasks, the ablations on side information and multi-task transfer, and the open-source release with multiple backends are strengths that support reproducibility and potential adoption. The approach could reduce the need for specialized tools if the optimizer's contribution can be isolated from task-specific components.
major comments (3)
- [Abstract] Abstract: The central claim that a single system achieves SOTA results across six tasks rests on reported quantitative gains (e.g., ARC-AGI 32.5% to 89.5%, 40% cost reduction, 87% CUDA kernels matching or beating PyTorch). However, the abstract supplies no explicit construction of the scoring functions, no baselines, no statistical tests, and no ablation controls, making it impossible to determine whether these gains are attributable to the optimizer or to unstated properties of the scorers.
- [Methods] Scoring function definitions (Methods section): The universality argument requires that scoring functions serve as minimal, fixed, neutral proxies. If the paper does not demonstrate via sensitivity analysis or comparison to generic accuracy/latency metrics that equivalent gains cannot be obtained without task-specific test suites or reward shaping inside the scorer, then the reported advantage may partly reflect scorer engineering rather than the search procedure itself.
- [Results] Ablations (Results section): The claim that multi-task search outperforms independent optimization 'given equivalent per-problem budget' is load-bearing for the cross-problem transfer result. Without a precise description of how the per-problem budget is defined and allocated in the independent baseline (including total LLM calls or wall-clock time), the comparison cannot be evaluated for fairness.
minor comments (2)
- [Results] The manuscript should include a table summarizing the six tasks, their scoring functions, and the exact baselines used for each SOTA comparison.
- [Ablations] Notation for 'actionable side information' versus 'score-only feedback' should be defined explicitly in the first use to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, clarifying the manuscript's contributions while making targeted revisions to improve transparency and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that a single system achieves SOTA results across six tasks rests on reported quantitative gains (e.g., ARC-AGI 32.5% to 89.5%, 40% cost reduction, 87% CUDA kernels matching or beating PyTorch). However, the abstract supplies no explicit construction of the scoring functions, no baselines, no statistical tests, and no ablation controls, making it impossible to determine whether these gains are attributable to the optimizer or to unstated properties of the scorers.
Authors: We acknowledge that the abstract's brevity limits inclusion of full methodological details. Scoring functions are defined in the Methods section as minimal, task-appropriate metrics (e.g., test-set accuracy for ARC-AGI without additional shaping, measured cost for scheduling). Baselines, statistical comparisons where applicable, and ablations appear in Results. To improve accessibility, we will revise the abstract to briefly note the scoring-function formulation and reference the main text for baselines and controls. The controlled single- vs. multi-task experiments and side-information ablations are designed to isolate the optimizer's contribution from scorer properties. revision: partial
-
Referee: [Methods] Scoring function definitions (Methods section): The universality argument requires that scoring functions serve as minimal, fixed, neutral proxies. If the paper does not demonstrate via sensitivity analysis or comparison to generic accuracy/latency metrics that equivalent gains cannot be obtained without task-specific test suites or reward shaping inside the scorer, then the reported advantage may partly reflect scorer engineering rather than the search procedure itself.
Authors: Scoring functions use standard, fixed metrics without reward shaping: accuracy on held-out ARC-AGI examples, runtime and correctness for CUDA kernels, and direct cost for scheduling. The same optimizer is applied across all tasks, with ablations showing gains from search strategy rather than scorer changes. While a dedicated sensitivity analysis to generic metrics was not present in the original submission, the cross-task transfer results and side-information comparisons provide evidence that the optimizer drives performance. We will add a subsection in Methods explicitly discussing scorer neutrality and comparing against generic metrics where feasible. revision: yes
-
Referee: [Results] Ablations (Results section): The claim that multi-task search outperforms independent optimization 'given equivalent per-problem budget' is load-bearing for the cross-problem transfer result. Without a precise description of how the per-problem budget is defined and allocated in the independent baseline (including total LLM calls or wall-clock time), the comparison cannot be evaluated for fairness.
Authors: The per-problem budget is defined as an equal allocation of total LLM calls (optimization steps) to each task in the independent baseline, with the multi-task setting using the same aggregate budget but allowing information sharing. This is stated in Results, but we agree a more precise specification would strengthen the claim. We will revise the section to include an explicit definition, a budget-allocation table, and pseudocode distinguishing the two regimes, ensuring the comparison accounts for total compute and wall-clock time. revision: yes
Circularity Check
No circularity: empirical results rest on independent experimental outcomes
full rationale
The paper formulates optimization as improving text artifacts under provided scoring functions and reports empirical gains across six tasks (e.g., ARC-AGI accuracy lift, cloud-cost reduction, CUDA kernel performance). No equations, derivations, or self-referential definitions appear. Claims of universality and cross-task transfer are supported by ablations and observed performance rather than reducing by construction to fitted inputs, self-citations, or renamed known results. Scoring functions are treated as external inputs whose quality is an assumption, not a load-bearing derivation step internal to the optimizer. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based iterative text editing guided by scalar scores can discover high-performing solutions across unrelated domains
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
when optimization problems are formulated as improving a text artifact evaluated by a scoring function, a single AI-based optimization system... achieves state-of-the-art results across six diverse tasks
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Side Information as a first-class evaluator contract... SI is the text-optimization analogue of the gradient
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Lakshya A Agrawal. 2025. ARC-AGI Agent Architecture Optimization with GEPAAdapter. https://github.com/gepa-ai/gepa/blob/ebe0cd71/src/gepa/ examples/dspy_full_program_evolution/arc_agi.ipynb. Committed September 1,
work page 2025
-
[2]
Readable version: https://gepa-ai.github.io/gepa/tutorials/arc_agi/
-
[3]
Seshia, Koushik Sen, Dan Klein, Ion Stoica, Joseph E
Lakshya A Agrawal, Donghyun Lee, Shangyin Tan, Wenjie Ma, Karim Elmaaroufi, Rohit Sandadi, Sanjit A. Seshia, Koushik Sen, Dan Klein, Ion Stoica, Joseph E. Gonzalez, Omar Khattab, Alexandros G. Dimakis, and Matei Zaharia. 2026. In- troducing optimize_anything: A Unified Text Optimization API. https://gepa- ai.github.io/gepa/blog/2026/02/18/introducing-opti...
work page 2026
-
[4]
Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. 2026. GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning. InInternational...
work page 2026
-
[5]
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: A Next-generation Hyperparameter Optimization Frame- work. arXiv:1907.10902 [cs.LG] https://arxiv.org/abs/1907.10902
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
Angelica Chen, David Dohan, and David So. 2023. EvoPrompting: Language Mod- els for Code-Level Neural Architecture Search. InAdvances in Neural Information Processing Systems (NeurIPS)
work page 2023
-
[7]
Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Bowen Wang, Alex Krentsel, Tian Xia, Mert Cemri, Jongseok Park, Shuo Yang, Jeff Chen, Lakshya Agrawal, Aditya Desai, Jiarong Xing, Koushik Sen, Matei Zaharia, and Ion Stoica. 2025. Barbarians at the Gate: How AI is Upending Systems Research. arXiv:2510.06189 [cs.AI] https://arxiv.org/abs/2510.06189
-
[8]
François Chollet. 2019. On the Measure of Intelligence.arXiv preprint arXiv:1911.01547(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[9]
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. 2023. Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution. arXiv:2309.16797 [cs.CL] https://arxiv.org/abs/2309.16797
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Shamil I Galiev and Maria S Lisafina. 2013. Linear models for the approximate solution of the problem of packing equal circles into a given domain.European Journal of Operational Research230, 3 (2013), 505–514
work page 2013
-
[11]
Ronald L Graham and Boris D Lubachevsky. 1996. Dense packings of equal disks in an equilateral triangle: from 22 to 34 and beyond.The Electronic Journal of Combinatorics2 (1996)
work page 1996
-
[12]
Shengran Hu, Cong Lu, and Jeff Clune. 2024. Automated Design of Agentic Systems. InarXiv preprint arXiv:2408.08435
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2023. DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines. arXiv:2310.03714 [cs.CL] https://arxiv.org/abs/2310.03714
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. 2025. ShinkaE- volve: Towards Open-Ended And Sample-Efficient Program Evolution. arXiv:2509.19349 [cs.CL] https://arxiv.org/abs/2509.19349
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [15]
-
[16]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al
-
[17]
Self-Refine: Iterative Refinement with Self-Feedback.Advances in Neural Information Processing Systems (NeurIPS)(2023)
work page 2023
-
[18]
Michael McCourt. 2016. Optimization Test Functions. https://github.com/sigopt/ evalset. https://github.com/sigopt/evalset
work page 2016
-
[19]
Jean-Baptiste Mouret and Jeff Clune. 2015. Illuminating search spaces by mapping elites. arXiv:1504.04909 [cs.AI] https://arxiv.org/abs/1504.04909
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
Alexander Novikov, Ngân V ˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. 2025. AlphaEvolve: A coding agent for scientific an...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [21]
-
[22]
KernelBench: Can LLMs Write Efficient GPU Kernels?
Anne Ouyang, Simon Guo, Simran Arora, Alex L. Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. 2025. KernelBench: Can LLMs Write Efficient GPU Kernels? arXiv:2502.10517 [cs.LG] https://arxiv.org/abs/2502.10517
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng
-
[24]
Automatic Prompt Optimization with “Gradient Descent” and Beam Search. InEmpirical Methods in Natural Language Processing (EMNLP)
-
[25]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi
-
[26]
Pawan Kumar, Emilien Dupont, Francisco J
Mathematical discoveries from program search with large language models. Nature625, 7995 (2024), 468–475. doi:10.1038/s41586-023-06924-6
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeek- Math: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300 [cs.CL] https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
2025.OpenEvolve: an open-source evolutionary coding agent
Asankhaya Sharma. 2025.OpenEvolve: an open-source evolutionary coding agent. https://github.com/algorithmicsuperintelligence/openevolve
work page 2025
-
[29]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv:2303.11366 [cs.AI] https://arxiv.org/abs/2303. 11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Shangyin Tan, Lakshya A Agrawal, Rohit Sandadi, Dan Klein, Koushik Sen, Alexandros G. Dimakis, and Matei Zaharia. 2026. Automatically Learning Skills for Coding Agents. https://gepa-ai.github.io/gepa/blog/2026/02/18/automatically- learning-skills-for-coding-agents/. Blog post, February 18, 2026
work page 2026
-
[31]
Large Language Models as Optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. 2024. Large Language Models as Optimizers. arXiv:2309.03409 [cs.LG] https://arxiv.org/abs/2309.03409
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
TextGrad: Automatic "Differentiation" via Text
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. 2024. TextGrad: Automatic "Differentiation" via Text. arXiv:2406.07496 [cs.CL] https://arxiv.org/abs/2406.07496
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. 2025. AFlow: Automating Agentic Workflow Generation. arXiv:2410.10762 [cs.AI] https://arxiv.org/abs/2410.10762
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. 2023. Large Language Models Are Human-Level Prompt Engineers. arXiv:2211.01910 [cs.LG] https://arxiv.org/abs/2211.01910 optimize_anything: A Universal API for Optimizing any Text Parameter CAIS ’26, May 26–29, 2026, San Jose, CA, USA A Use of Generative...
-
[35]
The mechanism: Optuna’s fixed TPE-CMA-ES pipeline fails in predictable, structural ways (e.g., TPE’s per-dimension sampling converges to trap basins; CMA-ES assumes smooth unimodal land- scapes). optimize_anything tailors the solver to each problem— discovering L-BFGS-B for boundary optima and multi-start search for deceptive traps. C Seedless Mode: 3D Un...
work page 2026
-
[36]
Restate the problem briefly in your own words
-
[37]
Set up notation and equations cleanly before manipulating them. - Define variables explicitly. - State all constraints (e.g., integrality, ranges, geometric conditions) before using them
-
[38]
- Justify each important algebraic or geometric step
Show clear, logically ordered reasoning. - Justify each important algebraic or geometric step. - When you split into cases, state why each case is necessary and what assumptions define it. - If you invoke a known theorem (e.g., Ptolemy, Power of a Point, similarity, Vieta), name it and show exactly how it applies in this context
-
[39]
- If you realize a line of reasoning leads to a contradiction or dead end, explicitly say so
Handle dead ends correctly. - If you realize a line of reasoning leads to a contradiction or dead end, explicitly say so. - Then restart from the last correct point; do not guess or hand-wave
-
[40]
- Avoid unnecessary numerical approximations if an exact approach is available
Keep the reasoning focused and minimal while still being rigorous. - Avoid unnecessary numerical approximations if an exact approach is available. - Do not approximate exact values unless the problem explicitly asks for a decimal. - Prefer algebraic or structural arguments over trial-and-error or random guessing. - You may test candidate values only after...
-
[41]
- Do not include any extra words, symbols, or explanation on that final line
At the end, clearly isolate the answer: - Provide the final answer as a single number or expression on its own line. - Do not include any extra words, symbols, or explanation on that final line. J Discovered solutions We present excerpts of the final optimized artifacts discovered by optimize_anythingfor each domain. J.1 Coding Agent Skills: Bleve Reposit...
-
[42]
Run tests early and iterate from failures (tests are the bug report) - Start broad when feasible: ‘cd /testbed && go test ./...‘ (or project equivalent). - Narrow quickly: - package: ‘go test ./path/to/pkg‘ - single test: ‘go test ./path/to/pkg -run TestName -count=1‘ (add -v only if needed) - For panics: follow the stack trace top frame in repo code firs...
work page 2026
-
[43]
Make minimal, reviewable changes and verify continuously - Change one behavior at a time; rerun the smallest reproducing test after each change. - Add focused unit tests when coverage is missing; keep them in the same package and table-driven where sensible (include short words + accented/Unicode edge cases). - Avoid scratch main.go files in repo root. J....
-
[44]
Provider-Aware Weighting: biases path finding towards intra-provider links to minimize egress
-
[45]
Pareto-Frontier Candidate Selection: Explicitly keeps candidates that offer distinct cost/time tradeoffs
-
[46]
Diverse Steiner Strategies: Includes MST-like approximations for cost and bottleneck-widest paths for throughput
-
[47]
""Bilevel L-BFGS with exact LP sensitivities + SLP block boosts + CMA/Evolution fallback
Robust Greedy Allocation: Accurately models bandwidth contention across partitions. """ # --- Constants & Configuration --- EST_DATA_VOL_GB = 300.0 EST_INSTANCE_COST_PER_HR = 10.0 PARTITION_VOL_GB = EST_DATA_VOL_GB /max(1, num_partitions) # Sweep parameters for Cost vs Time tradeoff alphas = [0.0, 1e-5, 0.001, 0.01, 0.05, 0.1, 0.5, 2.0] bw_thresholds = [0...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.