No Pose, No Problem in 4D: Feed-Forward Dynamic Gaussians from Unposed Multi-View Videos
Pith reviewed 2026-05-22 06:23 UTC · model grok-4.3
The pith
NoPo4D reconstructs dynamic 4D scenes from unposed multi-view videos in a single feed-forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NoPo4D is the first feed-forward system to jointly address dynamic content, multi-view input, and unknown camera poses by introducing a velocity decomposition that splits Gaussian motion into per-pixel image-plane shifts and depth changes, enabling direct supervision from pseudo ground-truth optical flow, together with a bidirectional motion encoder for cross-view and cross-frame aggregation and view-dependent opacity to mitigate misalignments.
What carries the argument
Velocity decomposition that splits Gaussian motion into per-pixel image-plane shifts supervised by optical flow and separate depth changes.
If this is right
- Enables joint reconstruction of dynamics, multiple views, and unknown poses in one forward pass.
- Outperforms existing feed-forward baselines on four multi-view dynamic benchmarks.
- With optional post-optimization reaches or exceeds quality of per-scene optimization methods.
- Runs orders of magnitude faster than per-scene optimization approaches.
- Avoids any requirement for 3D motion ground truth by relying on 2D optical flow for the image-plane term.
Where Pith is reading between the lines
- The decomposition may allow 2D optical-flow tools to bootstrap 3D dynamic modeling in other representations beyond Gaussians.
- It could support real-time 4D capture pipelines where camera calibration is impractical or costly.
- Future extensions might combine the same motion split with longer video sequences or additional priors for temporal consistency.
- The approach suggests that many dynamic reconstruction tasks can be decoupled into 2D image-plane and depth components for simpler supervision.
Load-bearing premise
That pseudo ground-truth optical flow supplies sufficiently accurate supervision for the image-plane motion component without producing 3D inconsistencies that cannot be resolved later.
What would settle it
A multi-view dynamic benchmark in which estimated optical flow contains large errors, resulting in visibly broken 3D motion in the output Gaussians that post-optimization cannot repair.
Figures



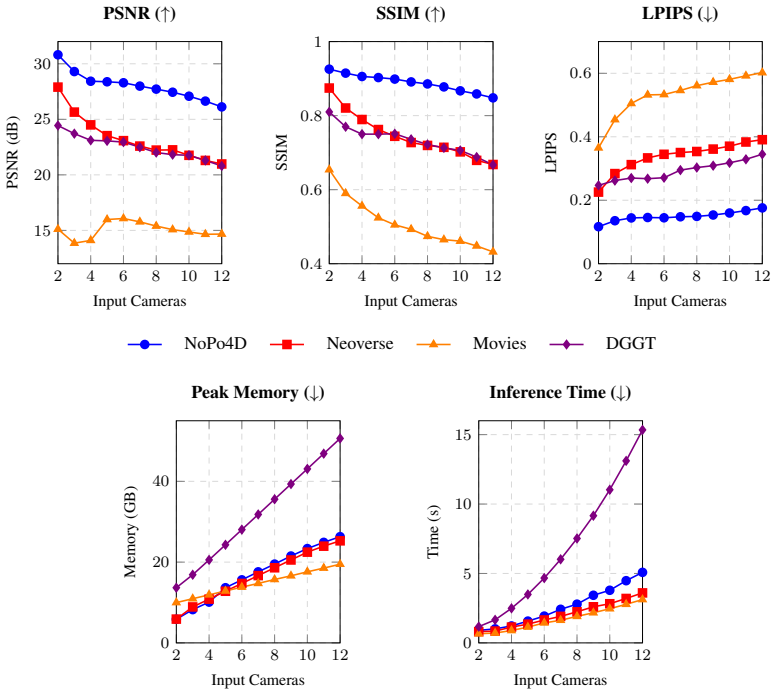

read the original abstract
Recent feed-forward 3D gaussian splatting methods have made dramatic progress on individual aspects of 3D scene reconstruction, but no existing method jointly addresses dynamic content, multi-view input, and unknown camera poses in a single feed-forward pass. Methods that handle dynamics either require accurate camera poses or accept only monocular input; pose-free multi-view methods address only static scenes; and per-scene optimization methods bridge some of these gaps but at minutes-to-hours cost per scene. We introduce NoPo4D, the first feed-forward system that addresses this empty quadrant. Building on a pretrained geometry backbone and recent 4D Gaussian frameworks, NoPo4D introduces a velocity decomposition that splits Gaussian motion into per-pixel image-plane shifts and depth changes, allowing direct supervision from pseudo ground-truth optical flow on the 2D component. This sidesteps both the differentiable rendering that couples prior posed methods to pose accuracy and the 3D motion ground truth that prior pose-free methods require. The system is rounded out by a bidirectional motion encoder for cross-view and cross-frame feature aggregation, and view-dependent opacity that mitigates cross-view and cross-timestep Gaussian misalignments. On four multi-view dynamic benchmarks, NoPo4D consistently outperforms prior feed-forward baselines, and with an optional post-optimization stage surpasses per-scene optimization methods, while running orders of magnitude faster.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents NoPo4D, the first feed-forward method for joint dynamic 4D Gaussian reconstruction from unposed multi-view videos. It builds on a pretrained geometry backbone and 4D Gaussian frameworks by introducing a velocity decomposition that splits Gaussian motion into per-pixel image-plane shifts (directly supervised by pseudo ground-truth optical flow) and scalar depth changes. The approach is completed by a bidirectional motion encoder for cross-view and cross-frame aggregation and view-dependent opacity to mitigate misalignments. Claims include consistent outperformance of prior feed-forward baselines on four multi-view dynamic benchmarks and, with optional post-optimization, surpassing per-scene optimization methods at orders-of-magnitude lower runtime.
Significance. If the central claims hold, the work would fill an important gap by enabling fast, pose-free feed-forward reconstruction of dynamic multi-view scenes without requiring known camera poses, monocular input restrictions, or expensive per-scene optimization. The velocity decomposition and optical-flow supervision strategy is a notable technical contribution that avoids coupling to differentiable rendering or 3D motion ground truth.
major comments (1)
- [§3.2] §3.2 (Velocity Decomposition): The decomposition splits Gaussian velocity into 2D image-plane shifts plus scalar depth changes, with direct supervision applied only to the 2D component via optical flow. Because no differentiable rendering, multi-view geometric consistency loss, or 3D motion ground truth is used, the depth-velocity component receives no explicit 3D signal. In regimes with non-negligible out-of-plane motion or parallax, this leaves 4D trajectories under-constrained; the bidirectional encoder and view-dependent opacity must then carry all cross-view consistency, which is itself learned. This directly affects the feed-forward quality claims and the reported gains from optional post-optimization.
minor comments (2)
- [Abstract] The abstract states performance gains but provides no quantitative numbers, ablation details, or error analysis; these should be summarized with key metrics and dataset names for readers who stop at the abstract.
- [§3.2] Notation for the velocity components (e.g., the exact definition of the depth-change scalar and its integration into the 4D Gaussian trajectory) should be made fully explicit with an equation reference in §3.2.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We address the single major comment below, providing clarifications on the velocity decomposition design while noting targeted revisions to improve the discussion.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Velocity Decomposition): The decomposition splits Gaussian velocity into 2D image-plane shifts plus scalar depth changes, with direct supervision applied only to the 2D component via optical flow. Because no differentiable rendering, multi-view geometric consistency loss, or 3D motion ground truth is used, the depth-velocity component receives no explicit 3D signal. In regimes with non-negligible out-of-plane motion or parallax, this leaves 4D trajectories under-constrained; the bidirectional encoder and view-dependent opacity must then carry all cross-view consistency, which is itself learned. This directly affects the feed-forward quality claims and the reported gains from optional post-optimization.
Authors: We thank the referee for this observation on the velocity decomposition. It is accurate that explicit supervision via optical flow is applied solely to the 2D image-plane shifts, and the scalar depth-velocity component lacks direct 3D ground truth, differentiable rendering losses, or an explicit multi-view geometric consistency term. We maintain, however, that the depth component is not left under-constrained in practice. The bidirectional motion encoder aggregates features across all input views and timesteps during both training and inference, enabling the network to learn joint representations that enforce cross-view and cross-frame consistency on the full 4D motion—including depth changes—from the multi-view video data itself. Because the model is trained end-to-end on posed multi-view dynamic sequences (even though poses are not provided at test time), the learned depth velocities are implicitly regularized by the requirement to produce coherent 4D Gaussians that can be rendered consistently from multiple viewpoints. The view-dependent opacity module further compensates for residual misalignments that may arise from out-of-plane motion. Ablation results in the manuscript show that disabling the bidirectional encoder leads to clear degradation on benchmarks containing substantial 3D dynamics and parallax, supporting its role in maintaining consistency. We have added a clarifying paragraph in the revised §3.2 that explicitly discusses how cross-view feature aggregation provides the necessary 3D signal without requiring differentiable rendering or 3D motion ground truth. This design choice directly supports the feed-forward claims by avoiding pose sensitivity; the empirical gains over baselines and the further improvement with optional post-optimization remain valid, revision: partial
Circularity Check
No significant circularity; derivation is self-contained with external supervision
full rationale
The paper introduces a velocity decomposition splitting Gaussian motion into per-pixel image-plane shifts and depth changes, with direct supervision applied to the 2D component from pseudo ground-truth optical flow. This supervision is external to the model's own outputs rather than a fitted parameter renamed as a prediction. The bidirectional motion encoder and view-dependent opacity are presented as additional architectural components for cross-view aggregation and misalignment mitigation. No load-bearing self-citations, uniqueness theorems from prior author work, or ansatzes smuggled via citation are described. The central claims rest on these new components and pretrained geometry backbone, with performance evaluated on external benchmarks, keeping the derivation independent of its own fitted results by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A pretrained geometry backbone supplies reliable features for initializing dynamic scene reconstruction.
Reference graph
Works this paper leans on
-
[1]
Cross-View Completion Models are Zero-shot Correspondence Estimators, December 2024
Honggyu An, Jinhyeon Kim, Seonghoon Park, Jaewoo Jung, Jisang Han, Sunghwan Hong, and Seungryong Kim. Cross-View Completion Models are Zero-shot Correspondence Estimators, December 2024. URLhttp://arxiv.org/abs/2412.09072. arXiv:2412.09072
-
[2]
C3G: Learning Compact 3D Representations with 2K Gaussians
Honggyu An, Jaewoo Jung, Mungyeom Kim, Sunghwan Hong, Chaehyun Kim, Kazumi Fukuda, Minkyeong Jeon, Jisang Han, Takuya Narihira, Hyuna Ko, et al. C3g: Learning compact 3d representations with 2k gaussians.arXiv preprint arXiv:2512.04021, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
ReCamMaster: Camera-Controlled Generative Rendering from A Single Video, March 2025
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, and Di Zhang. ReCamMaster: Camera-Controlled Generative Rendering from A Single Video, March 2025. URL http://arxiv.org/abs/2503.11647. arXiv:2503.11647 version: 1
-
[4]
Michael Broxton, John Flynn, Ryan Overbeck, Daniel Erickson, Peter Hedman, Matthew Duvall, Jason Dourgarian, Jay Busch, Matt Whalen, and Paul Debevec. Immersive light field video with a layered mesh representation.ACM Transactions on Graphics, 39(4), August 2020. ISSN 0730-0301, 1557-7368. doi: 10.1145/3386569.3392485. URL https://dl.acm.org/ doi/10.1145/...
-
[5]
HexPlane: A Fast Representation for Dynamic Scenes, March
Ang Cao and Justin Johnson. HexPlane: A Fast Representation for Dynamic Scenes, March
- [6]
-
[7]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction, 2024
David Charatan, Sizhe Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction, December 2023. URL http://arxiv.org/abs/2312.12337. arXiv:2312.12337
-
[8]
Feedforward 4d reconstruction for dynamic driving scenes using unposed images
Xiaoxue Chen, Ziyi Xiong, Yuantao Chen, Gen Li, Nan Wang, Hongcheng Luo, Long Chen, Haiyang Sun, BING WANG, Guang Chen, et al. Feedforward 4d reconstruction for dynamic driving scenes using unposed images
-
[9]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images, 2024
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi- View Images, March 2024. URL http://arxiv.org/abs/2403.14627. arXiv:2403.14627
-
[10]
Zequn Chen, Jiezhi Yang, and Heng Yang. Pref3r: Pose-free feed-forward 3d gaussian splatting from variable-length image sequence.arXiv preprint arXiv:2411.16877, 2024
-
[11]
Seokju Cho, Sunghwan Hong, Sangryul Jeon, Yunsung Lee, Kwanghoon Sohn, and Seungryong Kim. Cats: Cost aggregation transformers for visual correspondence.Advances in Neural Information Processing Systems, 34:9011–9023, 2021
work page 2021
-
[12]
Seokju Cho, Sunghwan Hong, and Seungryong Kim. Cats++: Boosting cost aggregation with convolutions and transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(6):7174–7194, 2022
work page 2022
-
[13]
Cat-seg: Cost aggregation for open-vocabulary semantic segmentation
Seokju Cho, Heeseong Shin, Sunghwan Hong, Anurag Arnab, Paul Hongsuck Seo, and Se- ungryong Kim. Cat-seg: Cost aggregation for open-vocabulary semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4113–4123, 2024
work page 2024
-
[14]
4D-Rotor Gaussian Splatting: Towards Efficient Novel View Synthesis for Dynamic Scenes, July 2024
Yuanxing Duan, Fangyin Wei, Qiyu Dai, Yuhang He, Wenzheng Chen, and Baoquan Chen. 4D-Rotor Gaussian Splatting: Towards Efficient Novel View Synthesis for Dynamic Scenes, July 2024. URLhttp://arxiv.org/abs/2402.03307. arXiv:2402.03307 [cs]. 10
-
[15]
K-Planes: Explicit Radiance Fields in Space, Time, and Appearance, March
Sara Fridovich-Keil, Giacomo Meanti, Frederik Warburg, Benjamin Recht, and Angjoo Kanazawa. K-Planes: Explicit Radiance Fields in Space, Time, and Appearance, March
- [16]
-
[17]
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Tri- antafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, Eugene Byrne, Zach Chavis, Joya Chen, Feng Cheng, Fu-Jen Chu, Sean Crane, Avijit Dasgupta, Jing Dong, Maria Escobar, Cristhian Forigua, Abrham Gebreselasie, Sanjay Haresh, Jing Huang, Md Mo...
-
[18]
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J. Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, Thomas Kipf, Abhijit Kundu, Dmitry Lagun, Issam Laradji, Hsueh-Ti, Liu, Henning Meyer, Yishu Miao, Derek Nowrouzezahrai, Cengiz Oztireli, Etienne Pot, Noha Radwan, Daniel Rebain, Sara Sabour, Mehdi S. ...
-
[19]
Entropy-Gradient Grounding: Training-Free Evidence Retrieval in Vision-Language Models
Marcel Gröpl, Jaewoo Jung, Seungryong Kim, Marc Pollefeys, and Sunghwan Hong. Entropy- gradient grounding: Training-free evidence retrieval in vision-language models.arXiv preprint arXiv:2604.08456, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
ScreenParse: Moving Beyond Sparse Grounding with Complete Screen Parsing Supervision
A Said Gurbuz, Sunghwan Hong, Ahmed Nassar, Marc Pollefeys, and Peter Staar. Mov- ing beyond sparse grounding with complete screen parsing supervision.arXiv preprint arXiv:2602.14276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
D^2USt3R: Enhancing 3D Reconstruction with 4D Pointmaps for Dynamic Scenes, April 2025
Jisang Han, Honggyu An, Jaewoo Jung, Takuya Narihira, Junyoung Seo, Kazumi Fukuda, Chaehyun Kim, Sunghwan Hong, Yuki Mitsufuji, and Seungryong Kim. D^2USt3R: Enhancing 3D Reconstruction with 4D Pointmaps for Dynamic Scenes, April 2025. URL http://arxiv. org/abs/2504.06264. arXiv:2504.06264
-
[22]
Jisang Han, Sunghwan Hong, Jaewoo Jung, Wooseok Jang, Honggyu An, Qianqian Wang, Seungryong Kim, and Chen Feng. Emergent outlier view rejection in visual geometry grounded transformers.arXiv preprint arXiv:2512.04012, 2025
-
[23]
Deep matching prior: Test-time optimization for dense correspondence
Sunghwan Hong and Seungryong Kim. Deep matching prior: Test-time optimization for dense correspondence. InProceedings of the IEEE/CVF international conference on computer vision, pages 9907–9917, 2021
work page 2021
-
[24]
Cost aggregation with 4d convolutional swin transformer for few-shot segmentation
Sunghwan Hong, Seokju Cho, Jisu Nam, Stephen Lin, and Seungryong Kim. Cost aggregation with 4d convolutional swin transformer for few-shot segmentation. InEuropean Conference on Computer Vision, pages 108–126. Springer, 2022
work page 2022
-
[25]
Sunghwan Hong, Jisu Nam, Seokju Cho, Susung Hong, Sangryul Jeon, Dongbo Min, and Seungryong Kim. Neural matching fields: Implicit representation of matching fields for visual correspondence.Advances in Neural Information Processing Systems, 35:13512–13526, 2022. 11
work page 2022
-
[26]
Pf3plat: Pose-free feed-forward 3d gaussian splatting, 2025
Sunghwan Hong, Jaewoo Jung, Heeseong Shin, Jisang Han, Jiaolong Yang, Chong Luo, and Seungryong Kim. PF3plat: Pose-Free Feed-Forward 3D Gaussian Splatting, October 2024. URLhttp://arxiv.org/abs/2410.22128. arXiv:2410.22128
-
[27]
Unifying correspondence pose and nerf for generalized pose-free novel view synthesis
Sunghwan Hong, Jaewoo Jung, Heeseong Shin, Jiaolong Yang, Seungryong Kim, and Chong Luo. Unifying correspondence pose and nerf for generalized pose-free novel view synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20196–20206, 2024
work page 2024
-
[28]
Sc-gs: Sparse-controlled gaussian splatting for editable dynamic scenes
Yi-Hua Huang, Yang-Tian Sun, Ziyi Yang, Xiaoyang Lyu, Yan-Pei Cao, and Xiaojuan Qi. Sc-gs: Sparse-controlled gaussian splatting for editable dynamic scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4220–4230, 2024
work page 2024
-
[29]
Ufo-4d: Unposed feedforward 4d reconstruction from two images.arXiv preprint arXiv:2602.24290, 2026
Junhwa Hur, Charles Herrmann, Songyou Peng, Philipp Henzler, Zeyu Ma, Todd Zickler, and Deqing Sun. Ufo-4d: Unposed feedforward 4d reconstruction from two images.arXiv preprint arXiv:2602.24290, 2026
-
[30]
Anysplat: Feed-forward 3d gaussian splatting from unconstrained views, 2025
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, Dahua Lin, and Bo Dai. AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views, May 2025. URLhttp://arxiv.org/abs/2505.23716. arXiv:2505.23716
-
[31]
3D Gaussian Splatting for Real-Time Radiance Field Rendering, August 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3D Gaussian Splatting for Real-Time Radiance Field Rendering, August 2023. URL http://arxiv.org/ abs/2308.04079. arXiv:2308.04079
-
[32]
Chaehyun Kim, Heeseong Shin, Eunbeen Hong, Heeji Yoon, Anurag Arnab, Paul Hongsuck Seo, Sunghwan Hong, and Seungryong Kim. Seg4diff: Unveiling open-vocabulary segmentation in text-to-image diffusion transformers.arXiv preprint arXiv:2509.18096, 2025
-
[33]
JoungBin Lee, Jaewoo Jung, Jisang Han, Takuya Narihira, Kazumi Fukuda, Junyoung Seo, Sunghwan Hong, Yuki Mitsufuji, and Seungryong Kim. 3d scene prompting for scene-consistent camera-controllable video generation.arXiv preprint arXiv:2510.14945, 2025
-
[34]
TORA: Topological Representation Alignment for 3D Shape Assembly
Nahyuk Lee, Zhiang Chen, Marc Pollefeys, and Sunghwan Hong. Tora: Topological representa- tion alignment for 3d shape assembly.arXiv preprint arXiv:2604.04050, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
MoSca: Dynamic Gaussian Fusion from Casual Videos via 4D Motion Scaffolds, November 2024
Jiahui Lei, Yijia Weng, Adam Harley, Leonidas Guibas, and Kostas Daniilidis. MoSca: Dynamic Gaussian Fusion from Casual Videos via 4D Motion Scaffolds, November 2024. URL http: //arxiv.org/abs/2405.17421. arXiv:2405.17421
-
[36]
Grounding image matching in 3d with mast3r, 2024
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding Image Matching in 3D with MASt3R, June 2024. URLhttp://arxiv.org/abs/2406.09756. arXiv:2406.09756 [cs]
-
[37]
Neural 3d video synthesis from multi-view video
Tianye Li, Mira Slavcheva, Michael Zollhoefer, Simon Green, Christoph Lassner, Changil Kim, Tanner Schmidt, Steven Lovegrove, Michael Goesele, Richard Newcombe, et al. Neural 3d video synthesis from multi-view video. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5521–5531, 2022
work page 2022
-
[38]
Movies: Motion-aware 4d dynamic view synthesis in one second
Chenguo Lin, Yuchen Lin, Panwang Pan, Yifan Yu, Tao Hu, Honglei Yan, Katerina Fragkiadaki, and Yadong Mu. Movies: Motion-aware 4d dynamic view synthesis in one second. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2026
work page 2026
-
[39]
Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Junhao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth Anything 3: Recovering the Visual Space from Any Views, November
-
[40]
Depth Anything 3: Recovering the Visual Space from Any Views
URLhttp://arxiv.org/abs/2511.10647. arXiv:2511.10647
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization, November 2017. URLhttps://arxiv.org/abs/1711.05101v3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Dynamic 3D Gaussians: Tracking by Persistent Dynamic View Synthesis, August 2023
Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3D Gaussians: Tracking by Persistent Dynamic View Synthesis, August 2023. URL http://arxiv.org/ abs/2308.09713. arXiv:2308.09713 [cs]. 12
-
[43]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick La...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Keunhong Park, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan B. Goldman, Steven M. Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable Neural Radiance Fields, September
- [45]
-
[46]
D-nerf: Neural radiance fields for dynamic scenes.arXiv preprint arXiv:2011.13961, 2020
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-NeRF: Neural Radiance Fields for Dynamic Scenes, November 2020. URL http://arxiv.org/ abs/2011.13961. arXiv:2011.13961
-
[47]
Vision Transformers for Dense Predic- tion, March 2021
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision Transformers for Dense Predic- tion, March 2021. URLhttp://arxiv.org/abs/2103.13413. arXiv:2103.13413
-
[48]
L4GM: Large 4D Gaussian Reconstruction Model, June 2024
Jiawei Ren, Kevin Xie, Ashkan Mirzaei, Hanxue Liang, Xiaohui Zeng, Karsten Kreis, Ziwei Liu, Antonio Torralba, Sanja Fidler, Seung Wook Kim, and Huan Ling. L4GM: Large 4D Gaussian Reconstruction Model, June 2024. URL http://arxiv.org/abs/2406.10324. arXiv:2406.10324
-
[49]
Heeseong Shin, Chaehyun Kim, Sunghwan Hong, Seokju Cho, Anurag Arnab, Paul Hongsuck Seo, and Seungryong Kim. Towards open-vocabulary semantic segmentation without semantic labels.Advances in Neural Information Processing Systems, 37:9153–9177, 2024
work page 2024
-
[50]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
Brandon Smart, Chuanxia Zheng, Iro Laina, and Victor Adrian Prisacariu. Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs, August 2024. URL http://arxiv.org/ abs/2408.13912. arXiv:2408.13912
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Dynamic gaussian marbles for novel view synthesis of casual monocular videos
Colton Stearns, Adam Harley, Mikaela Uy, Florian Dubost, Federico Tombari, Gordon Wet- zstein, and Leonidas Guibas. Dynamic gaussian marbles for novel view synthesis of casual monocular videos. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[52]
Edgar Tretschk, Ayush Tewari, Vladislav Golyanik, Michael Zollhöfer, Christoph Lassner, and Christian Theobalt. Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Dynamic Scene From Monocular Video, August 2021. URL http://arxiv. org/abs/2012.12247. arXiv:2012.12247
-
[53]
3d reconstruction with spatial memory
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory. In2025 Interna- tional Conference on 3D Vision (3DV), pages 78–89. IEEE, 2025
work page 2025
-
[54]
Vggt: Visual geometry grounded transformer, 2025
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual Geometry Grounded Transformer, March 2025. URL http: //arxiv.org/abs/2503.11651. arXiv:2503.11651
-
[55]
Shape of motion: 4d reconstruc- tion from a single video
Qianqian Wang, Vickie Ye, Hang Gao, Jake Austin, Zhengqi Li, and Angjoo Kanazawa. Shape of Motion: 4D Reconstruction from a Single Video, July 2024. URL http://arxiv.org/ abs/2407.13764. arXiv:2407.13764 [cs]
-
[56]
Shape of motion: 4d reconstruction from a single video
Qianqian Wang, Vickie Ye, Hang Gao, Weijia Zeng, Jake Austin, Zhengqi Li, and Angjoo Kanazawa. Shape of motion: 4d reconstruction from a single video. InInternational Conference on Computer Vision (ICCV), 2025
work page 2025
-
[57]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
work page 2025
-
[58]
Dust3r: Geometric 3d vision made easy, 2024
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. DUSt3R: Geometric 3D Vision Made Easy, December 2023. URL http://arxiv.org/abs/2312. 14132. arXiv:2312.14132. 13
-
[59]
SEA-RAFT: Simple, Efficient, Accurate RAFT for Optical Flow, May 2024
Yihan Wang, Lahav Lipson, and Jia Deng. SEA-RAFT: Simple, Efficient, Accurate RAFT for Optical Flow, May 2024. URLhttp://arxiv.org/abs/2405.14793. arXiv:2405.14793
-
[60]
MonoFusion: Sparse- View 4D Reconstruction via Monocular Fusion, July 2025
Zihan Wang, Jeff Tan, Tarasha Khurana, Neehar Peri, and Deva Ramanan. MonoFusion: Sparse- View 4D Reconstruction via Monocular Fusion, July 2025. URL http://arxiv.org/abs/ 2507.23782. arXiv:2507.23782 [cs]
-
[61]
4d gaussian splatting for real-time dynamic scene rendering,
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering, July 2024. URLhttp://arxiv.org/abs/2310.08528. arXiv:2310.08528 [cs]
-
[62]
4DGT: Learning a 4D Gaussian Transformer Using Real-World Monocular Videos, June 2025
Zhen Xu, Zhengqin Li, Zhao Dong, Xiaowei Zhou, Richard Newcombe, and Zhaoyang Lv. 4DGT: Learning a 4D Gaussian Transformer Using Real-World Monocular Videos, June 2025. URLhttp://arxiv.org/abs/2506.08015. arXiv:2506.08015 [cs]
-
[63]
arXiv preprint arXiv:2501.13928 (2025)
Jianing Yang, Alexander Sax, Kevin J. Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass, January 2025. URL http://arxiv.org/abs/2501.13928. arXiv:2501.13928
-
[64]
Depth anything: Unleash- ing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data, April 2024. URL http://arxiv.org/abs/2401.10891. arXiv:2401.10891
-
[65]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Heng- shuang Zhao. Depth Anything V2, June 2024. URL http://arxiv.org/abs/2406.09414. arXiv:2406.09414
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos, January 2026
Yuxue Yang, Lue Fan, Ziqi Shi, Junran Peng, Feng Wang, and Zhaoxiang Zhang. NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos, January 2026. URL http: //arxiv.org/abs/2601.00393. arXiv:2601.00393
-
[67]
Zeyu Yang, Hongye Yang, Zijie Pan, and Li Zhang. Real-time Photorealistic Dynamic Scene Representation and Rendering with 4D Gaussian Splatting, February 2024. URL http:// arxiv.org/abs/2310.10642. arXiv:2310.10642 [cs]
-
[68]
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction, November 2023. URLhttp://arxiv.org/abs/2309.13101. arXiv:2309.13101 [cs]
-
[69]
No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images
Botao Ye, Sifei Liu, Haofei Xu, Xueting Li, Marc Pollefeys, Ming-Hsuan Yang, and Songyou Peng. No Pose, No Problem: Surprisingly Simple 3D Gaussian Splats from Sparse Unposed Images, October 2024. URLhttp://arxiv.org/abs/2410.24207. arXiv:2410.24207
-
[70]
Yonosplat: You only need one model for feedforward 3d gaussian splatting, 2025
Botao Ye, Boqi Chen, Haofei Xu, Daniel Barath, and Marc Pollefeys. Yonosplat: You only need one model for feedforward 3d gaussian splatting.arXiv preprint arXiv:2511.07321, 2025
-
[71]
Heeji Yoon, Jaewoo Jung, Junwan Kim, Hyungyu Choi, Heeseong Shin, Sangbeom Lim, Honggyu An, Chaehyun Kim, Jisang Han, Donghyun Kim, et al. Visual representation alignment for multimodal large language models.arXiv preprint arXiv:2509.07979, 2025
-
[72]
Litept: Lighter yet stronger point transformer.arXiv preprint arXiv:2512.13689, 2025
Yuanwen Yue, Damien Robert, Jianyuan Wang, Sunghwan Hong, Jan Dirk Wegner, Christian Rupprecht, and Konrad Schindler. Litept: Lighter yet stronger point transformer.arXiv preprint arXiv:2512.13689, 2025
-
[73]
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jampani, Trevor Darrell, Forrester Cole, Deqing Sun, and Ming-Hsuan Yang. MonST3R: A Simple Approach for Estimating Geome- try in the Presence of Motion, October 2024. URL http://arxiv.org/abs/2410.03825. arXiv:2410.03825
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views, 2026
Shangzhan Zhang, Jianyuan Wang, Yinghao Xu, Nan Xue, Christian Rupprecht, Xiaowei Zhou, Yujun Shen, and Gordon Wetzstein. FLARE: Feed-forward Geometry, Appearance and Camera Estimation from Uncalibrated Sparse Views, February 2025. URL http://arxiv.org/abs/ 2502.12138. arXiv:2502.12138. 14 Supplementary Material This document provides additional analysis ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.