Inference-Time Alignment of Diffusion Models via Trust-Region Iterative Twisted Sequential Monte Carlo
Pith reviewed 2026-06-30 11:54 UTC · model grok-4.3
The pith
TRI-TSMC steers diffusion models to high-reward outputs at inference time by learning twisting functions through trust-region updates in SMC.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TRI-TSMC computes an exact KL-constrained update for the twisting function in path space that admits a closed-form solution by tempered importance reweighting, then projects this target onto the parameterized family by weighted maximum likelihood; the resulting sequence follows an escort path toward the reward-tilted distribution, the optimal twisting function is the value function that produces a zero-variance sampler, and each step reduces residual importance-weight variance.
What carries the argument
Trust-region iterative update of twisting functions, realized by tempered importance reweighting to obtain the KL-constrained target in path space followed by weighted maximum-likelihood projection onto the parameterized family.
If this is right
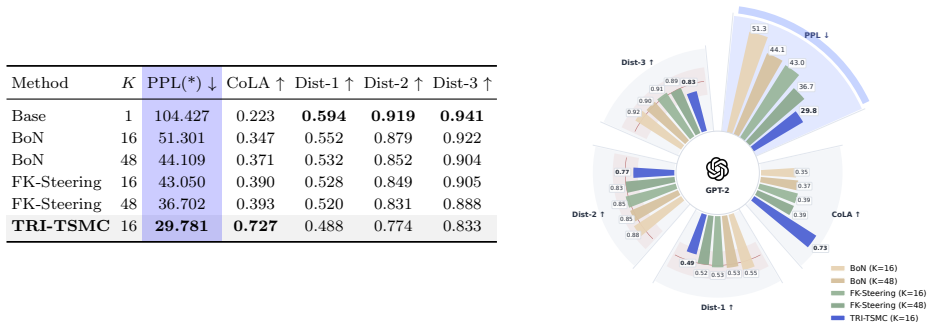
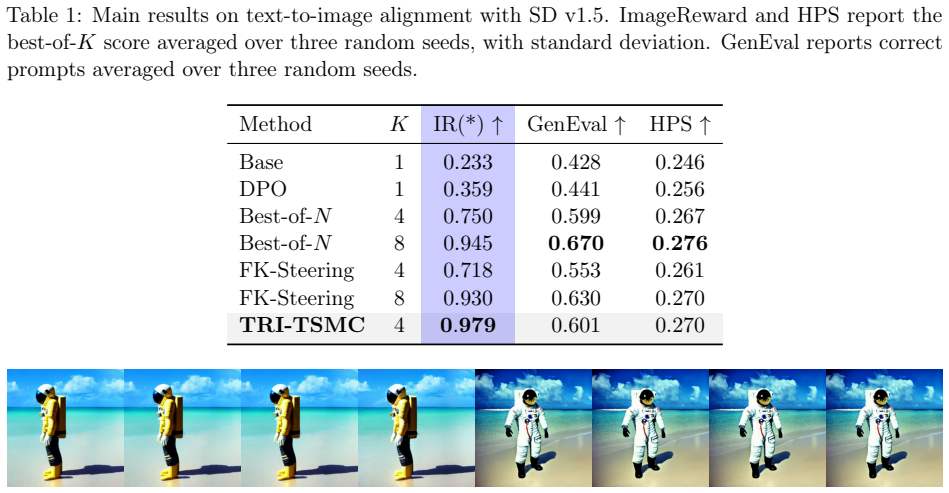
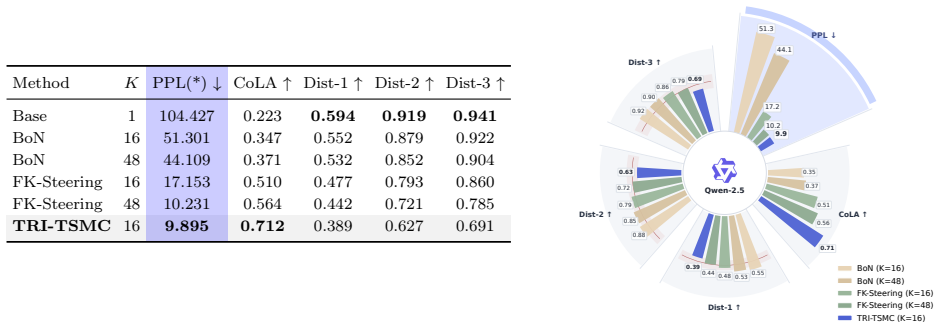
- Higher primary alignment scores are obtained on discrete diffusion text generation and text-to-image tasks under identical inference-time budgets.
- Particle efficiency improves because look-ahead twisting reduces weight degeneracy compared with base proposals.
- The sequence of updates is guaranteed to follow an escort path that monotonically decreases residual importance-weight variance.
- The framework remains applicable when rewards are terminal, noisy, or black-box because the twisting functions are learned from the same reward signals used in reweighting.
Where Pith is reading between the lines
- The same trust-region projection step could be applied to other sequential Monte Carlo settings outside diffusion, such as state-space models with terminal rewards.
- Combining the learned twisting functions with a small amount of supervised fine-tuning might produce hybrid alignment pipelines that trade off compute between inference and training.
- The value-function view of the optimal twisting function suggests that any method able to estimate value functions in diffusion state spaces could serve as an alternative twisting approximator.
Load-bearing premise
The chosen parameterized family of twisting functions can approximate the optimal twisting function closely enough that the KL-constrained updates stay stable and the projection step does not introduce large bias in high-dimensional diffusion spaces.
What would settle it
Run TRI-TSMC and untuned SMC on the same text-to-image prompt set with identical particle count and diffusion steps; if the primary alignment reward or human preference rate shows no statistically significant gain, the claimed improvement under matched budgets is falsified.
Figures



read the original abstract
We study inference-time alignment for diffusion-based generative models, aiming to steer a base model toward high-reward outputs without updating its weights. Recent Sequential Monte Carlo (SMC)-based steering methods approximate reward-tilted target distributions in a principled way, but their proposals remain largely tied to the base sampler. Since reward information is mainly used after propagation through particle reweighting and resampling, these methods can require large particle budgets and suffer from weight degeneracy and high-variance estimates. One way to reduce variance and improve particle efficiency is to iteratively learn twisting functions that provide look-ahead guidance, as in twisted SMC. However, existing learnable twisting methods are developed mainly for classical sequential inference and can be unstable when applied to diffusion-based alignment with high-dimensional state spaces and terminal, noisy, or black-box rewards. We propose Trust-Region Iterative Twisted Sequential Monte Carlo (TRI-TSMC), a trust-region framework for learning twisting functions in SMC-based inference-time alignment. Each iteration computes an exact KL-constrained update in path space, which admits a closed-form solution by tempered importance reweighting, and projects this target back to the parameterized twisted family by weighted maximum likelihood. Theoretically, we formalize the value-function interpretation of the optimal twisting function and show that it yields a zero-variance sampler. We prove that the trust-region update follows an escort path toward the target distribution, that the weighted maximum-likelihood update is a forward-KL projection, and that the path reduces residual importance-weight variance. Empirically, TRI-TSMC improves primary alignment objectives on discrete diffusion text generation and text-to-image generation under matched inference-time budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Trust-Region Iterative Twisted Sequential Monte Carlo (TRI-TSMC) for inference-time alignment of diffusion models without weight updates. It iteratively learns twisting functions via a trust-region framework that computes exact KL-constrained updates in path space (via tempered importance reweighting) and projects them onto a parameterized twisted family using weighted maximum likelihood. Theoretical results formalize the optimal twisting function as a value function yielding a zero-variance sampler, prove that the trust-region update follows an escort path, and show that the projection is a forward-KL step that reduces residual importance-weight variance. Empirically, the method improves primary alignment objectives on discrete diffusion text generation and text-to-image generation under matched inference-time budgets.
Significance. If the central claims hold, this provides a principled and more particle-efficient approach to SMC-based inference-time alignment for diffusion models, directly addressing weight degeneracy and high-variance issues in prior methods. The value-function interpretation of twisting functions and the escort-path analysis of the trust-region updates are substantive theoretical contributions that could generalize beyond the specific setting. The empirical gains under fixed budgets indicate practical relevance for alignment tasks. Strengths include the closed-form KL update and the explicit variance-reduction argument; these are load-bearing for the paper's contribution.
major comments (2)
- [§4] §4 (value-function interpretation and zero-variance claim): The zero-variance sampler guarantee and the escort-path variance reduction both require the parameterized twisted family to closely approximate the optimal value function. The manuscript provides no capacity analysis, approximation bounds, or empirical diagnostics on how well the chosen family represents look-ahead guidance for terminal or black-box rewards in high-dimensional diffusion state spaces. This assumption is load-bearing for the stability of the KL-constrained updates and the claimed bias/variance benefits of the weighted-MLE projection.
- [§5] §5 (empirical evaluation): The primary alignment improvements are reported only at summary level. Without visible controls for the expressivity of the twisting family (e.g., ablation on family capacity, residual weight variance plots, or comparison to an oracle twisting function), it is difficult to verify that the observed gains stem from the trust-region mechanism rather than incidental factors.
minor comments (2)
- [§3] Notation for the tempered importance weights and the escort path could be clarified with an explicit recursive definition early in the theoretical section to aid readability.
- The abstract states that the method 'improves primary alignment objectives' but does not list the concrete metrics or baselines; adding these to the main text would strengthen the empirical narrative.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments point-by-point below, agreeing where the manuscript is incomplete and outlining targeted revisions.
read point-by-point responses
-
Referee: [§4] §4 (value-function interpretation and zero-variance claim): The zero-variance sampler guarantee and the escort-path variance reduction both require the parameterized twisted family to closely approximate the optimal value function. The manuscript provides no capacity analysis, approximation bounds, or empirical diagnostics on how well the chosen family represents look-ahead guidance for terminal or black-box rewards in high-dimensional diffusion state spaces. This assumption is load-bearing for the stability of the KL-constrained updates and the claimed bias/variance benefits of the weighted-MLE projection.
Authors: The theoretical results formalize the optimal twisting function as the value function yielding zero variance exactly, prove the trust-region update follows an escort path, and show the weighted-MLE projection is a forward-KL step that reduces residual importance-weight variance. These properties are established for the projection onto the given family; the zero-variance claim is stated for the optimal case. We agree the manuscript contains no capacity analysis, approximation bounds, or diagnostics on how well the chosen family approximates look-ahead guidance in high-dimensional spaces. We will revise §4 to add an explicit discussion of this modeling assumption, clarifying that variance reduction from the projection holds even under imperfect approximation while noting the lack of quantitative bounds as a limitation of the current analysis. revision: yes
-
Referee: [§5] §5 (empirical evaluation): The primary alignment improvements are reported only at summary level. Without visible controls for the expressivity of the twisting family (e.g., ablation on family capacity, residual weight variance plots, or comparison to an oracle twisting function), it is difficult to verify that the observed gains stem from the trust-region mechanism rather than incidental factors.
Authors: The empirical results demonstrate improvements on the primary alignment objectives for discrete diffusion text generation and text-to-image tasks under matched inference budgets relative to prior SMC baselines. We agree that the section lacks dedicated controls such as family-capacity ablations, residual weight-variance trajectories, or oracle comparisons that would more directly attribute gains to the trust-region mechanism. In the revision we will add (i) residual importance-weight variance plots over iterations and (ii) an ablation varying twisting-function capacity (e.g., network width). An oracle comparison is feasible only on simplified settings and will be included if space allows; otherwise we will note its absence as a limitation. revision: yes
Circularity Check
No significant circularity; derivations use standard SMC identities
full rationale
The paper's central theoretical steps formalize the value-function interpretation of the optimal twisting function (yielding zero-variance sampler) and prove that the trust-region update follows an escort path with the weighted MLE being a forward-KL projection. These follow directly from standard tempered importance reweighting and KL-projection identities in SMC literature rather than reducing to a fitted parameter or self-citation by construction. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described derivation chain. The method is presented as building on existing twisted SMC while adding a trust-region constraint for stability in diffusion settings.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math KL divergence admits a closed-form minimizer under tempered importance reweighting
- domain assumption The twisted family is closed under the weighted maximum-likelihood projection
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type url volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := ...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Avrahami, E. and Nachmani, E. (2026). Ilrr: Inference-time steering method for masked diffusion language models. arXiv preprint arXiv:2601.21647
-
[4]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y. , Jones, A. , Ndousse, K. , Askell, A. , Chen, A. , DasSarma, N. , Drain, D. , Fort, S. , Ganguli, D. , Henighan, T. et al. (2022). Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
, Janner, M
Black, K. , Janner, M. , Du, Y. , Kostrikov, I. and Levine, S. (2024). Training diffusion models with reinforcement learning. In The Twelfth International Conference on Learning Representations. ://openreview.net/forum?id=YCWjhGrJFD
2024
-
[6]
Blessing, D. , Berner, J. , Richter, L. , Domingo-Enrich, C. , Du, Y. , Vahdat, A. and Neumann, G. (2025). Trust region constrained measure transport in path space for stochastic optimal control and inference. arXiv preprint arXiv:2508.12511
-
[7]
and Elvira, V
Branchini, N. and Elvira, V. (2021). Optimized auxiliary particle filters: adapting mixture proposals via convex optimization. In Uncertainty in Artificial Intelligence. PMLR
2021
-
[8]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Chung, H. , Kim, J. , Mccann, M. T. , Klasky, M. L. and Ye, J. C. (2022). Diffusion posterior sampling for general noisy inverse problems. arXiv preprint arXiv:2209.14687
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Directly Fine-Tuning Diffusion Models on Differentiable Rewards
Clark, K. , Vicol, P. , Swersky, K. and Fleet, D. J. (2023). Directly fine-tuning diffusion models on differentiable rewards. arXiv preprint arXiv:2309.17400
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Dathathri, S. , Madotto, A. , Lan, J. , Hung, J. , Frank, E. , Molino, P. , Yosinski, J. and Liu, R. (2019). Plug and play language models: A simple approach to controlled text generation. arXiv preprint arXiv:1912.02164
-
[11]
, Vargas, F
Denker, A. , Vargas, F. , Padhy, S. , Didi, K. , Mathis, S. , Barbano, R. , Dutordoir, V. , Mathieu, E. , Komorowska, U. J. and Lio, P. (2024). Deft: Efficient fine-tuning of diffusion models by learning the generalised h -transform. Advances in Neural Information Processing Systems 37 19636--19682
2024
-
[12]
and Nichol, A
Dhariwal, P. and Nichol, A. (2021). Diffusion models beat gans on image synthesis. Advances in neural information processing systems 34 8780--8794
2021
-
[13]
Domingo-Enrich, C. , Drozdzal, M. , Karrer, B. and Chen, R. T. (2024). Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control. arXiv preprint arXiv:2409.08861
-
[14]
, Watkins, O
Fan, Y. , Watkins, O. , Du, Y. , Liu, H. , Ryu, M. , Boutilier, C. , Abbeel, P. , Ghavamzadeh, M. , Lee, K. and Lee, K. (2023). Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models. Advances in Neural Information Processing Systems 36 79858--79885
2023
-
[15]
, Hajishirzi, H
Ghosh, D. , Hajishirzi, H. and Schmidt, L. (2023). Geneval: An object-focused framework for evaluating text-to-image alignment. Advances in Neural Information Processing Systems 36 52132--52152
2023
-
[16]
, Johansen, A
Guarniero, P. , Johansen, A. M. and Lee, A. (2017). The iterated auxiliary particle filter. Journal of the American Statistical Association 112 1636--1647
2017
-
[17]
, Bishop, A
Heng, J. , Bishop, A. N. , Deligiannidis, G. and Doucet, A. (2020). Controlled sequential monte carlo. The Annals of Statistics 48 2904--2929
2020
-
[18]
Qwen2.5-Coder Technical Report
Hui, B. , Yang, J. , Cui, Z. , Yang, J. , Liu, D. , Zhang, L. , Liu, T. , Zhang, J. , Yu, B. , Lu, K. et al. (2024). Qwen2.5-coder technical report. arXiv preprint arXiv:2409.12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Aligning Text-to-Image Models using Human Feedback
Lee, K. , Liu, H. , Ryu, M. , Watkins, O. , Du, Y. , Boutilier, C. , Abbeel, P. , Ghavamzadeh, M. and Gu, S. S. (2023). Aligning text-to-image models using human feedback. arXiv preprint arXiv:2302.12192
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
, Galley, M
Li, J. , Galley, M. , Brockett, C. , Gao, J. and Dolan, W. B. (2016). A diversity-promoting objective function for neural conversation models. In Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies
2016
-
[21]
Guidance for twisted particle filter: a continuous-time perspective
Lu, J. and Wang, Y. (2024). Guidance for twisted particle filter: a continuous-time perspective. ://arxiv.org/abs/2409.02399
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [22]
-
[23]
Pani, C. , Ou, Z. and Li, Y. (2025). Test-time alignment of discrete diffusion models with sequential monte carlo. In Second Workshop on Test-Time Adaptation: Putting Updates to the Test! at ICML 2025
2025
-
[24]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D. , English, Z. , Lacey, K. , Blattmann, A. , Dockhorn, T. , M \"u ller, J. , Penna, J. and Rombach, R. (2023). Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Radford, A. , Wu, J. , Child, R. , Luan, D. , Amodei, D. , Sutskever, I. et al. (2019). Language models are unsupervised multitask learners. OpenAI blog 1 9
2019
-
[26]
, Blattmann, A
Rombach, R. , Blattmann, A. , Lorenz, D. , Esser, P. and Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
2022
-
[27]
, Arriola, M
Sahoo, S. , Arriola, M. , Schiff, Y. , Gokaslan, A. , Marroquin, E. , Chiu, J. , Rush, A. and Kuleshov, V. (2024). Simple and effective masked diffusion language models. Advances in Neural Information Processing Systems 37 130136--130184
2024
-
[28]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T. and Ho, J. (2022). Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
, Levine, S
Schulman, J. , Levine, S. , Abbeel, P. , Jordan, M. and Moritz, P. (2015). Trust region policy optimization. In International conference on machine learning. PMLR
2015
-
[30]
Singhal, R. , Horvitz, Z. , Teehan, R. , Ren, M. , Yu, Z. , McKeown, K. and Ranganath, R. (2025). A general framework for inference-time scaling and steering of diffusion models. arXiv preprint arXiv:2501.06848
-
[31]
So, O. , Karrer, B. , Fan, C. , Chen, R. T. and Liu, G.-H. (2026). Discrete adjoint matching. arXiv preprint arXiv:2602.07132
-
[32]
, Ouyang, L
Stiennon, N. , Ouyang, L. , Wu, J. , Ziegler, D. , Lowe, R. , Voss, C. , Radford, A. , Amodei, D. and Christiano, P. F. (2020). Learning to summarize with human feedback. Advances in neural information processing systems 33 3008--3021
2020
- [33]
-
[34]
, Dang, M
Wallace, B. , Dang, M. , Rafailov, R. , Zhou, L. , Lou, A. , Purushwalkam, S. , Ermon, S. , Xiong, C. , Joty, S. and Naik, N. (2024). Diffusion model alignment using direct preference optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2024
-
[35]
, Singh, A
Warstadt, A. , Singh, A. and Bowman, S. R. (2019). Neural network acceptability judgments. Transactions of the Association for Computational Linguistics 7 625--641
2019
-
[36]
, Trippe, B
Wu, L. , Trippe, B. , Naesseth, C. , Blei, D. and Cunningham, J. P. (2023 a ). Practical and asymptotically exact conditional sampling in diffusion models. Advances in Neural Information Processing Systems 36 31372--31403
2023
-
[37]
Wu, X. , Hao, Y. , Sun, K. , Chen, Y. , Zhu, F. , Zhao, R. and Li, H. (2023 b ). Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
, Liu, X
Xu, J. , Liu, X. , Wu, Y. , Tong, Y. , Li, Q. , Ding, M. , Tang, J. and Dong, Y. (2023). Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems 36 15903--15935
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.