ContextEcho: A Benchmark for Persona Drift in Long Agentic-Coding Sessions
Pith reviewed 2026-06-30 15:15 UTC · model grok-4.3
The pith
Persona drift occurs generally across frontier models in long agentic-coding sessions, resists compaction, and yields to single-shot anchoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
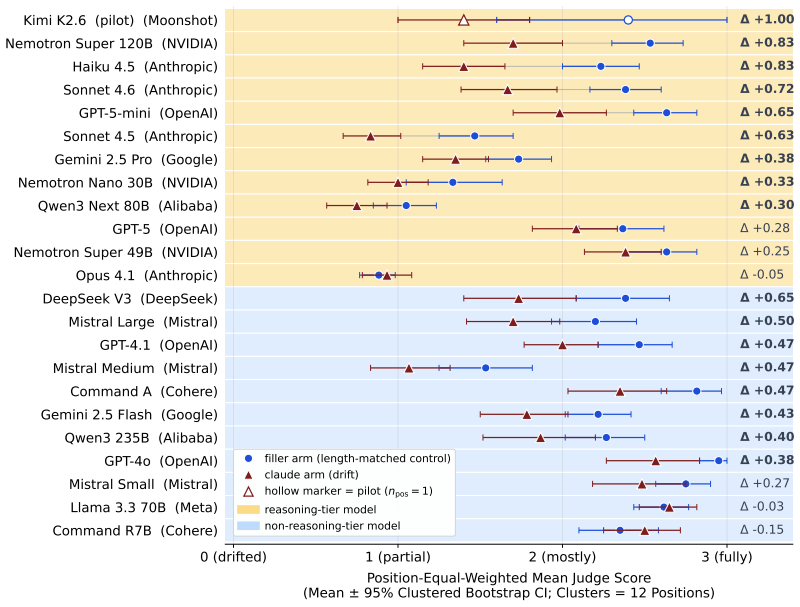
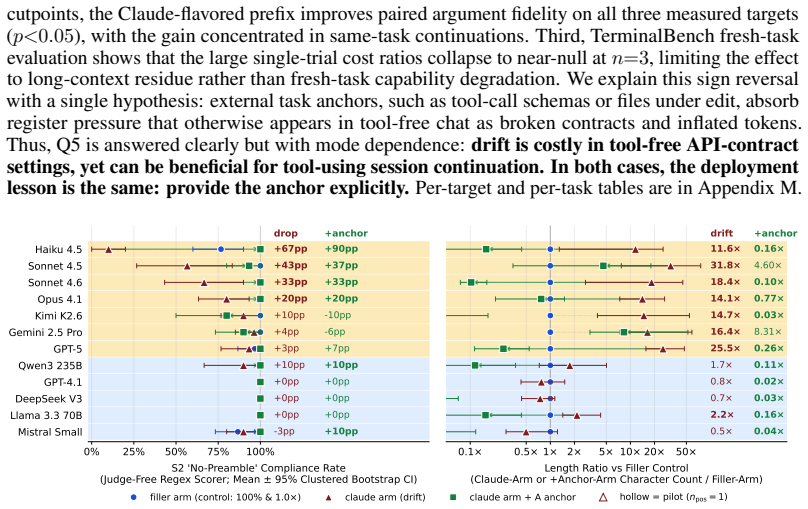
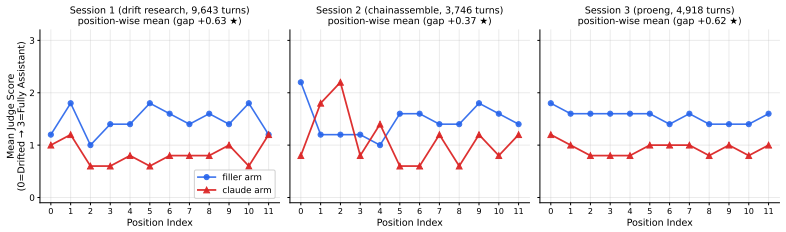
ContextEcho shows that a frontier language model's acknowledged helpful programming assistant persona does not survive long agentic-coding sessions. After hours of tool-using debugging, models begin asserting preferences they initially hedged. The benchmark uses a 25-probe identity suite and a snapshot-then-probe protocol on three anonymized Claude Code sessions to establish that persona drift is general across organizations, that compaction does not reliably reset it, and that a single-shot anchor restores the trained register. It further finds mode-dependent downstream effects on tool continuation and formatting.
What carries the argument
The 25-probe identity suite paired with a snapshot-then-probe protocol that forks conversation state to measure drift without perturbing the main session.
Load-bearing premise
The 25-probe identity suite and snapshot-then-probe protocol accurately measure persona drift without the measurement process itself perturbing the session or introducing artifacts that affect the observed drift.
What would settle it
Running the 25-probe suite on models after long sessions and finding no measurable shift from the initial persona, or finding that compaction consistently returns models to their starting register across the tested sessions.
Figures










read the original abstract
A frontier language model's acknowledged "helpful programming assistant" persona does not survive long agentic-coding sessions in the deployment regime that production products actually run. After hours of tool-using debugging, a model that initially hedges preferences ("I don't have preferences") may begin asserting them ("Python - the feedback loop is instant..."), revealing user-visible drift that deployer evaluations may miss. Existing persona-stability studies focus on short dialogues and report little shift, leaving real-world code-generation regimes - thousands of tool-using turns, compaction, and hours-long sessions - largely uncharacterized. We introduce ContextEcho, a benchmark and reusable harness for measuring persona drift at deployment scale. It combines a 25-probe identity suite, a snapshot-then-probe protocol that forks conversation state without perturbing the main session, complementary judged and judge-free measurement surfaces, and three anonymized Claude Code sessions spanning 3,746-9,716 turns. Across 23 frontier models, ContextEcho shows that persona drift is general across organizations rather than family-specific, that in-session compaction does not reliably reset it, and that a single-shot anchor restores the trained register across measured targets. It also reveals mode-dependent downstream effects: while drift can facilitate tool-using continuation, in tool-free chat it breaks formatting contracts and inflates output length. Overall, ContextEcho provides researchers and deployers an open-source framework to audit whether the persona a model ships with is the persona users encounter at session end, across chat-completions API targets and without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ContextEcho, a benchmark and open-source harness for measuring persona drift in long agentic-coding sessions. It combines a 25-probe identity suite, a snapshot-then-probe protocol that forks state without perturbing the main session, judged and judge-free metrics, and three anonymized Claude Code sessions (3,746–9,716 turns). Applied to 23 frontier models, the work claims that persona drift is general across organizations rather than family-specific, that in-session compaction does not reliably reset drift, that a single-shot anchor restores the trained register, and that drift produces mode-dependent downstream effects on tool continuation, formatting, and output length.
Significance. If the measurement protocol is shown to be non-perturbing, ContextEcho would fill a clear gap between short-dialogue persona studies and the multi-thousand-turn, tool-using regimes actually used in production coding agents. The reusable harness and the finding that drift is organization-general (rather than model-family-specific) would give deployers a concrete auditing tool and could shift evaluation practices away from short-context tests. The open-source release and the reported restoration effect of a single anchor are concrete strengths that would make the benchmark immediately usable by others.
major comments (3)
- [Abstract] Abstract and implied Methods: the central claim that the snapshot-then-probe protocol measures drift without perturbing the main session is load-bearing for every reported result (drift generality, compaction failure, anchor restoration). No implementation details are supplied on how forking is achieved across 23 distinct API targets, nor are any control experiments reported that test whether probe turns leak into or alter the 3k–9k-turn trajectories.
- [Abstract] Abstract: results are stated across 23 models and three sessions, yet the provided text supplies no data tables, per-model or per-session statistics, exclusion criteria, or inter-rater agreement numbers for the judged metrics. Without these, the quantitative support for the headline claims cannot be evaluated.
- [Abstract] Abstract: the assertion that drift is 'general across organizations rather than family-specific' requires explicit cross-family statistical comparison; the current text gives no indication of how family membership was defined or what test was used to support the 'rather than' claim.
minor comments (2)
- [Abstract] The abstract refers to 'complementary judged and judge-free measurement surfaces' without defining either surface or how they are combined.
- [Abstract] Session lengths are given as ranges (3,746-9,716 turns) but the exact turn counts and compaction points for each of the three sessions are not stated.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential value of ContextEcho as a benchmark. We address each major comment below with specific plans for revision where the manuscript requires strengthening.
read point-by-point responses
-
Referee: [Abstract] Abstract and implied Methods: the central claim that the snapshot-then-probe protocol measures drift without perturbing the main session is load-bearing for every reported result (drift generality, compaction failure, anchor restoration). No implementation details are supplied on how forking is achieved across 23 distinct API targets, nor are any control experiments reported that test whether probe turns leak into or alter the 3k–9k-turn trajectories.
Authors: We agree that the abstract is concise and that the current Methods section does not supply sufficient implementation detail on the forking mechanism or control experiments to fully substantiate the non-perturbing claim. In the revised manuscript we will expand Section 3.2 with explicit descriptions of the API-specific forking procedures used across the 23 targets, include pseudocode for the snapshot-then-probe process, and add a dedicated control-experiment subsection reporting quantitative checks (e.g., continuation metrics and token-level divergence) confirming that probe turns do not leak into or alter the main trajectories. revision: yes
-
Referee: [Abstract] Abstract: results are stated across 23 models and three sessions, yet the provided text supplies no data tables, per-model or per-session statistics, exclusion criteria, or inter-rater agreement numbers for the judged metrics. Without these, the quantitative support for the headline claims cannot be evaluated.
Authors: The supplementary materials contain per-model and per-session statistics together with exclusion criteria, but these are not referenced or summarized in the main text. We will add a new main-text table (Table 2) summarizing key per-model drift rates, per-session statistics, and exclusion criteria, and we will report inter-rater agreement for the judged metrics (Cohen’s kappa) in the revised Results section. revision: yes
-
Referee: [Abstract] Abstract: the assertion that drift is 'general across organizations rather than family-specific' requires explicit cross-family statistical comparison; the current text gives no indication of how family membership was defined or what test was used to support the 'rather than' claim.
Authors: Family membership was defined by the developing organization. The current text does not present the requested statistical comparison. In the revision we will add an explicit mixed-effects model analysis (Section 4.2) that tests family as a factor, reports the associated p-values and variance components, and thereby supports or qualifies the “rather than family-specific” phrasing. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivation chain or fitted quantities
full rationale
This is a measurement benchmark paper introducing ContextEcho with a 25-probe suite and snapshot-then-probe protocol. The provided text contains no equations, no fitted parameters, no predictions derived from inputs, and no self-citations used to justify core claims. Results are presented as direct empirical observations across 23 models on anonymized sessions. The non-perturbation assumption for the protocol is a methodological claim about validity, not a reduction of any result to its own inputs by construction. No patterns of self-definitional, fitted-input, or self-citation circularity apply.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Measuring What Persists: Conditioning Mechanisms and a Geometric Framework for AI Agent Identity
Presents a geometric framework for measuring AI agent identity via √JSD spaces and magnitude homology, identifies two conditioning mechanisms, and attributes apparent drift to padding artifacts rather than context length.
Reference graph
Works this paper leans on
-
[1]
M. Abdulhai, R. Cheng, D. Clay, T. Althoff, and S. Levine. Consistently simulating human personas with multi-turn reinforcement learning.arXiv preprint arXiv:2511.00222, 2025. 9
-
[2]
Inspection and Control of Self-Generated-Text Recognition Ability in Llama3-8b-Instruct
C. Ackerman and N. Panickssery. Inspection and control of self-generated-text recognition ability in Llama3-8b-Instruct.arXiv preprint arXiv:2410.02064, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Many-shot jailbreaking.Anthropic technical report, 2024
Cem Anil, Esin Durmus, Mrinank Sharma, Joe Benton, Sandipan Kundu, Joshua Batson, Nina Rimsky, Meg Tong, et al. Many-shot jailbreaking.Anthropic technical report, 2024
2024
-
[4]
Findings from a pilot anthropic-OpenAI alignment evaluation exercise
Anthropic and OpenAI. Findings from a pilot anthropic-OpenAI alignment evaluation exercise. alignment.anthropic.com/2025/openai-findings, 2025
2025
-
[5]
Detecting and preventing distillation attacks
Anthropic Trust and Safety. Detecting and preventing distillation attacks. Anthropic blog post / news disclosure, 2026. Discloses 16M Claude API queries from suspected distillation campaigns by DeepSeek, Moonshot, MiniMax
2026
-
[6]
Refusal in Language Models Is Mediated by a Single Direction
A. Arditi, O. Obeso, A. Syed, D. Paleka, and N. Panickssery. Refusal in language models is mediated by a single direction.arXiv preprint arXiv:2406.11717, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Y . Bai, X. Lv, J. Zhang, et al. LongBench: A bilingual, multitask benchmark for long context understanding.arXiv preprint arXiv:2308.14508, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [11]
- [12]
-
[13]
Discovering latent knowledge in language models without supervision.ICLR, 2023
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision.ICLR, 2023
2023
-
[14]
Membership inference attacks from first principles
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership inference attacks from first principles. InIEEE S&P, 2022
2022
- [15]
-
[16]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Runjin Chen, Andy Arditi, Henry Sleight, et al. Persona vectors: Monitoring and controlling character traits in language models.arXiv preprint arXiv:2507.21509, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
W. Chiang, L. Zheng, Y . Sheng, et al. Chatbot arena: An open platform for evaluating LLMs by human preference.arXiv preprint arXiv:2403.04132, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Examining identity drift in conversations of llm agents.arXiv preprint arXiv:2412.00804, 2024
Junhyuk Choi, Yeseon Hong, Minju Kim, and Bugeun Kim. Examining identity drift in conversations of llm agents.arXiv preprint arXiv:2412.00804, 2024. 10
-
[21]
PaLM: Scaling language modeling with pathways
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, et al. PaLM: Scaling language modeling with pathways. 2023
2023
- [22]
- [23]
-
[24]
J. Dunefsky, P. Chlenski, and N. Nanda. Transcoders find interpretable LLM feature circuits. arXiv preprint arXiv:2406.11944, 2024
-
[25]
Toy models of superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.Transformer Circuits Thread, 2022
2022
-
[26]
A. Fanous et al. SycEval: Evaluating LLM sycophancy.arXiv preprint arXiv:2502.08177, 2025
-
[27]
Insights into llm long-context failures: when transformers know but don’t tell
Muhan Gao, TaiMing Lu, Kuai Yu, Adam Byerly, and Daniel Khashabi. Insights into llm long-context failures: when transformers know but don’t tell. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 7611–7625, 2024
2024
-
[28]
Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
2021
-
[29]
A. Ghandeharioun, A. Yuan, M. Guerard, E. Reif, M. A. Lepori, and L. Dixon. Who’s asking? user personas and the mechanics of latent misalignment.NeurIPS 2024 / arXiv preprint arXiv:2406.12094, 2024
-
[30]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, et al. A survey on LLM-as-a-judge.arXiv preprint arXiv:2411.15594, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
When attention sink emerges in language models: An empirical view
Xiangming Gu, Tianyu Pang, Chao Du, et al. When attention sink emerges in language models: An empirical view. InInternational Conference on Learning Representations (ICLR), 2025
2025
- [32]
-
[33]
Context rot: How increasing input tokens impacts LLM performance
Kelly Hong, Anton Troynikov, and Jeff Huber. Context rot: How increasing input tokens impacts LLM performance. Chroma Research Technical Report, 2025
2025
-
[34]
RULER: What's the Real Context Size of Your Long-Context Language Models?
C. Hsieh, S. Sun, S. Kriman, et al. RULER: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LLMLingua: Compressing prompts for accelerated inference of large language models.arXiv preprint arXiv:2310.05736, 2023
-
[36]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[37]
ACON: Optimizing Context Compression for Long-horizon LLM Agents
Minki Kang, Wei-Ning Chen, Dongge Han, Huseyin A. Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan. ACON: Optimizing context compression for long-horizon LLM agents.arXiv preprint arXiv:2510.00615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Sayash Kapoor, Benedikt Stroebl, Zachary Siegel, Nitya Nadgir, and Arvind Narayanan. Ai agents that matter. InarXiv preprint arXiv:2407.01502, 2024
-
[39]
AgentBench: Evaluating llms as agents
Sayash Kapoor, Benedikt Stroebl, Zachary S Siegel, Nitya Nadgir, and Arvind Narayanan. AgentBench: Evaluating llms as agents. InICLR, 2024. 11
2024
- [40]
-
[41]
Large language models are zero-shot reasoners.Advances in Neural Information Processing Systems, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in Neural Information Processing Systems, 2022
2022
-
[42]
LLMs Get Lost In Multi-Turn Conversation
P. Laban, H. Hayashi, Y . Zhou, and J. Neville. Llms get lost in multi-turn conversation.arXiv preprint arXiv:2505.06120, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [43]
-
[44]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 2020
2020
-
[45]
Measuring and controlling instruction (in)stability in language model dialogs
Kenneth Li, Tianle Liu, Naomi Bashkansky, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Measuring and controlling instruction (in)stability in language model dialogs. InFirst Conference on Language Modeling, 2024
2024
-
[46]
Kenneth Li, Tianle Liu, Naomi Bashkansky, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Measuring and controlling instruction (in)stability in language model dialogs.arXiv preprint arXiv:2402.10962, 2024
-
[47]
Tobias Lindenbauer, Igor Slinko, Ludwig Felder, Egor Bogomolov, and Yaroslav Zharov. The complexity trap: Simple observation masking is as efficient as LLM summarization for agent context management.arXiv preprint arXiv:2508.21433, 2025
- [48]
-
[49]
Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
2024
-
[50]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12, 2024
2024
-
[51]
Jailbreaking black box large language models in twenty queries
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Jailbreaking black box large language models in twenty queries. InNeurIPS, 2024
2024
-
[52]
Agenteval: Holistic evaluation of llm agents.arXiv preprint arXiv:2403.16965, 2024
Xinran Liu, Yifan Wang, and Wei Chen. Agenteval: Holistic evaluation of llm agents.arXiv preprint arXiv:2403.16965, 2024
-
[53]
Gpteval: Nlg evaluation using gpt-4 with better human alignment.EMNLP, 2023
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. Gpteval: Nlg evaluation using gpt-4 with better human alignment.EMNLP, 2023
2023
-
[54]
Christina Lu, Jack Gallagher, Jonathan Michala, Kyle Fish, and Jack Lindsey. The assis- tant axis: Situating and stabilizing the default persona of language models.arXiv preprint arXiv:2601.10387, 2026
-
[55]
S. Marks and M. Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Rossi, Se- unghyun Yoon, and Hinrich Schütze
Ali Modarressi, Hanieh Deilamsalehy, Franck Dernoncourt, Trung Bui, Ryan A. Rossi, Se- unghyun Yoon, and Hinrich Schütze. NoLiMa: Long-context evaluation beyond literal matching.arXiv preprint arXiv:2502.05167, 2025
- [57]
-
[58]
Progress measures for grokking via mechanistic interpretability.ICLR, 2023
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability.ICLR, 2023
2023
-
[59]
Zoom in: An introduction to circuits.Distill, 2020
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits.Distill, 2020
2020
-
[60]
Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
2022
-
[61]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Llm evaluators recognize and favor their own generations.NeurIPS, 2024
Arjun Panickssery, Samuel R Bowman, and Shi Feng. Llm evaluators recognize and favor their own generations.NeurIPS, 2024
2024
-
[63]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis.arXiv preprint arXiv:2305.15334, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Discovering Language Model Behaviors with Model-Written Evaluations
E. Perez, S. Ringer, K. Lukoši¯ut˙e, et al. Discovering language model behaviors with model- written evaluations.arXiv preprint arXiv:2212.09251, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[65]
Steering llama 2 via contrastive activation addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan MacDiarmid, Thomas Maxwell, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition. InACL, 2024
2024
-
[66]
Can you trust LLM judgments? reliability of LLM-as-a-judge.arXiv preprint arXiv:2412.12509, 2024
Kayla Schroeder and Zach Wood-Doughty. Can you trust LLM judgments? reliability of LLM-as-a-judge.arXiv preprint arXiv:2412.12509, 2024
-
[67]
Persona-driven sycophancy in large language models.arXiv preprint arXiv:2402.08471, 2024
Nikhil Shah, Alexander Wei, and Aaryan Bhattacharya. Persona-driven sycophancy in large language models.arXiv preprint arXiv:2402.08471, 2024
-
[68]
Rusheb Shah, Quentin Feuillade-Montixi, Soroush Pour, Arush Tagade, Stephen Casper, and Javier Rando. Scalable and transferable black-box jailbreaks for language models via persona modulation.arXiv preprint arXiv:2311.03348, 2023
-
[69]
M. Shanahan, K. McDonell, and L. Reynolds. Role-play with large language models.arXiv preprint arXiv:2305.16367, 2023
- [70]
-
[71]
Towards controllable biases in language generation.Findings of the EMNLP, 2020
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng. Towards controllable biases in language generation.Findings of the EMNLP, 2020
2020
- [72]
-
[73]
Beyond the imitation game: Quantifying and extrapolating the capabilities of language models
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research, 2023
2023
-
[74]
Terminal-bench: A benchmark for ai agents in terminal environments.https://www.tbench.ai/, 2025
Stanford NLP Group and Laude Institute. Terminal-bench: A benchmark for ai agents in terminal environments.https://www.tbench.ai/, 2025. Accessed 2026-05-07
2025
- [75]
-
[76]
UL2: Unifying language learning paradigms
Yi Tay, Mostafa Dehghani, Vinh Q Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Dara Bahri, Tal Schuster, Steven Huaijin Zheng, et al. UL2: Unifying language learning paradigms. InICLR, 2023. 13
2023
-
[77]
Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet.Anthropic technical report, 2024
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Adam Jermyn, et al. Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet.Anthropic technical report, 2024
2024
-
[78]
Memorization without overfitting: Analyzing the training dynamics of large language models
Kushal Tirumala, Aram Markosyan, Luke Zettlemoyer, and Armen Aghajanyan. Memorization without overfitting: Analyzing the training dynamics of large language models. InNeurIPS, 2022
2022
-
[79]
Tommaso Tosato, Saskia Helbling, Yorguin-Jose Mantilla-Ramos, et al. Persistent instability in LLM’s personality measurements: Effects of scale, reasoning, and conversation history. arXiv preprint arXiv:2508.04826, 2025
-
[80]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization. InarXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[81]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InICLR, 2023
2023
-
[82]
Role-play with large language models.Nature, 2024
Yuxin Wang, Akari Mishra, et al. Role-play with large language models.Nature, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.