Detecting Synthetic Political Narratives in Cross-Platform Social Media Discourse
Pith reviewed 2026-05-22 01:26 UTC · model grok-4.3
The pith
Combining lexical diversity, burstiness, repetition and homogenization into one score detects synthetic political narratives more robustly than any single metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
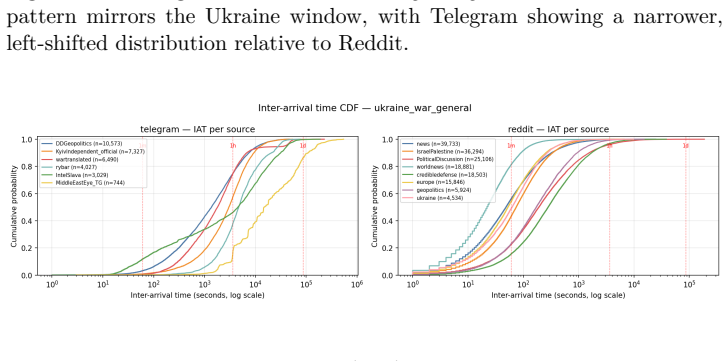
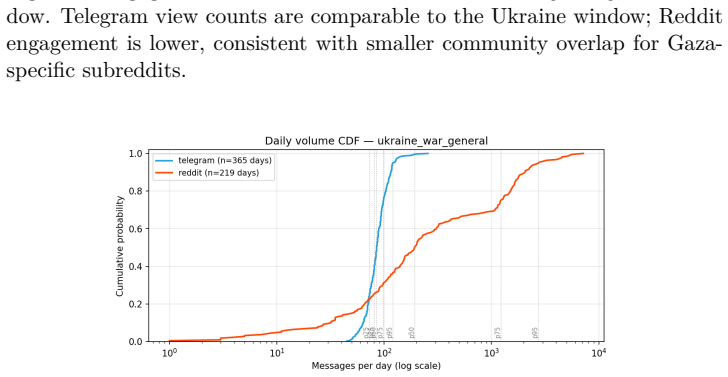
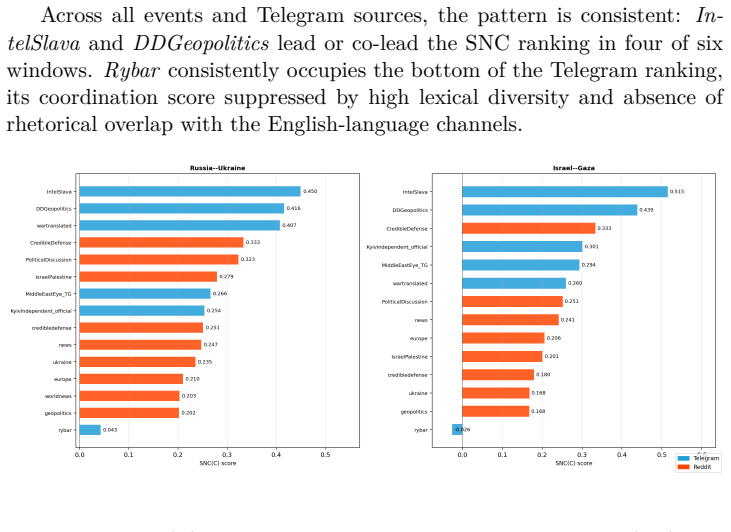
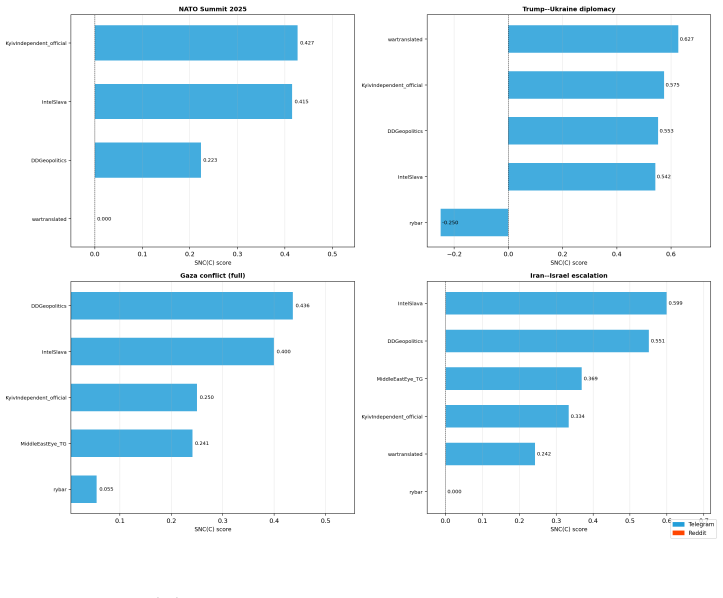
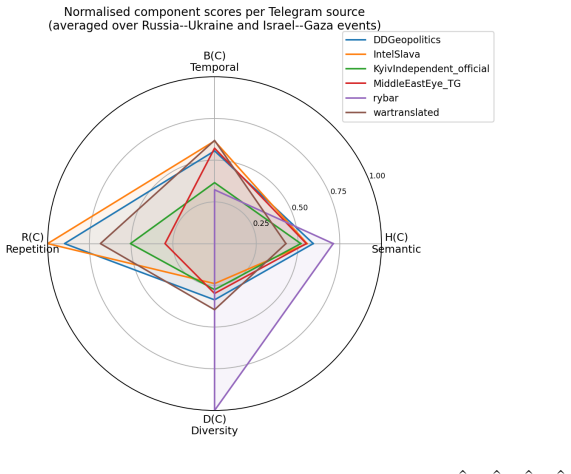
The paper claims that the Synthetic Narrative Coordination Score formed from lexical diversity D(C), temporal burstiness B(C), rhetorical repetition R(C), and semantic homogenization H(C) supplies a more robust and interpretable signal for detecting synthetic political narratives than any individual metric, as evidenced by one channel ranking highest on four of six event windows while another ranks last despite high semantic homogenization.
What carries the argument
The Synthetic Narrative Coordination Score SNC(C) that aggregates the four coordination signals to assess overall synthetic narrative activity.
If this is right
- Channels with high SNC(C) values are more likely to be disseminating coordinated synthetic political narratives.
- No single signal is sufficient because factors such as language can produce misleading results on individual measures.
- The framework can rank sources by coordination likelihood without requiring pre-existing labeled examples.
- The same multi-dimensional approach can be applied to additional platforms or event periods to track narrative patterns.
Where Pith is reading between the lines
- Platforms could monitor high-scoring channels in real time to surface potential synthetic campaigns during major events.
- Adjusting the signals for translation might expose more cross-language coordination that current metrics under-detect.
- The composite score offers a practical starting point for automated flagging systems that do not rely on supervised training data.
Load-bearing premise
The four coordination signals reliably distinguish synthetic coordinated activity from organic discussion without any labeled ground-truth examples of synthetic narratives in the data.
What would settle it
A verified case in which a channel with a high SNC(C) score is shown to produce only uncoordinated organic content, or a low-scoring channel is confirmed as a source of synthetic narratives.
Figures
















read the original abstract
The proliferation of large language models has introduced a new paradigm of synthetic political communication in which narratives may be generated, semantically coordinated, and strategically disseminated across platforms at scale. We present a cross-platform framework for detecting synthetic political narratives using four coordination signals -- lexical diversity D(C), temporal burstiness B(C), rhetorical repetition R(C), and semantic homogenization H(C) -- combined into a Synthetic Narrative Coordination Score SNC(C). We apply the framework to a corpus of 353,223 records spanning six geopolitical event windows collected from six Telegram channels and nine Reddit communities (2023--2026). Results show that IntelSlava exhibits the lowest lexical diversity (MATTR 0.52--0.54), the highest burstiness (B=+0.48 to +0.73), and the highest rhetorical overlap with peer channels (Jaccard 0.12), ranking first in the composite SNC(C) on four of six event windows (SNC 0.45--0.60). Rybar ranks last on all windows despite its high semantic homogenization, because its Russian-language output yields high lexical diversity and near-zero rhetorical Jaccard with English-language channels -- demonstrating that no single indicator is sufficient for coordination detection. Multi-dimensional SNC(C) scoring provides a more robust and interpretable signal than any individual metric.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present a cross-platform framework for detecting synthetic political narratives using four coordination signals—lexical diversity D(C), temporal burstiness B(C), rhetorical repetition R(C), and semantic homogenization H(C)—combined into a Synthetic Narrative Coordination Score SNC(C). Applied to a corpus of 353,223 records from six Telegram channels and nine Reddit communities across six geopolitical event windows (2023–2026), it reports that IntelSlava exhibits the lowest lexical diversity (MATTR 0.52–0.54), highest burstiness (B=+0.48 to +0.73), and highest rhetorical overlap (Jaccard 0.12), ranking first in SNC(C) on four of six windows (SNC 0.45–0.60), while Rybar ranks last on all windows; the central claim is that multi-dimensional SNC(C) scoring provides a more robust and interpretable signal than any individual metric.
Significance. If the mapping from elevated SNC(C) to synthetic (LLM-driven) narratives can be validated, the framework offers a timely methodological contribution for identifying coordinated inauthentic political communication at scale. The large corpus size, cross-platform design, and concrete empirical demonstration that no single signal suffices (e.g., Rybar’s high semantic homogenization offset by language and diversity differences) are strengths that could inform future detection tools. The work highlights practical challenges in multi-platform analysis but currently functions more as a heuristic for statistical coordination than as confirmed synthetic-narrative detection.
major comments (2)
- [§3 (Methodology)] §3 (Methodology): The SNC(C) is presented as a composite of the four signals without explicit equations, normalization procedures, or weighting scheme; this prevents assessment of reproducibility and whether the score involves any fitted parameters or reduces to a self-referential definition.
- [§5 (Results)] §5 (Results): The interpretation that high SNC(C) ranks indicate synthetic LLM-driven narratives (rather than organic or human-coordinated discourse) lacks any labeled ground-truth examples of synthetic content or explicit organic baseline sets in the corpus; this is load-bearing for the robustness claim, as the reported differences (e.g., IntelSlava vs. Rybar) could arise from other coordination mechanisms.
minor comments (2)
- [Abstract] Abstract: The reported SNC(C) range (0.45–0.60) would be more interpretable if the theoretical minimum and maximum of the composite score were stated.
- [Figures/Tables] Figure/Table captions: Ensure all metric definitions (MATTR, Jaccard, burstiness) are briefly restated or referenced for readers unfamiliar with the specific implementations.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting both the strengths of the cross-platform corpus and the need for greater methodological transparency. We respond to each major comment below and describe the revisions that will be incorporated.
read point-by-point responses
-
Referee: §3 (Methodology): The SNC(C) is presented as a composite of the four signals without explicit equations, normalization procedures, or weighting scheme; this prevents assessment of reproducibility and whether the score involves any fitted parameters or reduces to a self-referential definition.
Authors: We agree that the current presentation of SNC(C) lacks sufficient formal detail. In the revised manuscript we will expand §3 to include the explicit mathematical definitions of each coordination signal, the min-max normalization applied to map every signal to [0,1], and the aggregation rule (equal-weighted average of the four normalized values). The formulation contains no learned or fitted parameters and is fully deterministic given the input data, thereby eliminating any self-referential character. revision: yes
-
Referee: §5 (Results): The interpretation that high SNC(C) ranks indicate synthetic LLM-driven narratives (rather than organic or human-coordinated discourse) lacks any labeled ground-truth examples of synthetic content or explicit organic baseline sets in the corpus; this is load-bearing for the robustness claim, as the reported differences (e.g., IntelSlava vs. Rybar) could arise from other coordination mechanisms.
Authors: We accept that the manuscript would be strengthened by a more explicit treatment of this limitation. The revised §5 will reframe the central claim to emphasize that SNC(C) is a multi-signal coordination heuristic whose elevated values are consistent with—but do not prove—synthetic generation. We will add a dedicated limitations paragraph that (a) acknowledges the absence of labeled synthetic or organic baselines in the present corpus, (b) notes that alternative explanations such as human-orchestrated campaigns remain possible, and (c) outlines how future work could inject controlled synthetic content for validation. The comparative analysis of IntelSlava and Rybar will be retained as evidence that single metrics are insufficient, while the interpretive language will be tempered accordingly. revision: partial
Circularity Check
No circularity in derivation of SNC(C) or coordination signals
full rationale
The paper defines four independent coordination signals (lexical diversity D(C), temporal burstiness B(C), rhetorical repetition R(C), semantic homogenization H(C)) and states they are combined into a composite SNC(C) score, then ranks channels such as IntelSlava and Rybar on observed values across event windows. No equations are supplied that render SNC(C) equivalent to any of its inputs by construction, no parameters are fitted to a subset and then relabeled as predictions, and no self-citations or uniqueness theorems are invoked to justify the combination or the mapping to synthetic narratives. The central claim therefore rests on direct computation from the collected corpus rather than on a self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected Telegram channels and Reddit communities during the six geopolitical windows contain measurable differences in synthetic versus organic narrative behavior.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SNC(C) = α Ĥ(C) + β B̂(C) + γ R̂(C) − δ D̂(C) with equal weights 0.25; IntelSlava leads on four windows via low MATTR, high B, high trigram Jaccard
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
H(C) computed as mean pairwise cosine similarity of paraphrase-multilingual-MiniLM embeddings
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Pir Noman Ahmad, Adnan Muhammad Shah, and KangYoon Lee. En- hanced propaganda detection in public social media discussions using a fine-tuned deep learning model: A diffusion of innovation perspective. Future Internet, 17(5):212, 2025
work page 2025
-
[2]
Pir Noman Ahmad, Adnan Muhammad Shah, and KangYoon Lee. An information retrieval language model-based zero- and few-shot learn- ing for propaganda detection in social media content.Knowledge and Information Systems, 68(1):88, 2026
work page 2026
-
[3]
PhD thesis, Columbia University, 2025
Lin Ai.Towards Trustworthy AI: Detecting, Understanding, and Miti- gating Information Disorder. PhD thesis, Columbia University, 2025
work page 2025
-
[4]
Too focused on accuracy to notice the fallout: Towards socially responsible fake news 41 detection
Esma Aïmeur, Gilles Brassard, and Dorsaf Sallami. Too focused on accuracy to notice the fallout: Towards socially responsible fake news 41 detection. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, pages 55–65, 2025
work page 2025
-
[5]
Despoina Antonakaki, Paraskevi Fragopoulou, and Sotiris Ioannidis. A survey of twitter research: Data model, graph structure, sentiment analysis and attacks.Expert Systems with Applications, 164:114006, 2021
work page 2021
-
[6]
Despoina Antonakaki and Sotiris Ioannidis. Cross-platform digital dis- course analysis of the israel-hamas conflict: Sentiment, topics, and event dynamics, 2025
work page 2025
-
[7]
Israel-hamas war through telegram, reddit and twitter, 2025
Despoina Antonakaki and Sotiris Ioannidis. Israel-hamas war through telegram, reddit and twitter, 2025
work page 2025
-
[8]
Despoina Antonakaki and Sotiris Ioannidis. Coordinated information dissemination on telegram and reddit during political turbulence: A case study of venezuela in global news channels, 2026
work page 2026
-
[9]
Despoina Antonakaki and Sotiris Ioannidis. Cross-platform digital dis- course analysis of iran: Topics, sentiment, polarization, and event vali- dation on telegram and reddit, 2026
work page 2026
-
[10]
Samaras, Sotiris Ioannidis, and Paraskevi Fragopoulou
Despoina Antonakaki, Dimitris Spiliotopoulos, Christos V. Samaras, Sotiris Ioannidis, and Paraskevi Fragopoulou. Investigating the com- plete corpus of referendum and elections tweets. In2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), pages 100–105. IEEE, 2016
work page 2016
-
[11]
Samaras, Polyvios Pratikakis, Sotiris Ioannidis, and Paraskevi Fragopoulou
Despoina Antonakaki, Dimitris Spiliotopoulos, Christos V. Samaras, Polyvios Pratikakis, Sotiris Ioannidis, and Paraskevi Fragopoulou. Social media analysis during political turbulence.PLOS ONE, 12(10):e0186836, 2017
work page 2017
-
[12]
Arash Barfar and Lee Sommerfeldt. Propaganda by prompt: Trac- ing hidden linguistic strategies in large language models.Information Processing & Management, 63(2):104403, 2026
work page 2026
-
[13]
Shalin, Nitin Agarwal, and Esra Akbas
Apaar Bawa, Ugur Kursuncu, Dilshod Achilov, Valerie L. Shalin, Nitin Agarwal, and Esra Akbas. Telegram as a battlefield: Kremlin-related communications during the russia-ukraine conflict.Proceedings of the International AAAI Conference on Web and Social Media, 19(1):2361– 2370, 2025. 42
work page 2025
-
[14]
Generative ai and dis- information: Recent advances, challenges, and opportunities
Kalina Bontcheva, Symeon Papadopoulous, Filareti Tsalakanidou, Riccardo Gallotti, Lidia Dutkiewicz, Noémie Krack, Denis Teyssou, Francesco Severio Nucci, Jochen Spangenberg, Ivan Srba, Patrick Aichroth, Luca Cuccovillo, and Luisa Verdoliva. Generative ai and dis- information: Recent advances, challenges, and opportunities. Technical report, European Digit...
work page 2024
-
[15]
Julian Burmester. Influencing belief in llm-based agent networks: An empirically validated simulation of bot-driven manipulation. Master’s thesis, Leuphana University Lüneburg, 2026
work page 2026
-
[16]
Expos- ing cross-platform coordinated inauthentic activity in the run-up to the 2024 u.s
Federico Cinus, Marco Minici, Luca Luceri, and Emilio Ferrara. Expos- ing cross-platform coordinated inauthentic activity in the run-up to the 2024 u.s. election. InProceedings of the ACM Web Conference 2025. ACM, 2025
work page 2024
-
[17]
Combating disinformation in the age of generativeai: Fromwatermarkingllmstopersuasionanalysisofmemes
Amirhossein Dabiriaghdam. Combating disinformation in the age of generativeai: Fromwatermarkingllmstopersuasionanalysisofmemes. Master’s thesis, University of British Columbia, 2025
work page 2025
-
[18]
C. Donner. Misinformation detection methods using large language models and evaluation of application programming interfaces. Master’s thesis, Oklahoma State University, 2024. Metadata verified from public index snippets and secondary references
work page 2024
-
[19]
PhD thesis, University of Bologna, 2024
Margherita Gambini.Digital Sentinels: Unraveling the Societal Impli- cations and Social Media Defence Strategies Against Large Language Models. PhD thesis, University of Bologna, 2024
work page 2024
-
[20]
Studying disinformation narratives on social media with llms and semantic similarity, 2025
Chaytan Inman. Studying disinformation narratives on social media with llms and semantic similarity, 2025
work page 2025
-
[21]
Soveatin Kuntur, Anna Wróblewska, Marcin Paprzycki, and Maria Ganzha. Under the influence: A survey of large language models in fake news detection.IEEE Transactions on Artificial Intelligence, 6(2):458– 476, 2025
work page 2025
-
[22]
Soonchan Kwon and Beakcheol Jang. A comprehensive survey of fake text detection on misinformation and lm-generated texts.IEEE Access, 13:25301–25324, 2025
work page 2025
-
[23]
Ioannis Lamprou, Alexander Shevtsov, Despoina Antonakaki, Polyvios Pratikakis, and Sotiris Ioannidis. Exploring crisis-driven social media 43 patterns: A twitter dataset of usage during the russo-ukrainian war. In International Conference on Advances in Social Networks Analysis and Mining, pages 70–85. Springer Nature Switzerland, 2024
work page 2024
-
[24]
Simulatingmisinformationpropagation in social networks using large language models, 2025
Raj Gaurav Maurya, Vaibhav Shukla, Raj Abhijit Dandekar, Rajat Dandekar, andSreedathPanat. Simulatingmisinformationpropagation in social networks using large language models, 2025
work page 2025
-
[25]
A survey on the use of large language models (llms) in fake news.Future Internet, 16(8):298, 2024
Eleftheria Papageorgiou, Christos Chronis, Iraklis Varlamis, and Yas- sine Himeur. A survey on the use of large language models (llms) in fake news.Future Internet, 16(8):298, 2024
work page 2024
-
[26]
C. Polychronis. The anatomy of a propaganda machine: How state- sponsored agents collaborate to pollute and manipulate the information environment. ProQuest, 2025. Dataset details not publicly verified in this draft
work page 2025
-
[27]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2019
work page 2019
-
[28]
From deception to detection: The dual roles of large language models in fake news, 2024
Dorsaf Sallami, Yuan-Chen Chang, and Esma Aïmeur. From deception to detection: The dual roles of large language models in fake news, 2024
work page 2024
-
[29]
The role of llms in curtailing the spread of disinfor- mation
Diksha Saxena. The role of llms in curtailing the spread of disinfor- mation. Master’s thesis, University at Buffalo, State University of New York, 2024
work page 2024
-
[30]
Siddhant Bikram Shah, Surendrabikram Thapa, Ashish Acharya, Kritesh Rauniyar, Sweta Poudel, Sandesh Jain, Anum Masood, and Usman Naseem. Navigating the web of disinformation and misinfor- mation: Large language models as double-edged swords.IEEE Access, 2024
work page 2024
-
[31]
Russo- ukrainian war: Prediction and explanation of twitter suspension
Alexander Shevtsov, Despoina Antonakaki, Ioannis Lamprou, Ioan- nis Kontogiorgakis, Polyvios Pratikakis, and Sotiris Ioannidis. Russo- ukrainian war: Prediction and explanation of twitter suspension. In Proceedings of the International Conference on Advances in Social Net- works Analysis and Mining, pages 348–355, 2023. 44
work page 2023
-
[32]
Discovery and classification of twitter bots.SN Computer Science, 3(3):255, 2022
Alexander Shevtsov, Maria Oikonomidou, Despoina Antonakaki, Polyvios Pratikakis, and Sotiris Ioannidis. Discovery and classification of twitter bots.SN Computer Science, 3(3):255, 2022
work page 2022
-
[33]
Silalahi, Jonson Manurung, and Bagus Hendra Saputra
Nick Holson M. Silalahi, Jonson Manurung, and Bagus Hendra Saputra. Multimodal deep learning framework for detection and attribution of adversarial information operations on social media platforms.Journal of Defense Technology and Engineering, 2026. 45
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.