WorldKV: Efficient World Memory with World Retrieval and Compression
Pith reviewed 2026-05-22 06:16 UTC · model grok-4.3
The pith
WorldKV retrieves and compresses historical KV chunks to keep generated worlds visually consistent at twice the speed of full memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
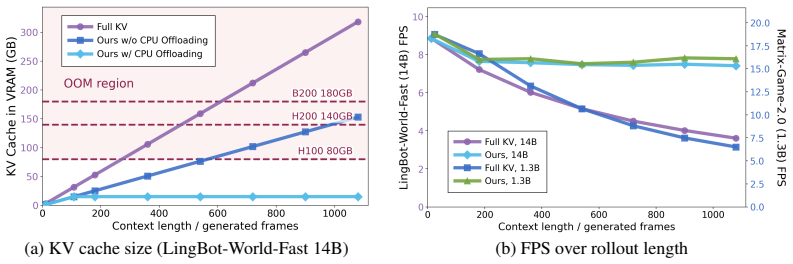
WorldKV is a training-free framework that preserves persistent world consistency in autoregressive video diffusion models. World Retrieval stores evicted KV-cache chunks in GPU or CPU memory and selectively reinserts scene-relevant chunks into the native attention window by camera and action correspondence without re-encoding. World Compression then prunes redundant tokens inside each chunk by key-key similarity to an anchor frame, halving per-chunk storage so that twice as much history fits under a fixed budget. On Matrix-Game-2.0 and LingBot-World-Fast the method matches or exceeds full-KV fidelity at roughly twice the throughput and remains competitive with memory-trained baselines.
What carries the argument
World Retrieval, which stores and selectively reinserts historical KV-cache chunks using camera and action correspondence, paired with World Compression that prunes tokens via key-key similarity to an anchor frame.
Load-bearing premise
Camera and action correspondence alone is enough to identify the exact historical chunks needed to preserve visual consistency.
What would settle it
A controlled test sequence in which the camera revisits a prior viewpoint but the retrieval step returns the wrong chunk, producing visible content drift or inconsistency in the generated frames.
Figures









read the original abstract
Autoregressive video diffusion models have enabled real-time, action-conditioned world generation. However, sustaining a persistent world, where revisiting a previously seen viewpoint yields consistent content, remains an open problem. Full KV-cache attention preserves this consistency but breaks real-time constraints: memory footprint and attention cost grow linearly with rollout length. Sliding window inference restores throughput but discards long-term consistency. We propose WorldKV, a training-free framework with two components: World Retrieval and World Compression. World Retrieval stores evicted KV-cache chunks in GPU/CPU memory and selectively retrieves scene-relevant chunks via camera/ action correspondence, inserting them back into the native attention window without re-encoding. World Compression prunes redundant tokens within each chunk via key-key similarity to an anchor frame, halving per-chunk storage to fit 2x more history under a fixed budget. On Matrix-Game-2.0 and LingBot- World-Fast, WorldKV matches or exceeds full-KV memory fidelity at roughly 2x the throughput, and is competitive with memory-trained baselines without any fine-tuning. Project Page: https://cvlab-kaist.github.io/WorldKV/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes WorldKV, a training-free framework for persistent world consistency in autoregressive video diffusion models. It introduces World Retrieval to store evicted KV-cache chunks and selectively re-insert scene-relevant ones into the attention window using camera/action correspondence (without re-encoding), plus World Compression that prunes redundant tokens within chunks via key-key similarity to an anchor frame. On Matrix-Game-2.0 and LingBot-World-Fast, the method is reported to match or exceed full-KV fidelity at roughly 2x throughput while remaining competitive with memory-trained baselines.
Significance. If the empirical claims hold under rigorous validation, the work would be significant for enabling longer, consistent rollouts in real-time world generation without the linear memory cost of full KV-cache or the inconsistency of sliding windows. The training-free design and parameter-free compression are notable strengths that could allow immediate application to existing models.
major comments (2)
- [World Retrieval] World Retrieval section: the central fidelity claim (matching full-KV at 2x throughput) rests on the assumption that camera/action correspondence alone retrieves the exact historical chunks needed for visual consistency. The manuscript provides no quantitative retrieval metrics (precision/recall vs. ground-truth frames) and no failure-case analysis for ambiguous situations such as repeated viewpoints, dynamic objects, or partial overlaps. Without these, the comparison to full-KV memory cannot be fully substantiated.
- [Experiments] Experimental results: the abstract and evaluation report competitive quantitative results on two named environments but omit error bars, exact definitions of the fidelity metrics, and ablations isolating retrieval failures. These omissions are load-bearing because they directly affect confidence in the 'matches or exceeds' and '2x throughput' claims.
minor comments (2)
- [World Compression] Clarify the precise implementation of key-key similarity pruning in World Compression, including how the anchor frame is chosen and the similarity threshold is set.
- Add a short discussion of memory overhead for storing evicted chunks in GPU/CPU and any practical limits on history length under fixed budgets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment in detail below, offering clarifications based on the design of WorldKV and committing to revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [World Retrieval] World Retrieval section: the central fidelity claim (matching full-KV at 2x throughput) rests on the assumption that camera/action correspondence alone retrieves the exact historical chunks needed for visual consistency. The manuscript provides no quantitative retrieval metrics (precision/recall vs. ground-truth frames) and no failure-case analysis for ambiguous situations such as repeated viewpoints, dynamic objects, or partial overlaps. Without these, the comparison to full-KV memory cannot be fully substantiated.
Authors: We thank the referee for highlighting this aspect. In the evaluated environments (Matrix-Game-2.0 and LingBot-World-Fast), camera poses and actions are explicitly available from the simulator state, allowing World Retrieval to perform exact matching rather than approximate similarity search. When a viewpoint is revisited under matching conditions, the corresponding KV-cache chunk is deterministically retrieved and re-inserted into the attention window. This design directly supports the observed fidelity parity with full KV-cache. For scenarios involving repeated viewpoints, dynamic objects, or partial overlaps, the method retrieves all matching chunks, with World Compression and native attention handling redundancy and consistency. To further substantiate the mechanism, we will add quantitative retrieval metrics (such as precision/recall for exact viewpoint matches against ground-truth history) and a failure-case analysis subsection in the revised manuscript. revision: yes
-
Referee: [Experiments] Experimental results: the abstract and evaluation report competitive quantitative results on two named environments but omit error bars, exact definitions of the fidelity metrics, and ablations isolating retrieval failures. These omissions are load-bearing because they directly affect confidence in the 'matches or exceeds' and '2x throughput' claims.
Authors: We agree that clearer reporting would increase confidence in the results. The fidelity metrics employed are standard image quality measures (PSNR, SSIM, and LPIPS) computed frame-by-frame against environment ground truth. Throughput is measured as frames per second under fixed hardware constraints. In the revision, we will include error bars from multiple random seeds, provide explicit definitions and formulas for all metrics in the experimental section, and add ablations that disable World Retrieval (while retaining compression) to isolate its contribution to long-term consistency. These updates will directly address the load-bearing aspects of the claims. revision: yes
Circularity Check
No circularity: empirical engineering framework with external benchmarks
full rationale
The paper introduces WorldKV as a training-free engineering construction with two components (World Retrieval via camera/action correspondence and World Compression via key-key similarity pruning). All performance claims are framed as empirical matches to full-KV fidelity on Matrix-Game-2.0 and LingBot-World-Fast, without any derivation chain, equations, fitted parameters, or self-referential definitions. No load-bearing step reduces a prediction to its own inputs by construction, and no self-citation is used to justify uniqueness or ansatzes. The framework is therefore self-contained against external validation rather than internally circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zefan Cai, Wen Xiao, Hanshi Sun, Cheng Luo, Yikai Zhang, Ke Wan, Yucheng Li, Yeyang Zhou, Li-Wen Chang, Jiuxiang Gu, et al. R-kv: Redundancy-aware kv cache compression for reasoning models.arXiv preprint arXiv:2505.24133, 2025
-
[2]
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
work page 2024
-
[3]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Ye, Sihyun Yu, Wei-Cheng Tseng, Yuzhu Dong, Kaichun Mo, Chen-Hsuan Lin, Qianli Ma, Seungjun Nah, Loic Magne, Jiannan Xiang, Yuqi Xie, Ruijie Zheng, Dantong Niu, You Liang Tan, K.R. Zentner, George Kurian, Suneel Indupuru, Pooya Jannaty, Jinwei Gu, Jun Zhang, Jitendra Malik, Pieter Abbeel,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Ravi Ghadia, Avinash Kumar, Gaurav Jain, Prashant Nair, and Poulami Das. Dialogue without limits: Constant-sized kv caches for extended responses in llms.arXiv preprint arXiv:2503.00979, 2025
-
[6]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InNeural Information Processing Systems, 2017. URLhttps://api.semanticscholar.org/CorpusID:326772
work page 2017
-
[8]
Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040,
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, et al. Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
-
[9]
Junchao Huang, Xinting Hu, Boyao Han, Shaoshuai Shi, Zhuotao Tian, Tianyu He, and Li Jiang. Mem- ory forcing: Spatio-temporal memory for consistent scene generation on minecraft.arXiv preprint arXiv:2510.03198, 2025
-
[10]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Jiaqi Li, Junshu Tang, Zhiyong Xu, Longhuang Wu, Yuan Zhou, Shuai Shao, Tianbao Yu, Zhiguo Cao, and Qinglin Lu. Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition, 2025. URLhttps://arxiv.org/abs/2506.17201
-
[12]
Runjia Li, Philip Torr, Andrea Vedaldi, and Tomas Jakab. Vmem: Consistent interactive video scene generation with surfel-indexed view memory.arXiv preprint arXiv:2506.18903, 2025
-
[13]
SnapKV: LLM Knows What You are Looking for Before Generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation.arXiv preprint arXiv:2404.14469, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024. doi: 10.1162/tacl_a_00638. URL https://aclanthology.org/2024.tacl-1.9/
-
[16]
Yume-1.5: A text-controlled interactive world generation model.arXiv preprint arXiv:2512.22096,
Xiaofeng Mao, Zhen Li, Chuanhao Li, Xiaojie Xu, Kaining Ying, Tong He, Jiangmiao Pang, Yu Qiao, and Kaipeng Zhang. Yume-1.5: A text-controlled interactive world generation model.arXiv preprint arXiv:2512.22096, 2025
-
[17]
Gen3c: 3d-informed world-consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 11
work page 2025
-
[18]
Solaris: Building a multiplayer video world model in minecraft
Georgy Savva, Oscar Michel, Daohan Lu, Suppakit Waiwitlikhit, Timothy Meehan, Dhairya Mishra, Srivats Poddar, Jack Lu, and Saining Xie. Solaris: Building a multiplayer video world model in minecraft. arXiv preprint arXiv:2602.22208, 2026
-
[19]
Grounding world simulation models in a real-world metropolis.arXiv preprint arXiv:2603.15583, 2026
Junyoung Seo, Hyunwook Choi, Minkyung Kwon, Jinhyeok Choi, Siyoon Jin, Gayoung Lee, Junho Kim, JoungBin Lee, Geonmo Gu, Dongyoon Han, et al. Grounding world simulation models in a real-world metropolis.arXiv preprint arXiv:2603.15583, 2026
-
[20]
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, Tengfei Wang, and Chunchao Guo. Worldplay: Towards long-term geometric consistency for real-time interactive world modeling.arXiv preprint arXiv:2512.14614, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: Query-aware sparsity for efficient long-context llm inference.arXiv preprint arXiv:2406.10774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
InSpatio Team, Donghui Shen, Guofeng Zhang, Haomin Liu, Haoyu Ji, Hujun Bao, Hongjia Zhai, Jialin Liu, Jing Guo, Nan Wang, Siji Pan, Weihong Pan, Weijian Xie, Xianbin Liu, Xiaojun Xiang, Xiaoyu Zhang, Xinyu Chen, Yifu Wang, Yipeng Chen, Zhenzhou Fan, Zhewen Le, Zhichao Ye, and Ziqiang Zhao. Inspatio-world: A real-time 4d world simulator via spatiotemporal...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Advancing Open-source World Models
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, et al. Advancing open-source world models.arXiv preprint arXiv:2601.20540, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Zhou Wang, Alan Conrad Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13:600–612, 2004. URLhttps://api.semanticscholar.org/CorpusID:207761262
work page 2004
-
[26]
Efficient streaming language models with attention sinks.arXiv, 2023
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv, 2023
work page 2023
-
[27]
Worldmem: Long-term consistent world simulation with memory
Zeqi Xiao, LAN Yushi, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xingang Pan. Worldmem: Long-term consistent world simulation with memory. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[28]
LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Yan: Foundational interactive video generation.arXiv preprint arXiv:2508.08601, 2025
Deheng Ye, Fangyun Zhou, Jiacheng Lv, Jianqi Ma, Jun Zhang, Junyan Lv, Junyou Li, Minwen Deng, Mingyu Yang, Qiang Fu, et al. Yan: Foundational interactive video generation.arXiv preprint arXiv:2508.08601, 2025
-
[30]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
H., Nam, J., Yoon, H., and Kim, S
Jung Yi, Wooseok Jang, Paul Hyunbin Cho, Jisu Nam, Heeji Yoon, and Seungryong Kim. Deep forc- ing: Training-free long video generation with deep sink and participative compression.arXiv preprint arXiv:2512.05081, 2025
-
[32]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22963–22974, 2025
work page 2025
-
[33]
Tianyu Yuan, Yuanbo Yang, Lin-Zhuo Chen, Yao Yao, and Zhuzhong Qian. Denoise to track: Harnessing video diffusion priors for robust correspondence.arXiv preprint arXiv:2512.04619, 2025
-
[34]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric.2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 586–595, 2018. URL https://api.semanticscholar.org/CorpusID: 4766599. 12
work page 2018
-
[35]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
work page 2023
-
[36]
Hongzhou Zhu, Min Zhao, Guande He, Hang Su, Chongxuan Li, and Jun Zhu. Causal forcing: Autoregres- sive diffusion distillation done right for high-quality real-time interactive video generation.arXiv preprint arXiv:2602.02214, 2026. 13 Appendix A Selective Retrieval Outperforms Full KV Cache Attention Lingbot-World-Fast2nd Visit3rd visitInput Frame1st Vis...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Top: input video with a fixed camera
Turn Left3) Turn Right1) Turn Right Figure 9: Applying WorldKV to Inspatio-World [22], a video-to-video 4D world model. Top: input video with a fixed camera. Middle: Inspatio-World generates novel-view sequences from the input video but loses scene memory upon revisit. Bottom: with WorldKV applied, the same scene content is preserved consistently across v...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.