DIVA: Harnessing the Representation Divergence in Unified Multimodal Models for Mutual Reinforcement
Pith reviewed 2026-06-29 23:06 UTC · model grok-4.3
The pith
Unified multimodal models can convert representation divergence between generation and understanding into mutual gains by factorizing visual features into shared and unique parts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
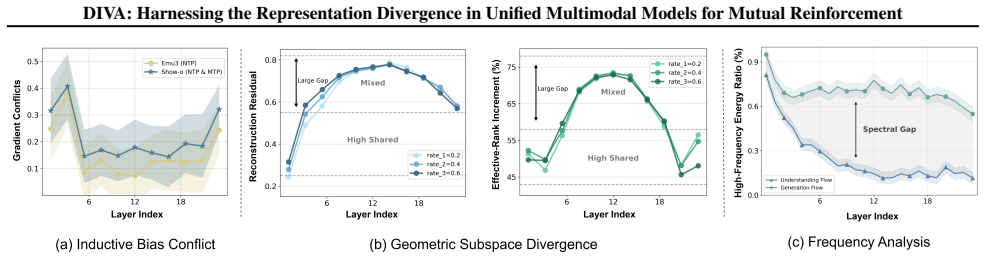
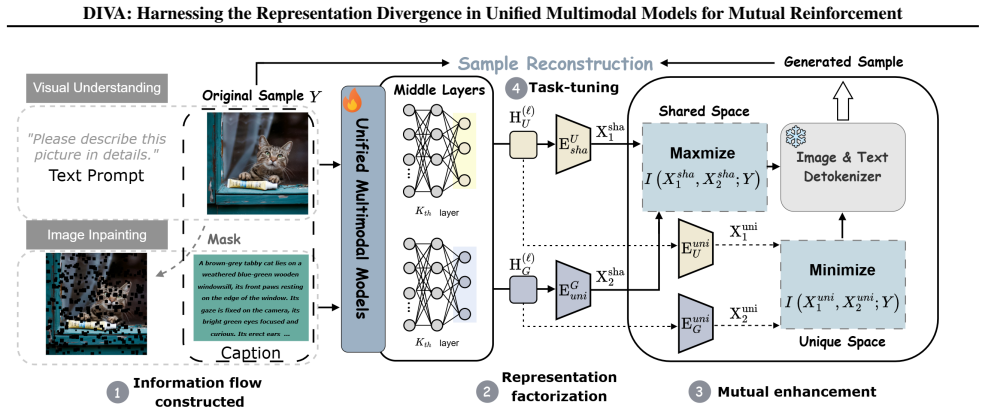
Optimizing complementary but non-equivalent objectives within a monolithic backbone leads to mutual impairment instead of enhancement. DIVA transforms the representation divergence into interior synergy by explicitly factorizing the visual representation into shared and unique components based on two complementary information flows, enabling both the understanding and generation branches to achieve beneficial transferring while preserving the integrity of unique information from cross-flow interference via mutual information estimation.
What carries the argument
Explicit factorization of visual representation into shared and unique components based on two complementary information flows with mutual information estimation to prevent cross-flow interference.
Load-bearing premise
The root cause of performance issues is representation divergence induced by distinct supervision signals, and explicit factorization via mutual information estimation on complementary flows can separate shared and unique components without losing task-critical information.
What would settle it
Running the DIVA post-training procedure on a unified multimodal model and measuring no improvement or a decrease in both understanding accuracy and generation fidelity metrics would falsify the claim that the factorization produces beneficial transfer.
Figures


read the original abstract
Unified Multimodal models (UMMs) built on a single architecture have shown impressive performance in both understanding and generation. We identify a fundamental challenge that lies in inductive biases induced by distinct supervision signals: generation branch prefers high-fidelity, fine-grained representations capable of reconstruction, while the understanding favours semantically discriminative embeddings that remain invariant to task-irrelevant factors. Consequently, optimizing these complementary but non-equivalent objectives within a monolithic backbone leads to mutual impairment instead of enhancement. In this paper, we first analyze the root cause of this interference in unified backbones and reveal a complementary structure in their internal representations. Motivated by the observation, we propose DIVA, a self-improved post-training framework that transforms the representation divergence into interior synergy. By explicitly factorizing the visual representation into shared and unique components based on two complementary information flow, DIVA enables both the understanding and generation branches to achieve beneficial transferring while preserving the integrity of unique information from cross-flow interference via mutual information estimation. Despite its generality, our method consistently achieves improvements across visual understanding (+7.82%) and generation (+8.46%). The official code is available at: https://github.com/Jayyy-H/DIVA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a representation divergence in unified multimodal models (UMMs) arising from distinct supervision signals: generation favors high-fidelity fine-grained features while understanding favors semantically invariant embeddings. It proposes DIVA, a post-training framework that explicitly factorizes visual representations into shared and unique components via complementary information flows and mutual information estimation, enabling beneficial transfer between understanding and generation branches while blocking cross-flow interference. Reported gains are +7.82% on visual understanding and +8.46% on generation tasks.
Significance. If the MI-based factorization cleanly separates shared and unique components without bias, variance, or information loss in high-dimensional embeddings, the approach would convert an identified source of mutual impairment into interior synergy and offer a general post-training recipe for UMMs. The claimed generality and consistent gains across tasks would be notable if substantiated by controlled ablations and comparisons.
major comments (2)
- [Abstract] Abstract: the central claim that 'explicit factorization ... via mutual information estimation' separates shared/unique components while 'preserving the integrity of unique information from cross-flow interference' is stated without any equation, estimator definition, or loss formulation; standard MI estimators are known to be biased or high-variance in high-dimensional visual features, so the claimed beneficial transferring does not automatically follow.
- [Abstract] Abstract: the motivation rests on the untested assertion that 'optimizing these complementary but non-equivalent objectives within a monolithic backbone leads to mutual impairment'; no quantitative evidence (e.g., representation similarity metrics, gradient conflict measures, or ablation removing one branch) is supplied to establish that the observed divergence is the root cause rather than a symptom.
minor comments (2)
- [Abstract] Abstract: headline percentages (+7.82%, +8.46%) are given without reference to the exact baselines, datasets, or evaluation protocols, preventing assessment of effect size or comparability.
- [Abstract] Abstract: the statement 'the official code is available at https://github.com/Jayyy-H/DIVA' should be accompanied by a reproducibility checklist or commit hash in the manuscript body.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below, clarifying how the manuscript handles the technical details and evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'explicit factorization ... via mutual information estimation' separates shared/unique components while 'preserving the integrity of unique information from cross-flow interference' is stated without any equation, estimator definition, or loss formulation; standard MI estimators are known to be biased or high-variance in high-dimensional visual features, so the claimed beneficial transferring does not automatically follow.
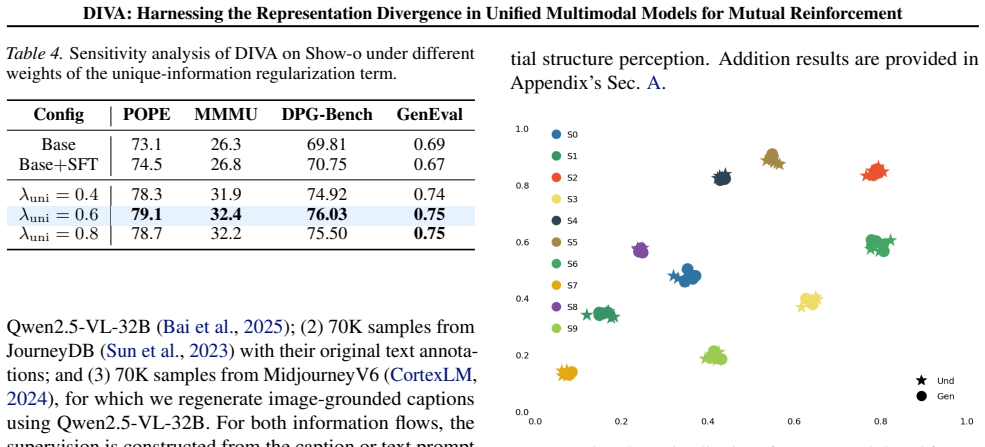
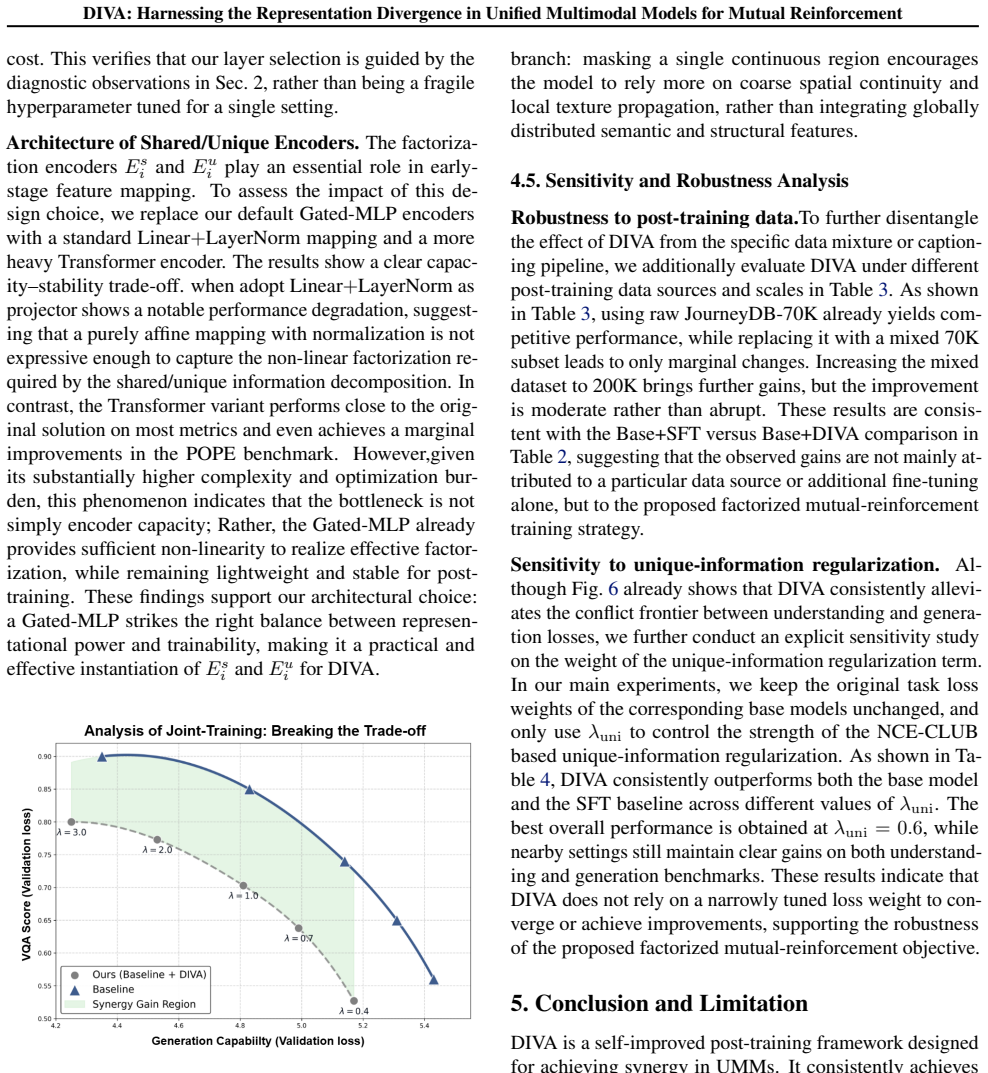
Authors: We agree the abstract omits equations and estimator specifics due to length constraints. The full manuscript details the MI estimator (a regularized neural estimator designed to control bias/variance in high-dimensional features), the complementary flow definitions, and the full loss in Section 3 with supporting equations. Ablations in the experiments confirm stable factorization and transfer gains without notable information loss. We will revise the abstract to reference Section 3 explicitly. revision: partial
-
Referee: [Abstract] Abstract: the motivation rests on the untested assertion that 'optimizing these complementary but non-equivalent objectives within a monolithic backbone leads to mutual impairment'; no quantitative evidence (e.g., representation similarity metrics, gradient conflict measures, or ablation removing one branch) is supplied to establish that the observed divergence is the root cause rather than a symptom.
Authors: The manuscript provides this analysis immediately after the abstract, including quantitative representation similarity metrics (e.g., cosine similarity across branches), gradient conflict measurements, and branch-removal ablations that isolate the impairment effect and confirm it as the root cause rather than a symptom. These appear in the motivation and preliminary analysis sections. No revision is required on this point. revision: no
Circularity Check
No circularity: method is a proposed post-training factorization using MI estimation
full rationale
The provided abstract and description introduce DIVA as a new framework that factorizes representations via mutual information estimation on complementary flows, motivated by an observed divergence. No equations, fitted parameters renamed as predictions, or self-citation chains are present that reduce the claimed gains or factorization to the inputs by construction. The derivation chain consists of analysis followed by an introduced technique whose validity rests on external empirical results rather than definitional equivalence or load-bearing self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Chen, J., Xu, Z., Pan, X., Hu, Y ., Qin, C., Goldstein, T., Huang, L., Zhou, T., Xie, S., Savarese, S., et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025a. Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., and Ruan, C. Janus-pro: Unified multimodal understa...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al. Emerging proper- ties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
SEED-X: Multimodal Models with Unified Multi-granularity Comprehension and Generation
Ge, Y ., Zhao, S., Zhu, J., Ge, Y ., Yi, K., Song, L., Li, C., Ding, X., and Shan, Y . Seed-x: Multimodal models with unified multi-granularity comprehension and generation. arXiv preprint arXiv:2404.14396,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Hu, X., Wang, R., Fang, Y ., Fu, B., Cheng, P., and Yu, G. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
SRUM: Fine-Grained Self-Rewarding for Unified Multimodal Models
Jin, W., Niu, Y ., Liao, J., Duan, C., Li, A., Gao, S., and Liu, X. Srum: Fine-grained self-rewarding for unified multimodal models.arXiv preprint arXiv:2510.12784,
work page internal anchor Pith review arXiv
-
[7]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs, B. F., Batifol, S., Blattmann, A., Boesel, F., Con- sul, S., Diagne, C., Dockhorn, T., English, J., English, Z., Esser, P., et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Llava- onevision: Easy visual task transfer.Trans
Li, B., Zhang, Y ., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y ., Liu, Z., and Li, C. Llava- onevision: Easy visual task transfer.Trans. Mach. Learn. Res., 2025,
2025
-
[9]
Evaluating object hallucination in large vision-language models
10 DIV A: Harnessing the Representation Divergence in Unified Multimodal Models for Mutual Reinforcement Li, Y ., Du, Y ., Zhou, K., Wang, J., Zhao, X., and Wen, J.-R. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empiri- cal methods in natural language processing, pp. 292–305,
2023
-
[10]
Mogao: An Omni Foundation Model for Interleaved Multi-Modal Generation
Liao, C., Liu, L., Wang, X., Luo, Z., Zhang, X., Zhao, W., Wu, J., Li, L., Tian, Z., and Huang, W. Mogao: An omni foundation model for interleaved multi-modal generation. arXiv preprint arXiv:2505.05472,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Liu, H., Li, C., Li, Y ., and Lee, Y . J. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 26296–26306, 2024a. Liu, S., Han, Y ., Xing, P., Yin, F., Wang, R., Cheng, W., Liao, J., Wang, Y ., Fu, H., Han, C., et al. Step1x-edit: A practical framework for general imag...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Decoupled Weight Decay Regularization
Liu, Y ., Duan, H., Zhang, Y ., Li, B., Zhang, S., Zhao, W., Yuan, Y ., Wang, J., He, C., Liu, Z., et al. Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pp. 216–233. Springer, 2024b. Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Niu, Y ., Ning, M., Zheng, M., Jin, W., Lin, B., Jin, P., Liao, J., Feng, C., Ning, K., Zhu, B., et al. Wise: A world knowledge-informed semantic evaluation for text- to-image generation.arXiv preprint arXiv:2503.07265,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Transfer between Modalities with MetaQueries
Pan, K., Lin, W., Yue, Z., Ao, T., Jia, L., Zhao, W., Li, J., Tang, S., and Zhang, H. Generative multimodal pre- training with discrete diffusion timestep tokens. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pp. 26136–26146, 2025a. Pan, X., Shukla, S. N., Singh, A., Zhao, Z., Mishra, S. K., Wang, J., Xu, Z., Chen, J., Li, K.,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Team, C. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Team, N., Han, C., Li, G., Wu, J., Sun, Q., Cai, Y ., Peng, Y ., Ge, Z., Zhou, D., Tang, H., et al. Nextstep-1: Toward autoregressive image generation with continuous tokens at scale.arXiv preprint arXiv:2508.10711,
-
[17]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024a. Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y ., Wang, J., Zhang, F., Wang, Y ., Li, Z., Yu, Q., et al. Emu3: Next-token prediction...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.-m., Bai, S., Xu, X., Chen, Y ., et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025a. Wu, C., Zheng, P., Yan, R., Xiao, S., Luo, X., Wang, Y ., Li, W., Jiang, X., Liu, Y ., Zhou, J., et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.188...
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
11 DIV A: Harnessing the Representation Divergence in Unified Multimodal Models for Mutual Reinforcement Xie, J., Mao, W., Bai, Z., Zhang, D. J., Wang, W., Lin, K. Q., Gu, Y ., Chen, Z., Yang, Z., and Shou, M. Z. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Reconstruction Alignment Improves Unified Multimodal Models
Xie, J., Darrell, T., Zettlemoyer, L., and Wang, X. Recon- struction alignment improves unified multimodal models. arXiv preprint arXiv:2509.07295,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Yan, Z., Lin, K., Li, Z., Ye, J., Han, H., Wang, Z., Liu, H., Lin, B., Li, H., Xu, X., et al. Can understanding and generation truly benefit together–or just coexist?arXiv preprint arXiv:2509.09666,
-
[22]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Ye, Y ., He, X., Li, Z., Lin, B., Yuan, S., Yan, Z., Hou, B., and Yuan, L. Imgedit: A unified image editing dataset and benchmark.arXiv preprint arXiv:2505.20275,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Yu, W., Yang, Z., Li, L., Wang, J., Lin, K., Liu, Z., Wang, X., and Wang, L. Mm-vet: Evaluating large multi- modal models for integrated capabilities.arXiv preprint arXiv:2308.02490,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Zhao, C., Song, Y ., Wang, W., Feng, H., Ding, E., Sun, Y ., Xiao, X., and Wang, J. Monoformer: One transformer for both diffusion and autoregression.arXiv preprint arXiv:2409.16280, 2024a. Zhao, H., Ma, X. S., Chen, L., Si, S., Wu, R., An, K., Yu, P., Zhang, M., Li, Q., and Chang, B. Ultraedit: Instruction- based fine-grained image editing at scale.Advan...
-
[25]
Related work
12 DIV A: Harnessing the Representation Divergence in Unified Multimodal Models for Mutual Reinforcement A. Related work. A.1. Unified Multimodal Models (UMMs) Vision-Language Models (VLMs) have demonstrated remarkable progress in multimodal understanding and reasoning, enabled by combining Large Language Models (LLMs) with powerful visual encoders (Liu e...
2023
-
[26]
Despite its simple architecture, experiments (Zhang et al., 2025; Deng et al.,
select discretize visual data into a sequence of tokens, and then jointly model it with text in the same Transformer. Despite its simple architecture, experiments (Zhang et al., 2025; Deng et al.,
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.