Frequency-Domain Regularized Adversarial Alignment for Transferable Attacks against Closed-Source MLLMs
Pith reviewed 2026-05-22 01:20 UTC · model grok-4.3
The pith
Frequency-domain regularization aligns attacks with shared visual focuses across MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FRA-Attack establishes that a unified frequency-domain treatment, consisting of a high-pass DCT objective on patch features for alignment and a model-agnostic low-pass regularizer on gradients using only geometric frequency coordinates, removes surrogate-specific high-frequency artifacts while preserving transferable low-frequency directions, yielding superior cross-model transferability to closed-source MLLMs.
What carries the argument
Frequency-domain regularization with high-pass DCT for patch-feature alignment and Frequency-domain Gradient Regularization (FGR) that modulates gradients using only geometric frequency coordinates.
If this is right
- Perturbations align with semantic cues that are common across models rather than with surrogate-specific behaviors.
- Transferability increases to closed-source models without requiring any internal access or statistics from the target.
- Low-frequency gradient directions remain effective for transfer while high-frequency surrogate artifacts are suppressed.
- The approach scales to multiple vendors and flagship models including GPT-5.4 and Gemini-3-flash.
Where Pith is reading between the lines
- Frequency-based regularizers might extend to transfer attacks in other multimodal or unimodal settings where surrogate-specific noise limits generalization.
- Defenses could target high-frequency input components to disrupt the shared visual focus exploited by such attacks.
- Further tests on additional MLLM families would check whether the high-frequency band remains a reliable carrier of transferable cues.
Load-bearing premise
The high-frequency band in patch features carries the intrinsic visual focus shared across different MLLMs.
What would settle it
An ablation experiment in which either the high-pass DCT objective or the geometric-frequency low-pass regularizer is removed, followed by re-testing transfer success rates on the same closed-source targets such as Claude-Opus-4.6.
Figures











read the original abstract
Multimodal large language models (MLLMs) remain vulnerable to transfer-based targeted attacks, where perturbations optimized on open-source surrogate encoders can generalize to closed-source MLLMs. A key challenge for improving adversarial transferability is to effectively capture the intrinsic visual focus shared across different models, such that perturbations align with transferable semantic cues rather than surrogate-specific behaviors. However, existing methods suffer from spatial-domain feature redundancy and surrogate-specific gradient signals, thereby hindering cross-model transferability. In this paper, we propose FRA-Attack, which addresses both challenges from a unified frequency-domain regularization perspective. For feature alignment, a high-pass DCT objective on patch features suppresses redundant global structures and concentrates the loss on the high-frequency band that carries the MLLMs' intrinsic visual focus. For gradient optimization, we introduce Frequency-domain Gradient Regularization (FGR), a \textit{model-agnostic} low-pass regularizer that modulates the surrogate gradient using only the geometric frequency coordinate, \textit{i.e.}, no surrogate-derived statistic is involved, so that FGR is model-agnostic by construction, removing surrogate-specific high-frequency artifacts while preserving transferable low-frequency directions. Together, the two components form a unified frequency-domain treatment of transferability. Extensive experiments on $15$ flagship MLLMs across $7$ vendors show that FRA-Attack achieves superior cross-model transferability, particularly with state-of-the-art performance on GPT-5.4, Claude-Opus-4.6 and Gemini-3-flash.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FRA-Attack, a frequency-domain method to improve transfer-based targeted attacks from open-source surrogate encoders to closed-source MLLMs. It introduces a high-pass DCT objective on patch features to suppress spatial redundancy and concentrate on high-frequency components presumed to encode shared intrinsic visual focus across models. It also presents Frequency-domain Gradient Regularization (FGR), a low-pass regularizer that modulates surrogate gradients using only geometric frequency coordinates (no surrogate-derived statistics) to remove model-specific high-frequency artifacts while retaining transferable low-frequency directions. The authors claim that extensive experiments across 15 flagship MLLMs from 7 vendors demonstrate superior cross-model transferability, with state-of-the-art results on GPT-5.4, Claude-Opus-4.6, and Gemini-3-flash.
Significance. If the core premise that high-frequency patch features encode model-invariant visual focus can be substantiated with cross-model evidence, the unified frequency-domain treatment could offer a useful regularization strategy for adversarial transferability that avoids surrogate overfitting. The explicit model-agnostic construction of FGR is a methodological strength worth highlighting. However, the current lack of supporting statistics or ablation on the frequency-band invariance assumption limits the immediate impact on the field of black-box multimodal attacks.
major comments (2)
- [Abstract and §3] Abstract and §3 (method description): The central claim that the high-frequency band 'carries the MLLMs' intrinsic visual focus' shared across different models is stated without any cross-model feature statistics, gradient-spectrum comparisons, or ablation showing that surviving DCT components are model-invariant rather than surrogate-dependent. This assumption directly supports both the high-pass alignment objective and the reported transferability gains; its absence is load-bearing for the paper's contribution.
- [Abstract and experimental section] Abstract and experimental section: The claim of 'superior cross-model transferability' and 'state-of-the-art performance' on 15 models is presented without quantitative metrics, baseline tables, statistical tests, or details on data exclusion and hyperparameter choices in the provided text. This prevents verification of the data-to-claim link for the central empirical result.
minor comments (2)
- [Abstract] The abstract would benefit from a brief summary sentence containing at least one key quantitative result (e.g., attack success rate improvement) to allow readers to gauge the scale of the reported gains.
- [Method] Notation for the FGR modulation (geometric frequency coordinate) should be introduced with an explicit equation early in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments identify important areas where additional evidence and clarity will strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): The central claim that the high-frequency band 'carries the MLLMs' intrinsic visual focus' shared across different models is stated without any cross-model feature statistics, gradient-spectrum comparisons, or ablation showing that surviving DCT components are model-invariant rather than surrogate-dependent. This assumption directly supports both the high-pass alignment objective and the reported transferability gains; its absence is load-bearing for the paper's contribution.
Authors: We agree that the invariance assumption is central and that direct supporting evidence should be provided. The high-pass DCT objective is motivated by the goal of suppressing spatially redundant low-frequency structures that tend to be surrogate-specific while emphasizing higher-frequency components that align with semantic details more likely to transfer. In the revised manuscript we will add a dedicated analysis subsection containing cross-model feature statistics (e.g., average cosine similarity of high-pass DCT patch features computed between the surrogate encoder and several target MLLMs) together with frequency-band ablations that compare transferability when only high-pass versus low-pass components are retained. These additions will make the empirical grounding of the assumption explicit. revision: yes
-
Referee: [Abstract and experimental section] Abstract and experimental section: The claim of 'superior cross-model transferability' and 'state-of-the-art performance' on 15 models is presented without quantitative metrics, baseline tables, statistical tests, or details on data exclusion and hyperparameter choices in the provided text. This prevents verification of the data-to-claim link for the central empirical result.
Authors: We acknowledge that the abstract and the high-level experimental summary should contain concrete numbers to allow immediate verification. The full manuscript already reports attack success rates on all 15 MLLMs, comparisons against multiple baselines, and hyperparameter settings in the experimental section. To improve accessibility we will revise the abstract to include the principal quantitative results (e.g., average ASR improvements) and will expand the experimental section with explicit references to the comparison tables, a description of the evaluation protocol, data selection criteria, and hyperparameter ranges. We will also report statistical significance tests (paired t-tests) for the main transferability gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes FRA-Attack via two explicit design choices: a high-pass DCT objective motivated by the premise that high-frequency patch features encode shared visual focus, and FGR defined directly as a low-pass modulator using only geometric frequency coordinates with the explicit statement that no surrogate-derived statistics are involved. Neither component reduces to a fitted parameter renamed as prediction, a self-citation chain, or an ansatz smuggled from prior work by the same authors. The method is presented as a unified frequency-domain treatment whose transferability claims are evaluated on external closed-source targets rather than derived tautologically from its own inputs. This leaves the derivation self-contained against the stated modeling assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption High-frequency band carries the MLLMs' intrinsic visual focus shared across models
- domain assumption Geometric frequency coordinate alone produces a model-agnostic regularizer
Reference graph
Works this paper leans on
-
[1]
Discrete cosine transform.IEEE transactions on Computers, 100(1):90–93, 1974
Nasir Ahmed, T_ Natarajan, and Kamisetty R Rao. Discrete cosine transform.IEEE transactions on Computers, 100(1):90–93, 1974
work page 1974
-
[2]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
work page 2022
-
[3]
Anthropic. Claude opus 4.6 system card. Technical report, Anthropic, 2026
work page 2026
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Bootstrap generalization ability from loss landscape perspective
Huanran Chen, Shitong Shao, Ziyi Wang, Zirui Shang, Jin Chen, Xiaofeng Ji, and Xinxiao Wu. Bootstrap generalization ability from loss landscape perspective. InEuropean conference on computer vision, pages 500–517. Springer, 2022
work page 2022
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
How robust is google’s bard to adversarial image attacks?arXiv preprint arXiv:2309.11751, 2023
Yinpeng Dong, Huanran Chen, Jiawei Chen, Zhengwei Fang, Xiao Yang, Yichi Zhang, Yu Tian, Hang Su, and Jun Zhu. How robust is google’s bard to adversarial image attacks?arXiv preprint arXiv:2309.11751, 2023
-
[8]
Frequency-guided adaptive gradient attack for transferable adversarial examples
Zewei Fu, Ya Li, and Yan Huang. Frequency-guided adaptive gradient attack for transferable adversarial examples. InAsian Conference on Pattern Recognition, pages 381–396. Springer, 2025
work page 2025
-
[9]
Sensen Gao, Xiaojun Jia, Xuhong Ren, Ivor Tsang, and Qing Guo. Boosting transferability in vision-language attacks via diversification along the intersection region of adversarial trajectory. InEuropean Conference on Computer Vision, pages 442–460. Springer, 2024
work page 2024
-
[10]
Boosting adversarial transferability via commonality-oriented gradient optimization
Yanting Gao, Yepeng Liu, Junming Liu, Qi Zhang, Hongyun Zhang, Duoqian Miao, and Cairong Zhao. Boosting adversarial transferability via commonality-oriented gradient optimization. InChinese Conference on Pattern Recognition and Computer Vision (PRCV), pages 62–76. Springer, 2025
work page 2025
-
[11]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adver- sarial examples. In3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015
work page 2015
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Chenhe Gu, Jindong Gu, Andong Hua, and Yao Qin. Improving adversarial transferability in mllms via dynamic vision-language alignment attack.arXiv preprint arXiv:2502.19672, 2025
-
[14]
Amira Guesmi, Bassem Ouni, and Muhammad Shafique. Tesser: Transfer-enhancing adversarial attacks from vision transformers via spectral and semantic regularization.arXiv preprint arXiv:2505.19613, 2025
-
[15]
Low Frequency Adversarial Perturbation
Chuan Guo, Jared S Frank, and Kilian Q Weinberger. Low frequency adversarial perturbation. arXiv preprint arXiv:1809.08758, 2018. 10
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Qi Guo, Shanmin Pang, Xiaojun Jia, Yang Liu, and Qing Guo. Efficient generation of targeted and transferable adversarial examples for vision-language models via diffusion models.IEEE Transactions on Information Forensics and Security, 20:1333–1348, 2024
work page 2024
-
[17]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Kai Hu, Weichen Yu, Li Zhang, Alexander Robey, Andy Zou, Chengming Xu, Haoqi Hu, and Matt Fredrikson. Transferable adversarial attacks on black-box vision-language models.arXiv preprint arXiv:2505.01050, 2025
-
[19]
Man Hua and Ximing Liu. Fe-advgan: A lightweight model adversarial attack method based on frequency-domain guidance and attention mechanism. In2025 International Conference on Algorithms, Software and Network Security (ASNS), pages 30–35, 2025
work page 2025
-
[20]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Adversarial attacks against closed-source mllms via feature optimal alignment
Xiaojun Jia, Sensen Gao, Simeng Qin, Tianyu Pang, Chao Du, Yihao Huang, Xinfeng Li, Yiming Li, Bo Li, and Yang Liu. Adversarial attacks against closed-source mllms via feature optimal alignment. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[22]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[23]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022
work page 2022
-
[24]
Zhaoyi Li, Xiaohan Zhao, Dong-Dong Wu, Jiacheng Cui, and Zhiqiang Shen. A frustratingly simple yet highly effective attack baseline: Over 90% success rate against the strong black- box models of gpt-4.5/4o/o1. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[25]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[26]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[27]
Liangchen Liu, Nannan Wang, Chen Chen, Decheng Liu, Xi Yang, Xinbo Gao, and Tongliang Liu. Frequency-based comprehensive prompt learning for vision-language models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[28]
Safety of multimodal large language models on images and text
Xin Liu, Yichen Zhu, Yunshi Lan, Chao Yang, and Yu Qiao. Safety of multimodal large language models on images and text. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 8151–8159, 2024
work page 2024
-
[29]
Frequency domain model augmentation for adversarial attack
Yuyang Long, Qilong Zhang, Boheng Zeng, Lianli Gao, Xianglong Liu, Jian Zhang, and Jingkuan Song. Frequency domain model augmentation for adversarial attack. InEuropean conference on computer vision, pages 549–566. Springer, 2022
work page 2022
-
[30]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 11
work page 2021
-
[31]
Improving adversarial transferability on vision transformers via forward propagation refinement
Yuchen Ren, Zhengyu Zhao, Chenhao Lin, Bo Yang, Lu Zhou, Zhe Liu, and Chao Shen. Improving adversarial transferability on vision transformers via forward propagation refinement. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25071– 25080, 2025
work page 2025
-
[32]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Towards the resistance of neural network fingerprinting to fine-tuning
Ling Tang, YueFeng Chen, Hui Xue, and Quanshi Zhang. Towards the resistance of neural network fingerprinting to fine-tuning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[34]
Defects of convolutional decoder networks in frequency representation
Ling Tang, Wen Shen, Zhanpeng Zhou, Yuefeng Chen, and Quanshi Zhang. Defects of convolutional decoder networks in frequency representation. InInternational Conference on Machine Learning, pages 33758–33791. PMLR, 2023
work page 2023
-
[35]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Enhancing transferability of adversarial examples with spatial momentum
Guoqiu Wang, Huanqian Yan, and Xingxing Wei. Enhancing transferability of adversarial examples with spatial momentum. InChinese Conference on Pattern Recognition and Computer Vision (PRCV), pages 593–604. Springer, 2022
work page 2022
-
[38]
Enhancing the transferability of adversarial attacks through variance tuning
Xiaosen Wang and Kun He. Enhancing the transferability of adversarial attacks through variance tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1924–1933, 2021
work page 1924
-
[39]
Juanjuan Weng, Zhiming Luo, and Shaozi Li. Exploring frequencies via feature mixing and meta-learning for improving adversarial transferability.IEEE Transactions on Image Processing, 2026
work page 2026
-
[40]
Towards transferable adversarial attacks with centralized perturbation
Shangbo Wu, Yu-an Tan, Yajie Wang, Ruinan Ma, Wencong Ma, and Yuanzhang Li. Towards transferable adversarial attacks with centralized perturbation. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 6109–6116, 2024
work page 2024
-
[41]
Stochastic variance reduced ensemble adversarial attack for boosting the adversarial transferability
Yifeng Xiong, Jiadong Lin, Min Zhang, John E Hopcroft, and Kun He. Stochastic variance reduced ensemble adversarial attack for boosting the adversarial transferability. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14983–14992, 2022
work page 2022
-
[42]
FACL-Attack: Frequency-aware contrastive learning for transferable adversarial attacks
Hunmin Yang, Jongoh Jeong, and Kuk-Jin Yoon. FACL-Attack: Frequency-aware contrastive learning for transferable adversarial attacks. InProceedings of the AAAI Conference on Artificial Intelligence, 2024
work page 2024
-
[43]
Anyattack: Towards large-scale self-supervised adversarial attacks on vision-language models
Jiaming Zhang, Junhong Ye, Xingjun Ma, Yige Li, Yunfan Yang, Yunhao Chen, Jitao Sang, and Dit-Yan Yeung. Anyattack: Towards large-scale self-supervised adversarial attacks on vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19900–19909, 2025
work page 2025
-
[44]
Transferable adversarial attacks on vision transformers with token gradient regularization
Jianping Zhang, Yizhan Huang, Weibin Wu, and Michael R Lyu. Transferable adversarial attacks on vision transformers with token gradient regularization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16415–16424, 2023
work page 2023
-
[45]
Xiaohan Zhao, Zhaoyi Li, Yaxin Luo, Jiacheng Cui, and Zhiqiang Shen. Pushing the frontier of black-box lvlm attacks via fine-grained detail targeting.arXiv preprint arXiv:2602.17645, 2026
-
[46]
Yunqing Zhao, Tianyu Pang, Chao Du, Xiao Yang, Chongxuan Li, Ngai-Man Man Cheung, and Min Lin. On evaluating adversarial robustness of large vision-language models.Advances in Neural Information Processing Systems, 36:54111–54138, 2023. 12
work page 2023
-
[47]
Yayin Zheng, Chen Wan, Zihong Guo, Hailing Kuang, and Xiaohai Lu. Boosting adversarial transferability via high-frequency augmentation and hierarchical-gradient fusion.arXiv preprint arXiv:2505.21181, 2025
-
[48]
Minigpt-4: En- hancing vision-language understanding with advanced large language models
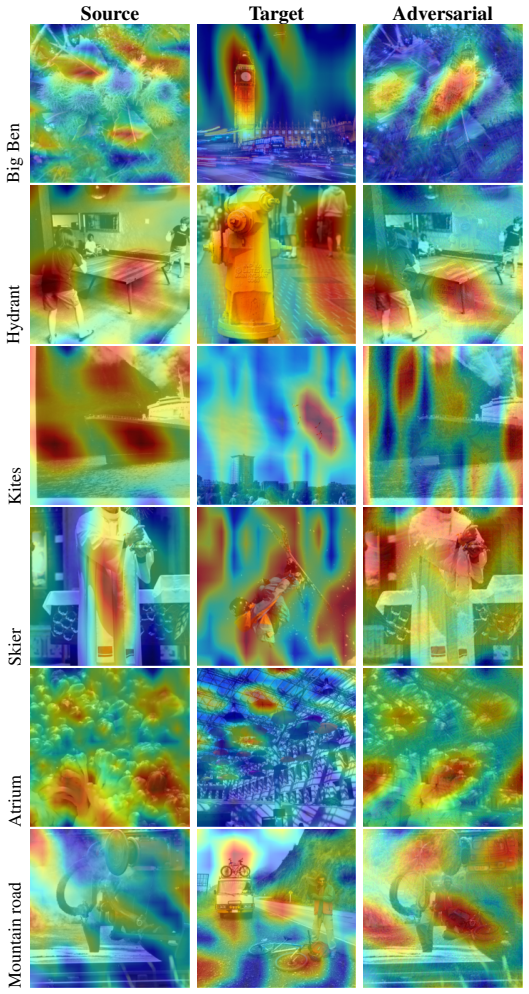
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: En- hancing vision-language understanding with advanced large language models. InThe Twelfth International Conference on Learning Representations, 2024. A DCT High-Frequency Energy Visualization We visualize on real source–target–adversarial triples how the DCT high-frequency ...
work page 2024
-
[49]
FGR uses the polynomial radial decay (Eq
The DCT alignment uses high-frequency threshold θ= 10 , number of selected high-frequency components n= 10 , global weight wg = 1.0 , local weight wl = 0.2 , and Sinkhorn entropic regularization λ= 0.1 . FGR uses the polynomial radial decay (Eq. 8) with exponent p= 1.5 . The MI-FGSM momentum decay is µ= 1.0 and the dynamic-weighting temperature is T= 1.0 ...
-
[50]
Average ASR (%) across GPT-5.4, Claude- Opus-4.6, and Gemini-3-flash on the 100-pair pilot panel; the default ϵ=16/255, N=300 matches the 1,000-pair main panel within ±3 ASR. FRA-Attack scales monotonically with the perturbation budget: ϵ= 4/255 is too small to escape the natural caption neighbourhood (4.0 ASR), ϵ= 8/255 already lands the perturbation in ...
-
[51]
Main Subject Consistency: same key subject/object→higher score
-
[52]
Relevant Description: same context or topic→higher score
-
[53]
Ignore Fine-Grained Details: do not penalize phrasing or minor variation
-
[54]
Partial Matches: extra information without contradiction→still high score
-
[55]
Score Range: 1.0: nearly identical in meaning. 0.8–0.9: same subject, highly related descriptions. 0.7–0.8: same subject, core meaning aligned. 0.5–0.7: same subject, different perspectives or missing details. 0.3–0.5: related but not highly similar. 0.0–0.2: completely different subjects or unrelated. Text 1: {caption_adv} Text 2: {caption_tgt} Output on...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.