Tackle CSM in JPEG Steganalysis with Data Adaptation
Pith reviewed 2026-05-22 02:00 UTC · model grok-4.3
The pith
TADA learns to emulate unknown processing pipelines from small unlabeled sets to reduce cover source mismatch in JPEG steganalysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training an emulator on a small unlabeled target set to align residual covariances, match residual distributions, and satisfy an L2 realism constraint, TADA reproduces the effects of an unknown processing pipeline on image residuals, allowing steganalysis models to operate effectively despite cover source mismatch.
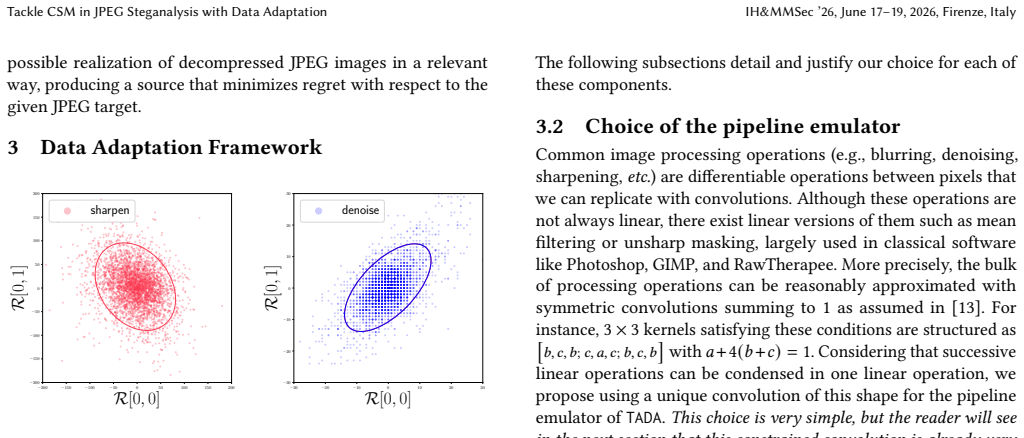
What carries the argument
The TADA emulator network, which transforms images so their residuals match the target's statistics via covariance alignment, distribution matching, and L2 loss.
If this is right
- Steganalysis detectors gain substantial robustness to cover source mismatch after TADA adaptation.
- Operational generalization improves relative to both holistic and atomistic baseline methods.
- The approach succeeds across controlled toy targets and realistic operational targets.
- Adaptation works without knowledge of the cover-stego ratio in the target set.
Where Pith is reading between the lines
- The same emulation strategy could be tested on other forensic tasks that face processing-pipeline shifts.
- If the emulator proves faithful, it might lower the volume of labeled target data needed for reliable deployment.
- Combining TADA with existing domain-adaptation layers could produce further gains in mismatched settings.
- Direct measurement of how closely emulated residuals match real target residuals would confirm the alignment mechanism.
Load-bearing premise
A small unlabeled target set contains enough information for the emulator to accurately reproduce the unknown processing pipeline's effects on residuals.
What would settle it
Applying the trained emulator to source images and finding that the resulting residual covariances and distributions remain closer to the original source than to the actual target set, with no corresponding improvement in steganalysis accuracy on the target.
Figures

read the original abstract
Steganalysis models excel on benchmark datasets but struggle in the wild when analyzed images are produced by a processing pipeline unseen during training. This problem known as Cover Source Mismatch (CSM) is particularly hard in realistic settings where practitioners (1) have access to only a small, unlabeled dataset, (2) are unsure of the processing techniques applied to these images, and (3) lack information on the proportion of covers and stegos in that set. To answer this challenge, we introduce TADA (Target Alignment through Data Adaptation), a framework learning to emulate the unknown processing pipeline from a small unlabeled target set. This architecture is trained with a loss combining residual covariance alignment, residual distribution matching, and a $\ell^2$ loss constraining the emulator to produce realistic images. Across toy and operational targets, TADA yields substantial gains in robustness to CSM and improves operational generalization compared to strong holistic and atomistic baselines. Additional resources are available at this link: https://github.com/RonyAbecidan/TADA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TADA (Target Alignment through Data Adaptation), a framework to mitigate Cover Source Mismatch (CSM) in JPEG steganalysis. It trains an emulator network on a small unlabeled target set to reproduce the effects of an unknown processing pipeline, using a joint loss of residual covariance alignment, residual distribution matching, and an ℓ² realism constraint. Experiments on toy and operational targets are reported to show substantial gains in robustness to CSM and improved operational generalization relative to strong holistic and atomistic baselines.
Significance. If the central claims hold under rigorous validation, the work could meaningfully advance practical steganalysis by offering a data-adaptation route that requires neither labeled target samples nor explicit knowledge of the pipeline or cover/stego mix. The combination of covariance, distribution, and realism losses for emulation is a concrete technical contribution, and the public GitHub repository supports reproducibility.
major comments (2)
- [Abstract] Abstract: the claim of 'substantial gains' on toy and operational targets is presented without any numerical results, error bars, dataset sizes, or ablation studies, so the magnitude and reliability of the reported improvements over baselines cannot be assessed from the provided text.
- [Method] Method (emulator training): the central claim requires that the small unlabeled target set, combined with the joint loss, suffices to recover an emulator that accurately reproduces the unknown pipeline's effect on residuals; no evidence is given that this assumption was tested by varying target-set size or by checking whether the loss admits multiple plausible emulators.
minor comments (1)
- [Abstract] The GitHub link is mentioned but its contents (code, datasets, or trained models) are not described in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential impact. We address each major comment below and indicate the revisions made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'substantial gains' on toy and operational targets is presented without any numerical results, error bars, dataset sizes, or ablation studies, so the magnitude and reliability of the reported improvements over baselines cannot be assessed from the provided text.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to gauge the improvements immediately. In the revised version, we have updated the abstract to reference the scale of the gains (while remaining within length limits), the sizes of the target sets employed, and the presence of error bars and ablations in the experimental results. The detailed numerical comparisons, standard deviations across runs, and ablation tables remain in Section 4 and the associated figures/tables. revision: yes
-
Referee: [Method] Method (emulator training): the central claim requires that the small unlabeled target set, combined with the joint loss, suffices to recover an emulator that accurately reproduces the unknown pipeline's effect on residuals; no evidence is given that this assumption was tested by varying target-set size or by checking whether the loss admits multiple plausible emulators.
Authors: We acknowledge the value of explicit sensitivity analysis for target-set size and potential non-uniqueness of the emulator. The original experiments already demonstrate successful emulation on small unlabeled sets for both toy and operational pipelines, with the joint loss (covariance alignment + distribution matching + ℓ² realism) providing strong constraints. We have added new experiments that vary target-set size and include a discussion of loss-component contributions to reduce ambiguity among plausible emulators; these results and the accompanying analysis appear in the revised Method and Experiments sections. revision: partial
Circularity Check
No significant circularity in TADA derivation chain
full rationale
The paper introduces TADA as a new data-adaptation framework that trains an emulator on a small unlabeled target set using a composite loss of residual covariance alignment, distribution matching, and ℓ² realism. This construction relies on external target data and standard alignment objectives rather than reducing any central claim to fitted parameters, self-definitions, or self-citation chains. The robustness gains are presented as empirical outcomes of applying the emulator to unseen pipelines, with no equations or steps shown to be equivalent to inputs by construction. The method remains self-contained against external benchmarks and does not invoke uniqueness theorems or prior author results as load-bearing justifications for the core adaptation mechanism.
Axiom & Free-Parameter Ledger
free parameters (1)
- loss term weights
axioms (1)
- domain assumption Small unlabeled target dataset suffices to emulate unknown processing pipeline effects on image residuals
invented entities (1)
-
TADA emulator network
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TADA training loss: λ∥Cov(E(S))−Cov(E(T))∥²_F + μ d(E(S),E(T)) + γ ℓ²(STIF,STADA)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
residual covariance alignment and distribution matching on KB-filtered patches
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rony Abecidan et al. 2022. Using Set Covering to Generate Databases for Holistic Steganalysis. In 2022 IEEE International Workshop on Information Forensics and Security (WIFS). 1–6. doi:10.1109/WIFS55849.2022.9975430
-
[2]
Rony Abecidan et al . 2023. Leveraging Data Geometry to Mitigate CSM in Steganalysis. In IEEE International Workshop on Information Forensics and Security (WIFS 2023). Nuremberg, Germany
work page 2023
-
[3]
Break Our Steganographic System
Patrick Bas, Tomas Filler, and Tomas Pevny. 2011. “Break Our Steganographic System”: The Ins and Outs of Organizing BOSS. InInformation Hiding (Lecture Notes in Computer Science, Vol. 6958) . 59–70. doi:10.1007/978-3-642-24178-9_15
-
[4]
Rémi Cogranne, Eva Giboulot, and Patrick Bas. 2020. ALASKA-2: Challenging Academic Research on Steganalysis with Realistic Images. In IEEE International Workshop on Information Forensics and Security . New York City (Virtual Confer- ence), United States. doi:10.1109/WIFS49906.2020.9360896
-
[5]
Max Ehrlich, Larry Davis, Ser-Nam Lim, and Abhinav Shrivastava. 2020. Quanti- zation Guided JPEG Artifact Correction. InComputer Vision – ECCV 2020 (Lecture Notes in Computer Science, Vol. 12353) . Springer, Cham, 293–309. doi:10.1007/978- 3-030-58598-3_18
-
[6]
Jean Feydy. 2020. Geometric data analysis, beyond convolutions. Applied Mathe- matics (2020)
work page 2020
-
[7]
Alessandro Foi, Mejdi Trimeche, Vladimir Katkovnik, and Karen Egiazarian
-
[8]
IEEE TIP17(10), 1737–1754 (2008).https://doi.org/10.1109/TIP.2008.2001399
Practical Poissonian-Gaussian Noise Modeling and Fitting for Single- Image Raw-Data. IEEE Transactions on Image Processing 17, 10 (2008), 1737–1754. doi:10.1109/TIP.2008.2001399
-
[9]
Jessica Fridrich, Tomáš Pevn`y, and Jan Kodovsk`y. 2007. Statistically undetectable jpeg steganography: dead ends challenges, and opportunities. In Proceedings of the 9th workshop on Multimedia & security . 3–14
work page 2007
-
[10]
Eva Giboulot, Rémi Cogranne, Dirk Borghys, and Patrick Bas. 2020. Effects and solutions of Cover-Source Mismatch in image steganalysis. Signal Process. Image Commun. 86 (2020), 115888
work page 2020
-
[11]
Quentin Giboulot, Rémi Cogranne, and Patrick Bas. 2021. Detectability-based JPEG steganography modeling the processing pipeline: the noise-content trade- off. IEEE Transactions on Information Forensics and Security 16 (2021), 2202–2217. doi:10.1109/TIFS.2021.3050063
-
[12]
Linjie Guo et al. 2015. Using Statistical Image Model for JPEG Steganography: Uniform Embedding Revisited. IEEE Transactions on Information Forensics and Security 10, 12 (2015), 2669–2680. doi:10.1109/TIFS.2015.2473815
-
[13]
Vojtech Holub and Jessica Fridrich. 2015. Low-Complexity Features for JPEG Steganalysis Using Undecimated DCT. IEEE Transactions on Information Forensics and Security 10, 2 (2015), 219–228. doi:10.1109/TIFS.2014.2364918
-
[14]
Eric Kee and Hany Farid. 2010. Digital image authentication from thumbnails. In Electronic Imaging
work page 2010
-
[15]
Andrew D. Ker and Rainer Böhme. 2008. Revisiting weighted stego-image ste- ganalysis. In Security, Forensics, Steganography, and Watermarking of Multimedia Contents X (Proceedings of SPIE, Vol. 6819) . 681905. doi:10.1117/12.766820
-
[16]
Antoine Mallet, Patrick Bas, and Rémi Cogranne. 2024. Statistical Correlation as a Forensic Feature to Mitigate the Cover-Source Mismatch. In 12th ACM Workshop on Information Hiding and Multimedia Security (IH&MMSEC’24). Baiona, Spain. doi:10.1145/3658664.3659638
-
[17]
Antoine Mallet, Martin Beneš, and Rémi Cogranne. 2024. Cover-source mismatch in steganalysis: systematic review. EURASIP Journal on Information Security 2024, 1 (2024), 26. doi:10.1186/s13635-024-00171-6
-
[18]
E. Martinec and P. Lee. 2010. AMAZE demosaicing algorithm. http://www. rawtherapee.com/
work page 2010
-
[19]
Phil Sallee. 2003. Model-based steganography. In International Workshop on Digital Watermarking. Springer, 154–167
work page 2003
-
[20]
Dominik Šepák, Lukáš Adam, and Tomáš Pevný. 2022. Formalizing cover-source mismatch as a robust optimization. In European Signal Processing Conference (EUSIPCO). Belgrade, Serbia
work page 2022
-
[21]
Théo Taburet, Patrick Bas, Wadih Sawaya, and Jessica Fridrich. 2020. Natu- ral steganography in JPEG domain with a linear development pipeline. IEEE Transactions on Information Forensics and Security 16 (2020), 173–186
work page 2020
-
[22]
Bart Thomee et al . 2015. The New Data and New Challenges in Multimedia Research. CoRR abs/1503.01817 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.