Decoupling Communication from Policy: Robust MARL under Bandwidth Constraints
Pith reviewed 2026-05-21 01:59 UTC · model grok-4.3
The pith
Decoupling the communication pathway from the policy latent space lets multi-agent reinforcement learning maintain performance under tight bandwidth limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
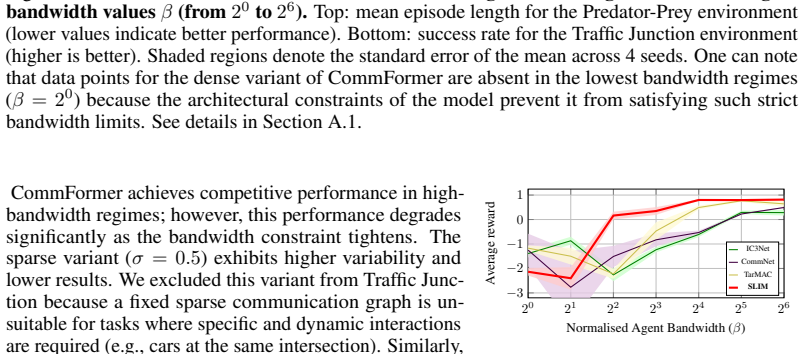
By providing a dedicated communication pathway separate from the policy's latent representation, SLIM isolates the impact of bandwidth constraints from policy capacity, enabling state-of-the-art results on partially observable MARL tasks with only marginal degradation as the bandwidth budget is reduced.
What carries the argument
SLIM, the minimal architecture with a decoupled communication pathway that allows in-step communication without linking message size to policy capacity.
If this is right
- Agents achieve high performance on coordination tasks even when bandwidth is severely limited.
- Reducing bandwidth causes only small drops in results rather than sharp declines.
- The approach scales to larger numbers of agents because policy complexity is independent of communication budget.
- Standard partially observable benchmarks show consistent advantages when communication is essential for success.
Where Pith is reading between the lines
- Similar decoupling ideas could help in other resource-limited multi-agent settings such as computation time or energy use.
- Real-world applications like search-and-rescue might see more reliable coordination if policies do not shrink with message size.
- Further tests could check whether the separation reduces training issues in very large agent groups.
Load-bearing premise
Adding the separate communication pathway does not add enough extra complexity or training problems to erase the performance gains from keeping policy capacity high.
What would settle it
Running the same tasks with a coupled architecture that is given extra parameters to match SLIM's total size but still shows large performance loss at low bandwidth would disprove the isolation benefit.
Figures





read the original abstract
Communication enables coordination in multi-agent reinforcement learning (MARL), but many real-world applications, e.g., search-and-rescue with drone swarms, operate under severe bandwidth constraints. Many communication architectures still expose a coupled bottleneck in which a shared latent representation is used for both policy execution and inter-agent communication. Consequently, reducing message size directly limits the policy's latent space, often leading to significant performance degradation. We address this with two contributions. First, we introduce $\beta$, a normalised per-agent bandwidth budget that unifies sparsity, rounds, and message dimension into a single comparable constraint. Second, we provide SLIM, a minimal architecture that decouples the communication pathway from the policy's latent representation, allowing us to isolate the effect of bandwidth from the effect of policy capacity while benefiting from in-step communication. We evaluate our method on several partially-observable MARL benchmarks, where communication is essential. Our approach achieves state-of-the-art performance and exhibits scalability and robustness under limited communication, with only marginal degradation as bandwidth is reduced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a normalized per-agent bandwidth budget β that unifies sparsity, communication rounds, and message dimension, along with the SLIM architecture that decouples the communication pathway from the policy's latent representation. This design aims to isolate bandwidth constraints from policy capacity while still enabling in-step communication. On partially observable MARL benchmarks where communication is essential, the method is reported to achieve state-of-the-art performance, scalability, and robustness under limited communication, with only marginal degradation as bandwidth is reduced.
Significance. If the central decoupling claim holds under joint training, the work would offer a practical advance for bandwidth-constrained MARL applications such as drone swarms, by allowing message size to vary without directly shrinking the policy latent space. The unification of constraints via β is a clear strength for enabling comparable evaluations across different communication regimes.
major comments (2)
- [SLIM architecture description] The architectural description of SLIM states that it decouples the communication pathway from the policy latent representation at the forward-pass level. However, because both modules are trained jointly via a shared optimizer and the MARL objective, gradients from the communication head can still flow back to policy parameters. This interaction means that changes in β (via sparsity or dimension) can indirectly alter policy capacity even when the forward architecture is fixed, weakening the isolation claim. An ablation measuring policy gradient norms or performance sensitivity to β while holding architecture constant would be needed to substantiate the decoupling.
- [Abstract and experimental evaluation] The abstract asserts SOTA results and only marginal degradation as bandwidth is reduced, yet the provided text supplies no quantitative tables, error bars, specific benchmark names, or ablation details on how β is varied. Without these, the central performance claim cannot be verified against the experimental setup, particularly the assumption that the dedicated communication pathway does not offset gains through added training instability.
minor comments (2)
- [Abstract] The abstract refers to 'several partially-observable MARL benchmarks' without naming them; explicitly listing the environments (e.g., SMAC, MPE variants) would improve reproducibility and context.
- [Introduction or method] Notation for β is introduced as a 'normalised per-agent bandwidth budget,' but the precise normalization formula and how it maps sparsity/rounds/dimension should be stated in an early equation for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comments point by point below, clarifying the nature of the decoupling and the support for our performance claims.
read point-by-point responses
-
Referee: [SLIM architecture description] The architectural description of SLIM states that it decouples the communication pathway from the policy latent representation at the forward-pass level. However, because both modules are trained jointly via a shared optimizer and the MARL objective, gradients from the communication head can still flow back to policy parameters. This interaction means that changes in β (via sparsity or dimension) can indirectly alter policy capacity even when the forward architecture is fixed, weakening the isolation claim. An ablation measuring policy gradient norms or performance sensitivity to β while holding architecture constant would be needed to substantiate the decoupling.
Authors: We acknowledge that joint optimization permits gradients from the communication head to reach policy parameters. Nevertheless, the decoupling is realized at the forward-pass level: the policy computes its latent representation independently of the communication pathway and of the value of β. Consequently, the policy's representational capacity remains fixed by design even as bandwidth constraints are tightened, which is the key distinction from coupled architectures in which message dimension directly reduces the shared latent space. The indirect gradient effect does not change this architectural separation during inference or when comparing models of equal policy size. We will incorporate the recommended ablation that measures policy performance sensitivity to β under a fixed architecture, and we will report policy gradient norms across β values where space allows. revision: yes
-
Referee: [Abstract and experimental evaluation] The abstract asserts SOTA results and only marginal degradation as bandwidth is reduced, yet the provided text supplies no quantitative tables, error bars, specific benchmark names, or ablation details on how β is varied. Without these, the central performance claim cannot be verified against the experimental setup, particularly the assumption that the dedicated communication pathway does not offset gains through added training instability.
Authors: The abstract supplies a concise summary of the main results. The full manuscript presents the supporting quantitative evidence in the Experiments section: tables report mean returns with standard deviations on the partially observable MARL benchmarks, ablations systematically vary β through sparsity, communication rounds, and message dimension, and training curves confirm stable convergence without added instability from the dedicated pathway. These results underpin the reported state-of-the-art performance and the marginal degradation under reduced bandwidth. If the editor and referee consider it useful, we can augment the abstract with explicit numerical highlights drawn from those tables. revision: partial
Circularity Check
No circularity: empirical claims rest on architecture and benchmarks, not self-referential derivations
full rationale
The paper defines a bandwidth budget β and proposes the SLIM architecture to decouple communication from policy latent space, then reports empirical results on MARL benchmarks. No equations, predictions, or first-principles derivations are presented that reduce by construction to fitted inputs, self-citations, or renamed known results. The central claims concern observed performance under varying β, which are externally falsifiable via the stated experimental setup rather than tautological. This is the expected non-finding for an empirical methods paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SLIM ... decouples the communication pathway from the policy's latent representation, allowing us to isolate the effect of bandwidth from the effect of policy capacity
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
normalised per-agent bandwidth budget β ... σ×k×d≤β
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Dan Klein. Neural module networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 39–48, 2016
work page 2016
-
[2]
Matteo Bettini, Ryan Kortvelesy, Jan Blumenkamp, and Amanda Prorok. Vmas: A vectorized multi-agent simulator for collective robot learning.The 16th International Symposium on Distributed Autonomous Robotic Systems, 2022
work page 2022
-
[3]
Caroline Claus and Craig Boutilier. The dynamics of reinforcement learning in cooperative multiagent systems.AAAI/IAAI, 1998(746-752):2, 1998
work page 1998
-
[4]
Tarmac: Targeted multi-agent communication
Abhishek Das, Théophile Gervet, Joshua Romoff, Dhruv Batra, Devi Parikh, Mike Rabbat, and Joelle Pineau. Tarmac: Targeted multi-agent communication. InInternational Conference on Machine Learning, pages 1538–1546. PMLR, 2019
work page 2019
-
[5]
Shifei Ding, Wei Du, Ling Ding, Jian Zhang, Lili Guo, and Bo An. Robust multi-agent communication with graph information bottleneck optimization.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3096–3107, 2023
work page 2023
-
[6]
Ziluo Ding, Tiejun Huang, and Zongqing Lu. Learning individually inferred communication for multi-agent cooperation.Advances in neural information processing systems, 33:22069–22079, 2020
work page 2020
-
[7]
Jakob Foerster, Ioannis Alexandros Assael, Nando De Freitas, and Shimon Whiteson. Learning to communicate with deep multi-agent reinforcement learning.Advances in neural information processing systems, 29, 2016
work page 2016
-
[8]
Counterfactual multi-agent policy gradients
Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[9]
Ziyang Guo, Zhenyu Chen, Peng Liu, Jianjun Luo, Xun Yang, and Xinghua Sun. Multi-agent reinforcement learning-based distributed channel access for next generation wireless networks. IEEE Journal on Selected Areas in Communications, 40(5):1587–1599, 2022
work page 2022
-
[10]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
work page 2018
-
[11]
Model-based sparse communication in multi- agent reinforcement learning
Shuai Han, Mehdi Dastani, and Shihan Wang. Model-based sparse communication in multi- agent reinforcement learning. InProceedings of the 2023 international conference on au- tonomous agents and multiagent systems, pages 439–447. International Foundation for Au- tonomous Agents and Multiagent Systems (IFAAMAS), 2023
work page 2023
-
[12]
Guangzheng Hu, Yuanheng Zhu, Dongbin Zhao, Mengchen Zhao, and Jianye Hao. Event- triggered communication network with limited-bandwidth constraint for multi-agent reinforce- ment learning.IEEE Transactions on Neural Networks and Learning Systems, 34(8):3966–3978, 2021. 10
work page 2021
-
[13]
Learning multi-agent communication from graph modeling perspective
Shengchao Hu, Li Shen, Ya Zhang, and Dacheng Tao. Learning multi-agent communication from graph modeling perspective. InInternational Conference on Learning Representations, 2024
work page 2024
-
[14]
Graph convolutional reinforcement learning
Jiechuan Jiang, Chen Dun, Tiejun Huang, and Zongqing Lu. Graph convolutional reinforcement learning. 2020
work page 2020
-
[15]
Jiechuan Jiang and Zongqing Lu. Learning attentional communication for multi-agent coopera- tion.Advances in neural information processing systems, 31, 2018
work page 2018
-
[16]
Rui Jiang, Xuetao Zhang, Yisha Liu, Yi Xu, Xuebo Zhang, and Yan Zhuang. Multi-agent cooperative strategy with explicit teammate modeling and targeted informative communication. Neurocomput., 586(C), June 2024
work page 2024
-
[17]
Rui Jiang, Xuetao Zhang, Yisha Liu, Yi Xu, Xuebo Zhang, and Yan Zhuang. Multi-agent cooperative strategy with explicit teammate modeling and targeted informative communication. Neurocomputing, 586:127638, 2024
work page 2024
-
[18]
Learning to schedule communication in multi-agent reinforcement learning
Daewoo Kim, Sangwoo Moon, David Hostallero, Wan Ju Kang, Taeyoung Lee, Kyunghwan Son, and Yung Yi. Learning to schedule communication in multi-agent reinforcement learning. InInternational Conference on Learning Representations, 2019
work page 2019
-
[19]
Trust region policy optimisation in multi-agent reinforcement learning
Jakub Grudzien Kuba, Ruiqing Chen, Muning Wen, Ying Wen, Fanglei Sun, Jun Wang, and Yaodong Yang. Trust region policy optimisation in multi-agent reinforcement learning. In International Conference on Learning Representations, 2022
work page 2022
-
[20]
Multi-agent cooperation and the emergence of (natural) language
Angeliki Lazaridou, Alexander Peysakhovich, and Marco Baroni. Multi-agent cooperation and the emergence of (natural) language. InInternational Conference on Learning Representations, 2017
work page 2017
-
[21]
Deep implicit coordination graphs for multi-agent reinforcement learning
Sheng Li, Jayesh K Gupta, Peter Morales, Ross Allen, and Mykel J Kochenderfer. Deep implicit coordination graphs for multi-agent reinforcement learning. InProceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, pages 764–772, 2021
work page 2021
-
[22]
Context-aware communication for multi-agent reinforcement learning
Xinran Li and Jun Zhang. Context-aware communication for multi-agent reinforcement learning. InProceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, pages 1156–1164, 2024
work page 2024
-
[23]
Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments.Advances in neural information processing systems, 30, 2017
work page 2017
-
[24]
Learning agent communication under limited bandwidth by message pruning
Hangyu Mao, Zhengchao Zhang, Zhen Xiao, Zhibo Gong, and Yan Ni. Learning agent communication under limited bandwidth by message pruning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5142–5149, 2020
work page 2020
-
[25]
Laetitia Matignon, Guillaume J Laurent, and Nadine Le Fort-Piat. Independent reinforce- ment learners in cooperative markov games: a survey regarding coordination problems.The Knowledge Engineering Review, 27(1):1–31, 2012
work page 2012
-
[26]
Emergence of grounded compositional language in multi- agent populations
Igor Mordatch and Pieter Abbeel. Emergence of grounded compositional language in multi- agent populations. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[27]
Frans A Oliehoek, Christopher Amato, et al.A concise introduction to decentralized POMDPs, volume 1. Springer, 2016
work page 2016
-
[28]
Murtaza Rangwala and Ryan Williams. Learning multi-agent communication through structured attentive reasoning.Advances in Neural Information Processing Systems, 33:10088–10098, 2020
work page 2020
-
[29]
Theodore S Rappaport.Wireless communications: Principles and practice, 2/E. Pearson Education India, 2010. 11
work page 2010
-
[30]
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning.Journal of Machine Learning Research, 21(178):1–51, 2020
work page 2020
-
[31]
High- dimensional continuous control using generalized advantage estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation. InInternational Conference on Learning Representations, 2016
work page 2016
-
[32]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Learning efficient diverse communication for cooperative heterogeneous teaming
Esmaeil Seraj, Zheyuan Wang, Rohan Paleja, Daniel Martin, Matthew Sklar, Anirudh Patel, and Matthew Gombolay. Learning efficient diverse communication for cooperative heterogeneous teaming. InProceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, pages 1173–1182, 2022
work page 2022
-
[34]
A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
Claude E Shannon. A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
work page 1948
-
[35]
Learning when to communicate at scale in multiagent cooperative and competitive tasks
Amanpreet Singh, Tushar Jain, and Sainbayar Sukhbaatar. Learning when to communicate at scale in multiagent cooperative and competitive tasks. InInternational Conference on Learning Representations, 2019
work page 2019
-
[36]
Goal-oriented semantic communication in bandwidth- constrained marl
Yang Su, Yali Du, and Yansha Deng. Goal-oriented semantic communication in bandwidth- constrained marl. In2025 IEEE International Conference on Communications Workshops (ICC Workshops), pages 1274–1279. IEEE, 2025
work page 2025
-
[37]
Sainbayar Sukhbaatar, Rob Fergus, et al. Learning multiagent communication with backpropa- gation.Advances in neural information processing systems, 29, 2016
work page 2016
-
[38]
Qingshuang Sun, Denis Steckelmacher, Yuan Yao, Ann Nowe, and Raphael Avalos. Dynamic size message scheduling for multi-agent communication under limited bandwidth.IEEE Transactions on Mobile Computing, 2024
work page 2024
-
[39]
Multi-agent reinforcement learning: Independent vs
Ming Tan. Multi-agent reinforcement learning: Independent vs. cooperative agents. InProceed- ings of the tenth international conference on Machine Learning, pages 330–337, 1993
work page 1993
-
[40]
Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Jun- young Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning.nature, 575(7782):350–354, 2019
work page 2019
-
[41]
Learning efficient multi-agent communication: An information bottleneck approach
Rundong Wang, Xu He, Runsheng Yu, Wei Qiu, Bo An, and Zinovi Rabinovich. Learning efficient multi-agent communication: An information bottleneck approach. In Hal Daumé III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 9908–9918. PMLR, 13–18 Jul 2020
work page 2020
-
[42]
Learning nearly de- composable value functions via communication minimization
Tonghan Wang, Jianhao Wang, Chongyi Zheng, and Chongjie Zhang. Learning nearly de- composable value functions via communication minimization. InInternational Conference on Learning Representations, 2020
work page 2020
-
[43]
Yuanfei Wang, Fangwei Zhong, Jing Xu, and Yizhou Wang. Tom2c: Target-oriented multi-agent communication and cooperation with theory of mind.arXiv preprint arXiv:2111.09189, 2021
-
[44]
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games.Advances in neural information processing systems, 35:24611–24624, 2022
work page 2022
-
[45]
Lebin Yu, Qiexiang Wang, Yunbo Qiu, Jian Wang, Xudong Zhang, and Zhu Han. Effective multi-agent communication under limited bandwidth.IEEE Transactions on Mobile Computing, 23(7):7771–7784, 2024
work page 2024
-
[46]
Understanding deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization.arXiv preprint arXiv:1611.03530, 2016. 12
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[47]
Sai Qian Zhang, Qi Zhang, and Jieyu Lin. Efficient communication in multi-agent reinforcement learning via variance based control.Advances in neural information processing systems, 32, 2019. 13 A Experiment Details Table 2:Hyperparameter configuration for the SLIM architecture across all benchmarks.These values were optimised using a fixed message dimensi...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.