Imagine2Real: Towards Zero-shot Humanoid-Object Interaction via Video Generative Priors
Pith reviewed 2026-05-22 05:59 UTC · model grok-4.3
The pith
Unified 4D point trajectories and sparse keypoint tracking inside a behavior model enable zero-shot humanoid-object interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
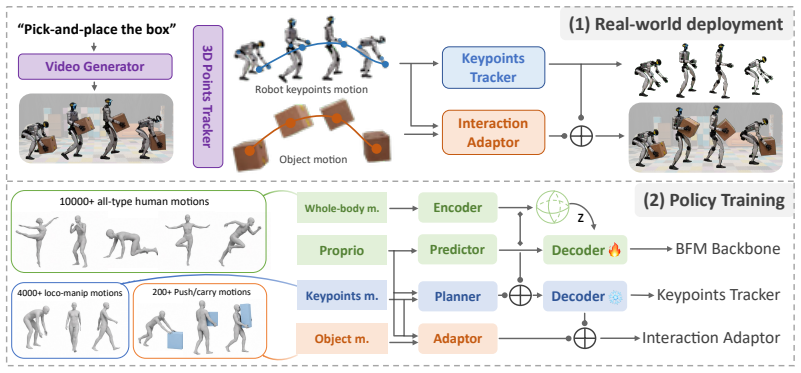
Imagine2Real resolves representation misalignment by formulating robot and object motions as unified 4D point trajectories. To overcome retargeting complexity, its Keypoints Tracker tracks only sparse critical points (base, hands, and object) entirely bypassing the error-amplifying retargeting process. By utilizing the latent space of a Behavior Foundation Model as the tracker's search domain and employing a progressive training strategy, the method learns robust behaviors with simple tracking rewards, enabling zero-shot physical deployment within a mocap system.
What carries the argument
The Keypoints Tracker operating in the Behavior Foundation Model latent space, which recovers natural gaits and reaching motions from sparse 4D point signals.
If this is right
- Enables flexible geometry-free interaction without explicit CAD models or geometric priors.
- Bypasses intensive morphing and morphological mismatch issues during retargeting.
- Maintains natural gaits and reaching despite using only sparse tracking signals.
- Supports zero-shot physical deployment on humanoid hardware inside a motion-capture system.
- Simplifies policy learning by relying on basic tracking rewards rather than hand-crafted reward engineering.
Where Pith is reading between the lines
- If the Behavior Foundation Model latent space is sufficiently general, the same sparse-tracking approach could transfer to other robot morphologies without retraining the tracker.
- Pairing the method with newer video-generation models might allow interaction behaviors for objects or scenes never seen during training.
- The current reliance on mocap hardware for deployment leaves open whether the same policies could be refined further through simulation-to-real techniques to reduce physical setup needs.
- The framework could be tested on multi-object or time-varying scenes to check whether the unified 4D trajectory representation scales beyond single static interactions.
Load-bearing premise
The latent space of the Behavior Foundation Model already contains natural gaits and reaching behaviors that can be recovered from sparse keypoint tracking signals without additional morphological retargeting or error amplification.
What would settle it
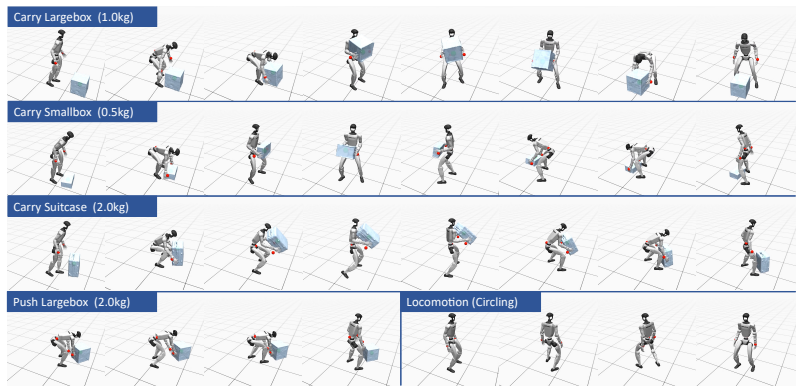
Deploy the trained policy on the physical humanoid and check whether it produces stable natural motions when only base, hand, and object positions are supplied as tracking targets, or whether additional retargeting and error correction become necessary.
Figures


read the original abstract
Whole-body Humanoid-Object Interaction (HOI) is bottlenecked by the scarcity of high-fidelity 3D data. While video generative priors offer a promising alternative, existing methods suffer from \textit{Representation Misalignment} due to their reliance on geometric priors (e.g., explicit CAD models), and \textit{Retargeting Complexity} arising from intensive morphing and morphological mismatch. We propose Imagine2Real, a zero-shot HOI framework for flexible, geometry-free interaction. To resolve misalignment, we formulate robot and object motions as unified 4D point trajectories. To overcome retargeting complexity, our Keypoints Tracker tracks only sparse critical points (base, hands, and object), entirely bypassing the error-amplifying retargeting process. To maintain natural gaits despite these sparse signals, we utilize the latent space of a Behavior Foundation Model (BFM) as the tracker's search domain. Using a progressive training strategy, Imagine2Real learns robust behaviors with simple tracking rewards, enabling zero-shot physical deployment within a motion capture(mocap) system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Imagine2Real, a zero-shot framework for whole-body humanoid-object interaction (HOI) that leverages video generative priors to address data scarcity. It resolves representation misalignment by formulating robot and object motions as unified 4D point trajectories and overcomes retargeting complexity by restricting a Keypoints Tracker to sparse critical points (base, hands, and object) inside the latent space of a Behavior Foundation Model (BFM). A progressive training strategy with simple tracking rewards is used to produce natural gaits, enabling direct physical deployment in mocap systems without geometric priors or morphological retargeting.
Significance. If the central assumptions hold, the geometry-free 4D trajectory formulation and sparse BFM-latent tracking could substantially lower the barrier to scalable humanoid HOI by eliminating CAD models and error-prone retargeting pipelines. The approach would be particularly valuable for rapid deployment in unstructured environments, provided the BFM prior reliably supplies missing degrees of freedom.
major comments (2)
- [§3 and §4] §3 (Method) and §4 (Experiments): The manuscript supplies no quantitative results, ablation studies, success rates, or error metrics for the zero-shot physical deployment claim. Without these, it is impossible to assess whether the BFM latent-space tracker actually recovers stable, natural full-body motions from the under-specified sparse keypoints.
- [§3.2] §3.2 (Keypoints Tracker): The load-bearing assumption that the BFM latent space already encodes recoverable natural gaits, balance corrections, and object-specific reaching behaviors from only base/hands/object keypoints is stated but not tested. Sparse 3D keypoints leave many morphological and dynamic degrees of freedom unconstrained; the paper provides no analysis showing that simple tracking rewards prevent kinematically feasible yet dynamically unstable or unnatural solutions.
minor comments (2)
- [Abstract] The acronym BFM is introduced without an explicit expansion on first use in the main text.
- [Figures] Figure captions should explicitly state whether trajectories are shown in simulation or on the physical robot.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional evidence would strengthen the claims regarding zero-shot physical deployment. We address each major comment below with honest clarifications and plans for revision.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Method) and §4 (Experiments): The manuscript supplies no quantitative results, ablation studies, success rates, or error metrics for the zero-shot physical deployment claim. Without these, it is impossible to assess whether the BFM latent-space tracker actually recovers stable, natural full-body motions from the under-specified sparse keypoints.
Authors: We agree that the current manuscript lacks quantitative metrics for the physical deployment results, focusing instead on the novel 4D trajectory formulation and qualitative mocap demonstrations. To address this directly, the revised version will include success rates for HOI tasks, keypoint tracking errors, stability indicators, and ablations comparing BFM-constrained tracking against unconstrained baselines. These additions will provide measurable evidence for the recovery of stable full-body motions. revision: yes
-
Referee: [§3.2] §3.2 (Keypoints Tracker): The load-bearing assumption that the BFM latent space already encodes recoverable natural gaits, balance corrections, and object-specific reaching behaviors from only base/hands/object keypoints is stated but not tested. Sparse 3D keypoints leave many morphological and dynamic degrees of freedom unconstrained; the paper provides no analysis showing that simple tracking rewards prevent kinematically feasible yet dynamically unstable or unnatural solutions.
Authors: The BFM latent space is chosen because it is pretrained on large-scale motion data that encodes natural dynamics and balance; restricting optimization to this space with progressive simple rewards is intended to fill in the unconstrained degrees of freedom plausibly. Our experiments show deployable natural gaits without retargeting, but we acknowledge the assumption would benefit from explicit validation. We will add analysis in revision, such as comparisons of motions generated inside versus outside the BFM space and qualitative/quantitative checks for instability. revision: partial
Circularity Check
No circularity: framework builds on external BFM prior without reducing claims to self-defined inputs
full rationale
The paper formulates motions as unified 4D point trajectories and restricts tracking to sparse keypoints inside a Behavior Foundation Model latent space, then applies simple tracking rewards. No equations, fitted parameters, or self-citation chains are exhibited that would make the claimed zero-shot behaviors equivalent to the authors' own definitions or inputs by construction. The BFM is invoked as an external prior whose latent space is assumed to contain recoverable gaits; this is an assumption rather than a derivation that collapses to the paper's choices. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
formulate robot and object motions as unified 4D point trajectories... Keypoints Tracker tracks only sparse critical points (base, hands, and object)... utilize the latent space of a Behavior Foundation Model (BFM) as the tracker's search domain
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
simple tracking rewards... BFM backbone... latent residual planner
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Chen et al. Gmt: A general and scalable motion-tracking framework for humanoid robots. arXiv preprint arXiv:2501.09876, 2025
-
[2]
Truong, Xiaoyu Huang, Yuman Gao, Guy Tevet, Koushil Sreenath, and C
Qiayuan Liao, Takara E. Truong, Xiaoyu Huang, Yuman Gao, Guy Tevet, Koushil Sreenath, and C. Karen Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint, 2025
work page 2025
-
[3]
Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint, 2025
Zhengyi Luo, Ye Yuan, Tingwu Wang, Chenran Li, Sirui Chen, Fernando Castañeda, Zi-Ang Cao, Jiefeng Li, David Minor, Qingwei Ben, Xingye Da, Runyu Ding, Cyrus Hogg, Lina Song, Edy Lim, Eugene Jeong, Tairan He, Haoru Xue, Wenli Xiao, Zi Wang, Simon Yuen, Jan Kautz, Yan Chang, Umar Iqbal, Linxi "Jim" Fan, and Yuke Zhu. Sonic: Supersizing motion tracking for ...
work page 2025
-
[4]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Oh Oh, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning, 2024
work page 2024
-
[5]
Rt-2: Vision-language- action models transfer web knowledge to robotic control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, et al. Rt-2: Vision-language- action models transfer web knowledge to robotic control. InConference on Robot Learning, 2023
work page 2023
-
[6]
${\pi}_{0.7}$: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, et al. Pi0.7: a steerable gen- eralist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4):1–20, 2021
work page 2021
-
[8]
Huayi Wang, Wentao Zhang, Runyi Yu, Tao Huang, Junli Ren, Feiyu Jia, Zirui Wang, Xiaojie Niu, Xiao Chen, Jiahe Chen, Qifeng Chen, Jingbo Wang, and Jiangmiao Pang. Physhsi: Towards a real-world generalizable and natural humanoid-scene interaction.arXiv preprint, 2025
work page 2025
-
[9]
Improved techniques for training gans.Advances in Neural Information Processing Systems, 29, 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans.Advances in Neural Information Processing Systems, 29, 2016
work page 2016
-
[10]
Siheng Zhao, Yanjie Ze, et al. Resmimic: From general motion tracking to humanoid whole- body loco-manipulation via residual learning.arXiv preprint arXiv:2510.05070, 2025
-
[11]
Hdmi: Learning interactive humanoid whole-body control from human videos.arXiv preprint, 2025
Haoyang Weng, Yitang Li, Nikhil Sobanbabu, Zihan Wang, Zhengyi Luo, Tairan He, Deva Ramanan, and Guanya Shi. Hdmi: Learning interactive humanoid whole-body control from human videos.arXiv preprint, 2025
work page 2025
- [12]
-
[13]
World-grounded human motion recovery via gravity-view coordinates
Zehong Shen, Huaijin Pi, Yan Xia, Zhi Cen, Sida Peng, Zechen Hu, Hujun Bao, Ruizhen Hu, and Xiaowei Zhou. World-grounded human motion recovery via gravity-view coordinates. In SIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[14]
Foundationpose: Unified 6d pose estimation and tracking of novel objects
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InIEEE Conference on Computer Vision and Pattern Recognition, pages 17868–17879, 2024
work page 2024
-
[15]
Yinhuai Wang, Qihan Zhao, Yuen Fui Lau, Runyi Yu, Hok Wai Tsui, Qifeng Chen, Jingbo Wang, Jiangmiao Pang, and Ping Tan. Humanx: Toward agile and generalizable humanoid interaction skills from human videos.arXiv preprint, 2026
work page 2026
-
[16]
Karen Liu, Rocky Duan, and Guanya Shi
Lujie Yang, Xiaoyu Huang, Zhen Wu, Angjoo Kanazawa, Pieter Abbeel, Carmelo Sferrazza, C. Karen Liu, Rocky Duan, and Guanya Shi. Omniretarget: Interaction-preserving data generation for humanoid whole-body loco-manipulation and scene interaction.arXiv preprint, 2025
work page 2025
-
[17]
Spatial relationship preserving character motion adaptation
Edmond SL Ho, Taku Komura, and Chiew-Lan Tai. Spatial relationship preserving character motion adaptation. InACM SIGGRAPH 2010 papers, pages 1–8. 2010
work page 2010
-
[18]
Shaofeng Yin, Yanjie Ze, Hong-Xing Yu, C. Karen Liu, and Jiajun Wu. Visualmimic: Visual humanoid loco-manipulation via motion tracking and generation.arXiv preprint, 2025. 9
work page 2025
-
[19]
Sirui Chen, Yufei Ye, Zi-ang Cao, Jennifer Lew, Pei Xu, and C Karen Liu. Hand-eye au- tonomous delivery: Learning humanoid navigation, locomotion and reaching.arXiv preprint arXiv:2508.03068, 2025
-
[20]
Bfm-zero: Unsupervised reinforcement learning for whole-body control
Yitang Li, Zhengyi Luo, et al. Bfm-zero: Unsupervised reinforcement learning for whole-body control. InInternational Conference on Learning Representations, 2026
work page 2026
-
[21]
Behavior foundation model for humanoid robots.arXiv preprint, 2025
Weishuai Zeng, Shunlin Lu, Kangning Yin, Xiaojie Niu, Minyue Dai, Jingbo Wang, and Jiangmiao Pang. Behavior foundation model for humanoid robots.arXiv preprint, 2025
work page 2025
-
[22]
Intermimic: Towards universal whole-body control for physics-based human-object interactions
Sirui Xu, Hung Yu Ling, Yu-Xiong Wang, and Liang-Yan Gui. Intermimic: Towards universal whole-body control for physics-based human-object interactions. InIEEE Conference on Computer Vision and Pattern Recognition, pages 12266–12277, 2025
work page 2025
-
[23]
Xue Bin Peng, Pieter Abbeel, Sergey Levine, and Michiel van de Panne. Deepmimic: Example- guided deep reinforcement learning of physics-based character skills.ACM Transactions on Graphics (TOG), 37(4):1–14, 2018
work page 2018
-
[24]
Asap: Aligning simulation and real-world physics for learning agile humanoid.arXiv preprint, 2025
Tairan He, Jiawei Gao, Wenli Xiao, Yuanhang Zhang, Zi Wang, Jiashun Wang, Zhengyi Luo, Guanqi He, Nikhil Sobanbab, Chaoyi Pan, Zeji Yi, Guannan Qu, Kris Kitani, Jessica Hodgins, Linxi "Jim" Fan, Yuke Zhu, Changliu Liu, and Guanya Shi. Asap: Aligning simulation and real-world physics for learning agile humanoid.arXiv preprint, 2025
work page 2025
-
[25]
Perpetual humanoid control for real-time simulated avatars
Zhengyi Luo, Jinkun Cao, Kris Kitani, Weipeng Xu, et al. Perpetual humanoid control for real-time simulated avatars. InIEEE International Conference on Computer Vision, pages 10895–10904, 2023
work page 2023
-
[26]
Omnih2o: Universal dexterous human-to-humanoid control.arXiv preprint arXiv:2508.12345, 2025
Tairan He et al. Omnih2o: Universal dexterous human-to-humanoid control.arXiv preprint arXiv:2508.12345, 2025
-
[27]
Hover: Humanoid versatile controller for general-purpose tasks.arXiv preprint arXiv:2410.21229, 2025
Tairan He et al. Hover: Humanoid versatile controller for general-purpose tasks.arXiv preprint arXiv:2410.21229, 2025
-
[28]
Exbody2: Advanced expressive humanoid whole-body control.arXiv preprint, 2024
Mazeyu Ji, Xuanbin Peng, Fangchen Liu, Jialong Li, Ge Yang, Xuxin Cheng, and Xiaolong Wang. Exbody2: Advanced expressive humanoid whole-body control.arXiv preprint, 2024
work page 2024
- [29]
-
[30]
Clot: Closed-loop global motion tracking for whole-body humanoid teleoperation.arXiv preprint, 2026
Tengjie Zhu, Guanyu Cai, Yang Zhaohui, Guanzhu Ren, Haohui Xie, ZiRui Wang, Junsong Wu, Jingbo Wang, Xiaokang Yang, Yao Mu, and Yichao Yan. Clot: Closed-loop global motion tracking for whole-body humanoid teleoperation.arXiv preprint, 2026
work page 2026
-
[31]
Agility meets stability: Versatile humanoid control with heterogeneous data.arXiv preprint, 2025
Yixuan Pan, Ruoyi Qiao, Li Chen, Kashyap Chitta, Liang Pan, Haoguang Mai, Qingwen Bu, Hao Zhao, Cunyuan Zheng, Ping Luo, and Hongyang Li. Agility meets stability: Versatile humanoid control with heterogeneous data.arXiv preprint, 2025
work page 2025
-
[32]
Yunshen Wang, Shaohang Zhu, Peiyuan Zhi, Yuhan Li, Jiaxin Li, Yong-Lu Li, Yuchen Xiao, Xingxing Wang, Baoxiong Jia, and Siyuan Huang. Omnixtreme: Breaking the generality barrier in high-dynamic humanoid control.arXiv preprint arXiv:2602.23843, 2026
-
[33]
Unitracker: Learning universal whole-body motion tracker for humanoid robots, 2025
Y . Xue et al. Unitracker: A scalable and adaptive framework for humanoid motion tracking. arXiv preprint arXiv:2507.07356, 2025
-
[34]
Learning athletic humanoid tennis skills from imperfect human motion data.arXiv preprint, 2026
Zhikai Zhang, Haofei Lu, Yunrui Lian, Ziqing Chen, Yun Liu, Chenghuai Lin, Han Xue, Zicheng Zeng, Zekun Qi, Shaolin Zheng, Qing Luan, Jingbo Wang, Junliang Xing, He Wang, and Li Yi. Learning athletic humanoid tennis skills from imperfect human motion data.arXiv preprint, 2026
work page 2026
-
[35]
Junli Ren, Yinghui Li, Kai Zhang, Penglin Fu, Haoran Jiang, Yixuan Pan, Guangjun Zeng, Tao Huang, Weizhong Guo, Peng Lu, Tianyu Li, Jingbo Wang, Li Chen, Hongyang Li, and Ping Luo. Smash: Mastering scalable whole-body skills for humanoid ping-pong with egocentric vision.arXiv preprint, 2026
work page 2026
-
[36]
Humanoid goalkeeper: Learning from position conditioned task-motion constraints.arXiv preprint, 2025
Junli Ren, Junfeng Long, Tao Huang, Huayi Wang, Zirui Wang, Feiyu Jia, Wentao Zhang, Jingbo Wang, Ping Luo, and Jiangmiao Pang. Humanoid goalkeeper: Learning from position conditioned task-motion constraints.arXiv preprint, 2025
work page 2025
-
[37]
Zhi Su, Bike Zhang, Nima Rahmanian, Yuman Gao, Qiayuan Liao, Caitlin Regan, Koushil Sreenath, and S. Shankar Sastry. Hitter: A humanoid table tennis robot via hierarchical planning and learning.arXiv preprint, 2025. 10
work page 2025
-
[38]
Sim-to-real learning for humanoid box loco-manipulation.arXiv preprint arXiv:2310.03191, 2023
J Dao, H Duan, and A Fern. Sim-to-real learning for humanoid box loco-manipulation.arXiv preprint arXiv:2310.03191, 2023
-
[39]
Opt2skill: Imitating dynamically- feasible whole-body trajectories.arXiv preprint, 2024
Fukang Liu, Zhaoyuan Gu, Yilin Cai, Ziyi Zhou, Hyunyoung Jung, Jaehwi employment Jang, Shijie Zhao, Sehoon Ha, Yue Chen, Danfei Xu, and Ye Zhao. Opt2skill: Imitating dynamically- feasible whole-body trajectories.arXiv preprint, 2024
work page 2024
-
[40]
Wococo: Learning whole-body humanoid control with sequential contacts
Chong Zhang, Wenli Xiao, Tairan He, and Guanya Shi. Wococo: Learning whole-body humanoid control with sequential contacts. InConference on Robot Learning, 2024
work page 2024
-
[41]
Generalizable humanoid manipulation with 3d diffusion policies
Yanjie Ze, Zixuan Chen, Wenhao Wang, Tianyi Chen, Xialin He, Ying Yuan, Xue Bin Peng, and Jiajun Wu. Generalizable humanoid manipulation with 3d diffusion policies. InIEEE/RSJ International Conference on Intelligent Robots and Systems, 2025
work page 2025
-
[42]
Humanplus: Hu- manoid shadowing and imitation from humans.arXiv preprint, 2024
Zipeng Fu, Qingqing Zhao, Qi Wu, Gordon Wetzstein, and Chelsea Finn. Humanplus: Hu- manoid shadowing and imitation from humans.arXiv preprint, 2024
work page 2024
-
[43]
Leverb: Humanoid whole-body control with latent vision-language instruction.arXiv preprint, 2025
Haoru Xue, Xiaoyu Huang, Dantong Niu, Qiayuan Liao, Thomas Kragerud, Jan Tommy Gravdahl, Xue Bin Peng, Guanya Shi, Trevor Darrell, Koushil Sreenath, and Shankar Sastry. Leverb: Humanoid whole-body control with latent vision-language instruction.arXiv preprint, 2025
work page 2025
-
[44]
Falcon: Learning force-adaptive humanoid loco-manipulation.arXiv preprint, 2025
Yuanhang Zhang, Yifu Yuan, Prajwal Gurunath, Ishita Gupta, Shayegan Omidshafiei, Ali akbar Agha-mohammadi, Marcell Vazquez-Chanlatte, Liam Pedersen, Tairan He, and Guanya Shi. Falcon: Learning force-adaptive humanoid loco-manipulation.arXiv preprint, 2025
work page 2025
-
[45]
Homie: Humanoid loco-manipulation with isomorphic exoskeleton cockpit.arXiv preprint, 2025
Qingwei Ben, Feiyu Jia, Jia Zeng, Junting Dong, Dahua Lin, and Jiangmiao Pang. Homie: Humanoid loco-manipulation with isomorphic exoskeleton cockpit.arXiv preprint, 2025
work page 2025
-
[46]
Ultra: Unified physics-driven neural retargeting and control.arXiv preprint arXiv:2603.03279, 2026
ULTRA Team. Ultra: Unified physics-driven neural retargeting and control.arXiv preprint arXiv:2603.03279, 2026
-
[47]
Demohlm: From one demonstration to generalizable humanoid loco-manipulation.arXiv preprint, 2025
Yuhui Fu, Feiyang Xie, Chaoyi Xu, Jing employment Xiong, Haoqi Yuan, and Zongqing Lu. Demohlm: From one demonstration to generalizable humanoid loco-manipulation.arXiv preprint, 2025
work page 2025
-
[48]
Dayang Liang, Yuhang Lin, Xinzhe Liu, Jiyuan Shi, Yunlong Liu, and Chenjia Bai. Interreal: A unified physics-based imitation framework for learning human-object interaction skills.arXiv preprint, 2026
work page 2026
-
[49]
Pro-hoi: Perceptive root-guided humanoid-object interaction.arXiv preprint arXiv:2603.01126, 2026
Yuhang Lin, Jiyuan Shi, Dewei Wang, Jipeng Kong, Yong Liu, Chenjia Bai, and Xuelong Li. Pro-hoi: Perceptive root-guided humanoid-object interaction.arXiv preprint arXiv:2603.01126, 2026
-
[50]
Dvij Kalaria, Sudarshan S Harithas, Pushkal Katara, Sangkyung Kwak, Sarthak Bhagat, Shankar Sastry, Srinath Sridhar, Sai Vemprala, Ashish Kapoor, and Jonathan Chung-Kuan Huang. Dreamcontrol: Human-inspired whole-body humanoid control for scene interaction via guided diffusion.arXiv preprint, 2025
work page 2025
-
[51]
Visual imitation enables contextual humanoid control.arXiv preprint, 2025
Arthur Allshire, Hongsuk Choi, Junyi Zhang, David McAllister, Anthony Zhang, Chung Min Kim, Trevor Darrell, Pieter Abbeel, Jitendra Malik, and Angjoo Kanazawa. Visual imitation enables contextual humanoid control.arXiv preprint, 2025
work page 2025
-
[52]
ZeroWBC Authors. Zerowbc: Learning natural visuomotor humanoid control directly from human egocentric video.arXiv preprint arXiv:2603.09170, 2025
-
[53]
Video generation models as world simulators
OpenAI. Video generation models as world simulators. Technical report, OpenAI, 2024
work page 2024
- [54]
- [55]
-
[56]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [57]
-
[58]
Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations
Shivansh Patel, Shraddhaa Mohan, Hanlin Mai, Unnat Jain, Svetlana Lazebnik, and Yunzhu Li. Robotic manipulation by imitating generated videos without physical demonstrations.arXiv preprint arXiv:2507.00990, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Kai Ye, Yuhang Wu, Shuyuan Hu, Junliang Li, Meng Liu, Yongquan Chen, and Rui Huang. Gen2real: Towards demo-free dexterous manipulation by harnessing generated video.arXiv preprint, 2025
work page 2025
-
[60]
Jhen Hsieh, Kuan-Hsun Tu, Kuo-Han Hung, and Tsung-Wei Ke. Dexman: Learning bimanual dexterous manipulation from human and generated videos.arXiv preprint, 2025
work page 2025
-
[61]
Geometry-aware 4D Video Generation for Robot Manipulation
Zeyi Liu, Shuang Li, Eric Cousineau, Siyuan Feng, Benjamin Burchfiel, and Shuran Song. Geometry-aware 4d video generation for robot manipulation.arXiv preprint arXiv:2507.01099, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Spatialtrackerv2: 3d point tracking made easy
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. Spatialtrackerv2: 3d point tracking made easy. In IEEE International Conference on Computer Vision, 2025
work page 2025
-
[64]
Amass: Archive of motion capture as surface shapes
Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Gerard Pons-Moll, and Michael J Black. Amass: Archive of motion capture as surface shapes. InIEEE International Conference on Computer Vision, pages 5442–5451, 2019
work page 2019
-
[65]
Harvey, Mike Yurick, Derek Nowrouzezahrai, and Christopher Pal
Félix G. Harvey, Mike Yurick, Derek Nowrouzezahrai, and Christopher Pal. Robust motion in-betweening. 39(4), 2020
work page 2020
-
[66]
Ian Mason, Sebastian Starke, and Taku Komura. Real-time style modelling of human locomotion via feature-wise transformations and local motion phases.Proceedings of the ACM on Computer Graphics and Interactive Techniques, 5(1):1–18, 2022
work page 2022
-
[67]
Pink: Python inverse kinematics based on Pinocchio, 2026
Stéphane Caron, Yann De Mont-Marin, Rohan Budhiraja, Seung Hyeon Bang, Ivan Domrachev, Simeon Nedelchev, Peter Du, Adrien Escande, Joris Vaillant, Bruce Wingo, Santosh Patapati, Daniel San José Pro, and Nicolas Guillermo Marticorena Vidal. Pink: Python inverse kinematics based on Pinocchio, 2026
work page 2026
-
[68]
Object motion guided human motion synthesis.ACM Transactions on Graphics (TOG), 42(6):1–11, 2023
Jiaman Li, Jiajun Wu, and C Karen Liu. Object motion guided human motion synthesis.ACM Transactions on Graphics (TOG), 42(6):1–11, 2023
work page 2023
-
[69]
Amazon FAR, Pieter Abbeel, Juyue Chen, Rocky Duan, Alejandro Escontrela, Manan Gandhi, Samuel Gundry, Xiaoyu Huang, Angjoo Kanazawa, Tomasz Lewicki, Jiaman Li, Karen Liu, Clay Rosenthal, Younggyo Seo, Carlo Sferrazza, Guanya Shi, Linda Shih, Jonathan Tseng, Zhen Wu, Lujie Yang, Brent Yi, and Yuanhang Zhang. Holosoma
-
[70]
Isaac gym: High performance gpu-based physics simulation for robot learning, 2021
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, and Gavriel State. Isaac gym: High performance gpu-based physics simulation for robot learning, 2021
work page 2021
-
[71]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[72]
The robot walks forward and carries the box
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. InIEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033. IEEE, 2012. 12 Appendix A Training Details In this section, we provide comprehensive training details for the three-stage progressive learning framework introduced in Section ...
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.