Brain-LLM Alignment Tracks Training Data, Not Typology
Pith reviewed 2026-05-25 05:38 UTC · model grok-4.3
The pith
Brain-LLM alignment follows the dominant language in the model's training data, not any special property of English.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
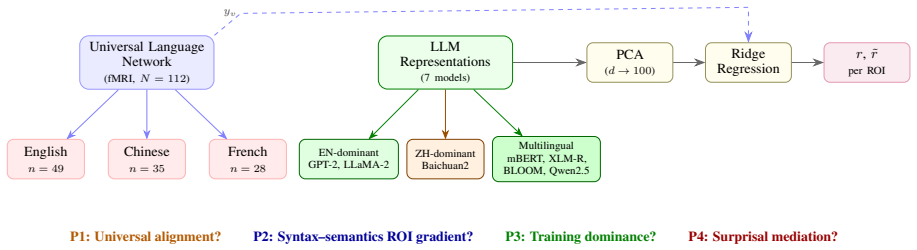
The central discovery is that training-language dominance drives the alignment pattern between LLMs and brains: an architecture-matched Chinese-dominant model aligns best with Chinese brains and worst with English brains, reversing the gradient seen in English-dominant models, while typological distance independently affects alignment degradation and tokenization fertility accounts for much of the cross-linguistic variation in optimal encoding layers.
What carries the argument
The architecture-matched comparison of English-dominant (LLaMA-2-7B) and Chinese-dominant (Baichuan2-7B) LLMs tested against fMRI recordings from the Le Petit Prince corpus in three languages.
If this is right
- Alignment can be made to favor any language by adjusting the training data dominance.
- Typological distance causes additional alignment degradation beyond training effects, with stronger effects in syntax-related brain regions.
- Tokenization differences explain about 60 percent of shifts in which model layer best matches brain activity across languages.
Where Pith is reading between the lines
- Models trained on more balanced multilingual data may achieve more uniform alignment across languages.
- Brain alignment studies should control for training data composition when comparing across languages.
- Improving tokenization for low-resource languages could enhance cross-lingual brain-LLM matching.
Load-bearing premise
The fMRI recordings from the Le Petit Prince corpus provide directly comparable brain signals across English, Chinese, and French speakers after standard preprocessing, and the architecture-matched models differ only in training-data language dominance.
What would settle it
If an architecture-matched model trained predominantly on Chinese data does not show stronger alignment with Chinese brains than with English brains, the claim that training dominance drives the pattern would be falsified.
Figures


read the original abstract
Brain-LLM alignment is well established in English, yet the brain's language network is neuroanatomically universal across languages. Does alignment also generalize cross-linguistically, and what governs the variation? We test this using fMRI data from 112 participants across English, Chinese, and French (the Le Petit Prince corpus) and seven LLMs spanning English-dominant, Chinese-dominant, and multilingual architectures. Our central finding is that training-language dominance, not an inherent property of English, drives the alignment pattern: a Chinese-dominant model (Baichuan2-7B), architecture-matched to LLaMA-2-7B, reverses the gradient entirely, aligning best with Chinese brains and worst with English. Beyond training dominance, formal typological distance independently covaries with alignment degradation, syntax-associated brain regions (IFG) show $2.3\times$ steeper typological gradients than lexico-semantic regions (PTL), and tokenization fertility accounts for $\sim$60% of a cross-linguistic shift in optimal encoding layer. These results reveal that the apparent "English advantage" in brain-LLM alignment is an artifact of training data composition, while the remaining variation reflects genuine typological structure concentrated in syntactic processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that brain-LLM alignment is driven primarily by training-language dominance rather than any inherent property of English. Using fMRI data from 112 participants in the Le Petit Prince corpus (English, Chinese, French) and seven LLMs including architecture-matched pairs (LLaMA-2-7B vs. Baichuan2-7B), it reports that a Chinese-dominant model reverses the alignment gradient, aligning best with Chinese brains. It further claims independent effects of typological distance, 2.3× steeper typological gradients in syntax regions (IFG) than lexico-semantic regions (PTL), and tokenization fertility accounting for ~60% of cross-linguistic shifts in optimal encoding layer.
Significance. If the central reversal result holds after verification of cross-language fMRI comparability, the work would reframe the 'English advantage' in brain-LLM alignment as an artifact of training data composition, while isolating a genuine typological component concentrated in syntactic processing. The architecture-matched model comparison is a methodological strength that isolates training dominance. The findings would inform both cognitive neuroscience of language and the design of multilingual LLMs.
major comments (2)
- [Methods (fMRI data acquisition, preprocessing, and alignment computation)] The reversal claim (Baichuan2-7B aligning best with Chinese and worst with English, opposite to LLaMA-2-7B) is load-bearing and rests on the assumption that alignment scores from the Le Petit Prince fMRI corpus are on a comparable scale across the three language groups after standard preprocessing. The methods section must provide explicit evidence (e.g., group-level BOLD variance comparisons, spatial overlap metrics, or participant-pool controls) that residual differences in signal properties or hemodynamic response do not drive the observed reversal; without this, data-quality artifacts remain a viable alternative explanation.
- [Results (tokenization fertility analysis)] The attribution that tokenization fertility accounts for ~60% of the cross-linguistic shift in optimal encoding layer requires a transparent quantitative decomposition or regression (with equation or procedure) rather than a post-hoc summary statistic. The results section should report the exact model, confidence intervals, and whether the 60% figure is derived from a predictive or explanatory analysis.
minor comments (2)
- [Abstract and Methods] The abstract states '112 participants' but provides no breakdown by language group or demographic details; the methods should include these to allow assessment of power and generalizability.
- [Results (region-specific gradients)] The 2.3× steeper gradient claim for IFG vs. PTL should be accompanied by the precise statistical test, degrees of freedom, and correction for multiple comparisons in the relevant results subsection.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help strengthen the methodological transparency of our work. We address each major comment below and will incorporate revisions as indicated.
read point-by-point responses
-
Referee: [Methods (fMRI data acquisition, preprocessing, and alignment computation)] The reversal claim (Baichuan2-7B aligning best with Chinese and worst with English, opposite to LLaMA-2-7B) is load-bearing and rests on the assumption that alignment scores from the Le Petit Prince fMRI corpus are on a comparable scale across the three language groups after standard preprocessing. The methods section must provide explicit evidence (e.g., group-level BOLD variance comparisons, spatial overlap metrics, or participant-pool controls) that residual differences in signal properties or hemodynamic response do not drive the observed reversal; without this, data-quality artifacts remain a viable alternative explanation.
Authors: We agree that explicit verification of cross-language fMRI comparability is essential to support the reversal result. In the revised manuscript we will add group-level BOLD variance comparisons across the English, Chinese, and French participant groups, along with spatial overlap metrics for the language network ROIs and a brief description of participant-pool controls from the Le Petit Prince corpus. These additions will be placed in the Methods section to demonstrate that residual signal or hemodynamic differences do not account for the observed alignment reversal. revision: yes
-
Referee: [Results (tokenization fertility analysis)] The attribution that tokenization fertility accounts for ~60% of the cross-linguistic shift in optimal encoding layer requires a transparent quantitative decomposition or regression (with equation or procedure) rather than a post-hoc summary statistic. The results section should report the exact model, confidence intervals, and whether the 60% figure is derived from a predictive or explanatory analysis.
Authors: We acknowledge that the current ~60% attribution is presented as a summary statistic and would benefit from greater transparency. In the revision we will expand the Results section to include the exact regression or decomposition procedure (with equation), report confidence intervals, and explicitly state whether the analysis is explanatory or predictive. This will replace the post-hoc summary with a fully documented quantitative breakdown. revision: yes
Circularity Check
No significant circularity; empirical comparisons stand independently
full rationale
The paper reports direct empirical comparisons of brain-LLM alignment scores across architecture-matched models (LLaMA-2-7B vs. Baichuan2-7B) on the same Le Petit Prince fMRI corpus, plus observed covariances with typological distance and tokenization fertility. No equations, self-citations, or definitional steps are shown that reduce any claimed prediction or gradient to a fitted input or prior self-result by construction. The reversal finding and ancillary observations are presented as measurements on external data rather than internal redefinitions, satisfying the default expectation of non-circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Richard J. Antonello and Aditya R. Vaidya and Alexander Huth , editor =. Scaling laws for language encoding models in fMRI , booktitle =. 2023 , burl =
work page 2023
-
[2]
Mariya Toneva and Leila Wehbe , editor =. Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain) , booktitle =. 2019 , burl =
work page 2019
-
[3]
Gabriele Merlin and Mariya Toneva , editor =. Language models and brains align due to more than next-word prediction and word-level information , booktitle =. 2024 , burl =. doi:10.18653/V1/2024.EMNLP-MAIN.1024 , timestamp =
-
[4]
John Hale , title =. Language Technologies 2001: The Second Meeting of the North American Chapter of the Association for Computational Linguistics,. 2001 , burl =
work page 2001
-
[6]
Lost in the Middle: How Language Models Use Long Contexts
Byung. Why Does Surprisal From Larger Transformer-Based Language Models Provide a Poorer Fit to Human Reading Times? , journal =. 2023 , burl =. doi:10.1162/TACL\_A\_00548 , timestamp =
work page internal anchor Pith review doi:10.1162/tacl 2023
-
[7]
Thomas McCoy and Shunyu Yao and Dan Friedman and Matthew Hardy and Thomas L
R. Thomas McCoy and Shunyu Yao and Dan Friedman and Matthew Hardy and Thomas L. Griffiths , title =. arXiv preprint , volume =. 2023 , burl =. doi:10.48550/ARXIV.2309.13638 , beprinttype =
-
[8]
Alexandre Pasquiou and Yair Lakretz and Bertrand Thirion and Christophe Pallier , title =. arXiv preprint , volume =. 2023 , burl =. doi:10.48550/ARXIV.2302.14389 , beprinttype =
-
[9]
Unsupervised Cross-lingual Representation Learning at Scale , booktitle =
Alexis Conneau and Kartikay Khandelwal and Naman Goyal and Vishrav Chaudhary and Guillaume Wenzek and Francisco Guzm. Unsupervised Cross-lingual Representation Learning at Scale , booktitle =. 2020 , burl =. doi:10.18653/V1/2020.ACL-MAIN.747 , timestamp =
-
[10]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin and Ming. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,. 2019 , burl =. doi:10.18653/V1/N19-1423 , timestamp =
-
[11]
Cross-lingual Language Model Pretraining , booktitle =
Alexis Conneau and Guillaume Lample , editor =. Cross-lingual Language Model Pretraining , booktitle =. 2019 , burl =
work page 2019
-
[12]
Emerging Cross-lingual Structure in Pretrained Language Models , booktitle =
Alexis Conneau and Shijie Wu and Haoran Li and Luke Zettlemoyer and Veselin Stoyanov , editor =. Emerging Cross-lingual Structure in Pretrained Language Models , booktitle =. 2020 , burl =. doi:10.18653/V1/2020.ACL-MAIN.536 , timestamp =
-
[13]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Teven Le Scao and Angela Fan and Christopher Akiki and Ellie Pavlick and Suzana Ilic and Daniel Hesslow and Roman Castagn. arXiv preprint , volume =. 2022 , burl =. doi:10.48550/ARXIV.2211.05100 , beprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.05100 2022
-
[14]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie. LLaMA: Open and Efficient Foundation Language Models , journal =. 2023 , burl =. doi:10.48550/ARXIV.2302.13971 , beprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[15]
How Multilingual is Multilingual BERT? , booktitle =
Telmo Pires and Eva Schlinger and Dan Garrette , editor =. How Multilingual is Multilingual BERT? , booktitle =. 2019 , burl =. doi:10.18653/V1/P19-1493 , timestamp =
-
[16]
Baichuan 2: Open Large-scale Language Models
Aiyuan Yang and Bin Xiao and Bingning Wang and Borong Zhang and Ce Bian and Chao Yin and Chenxu Lv and Da Pan and Dian Wang and Dong Yan and Fan Yang and Fei Deng and Feng Wang and Feng Liu and Guangwei Ai and Guosheng Dong and Haizhou Zhao and Hang Xu and Haoze Sun and Hongda Zhang and Hui Liu and Jiaming Ji and Jian Xie and Juntao Dai and Kun Fang and L...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.10305 2023
-
[17]
Mortensen and Ke Lin and Katherine Kairis and Carlisle Turner and Lori S
Patrick Littell and David R. Mortensen and Ke Lin and Katherine Kairis and Carlisle Turner and Lori S. Levin , editor =. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics,. 2017 , burl =. doi:10.18653/V1/E17-2002 , timestamp =
-
[18]
Edoardo Maria Ponti and Helen O'Horan and Yevgeni Berzak and Ivan Vulic and Roi Reichart and Thierry Poibeau and Ekaterina Shutova and Anna Korhonen , title =. Comput. Linguistics , volume =. 2019 , burl =. doi:10.1162/COLI\_A\_00357 , timestamp =
-
[19]
Alexander G. Huth and Wendy A. de Heer and Thomas L. Griffiths and Fr. Natural speech reveals the semantic maps that tile human cerebral cortex , journal =. 2016 , burl =. doi:10.1038/NATURE17637 , timestamp =
-
[20]
Incorporating Context into Language Encoding Models for fMRI , booktitle =
Shailee Jain and Alexander Huth , editor =. Incorporating Context into Language Encoding Models for fMRI , booktitle =. 2018 , burl =
work page 2018
-
[21]
Methods for computing the maximum performance of computational models of fMRI responses , journal =
Agustin Lage. Methods for computing the maximum performance of computational models of fMRI responses , journal =. 2019 , burl =. doi:10.1371/JOURNAL.PCBI.1006397 , timestamp =
-
[22]
Phillip Rust and Jonas Pfeiffer and Ivan Vulic and Sebastian Ruder and Iryna Gurevych , editor =. How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models , booktitle =. 2021 , burl =. doi:10.18653/V1/2021.ACL-LONG.243 , timestamp =
-
[23]
Jasdeep Singh and Bryan McCann and Richard Socher and Caiming Xiong , editor =. Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP, DeepLo@EMNLP-IJCNLP 2019, Hong Kong, China, November 3, 2019 , pages =. 2019 , burl =. doi:10.18653/V1/D19-6106 , timestamp =
-
[24]
Information-Theoretic Probing for Linguistic Structure , booktitle =
Tiago Pimentel and Josef Valvoda and Rowan Hall Maudslay and Ran Zmigrod and Adina Williams and Ryan Cotterell , editor =. Information-Theoretic Probing for Linguistic Structure , booktitle =. 2020 , burl =. doi:10.18653/V1/2020.ACL-MAIN.420 , timestamp =
-
[25]
Charlotte Caucheteux and Alexandre Gramfort and Jean. Model-based analysis of brain activity reveals the hierarchy of language in 305 subjects , booktitle =. 2021 , burl =. doi:10.18653/V1/2021.FINDINGS-EMNLP.308 , timestamp =
-
[26]
Hale and Bertrand Thirion and Christophe Pallier , editor =
Alexandre Pasquiou and Yair Lakretz and John T. Hale and Bertrand Thirion and Christophe Pallier , editor =. Neural Language Models are not Born Equal to Fit Brain Data, but Training Helps , booktitle =. 2022 , burl =
work page 2022
-
[27]
Neural Language Taskonomy: Which
Subba Reddy Oota and Jashn Arora and Veeral Agarwal and Mounika Marreddy and Manish Gupta and Bapi Raju Surampudi , editor =. Neural Language Taskonomy: Which. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,. 2022 , burl =. doi:10.18653/V1/2022.NAACL-MAIN.235 ,...
-
[28]
Chi and John Hewitt and Christopher D
Ethan A. Chi and John Hewitt and Christopher D. Manning , editor =. Finding Universal Grammatical Relations in Multilingual. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics,. 2020 , burl =. doi:10.18653/V1/2020.ACL-MAIN.493 , timestamp =
-
[29]
Robust Evaluation of Language-Brain Encoding Experiments , booktitle =
Lisa Beinborn and Samira Abnar and Rochelle Choenni , editor =. Robust Evaluation of Language-Brain Encoding Experiments , booktitle =. 2019 , burl =. doi:10.1007/978-3-031-24337-0\_4 , timestamp =
-
[30]
Ponti and Lucas Torroba Hennigen and Ryan Cotterell and Isabelle Augenstein , editor =
Karolina Stanczak and Edoardo M. Ponti and Lucas Torroba Hennigen and Ryan Cotterell and Isabelle Augenstein , editor =. Same Neurons, Different Languages: Probing Morphosyntax in Multilingual Pre-trained Models , booktitle =. 2022 , burl =. doi:10.18653/V1/2022.NAACL-MAIN.114 , timestamp =
-
[31]
Ryan Cotterell and S. J. Mielke and Jason Eisner and Brian Roark , editor =. Are All Languages Equally Hard to Language-Model? , booktitle =. 2018 , burl =. doi:10.18653/V1/N18-2085 , timestamp =
-
[32]
Fedorenko, Evelina and Ivanova, Anna A. and Regev, Tamar I. , year =. The language network as a natural kind within the broader landscape of the human brain , volume =. Nature Reviews Neuroscience , publisher =. doi:10.1038/s41583-024-00802-4 , number =
-
[33]
Malik-Moraleda, Saima and Ayyash, Dima and Gallée, Jeanne and Affourtit, Josef and Hoffmann, Malte and Mineroff, Zachary and Jouravlev, Olessia and Fedorenko, Evelina , year =. An investigation across 45 languages and 12 language families reveals a universal language network , volume =. Nature Neuroscience , publisher =. doi:10.1038/s41593-022-01114-5 , number =
-
[34]
Proceedings of the National Academy of Sciences , year =
The neural architecture of language: Integrative modeling converges on predictive processing , author =. Proceedings of the National Academy of Sciences , year =. doi:10.1073/pnas.2105646118 , pmid =
-
[35]
Goldstein, Ariel and Zada, Zaid and Buchnik, Eliav and Schain, Mariano and Price, Amy and Aubrey, Bobbi and Nastase, Samuel A. and Feder, Amir and Emanuel, Dotan and Cohen, Alon and Jansen, Aren and Gazula, Harshvardhan and Choe, Gina and Rao, Aditi and Kim, Catherine and Casto, Colton and Fanda, Lora and Doyle, Werner and Friedman, Daniel and Dugan, Patr...
-
[36]
Brains and algorithms partially converge in natural language processing , volume =
Caucheteux, Charlotte and King, Jean-Rémi , year =. Brains and algorithms partially converge in natural language processing , volume =. Communications Biology , publisher =. doi:10.1038/s42003-022-03036-1 , number =
-
[37]
Language in Brains, Minds, and Machines , volume =
Tuckute, Greta and Kanwisher, Nancy and Fedorenko, Evelina , year =. Language in Brains, Minds, and Machines , volume =. Annual Review of Neuroscience , publisher =. doi:10.1146/annurev-neuro-120623-101142 , number =
-
[38]
Nature Human Behaviour , year =
Driving and suppressing the human language network using large language models , author =. Nature Human Behaviour , year =. doi:10.1038/s41562-023-01783-7 , pmid =
-
[39]
Antonello, Richard and Huth, Alexander , year =. Predictive Coding or Just Feature Discovery? An Alternative Account of Why Language Models Fit Brain Data , issn =. doi:10.1162/nol_a_00087 , journal =
-
[40]
Evidence of a predictive coding hierarchy in the human brain listening to speech , volume =
Caucheteux, Charlotte and Gramfort, Alexandre and King, Jean-Rémi , year =. Evidence of a predictive coding hierarchy in the human brain listening to speech , volume =. Nature Human Behaviour , publisher =. doi:10.1038/s41562-022-01516-2 , number =
-
[41]
Proceedings of the National Academy of Sciences , year =
A hierarchy of linguistic predictions during natural language comprehension , author =. Proceedings of the National Academy of Sciences , year =. doi:10.1073/pnas.2201968119 , pmid =
-
[42]
Semantic reconstruction of continuous language from non-invasive brain recordings , author =. Nature Neuroscience , year =. doi:10.1038/s41593-023-01304-9 , pmid =
-
[43]
Neurobiology of Language , year =
Artificial Neural Network Language Models Predict Human Brain Responses to Language Even After a Developmentally Realistic Amount of Training , author =. Neurobiology of Language , year =. doi:10.1162/nol_a_00137 , pmid =
-
[44]
Lexical-Semantic Content, Not Syntactic Structure, Is the Main Contributor to
Kauf, Carina and Tuckute, Greta and Levy, Roger and Andreas, Jacob and Fedorenko, Evelina , journal =. Lexical-Semantic Content, Not Syntactic Structure, Is the Main Contributor to. 2024 , volume =
work page 2024
-
[45]
de Varda, Andrea Gregor and Malik-Moraleda, Saima and Tuckute, Greta and Fedorenko, Evelina , title =. 2025 , doi =
work page 2025
-
[46]
Expectation-based syntactic comprehension , author =. Cognition , year =
-
[47]
Proceedings of the National Academy of Sciences , year =
Large-scale evidence for logarithmic effects of word predictability on reading time , author =. Proceedings of the National Academy of Sciences , year =
-
[48]
Michaelov, James A. and Bardolph, Megan D. and Van Petten, Cyma K. and Bergen, Benjamin K. and Coulson, Seana , year =. Strong Prediction: Language Model Surprisal Explains Multiple N400 Effects , volume =. Neurobiology of Language , publisher =. doi:10.1162/nol_a_00105 , number =
-
[49]
Frank, Stefan L. and Otten, Leun J. and Galli, Giulia and Vigliocco, Gabriella , year =. The ERP response to the amount of information conveyed by words in sentences , volume =. doi:10.1016/j.bandl.2014.10.006 , journal =
-
[50]
Mahowald, Kyle and Ivanova, Anna A. and Blank, Idan A. and Kanwisher, Nancy and Tenenbaum, Joshua B. and Fedorenko, Evelina , title =. Trends in Cognitive Sciences , year =. doi:10.1016/j.tics.2024.01.011 , pmid =
-
[51]
Kanishka Misra and Kyle Mahowald , title =. arXiv preprint , volume =. 2024 , burl =. doi:10.48550/ARXIV.2403.19827 , beprinttype =
-
[52]
Constructions and Frames , year =
Usage-based constructionist approaches and large language models , author =. Constructions and Frames , year =
-
[53]
Oxford Univer- sity Press (2018).https://doi.org/10.1093/oso/9780198814788.001.0001
Croft, William , year =. Radical Construction Grammar: Syntactic Theory in Typological Perspective , isbn =. doi:10.1093/acprof:oso/9780198299554.001.0001 , publisher =
-
[54]
Scale-Free Networks: Complex Webs in Nature and Technology
Goldberg, Adele , year =. Constructions at Work: The Nature of Generalization in Language , isbn =. doi:10.1093/acprof:oso/9780199268511.001.0001 , publisher =
-
[55]
First Align, then Predict: Understanding the Cross-Lingual Ability of Multilingual
Benjamin Muller and Yanai Elazar and Beno. First Align, then Predict: Understanding the Cross-Lingual Ability of Multilingual. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume,. 2021 , burl =. doi:10.18653/V1/2021.EACL-MAIN.189 , timestamp =
-
[56]
On the Language Neutrality of Pre-trained Multilingual Representations , booktitle =
Jindrich Libovick. On the Language Neutrality of Pre-trained Multilingual Representations , booktitle =. 2020 , burl =. doi:10.18653/V1/2020.FINDINGS-EMNLP.150 , timestamp =
-
[57]
Skirgård, Hedvig and Haynie, Hannah J. and Blasi, Damián E. and Hammarström, Harald and Collins, Jeremy and Latarche, Jay J. and Lesage, Jakob and Weber, Tobias and Witzlack-Makarevich, Alena and Passmore, Sam and Chira, Angela and Maurits, Luke and Dinnage, Russell and Dunn, Michael and Reesink, Ger and Singer, Ruth and Bowern, Claire and Epps, Patience ...
-
[58]
and Haspelmath, Martin , booktitle =
Dryer, Matthew S. and Haspelmath, Martin , booktitle =. 2013 , doi =
work page 2013
-
[59]
Evans, Nicholas and Levinson, Stephen C. , year =. The myth of language universals: Language diversity and its importance for cognitive science , volume =. Behavioral and Brain Sciences , publisher =. doi:10.1017/s0140525x0999094x , number =
-
[60]
Mitchell, Tom M. and Shinkareva, Svetlana V. and Carlson, Andrew and Chang, Kai-Min and Malave, Vicente L. and Mason, Robert A. and Just, Marcel Adam , year =. Predicting Human Brain Activity Associated with the Meanings of Nouns , volume =. Science , publisher =. doi:10.1126/science.1152876 , number =
-
[61]
Nastase, Samuel A. and Liu, Yun-Fei and Hillman, Hanna and Zadbood, Asieh and Hasenfratz, Liat and Keshavarzian, Neggin and Chen, Janice and Honey, Christopher J. and Yeshurun, Yaara and Regev, Mor and Nguyen, Mai and Chang, Claire H. C. and Baldassano, Christopher and Lositsky, Olga and Simony, Erez and Chow, Michael A. and Leong, Yuan Chang and Brooks, ...
-
[62]
Fedorenko, Evelina and Behr, Michael K. and Kanwisher, Nancy , year =. Functional specificity for high-level linguistic processing in the human brain , volume =. Proceedings of the National Academy of Sciences , publisher =. doi:10.1073/pnas.1112937108 , number =
-
[63]
and Fedorenko, Evelina , title =
Blank, Idan A. and Fedorenko, Evelina , title =. The Journal of Neuroscience , year =. doi:10.1523/JNEUROSCI.3642-16.2017 , url =
-
[64]
The cortical organization of speech processing , volume =
Hickok, Gregory and Poeppel, David , year =. The cortical organization of speech processing , volume =. Nature Reviews Neuroscience , publisher =. doi:10.1038/nrn2113 , number =
-
[65]
Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks , author =. Neuron , year =. doi:10.1016/j.neuron.2019.12.002 , pmid =
-
[66]
The neural basis of first and second language processing , volume =
Perani, Daniela and Abutalebi, Jubin , year =. The neural basis of first and second language processing , volume =. Current Opinion in Neurobiology , publisher =. doi:10.1016/j.conb.2005.03.007 , number =
-
[67]
and Fedorenko, Evelina , journal =
Malik-Moraleda, Saima and Jouravlev, Olessia and Taliaferro, Maya and Mineroff, Zachary and Cucu, Theodore and Mahowald, Kyle and Blank, Idan A. and Fedorenko, Evelina , journal =. Functional characterization of the language network of polyglots and hyperpolyglots with precision. 2024 , volume =. doi:10.1093/cercor/bhae049 , pmid =
-
[68]
Green, David W. and Abutalebi, Jubin , year =. Language control in bilinguals: The adaptive control hypothesis , volume =. Journal of Cognitive Psychology , publisher =. doi:10.1080/20445911.2013.796377 , number =
-
[69]
Nathan and Brennan, Jonathan R
Li, Jixing and Bhattasali, Shohini and Zhang, Shulin and Franzluebbers, Berta and Luh, Wen-Ming and Spreng, R. Nathan and Brennan, Jonathan R. and Yang, Yiming and Pallier, Christophe and Hale, John , year =. Le Petit Prince multilingual naturalistic fMRI corpus , volume =. Scientific Data , publisher =. doi:10.1038/s41597-022-01625-7 , number =
-
[70]
Momenian, Mohammad and Ma, Zhengwu and Wu, Shuyi and Wang, Chengcheng and Brennan, Jonathan and Hale, John and Meyer, Lars and Li, Jixing , journal =. Le. 2024 , volume =. doi:10.1038/s41597-024-03745-8 , pmid =
-
[71]
The Little Prince in 26 Languages: Towards a Multilingual Neuro-Cognitive Corpus
Stehwien, Sabrina and Henke, Lena and Hale, John and Brennan, Jonathan and Meyer, Lars. The Little Prince in 26 Languages: Towards a Multilingual Neuro-Cognitive Corpus. Proceedings of the Second Workshop on Linguistic and Neurocognitive Resources. 2020
work page 2020
-
[72]
and Kalaitzi, Areti and Kwon, Nayoung and Lõo, Kaidi and Marelli, Marco and Papadopoulos, Timothy C
Siegelman, Noam and Schroeder, Sascha and Acartürk, Cengiz and Ahn, Hee-Don and Alexeeva, Svetlana and Amenta, Simona and Bertram, Raymond and Bonandrini, Rolando and Brysbaert, Marc and Chernova, Daria and Da Fonseca, Sara Maria and Dirix, Nicolas and Duyck, Wouter and Fella, Argyro and Frost, Ram and Gattei, Carolina A. and Kalaitzi, Areti and Kwon, Nay...
-
[73]
Juliette Millet and Charlotte Caucheteux and Pierre Orhan and Yves Boubenec and Alexandre Gramfort and Ewan Dunbar and Christophe Pallier and Jean. Toward a realistic model of speech processing in the brain with self-supervised learning , booktitle =. 2022 , burl =
work page 2022
-
[74]
Deep language algorithms predict semantic comprehension from brain activity , volume =
Caucheteux, Charlotte and Gramfort, Alexandre and King, Jean-Rémi , year =. Deep language algorithms predict semantic comprehension from brain activity , volume =. Scientific Reports , publisher =. doi:10.1038/s41598-022-20460-9 , number =
-
[75]
Smith, Nathaniel J. and Levy, Roger , year =. The effect of word predictability on reading time is logarithmic , volume =. Cognition , publisher =. doi:10.1016/j.cognition.2013.02.013 , number =
-
[76]
Snijders, Tom A. B. and Bosker, Roel J. , title =. 2012 , isbn =
work page 2012
- [77]
-
[78]
Bergen, Benjamin K. and Chang, Nancy , year =. Embodied Construction Grammar in simulation-based language understanding , isbn =. doi:10.1075/cal.3.08ber , booktitle =
-
[79]
CELER: A 365-Participant Corpus of Eye Movements in L1 and L2 English Reading , volume =
Berzak, Yevgeni and Nakamura, Chie and Smith, Amelia and Weng, Emily and Katz, Boris and Flynn, Suzanne and Levy, Roger , year =. CELER: A 365-Participant Corpus of Eye Movements in L1 and L2 English Reading , volume =. doi:10.1162/opmi_a_00054 , journal =
-
[80]
An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu and Mei Li and Mi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[81]
Nature Communications , title =
Stéphane d’Ascoli and Corentin Bel and Jérémy Rapin and Hubert Banville and Yohann Benchetrit and Christophe Pallier and Jean Rémi King , doi =. Nature Communications , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.