The Time is Here for Just-in-Time Systems: Challenges and Opportunities
Pith reviewed 2026-06-30 14:53 UTC · model grok-4.3
The pith
LLM agents can synthesize specialized key-value stores that outperform general systems on every workload tested.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
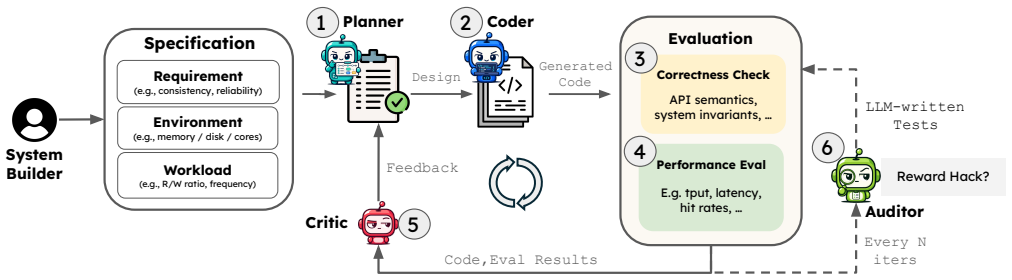
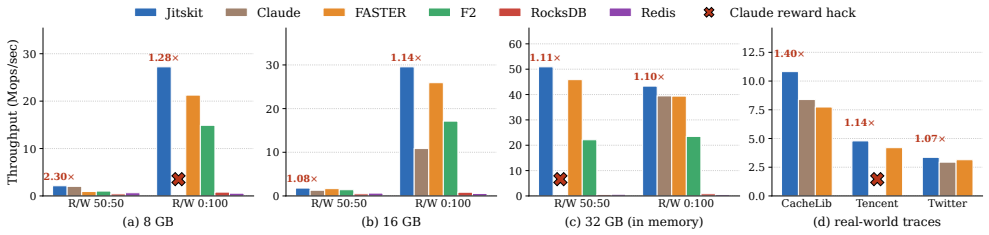
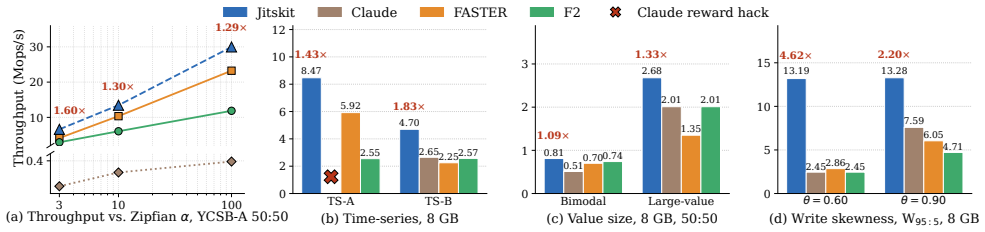
We argue that LLM-based coding agents now make Just-in-Time Systems tractable, in which the entire system is synthesized from scratch, specialized to the environment, workload, and required system properties. We present a JIT system synthesis pipeline, Jitskit, that iteratively refines a system implementation to match the specification against an evolving evaluation test suite. The resulting synthesized systems are performant, beating comparable state-of-the-art systems on 18 of 18 specs tried, by up to 4.6x over the best off-the-shelf baseline on the most favorable spec. Naively running Claude Code either reward-hacks or underperforms Jitskit by up to 5.4x.
What carries the argument
Jitskit, the iterative refinement pipeline that generates and tunes system code from spec cards spanning workloads, constraints, and properties using an evolving test suite.
If this is right
- Systems can be generated on demand for specific YCSB workloads, compute limits, consistency levels, and durability requirements.
- Performance reaches up to 4.6 times better than the strongest off-the-shelf baseline across all 18 evaluated specifications.
- Standard LLM usage without the Jitskit refinement loop either produces reward-hacking behavior or lags behind by as much as 5.4 times.
- Core systems no longer require years of general-purpose development when synthesis targets exact operating conditions.
Where Pith is reading between the lines
- The same synthesis loop could be applied to other core systems such as databases or schedulers once comparable spec cards and test suites exist.
- Long-term maintainability may suffer if synthesized code grows complex without human-readable structure, even if short-term tests pass.
- Security audits would need to expand beyond functional tests to catch issues introduced during LLM-driven refinement.
- Deployment pipelines could shift from selecting among existing systems to generating and validating a fresh one per environment.
Load-bearing premise
The iterative refinement process produces functionally correct code without introducing subtle bugs or security issues that the test suite fails to detect.
What would settle it
A deployment of a Jitskit-generated key-value store that passes every test in the suite yet exhibits incorrect behavior, data loss, or crashes under real workload conditions the suite did not cover.
Figures



read the original abstract
Core systems like key-value stores have historically taken years to build, and are designed to be general so as to amortize cost across deployments, paying a significant performance cost. We argue that LLM-based coding agents now make a different approach tractable: Just-in-Time Systems, in which the entire system is synthesized from scratch, specialized to the environment, workload, and required system properties. We present a JIT system synthesis pipeline, Jitskit, and explore its effectiveness in synthesizing key-value stores from spec cards that span different YCSB workloads, deployment constraints (e.g., compute resources), and system properties (e.g., consistency and durability). Jitskit iteratively refines a system implementation to match the specification against an evolving evaluation test suite. The resulting synthesized systems are performant, beating comparable state-of-the-art systems on 18 of 18 specs tried, by up to 4.6x over the best off-the-shelf baseline on the most favorable spec. Naively running Claude Code either reward-hacks or underperforms Jitskit by up to 5.4x. We discuss the challenges we overcame in building Jitskit and our key takeaways.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that LLM-based coding agents now enable 'Just-in-Time Systems' in which complete systems such as key-value stores are synthesized from scratch and specialized to a given workload, deployment constraints, and required properties (consistency, durability). It introduces the Jitskit pipeline, which iteratively refines candidate implementations against an evolving test suite derived from spec cards that encode YCSB workloads plus system properties. The central empirical claim is that the resulting synthesized KV stores outperform comparable state-of-the-art systems on all 18 evaluated specs, with speedups reaching 4.6× over the best off-the-shelf baseline on the most favorable spec, while naive use of Claude Code either reward-hacks or underperforms by up to 5.4×.
Significance. If the correctness and performance claims hold under rigorous verification, the work would be significant for the systems community: it supplies concrete evidence that LLM-driven synthesis can produce specialized, high-performance implementations that avoid the overhead of general-purpose designs. The explicit comparison against a naive LLM baseline and the discussion of practical challenges overcome in building Jitskit are useful contributions. The approach also supplies a reproducible experimental template (spec cards, iterative refinement loop) that future work could extend.
major comments (2)
- [Evaluation section] Evaluation section: the headline claim that the synthesized systems beat SOTA on 18/18 specs (and the associated 4.6× number) is load-bearing for the paper's thesis. The manuscript states that Jitskit relies on iterative refinement against an evolving test suite, yet provides no quantitative evidence on test-suite coverage for the durability and consistency properties listed in the spec cards (e.g., crash-recovery sequences, concurrent durability violations, or resource-constraint edge cases). Without such coverage data or an independent verification oracle, it is impossible to rule out that some of the reported speedups are measured on implementations that pass the available tests but contain latent bugs absent from the production baselines.
- [Experimental setup] Experimental setup (baseline comparison): the statement that the synthesized systems beat 'comparable state-of-the-art systems' on every spec requires a clear definition of which off-the-shelf KV stores were chosen, how they were configured under the same resource constraints, and whether any tuning was applied to the baselines that was not also applied to the synthesized code. The current description leaves open the possibility that the 18/18 win rate partly reflects unequal experimental conditions rather than intrinsic superiority of the JIT approach.
minor comments (1)
- [Abstract / Introduction] The abstract and introduction would benefit from a short table or bullet list that enumerates the 18 spec cards (workload + constraint + property combinations) so readers can immediately see the diversity of the evaluation.
Simulated Author's Rebuttal
Thank you for the constructive referee report and the recommendation for major revision. We value the emphasis on strengthening the evaluation rigor and clarifying the experimental setup. We address each major comment below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: the headline claim that the synthesized systems beat SOTA on 18/18 specs (and the associated 4.6× number) is load-bearing for the paper's thesis. The manuscript states that Jitskit relies on iterative refinement against an evolving test suite, yet provides no quantitative evidence on test-suite coverage for the durability and consistency properties listed in the spec cards (e.g., crash-recovery sequences, concurrent durability violations, or resource-constraint edge cases). Without such coverage data or an independent verification oracle, it is impossible to rule out that some of the reported speedups are measured on implementations that pass the available tests but contain latent bugs absent from the production baselines.
Authors: We agree that the absence of quantitative test-suite coverage metrics is a limitation that weakens confidence in the correctness of the synthesized systems. The manuscript describes the iterative refinement against an evolving test suite derived from spec cards but does not report coverage statistics for properties such as crash-recovery sequences or concurrent durability checks. In the revised manuscript, we will add a dedicated subsection under Evaluation that provides these metrics (e.g., number of crash scenarios, consistency violation tests, and resource edge cases exercised per spec card) and explains how the test generation targets the spec properties. This will allow readers to better assess whether the reported speedups reflect correct, specialized implementations. revision: yes
-
Referee: [Experimental setup] Experimental setup (baseline comparison): the statement that the synthesized systems beat 'comparable state-of-the-art systems' on every spec requires a clear definition of which off-the-shelf KV stores were chosen, how they were configured under the same resource constraints, and whether any tuning was applied to the baselines that was not also applied to the synthesized code. The current description leaves open the possibility that the 18/18 win rate partly reflects unequal experimental conditions rather than intrinsic superiority of the JIT approach.
Authors: We agree that the current description of baselines lacks sufficient detail to rule out unequal conditions. The intent was to compare against standard off-the-shelf KV stores (such as RocksDB and LevelDB) under identical resource constraints from the spec cards, using only their documented default or standard configurations without extra per-workload tuning. In the revised manuscript, we will expand the Experimental Setup section with a new 'Baselines' subsection that explicitly lists the chosen systems and versions, details the configuration parameters applied to match each spec's resource limits, and confirms that no differential tuning was performed. This will make the 18/18 comparison transparent and reproducible. revision: yes
Circularity Check
No circularity: empirical benchmarking of synthesized systems
full rationale
The paper reports an empirical pipeline (Jitskit) that synthesizes KV stores via iterative LLM refinement against test suites and measures wall-clock performance on YCSB workloads. No equations, derivations, fitted parameters, or self-citations appear in the provided text. The 18/18 success and 4.6x speedup claims are direct experimental outcomes, not reductions of any claimed prediction back to its own inputs by construction. The work is therefore self-contained against external baselines and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
N-Version Programming with Coding Agents
Diverse AI coding agents in N-version programming reduce mean failures from 387.44 to 130.99 in triples on the Launch Interceptor Program, with 11,844 zero-failure units observed across 1M tests.
Reference graph
Works this paper leans on
-
[1]
Anderson et al
Thomas E. Anderson et al. Self-defining systems. UW FOCI Whitepaper, 2025. https://foci.uw.edu/pa pers/whitepaper2025-sds.pdf
2025
-
[2]
Claude Code
Anthropic. Claude Code. https://www.anthropic. com/claude-code, 2025
2025
-
[3]
Berger, Sara McAllister, Isaac Grosof, Sathya Gunasekar, Jimmy Kim, Aaron Taylor, Daniel McVicker, Alexey Tumanov, Michael R
Benjamin Berg, Daniel S. Berger, Sara McAllister, Isaac Grosof, Sathya Gunasekar, Jimmy Kim, Aaron Taylor, Daniel McVicker, Alexey Tumanov, Michael R. Kozuch, and Mor Harchol-Balter. The CacheLib caching engine: Design and experiences at scale. InProceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 753–768, 2020
2020
-
[4]
Building a C compiler with a team of parallel Claudes
Nicholas Carlini. Building a C compiler with a team of parallel Claudes. Anthropic Engineering Blog, 2026. https://www.anthropic.com/engineering/buil ding-c-compiler
2026
-
[5]
Faster: A concurrent key-value store with in-place updates
Badrish Chandramouli, Guna Prasaad, Donald Koss- mann, Justin Levandoski, James Hunter, and Mike Bar- nett. Faster: A concurrent key-value store with in-place updates. InProceedings of the 2018 International Con- ference on Management of Data, pages 275–290, 2018
2018
-
[6]
Cosine: A cloud-cost optimized self- designing key-value storage engine.Proceedings of the VLDB Endowment, 15(1):112–126, 2022
Subarna Chatterjee, Meena Jagadeesan, Wilson Qin, and Stratos Idreos. Cosine: A cloud-cost optimized self- designing key-value storage engine.Proceedings of the VLDB Endowment, 15(1):112–126, 2022
2022
-
[7]
Narasayya
Surajit Chaudhuri and Vivek R. Narasayya. An effi- cient, cost-driven index selection tool for Microsoft SQL Server. InProceedings of the 23rd International Confer- ence on Very Large Data Bases (VLDB), pages 146–155, 1997
1997
-
[8]
Let the barbarians in: How ai can accelerate systems performance research
Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Shub- ham Agarwal, Mert Cemri, Bowen Wang, Alexander Krentsel, Tian Xia, Jongseok Park, et al. Let the bar- barians in: How ai can accelerate systems performance research.arXiv preprint arXiv:2512.14806, 2025
-
[9]
Benchmarking cloud serving systems with ycsb
Brian F Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears. Benchmarking cloud serving systems with ycsb. InProceedings of the 1st ACM symposium on Cloud computing, pages 143–154, 2010
2010
-
[10]
RocksDB: Evolution of development priorities in a key-value store serving large-scale applications
Siying Dong, Andrew Kryczka, Yanqin Jin, and Michael Stumm. RocksDB: Evolution of development priorities in a key-value store serving large-scale applications. ACM Transactions on Storage, 17(4):1–32, 2021
2021
-
[11]
Tuning database configuration parameters with iTuned.Proceedings of the VLDB Endowment, 2(1):1246–1257, 2009
Songyun Duan, Vamsidhar Thummala, and Shivnath Babu. Tuning database configuration parameters with iTuned.Proceedings of the VLDB Endowment, 2(1):1246–1257, 2009
2009
-
[12]
TinyLFU: A highly efficient cache admission policy.ACM Trans- actions on Storage, 13:35:1–35:31, 2017
Gil Einziger, Roy Friedman, and Ben Manes. TinyLFU: A highly efficient cache admission policy.ACM Trans- actions on Storage, 13:35:1–35:31, 2017
2017
-
[13]
Eisenbud, Cheng Yi, Carlo Contavalli, Cody Smith, Roman Kishi, Ardas Warrier, et al
Daniel E. Eisenbud, Cheng Yi, Carlo Contavalli, Cody Smith, Roman Kishi, Ardas Warrier, et al. Maglev: A fast and reliable software network load balancer. In Proceedings of the 13th USENIX Symposium on Net- worked Systems Design and Implementation (NSDI), pages 523–535, 2016
2016
-
[14]
Distributed caching with Memcached
Brad Fitzpatrick. Distributed caching with Memcached. Linux Journal, 2004(124):5, 2004
2004
-
[15]
Glia: A Human-Inspired AI for Automated Systems Design and Optimization
Pouya Hamadanian, Pantea Karimi, Arash Nasr- Esfahany, Kimia Noorbakhsh, Joseph Chandler, Ali ParandehGheibi, Mohammad Alizadeh, and Hari Bal- akrishnan. Glia: A human-inspired AI for automated systems design and optimization.arXiv preprint arXiv:2510.27176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Hiagent: Hierarchical work- ing memory management for solving long-horizon agent tasks with large language model
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. Hiagent: Hierarchical work- ing memory management for solving long-horizon agent tasks with large language model. InProceedings of the 63rd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), pages 32779–32798, 2025
2025
-
[17]
De- sign continuums and the path toward self-designing key- value stores that know and learn
Stratos Idreos, Niv Dayan, Wilson Qin, Mali Akmanalp, Sophie Hilgard, Andrew Ross, James Lennon, Varun Jain, Harshita Gupta, David Li, and Zichen Zhu. De- sign continuums and the path toward self-designing key- value stores that know and learn. InProceedings of the 9th Biennial Conference on Innovative Data Systems Research (CIDR), 2019
2019
-
[18]
Kester, and Demi Guo
Stratos Idreos, Kostas Zoumpatianos, Brian Hentschel, Michael S. Kester, and Demi Guo. The data calculator: Data structure design and cost synthesis from first prin- ciples and learned cost models. InProceedings of the 13 2018 International Conference on Management of Data (SIGMOD), pages 535–550. ACM, 2018
2018
-
[19]
Congestion avoidance and control
Van Jacobson. Congestion avoidance and control. ACM SIGCOMM Computer Communication Review, 18(4):314–329, 1988
1988
-
[20]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[21]
Konstantinos Kanellis, Badrish Chandramouli, Ted Hart, and Shivaram Venkataraman. From faster to f2: Evolv- ing concurrent key-value store designs for large skewed workloads.arXiv preprint arXiv:2305.01516, 2023
-
[22]
Clos- ing the verification loop: Observability-driven harnesses for building with agents
Alp Keles, Jai Menon, Sesh Nalla, and Vyom Shah. Clos- ing the verification loop: Observability-driven harnesses for building with agents. https://www.datadogh q.com/blog/ai/harness-first-agents/ , 2026. Datadog Engineering Blog, March 2026
2026
-
[23]
Towards instance-optimized data systems
Tim Kraska. Towards instance-optimized data systems. Proceedings of the VLDB Endowment, 14(12):3222– 3232, 2021
2021
-
[24]
Chi, Ani Kristo, Guillaume Leclerc, Samuel Madden, Hongzi Mao, and Vikram Nathan
Tim Kraska, Mohammad Alizadeh, Alex Beutel, Ed H. Chi, Ani Kristo, Guillaume Leclerc, Samuel Madden, Hongzi Mao, and Vikram Nathan. SageDB: A learned database system. InProceedings of the 9th Biennial Con- ference on Innovative Data Systems Research (CIDR), 2019
2019
-
[25]
Chi, Jeffrey Dean, and Neoklis Polyzotis
Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, and Neoklis Polyzotis. The case for learned index structures. InProceedings of the 2018 International Conference on Management of Data (SIGMOD), pages 489–504. ACM, 2018
2018
-
[26]
Measuring AI ability to complete long tasks
Thomas Kwa, Ben West, Joel Becker, Amy Deng, Katharyn Garcia, Max Hasin, Sami Jawhar, Megan Kin- niment, Nate Rush, Sydney V on Arx, et al. Measuring AI ability to complete long tasks. METR Blog, 2025. https://metr.org/blog/2025-03-19-measuring -ai-ability-to-complete-long-tasks/
2025
-
[27]
The Vertica analytic database: C-store 7 years later
Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan, Nga Tran, Ben Vandiver, Lyric Doshi, and Chuck Bear. The Vertica analytic database: C-store 7 years later. In Proceedings of the VLDB Endowment, volume 5, pages 1790–1801, 2012
2012
-
[28]
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
Robert Tjarko Lange, Jakob Foerster, and David Ha. ShinkaEvolve: Towards open-ended and sample- efficient program evolution, 2025. https://arxiv.or g/abs/2509.19349
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Bentley, Samuel Bernard, Guillaume Beslon, et al
Joel Lehman, Jeff Clune, Dusan Misevic, Christoph Adami, Lee Altenberg, Julie Beaulieu, Peter J. Bentley, Samuel Bernard, Guillaume Beslon, et al. The surprising creativity of digital evolution: A collection of anecdotes from the evolutionary computation and artificial life research communities.Artificial Life, 26(2):274–306, 2020
2020
-
[30]
Skydiscover: A flexible framework for ai-driven scientific and algorithmic discovery.URL: https: //skydiscover-ai.github.io/blog.html , 2026
Shu Liu, Mert Cemri, Shubham Agarwal, Alexander Krentsel, Ashwin Naren, Qiuyang Mang, Zhifei Li, Ak- shat Gupta, Monishwaran Maheswaran, Audrey Cheng, et al. Skydiscover: A flexible framework for ai-driven scientific and algorithmic discovery.URL: https: //skydiscover-ai.github.io/blog.html , 2026
2026
-
[31]
Context as a tool: Context management for long-horizon swe-agents,
Shukai Liu, Jian Yang, Bo Jiang, Yizhi Li, Jinyang Guo, Xianglong Liu, and Bryan Dai. Context as a tool: Con- text management for long-horizon swe-agents.arXiv preprint arXiv:2512.22087, 2025
-
[32]
Mankowitz, Andrea Michi, Anton Zhernov, Marco Gelmi, Marco Selvi, Cosmin Paduraru, Edouard Leurent, Shariq Iqbal, Jean-Baptiste Lespiau, Alex Ah- ern, et al
Daniel J. Mankowitz, Andrea Michi, Anton Zhernov, Marco Gelmi, Marco Selvi, Cosmin Paduraru, Edouard Leurent, Shariq Iqbal, Jean-Baptiste Lespiau, Alex Ah- ern, et al. Faster sorting algorithms discovered using deep reinforcement learning.Nature, 618(7964):257– 263, 2023
2023
-
[33]
Neural adaptive video streaming with Pensieve
Hongzi Mao, Ravi Netravali, and Mohammad Alizadeh. Neural adaptive video streaming with Pensieve. InPro- ceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM), pages 197–210. ACM, 2017
2017
-
[34]
Learning scheduling algorithms for data processing clus- ters
Hongzi Mao, Malte Schwarzkopf, Shaileshh Bojja Venkatakrishnan, Zili Meng, and Mohammad Alizadeh. Learning scheduling algorithms for data processing clus- ters. InProceedings of the ACM Special Interest Group on Data Communication (SIGCOMM), pages 270–288. ACM, 2019
2019
-
[35]
Cache craftiness for fast multicore key-value storage
Yandong Mao, Eddie Kohler, and Robert Tappan Morris. Cache craftiness for fast multicore key-value storage. InProceedings of the 7th ACM European Conference on Computer Systems (EuroSys), pages 183–196. ACM, 2012
2012
-
[36]
Neo: A learned query optimizer.Proceedings of the VLDB Endowment, 12(11):1705–1718, 2019
Ryan Marcus, Parimarjan Negi, Hongzi Mao, Chi Zhang, Mohammad Alizadeh, Tim Kraska, Olga Pa- paemmanouil, and Nesime Tatbul. Neo: A learned query optimizer.Proceedings of the VLDB Endowment, 12(11):1705–1718, 2019
2019
-
[37]
Le, Benoit Steiner, Rasmus Larsen, Yuefeng Zhou, Naveen Kumar, 14 Mohammad Norouzi, Samy Bengio, and Jeff Dean
Azalia Mirhoseini, Hieu Pham, Quoc V . Le, Benoit Steiner, Rasmus Larsen, Yuefeng Zhou, Naveen Kumar, 14 Mohammad Norouzi, Samy Bengio, and Jeff Dean. De- vice placement optimization with reinforcement learn- ing. InProceedings of the 34th International Conference on Machine Learning (ICML), pages 2430–2439, 2017
2017
-
[38]
Li, Ryan McElroy, Mike Paleczny, Daniel Peek, Paul Saab, David Stafford, Tony Tung, and Venkateshwaran Venkataramani
Rajesh Nishtala, Hans Fugal, Steven Grimm, Marc Kwiatkowski, Herman Lee, Harry C. Li, Ryan McElroy, Mike Paleczny, Daniel Peek, Paul Saab, David Stafford, Tony Tung, and Venkateshwaran Venkataramani. Scal- ing Memcache at Facebook. InProceedings of the 10th USENIX Symposium on Networked Systems Design and Implementation (NSDI), pages 385–398, 2013
2013
-
[39]
Ruiz, Abbas Mehrabian, M.˜Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog
Alexander Novikov, Ngân Vu, Marvin Eisenberger, Emi- lien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J.˜R. Ruiz, Abbas Mehrabian, M.˜Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. AlphaE- volve: A coding agent for scientific and al...
2025
-
[40]
Sitaraman, and Jennifer Sun
Erik Nygren, Ramesh K. Sitaraman, and Jennifer Sun. The Akamai network: A platform for high-performance internet applications.ACM SIGOPS Operating Systems Review, 44(3):2–19, 2010
2010
-
[41]
Stateless datacenter load-balancing with Beamer
Vladimir Olteanu, Alexandru Agache, Andrei V oinescu, and Costin Raiciu. Stateless datacenter load-balancing with Beamer. InProceedings of the 15th USENIX Sym- posium on Networked Systems Design and Implementa- tion (NSDI), pages 125–139, 2018
2018
-
[42]
Sparrow: Distributed, low latency schedul- ing
Kay Ousterhout, Patrick Wendell, Matei Zaharia, and Ion Stoica. Sparrow: Distributed, low latency schedul- ing. InProceedings of the 24th ACM Symposium on Op- erating Systems Principles (SOSP), pages 69–84. ACM, 2013
2013
-
[43]
The effects of reward misspecification: Mapping and miti- gating misaligned models
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. The effects of reward misspecification: Mapping and miti- gating misaligned models. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[44]
Maltz, Randy Kern, Hemant Kumar, Marios Zikos, Hongyu Wu, Changhoon Kim, and Naveen Karri
Parveen Patel, Deepak Bansal, Lihua Yuan, Ashwin Murthy, Albert Greenberg, David A. Maltz, Randy Kern, Hemant Kumar, Marios Zikos, Hongyu Wu, Changhoon Kim, and Naveen Karri. Ananta: Cloud scale load bal- ancing. InProceedings of the ACM SIGCOMM Confer- ence, pages 207–218. ACM, 2013
2013
-
[45]
Mowry, Matthew Perron, Ian Quah, et al
Andrew Pavlo, Gustavo Angulo, Joy Arulraj, Haibin Lin, Jiexi Lin, Lin Ma, Prashanth Menon, Todd C. Mowry, Matthew Perron, Ian Quah, et al. Self-driving database management systems. InProceedings of the 8th Bien- nial Conference on Innovative Data Systems Research (CIDR), 2017
2017
-
[46]
DuckDB: An embeddable analytical database
Mark Raasveldt and Hannes Mühleisen. DuckDB: An embeddable analytical database. InProceedings of the 2019 International Conference on Management of Data (SIGMOD), pages 1981–1984. ACM, 2019
2019
-
[47]
Redis Ltd. Redis. https://redis.io , 2024. Open- source in-memory data store
2024
-
[48]
Ruiz, Jordan S
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M.˜Pawan Kumar, Emilien Dupont, Francisco J.˜R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models. Nature, 625:468–475, 2024
2024
-
[49]
OpenEvolve: An open-source im- plementation of AlphaEvolve
Asankhaya Sharma. OpenEvolve: An open-source im- plementation of AlphaEvolve. https://github.com /algorithmicsuperintelligence/openevolve , 2025
2025
-
[50]
Joar Skalse, Nikolaus H. R. Howe, Dmitrii Krashenin- nikov, and David Krueger. Defining and characterizing reward hacking. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, 2022
2022
-
[51]
Specifications: The missing link to mak- ing the development of LLM systems an engineering discipline.arXiv [cs.SE], November 2024
Ion Stoica, Matei Zaharia, Joseph Gonzalez, Ken Gold- berg, Koushik Sen, Hao Zhang, Anastasios Angelopou- los, Shishir G Patil, Lingjiao Chen, Wei-Lin Chiang, and Jared Q Davis. Specifications: The missing link to mak- ing the development of LLM systems an engineering discipline.arXiv [cs.SE], November 2024
2024
-
[52]
Michael Stonebraker and Lawrence A. Rowe. The de- sign of Postgres.ACM SIGMOD Record, 15(2):340– 355, 1986
1986
-
[53]
Gordon, and Bohan Zhang
Dana Van Aken, Andrew Pavlo, Geoffrey J. Gordon, and Bohan Zhang. Automatic database management system tuning through large-scale machine learning. In Proceedings of the 2017 ACM International Conference on Management of Data (SIGMOD), pages 1009–1024. ACM, 2017
2017
-
[54]
Large- scale cluster management at Google with Borg
Abhishek Verma, Luis Pedrosa, Madhukar Korupolu, David Oppenheimer, Eric Tune, and John Wilkes. Large- scale cluster management at Google with Borg. InPro- ceedings of the 10th European Conference on Computer Systems (EuroSys), pages 1–17. ACM, 2015
2015
-
[55]
Bespoke OLAP: Synthesizing workload-specific one-size-fits-one database engines
Johannes Wehrstein, Timo Eckmann, Matthias Jasny, and Carsten Binnig. Bespoke OLAP: Synthesizing workload-specific one-size-fits-one database engines. arXiv preprint arXiv:2603.02001, 2026
-
[56]
Juncheng Yang, Yao Yue, and K. V . Rashmi. A large scale analysis of hundreds of in-memory cache clusters at Twitter. In14th USENIX Symposium on Operating 15 Systems Design and Implementation (OSDI), pages 191– 208, 2020
2020
-
[57]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representa- tions (ICLR), 2023
2023
-
[58]
Jain, and Michael Stumm
Ding Yuan, Yu Luo, Xin Zhuang, Guilherme Renna Ro- drigues, Xu Zhao, Yongle Zhang, Pranay U. Jain, and Michael Stumm. Simple testing can prevent most crit- ical failures: An analysis of production failures in dis- tributed data-intensive systems. InProceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 249–265, 2014
2014
-
[59]
An end-to-end automatic cloud database tuning system using deep rein- forcement learning
Ji Zhang, Yu Liu, Ke Zhou, Guoliang Li, Zhili Xiao, Bin Cheng, Jiashu Xing, Yangtao Wang, Tianheng Cheng, Li Liu, Minwei Ran, and Zekang Li. An end-to-end automatic cloud database tuning system using deep rein- forcement learning. InProceedings of the 2019 Interna- tional Conference on Management of Data (SIGMOD), pages 415–432. ACM, 2019
2019
-
[60]
Demystifying cache policies for photo stores at scale: A Tencent case study
Ke Zhou, Si Sun, Hua Wang, Ping Huang, Xubin He, Rui Lan, Wenyan Li, Wenjie Liu, and Tianming Yang. Demystifying cache policies for photo stores at scale: A Tencent case study. InProceedings of the 2018 Inter- national Conference on Supercomputing (ICS), pages 284–294. ACM, 2018. 16 A Design Catalog: Meta Cachelib Case Study Table 4 catalogs the design id...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.