Not only where, But when: Temporal Scheduling for RLVR
Pith reviewed 2026-06-29 22:32 UTC · model grok-4.3
The pith
Scheduling credit allocation criteria over RLVR training, starting with targeted policy behaviors then shifting to general optimization, yields more stable and efficient learning than fixed criteria.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
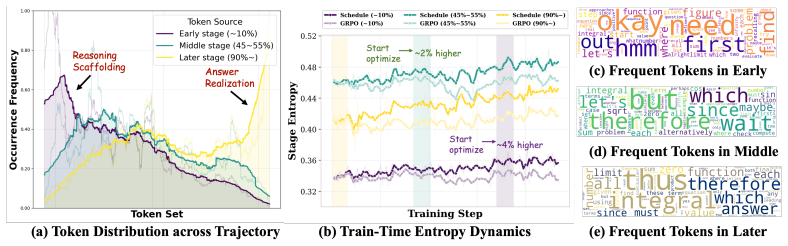
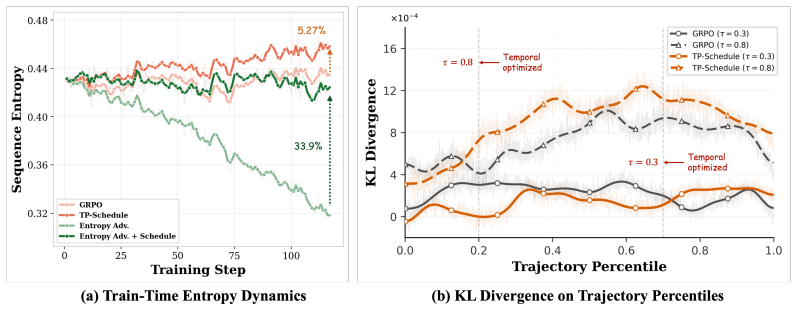
The central claim is that introducing the temporal dimension to credit allocation—prioritizing targeted tokens emphasized with specific policy behaviors early in training and gradually attenuating toward general optimization—produces more stable and efficient learning dynamics. Simple trajectory percentiles distinguish those behaviors effectively when paired with the schedule. Standard optimization sacrifices policy entropy when it must accommodate heterogeneous behaviors at once, whereas the scheduled approach supports healthier evolution. Experiments on mathematical and general reasoning benchmarks show consistent improvements.
What carries the argument
Temporal scheduling of credit allocation criteria, using trajectory percentiles to distinguish policy behaviors and gradually shifting emphasis from specific to general optimization.
If this is right
- Standard fixed allocation sacrifices policy entropy when handling heterogeneous behaviors simultaneously.
- Temporal scheduling produces healthier policy evolution dynamics across training.
- Experiments yield consistent performance gains on both mathematical and general reasoning benchmarks.
- Simple trajectory percentiles work effectively as the criterion when paired with the temporal schedule.
Where Pith is reading between the lines
- The temporal dimension could be combined with other existing credit-allocation techniques beyond percentiles.
- The same scheduling logic might reduce sensitivity to initial hyperparameter choices in RLVR setups.
- If the entropy preservation holds, it could extend the effective training horizon before policy collapse occurs.
Load-bearing premise
Trajectory percentiles supply a stable way to separate policy behaviors that combines with temporal scheduling without creating new instabilities or needing heavy tuning.
What would settle it
A controlled run that applies the proposed temporal schedule with trajectory percentiles yet shows no gain in benchmark scores or increased training variance relative to a fixed-allocation baseline.
Figures


read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has become a core technique for post-training of Large Language Models (LLMs). While policy optimization is driven by all sampled tokens under a globally broadcast scalar reward, the heterogeneous policy behaviors exhibited along trajectories are largely overlooked without differentiation. Existing works address this by credit allocation, including token-level advantage reweighting, and selective token optimization, however, the allocation criterion are principally stagnant throughout training, limiting resilient policy evolution. In this work, we argue that \textit{when} learning signals are scheduled can be as important as \textit{where} they are allocated across tokens, and introduce the temporal dimension that scheduling the credit allocation criteria over the course of RLVR optimization. We find that prioritizing targeted tokens emphasized with specific policy behaviors, and gradually attenuating toward general optimization leads to more stable and efficient learning dynamics. Furthermore, we show that simple trajectory percentiles provide a natural perspective for distinguishing policy behaviors, and works effectively with temporal scheduling. Our analysis reveals that standard optimization substantially sacrifices policy entropy when simultaneously accommodating heterogeneous behaviors, whereas temporal scheduling yields healthier policy evolution dynamics. Experiments across mathematical and general reasoning benchmarks demonstrate consistent improvements, suggesting that temporal scheduling constitutes a promising optimization dimension.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in RLVR for LLMs, adding a temporal dimension to credit allocation—by using simple trajectory percentiles to distinguish heterogeneous policy behaviors, initially prioritizing targeted tokens with specific behaviors, and gradually attenuating toward general optimization—yields more stable and efficient learning, healthier entropy dynamics than standard RLVR, and consistent gains on mathematical and general reasoning benchmarks.
Significance. If the results hold, the work usefully highlights the 'when' of credit allocation as a complementary axis to 'where' (token-level allocation), with the entropy analysis providing a concrete diagnostic of policy evolution. The simplicity of the percentile heuristic is a potential strength if shown to be robust.
major comments (2)
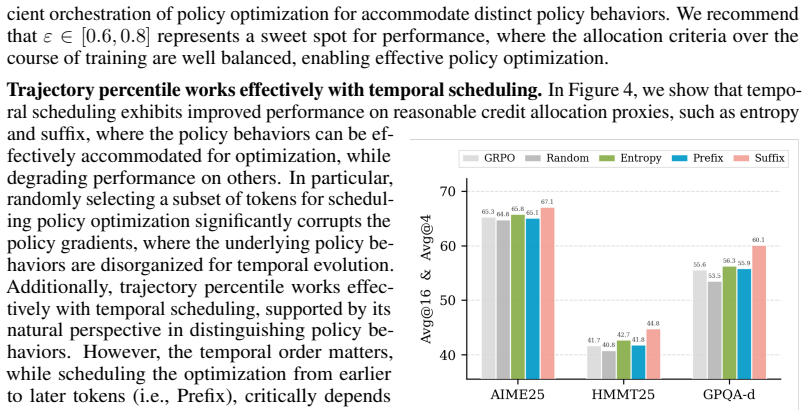
- [§3.2] §3.2 (Temporal Scheduling): The claim that trajectory percentiles 'naturally' separate policy behaviors for stable combination with temporal scheduling is load-bearing for the central contribution, yet the section provides no derivation or sensitivity analysis showing why percentile thresholds remain effective across reward variance levels or model scales; without this, the stability benefit over static allocation is not secured.
- [§5.1] §5.1, Experiments: The reported consistent improvements and entropy benefits lack ablations on percentile thresholds (e.g., 50th vs. 75th) or schedule attenuation rate; this directly bears on the skeptic concern that the method may require extensive tuning or introduce instabilities, undermining the assertion that the approach is both natural and robust.
minor comments (2)
- [Figure 2] Figure 2 caption: the y-axis label for entropy is ambiguous (policy entropy vs. token-level entropy) and should be clarified for reproducibility.
- [Related Work] Related work section omits direct comparison to recent token-level advantage reweighting methods that also aim at heterogeneous behaviors.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our central claims. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Temporal Scheduling): The claim that trajectory percentiles 'naturally' separate policy behaviors for stable combination with temporal scheduling is load-bearing for the central contribution, yet the section provides no derivation or sensitivity analysis showing why percentile thresholds remain effective across reward variance levels or model scales; without this, the stability benefit over static allocation is not secured.
Authors: We agree that §3.2 presents the percentile heuristic as an empirical observation rather than a formal derivation. The separation is motivated by the fact that trajectory percentiles reliably surface distinct behavioral modes (high-percentile trajectories concentrate on targeted tokens while lower ones reflect broader exploration). We will add a sensitivity analysis in the revision that varies percentile thresholds under controlled reward-variance conditions to quantify robustness. Analysis across model scales is not feasible within current compute limits and is noted as a limitation. revision: partial
-
Referee: [§5.1] §5.1, Experiments: The reported consistent improvements and entropy benefits lack ablations on percentile thresholds (e.g., 50th vs. 75th) or schedule attenuation rate; this directly bears on the skeptic concern that the method may require extensive tuning or introduce instabilities, undermining the assertion that the approach is both natural and robust.
Authors: We accept that additional ablations are needed to address tuning concerns. In the revised §5.1 we will report results for 50th, 75th, and 90th percentile thresholds together with linear and exponential attenuation schedules. These experiments will demonstrate that performance and entropy benefits remain consistent across the tested configurations, supporting the claim of robustness without extensive per-run tuning. revision: yes
Circularity Check
No significant circularity; empirical heuristic with independent experimental support
full rationale
The paper introduces temporal scheduling as an empirical heuristic for credit allocation in RLVR, using trajectory percentiles to distinguish behaviors and gradually attenuating prioritization. No equations, derivations, or first-principles claims are present that reduce by construction to fitted parameters or self-citations. Central claims rest on analysis of entropy dynamics and benchmark experiments rather than self-definitional loops or load-bearing self-citations. The approach is framed as a practical scheduling method, not a closed mathematical reduction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv prep...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Jiaru Zou, Ling Yang, Jingwen Gu, Jiahao Qiu, Ke Shen, Jingrui He, and Mengdi Wang. Reasonflux- prm: Trajectory-aware prms for long chain-of-thought reasoning in llms.arXiv preprint arXiv:2506.18896,
-
[4]
Jian Zhao, Runze Liu, Kaiyan Zhang, Zhimu Zhou, Junqi Gao, Dong Li, Jiafei Lyu, Zhouyi Qian, Biqing Qi, Xiu Li, et al. Genprm: Scaling test-time compute of process reward models via generative reasoning.arXiv preprint arXiv:2504.00891,
-
[5]
Reasoning with Exploration: An Entropy Perspective
Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Wayne Xin Zhao, Zhenliang Zhang, and Furu Wei. Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
Mehul Damani, Isha Puri, Stewart Slocum, Idan Shenfeld, Leshem Choshen, Yoon Kim, and Jacob Andreas. Beyond binary rewards: Training lms to reason about their uncertainty.arXiv preprint arXiv:2507.16806,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Zhihe Yang, Xufang Luo, Zilong Wang, Dongqi Han, Zhiyuan He, Dongsheng Li, and Yunjian Xu. Do not let low-probability tokens over-dominate in rl for llms.arXiv preprint arXiv:2505.12929, 2025b. Chiyu Ma, Shuo Yang, Kexin Huang, Jinda Lu, Haoming Meng, Shangshang Wang, Bolin Ding, Soroush V osoughi, Guoyin Wang, and Jingren Zhou. Fipo: Eliciting deep reaso...
-
[8]
Kexin Huang, Haoming Meng, Junkang Wu, Jinda Lu, Chiyu Ma, Ziqian Chen, Xue Wang, Bolin Ding, Jiancan Wu, Xiang Wang, et al. On the direction of rlvr updates for llm reasoning: Identifi- cation and exploitation.arXiv preprint arXiv:2603.22117,
-
[9]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
10 Ivan Moshkov, Darragh Hanley, Ivan Sorokin, Shubham Toshniwal, Christof Henkel, Benedikt Schif- ferer, Wei Du, and Igor Gitman. Aimo-2 winning solution: Building state-of-the-art mathematical reasoning models with openmathreasoning dataset.arXiv preprint arXiv:2504.16891,
-
[13]
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, et al. Deepmath-103k: A large-scale, challenging, de- contaminated, and verifiable mathematical dataset for advancing reasoning.arXiv preprint arXiv:2504.11456,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
Mislav Balunovi´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi´c, and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions.arXiv preprint arXiv:2505.23281,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Zayne Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. Musr: Testing the limits of chain-of-thought with multistep soft reasoning.arXiv preprint arXiv:2310.16049,
-
[20]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy-distillation. Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.64434/tml.20251026
-
[23]
Haoming Meng, Kexin Huang, Shaohang Wei, Chiyu Ma, Shuo Yang, Xue Wang, Guoyin Wang, Bolin Ding, and Jingren Zhou. Sparse but critical: A token-level analysis of distributional shifts in rlvr fine-tuning of llms.arXiv preprint arXiv:2603.22446,
-
[24]
Xingwu Chen, Tianle Li, and Difan Zou. Reshaping reasoning in llms: A theoretical analysis of rl training dynamics through pattern selection.arXiv preprint arXiv:2506.04695,
-
[25]
Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning
Maggie Huan, Yuetai Li, Tuney Zheng, Xiaoyu Xu, Seungone Kim, Minxin Du, Radha Pooven- dran, Graham Neubig, and Xiang Yue. Does math reasoning improve general llm capabilities? understanding transferability of llm reasoning.arXiv preprint arXiv:2507.00432,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
11 Minsang Kim and Seung Jun Baek. Explain in your own words: Improving reasoning via token- selective dual knowledge distillation.arXiv preprint arXiv:2603.13260,
-
[27]
TIP: Token Importance in On-Policy Distillation
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. Tip: Token importance in on-policy distillation.arXiv preprint arXiv:2604.14084,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
The learning rate follows a constant schedule
We conduct experiments on 8 H200 GPUs, and uses AdamW optimizer with weight decay of 0.1. The learning rate follows a constant schedule. Gradient clipping is applied with maximum gradient norm set to 1.0. During training, we use 2048 sampled trajectories for policy optimization at each update step, and perform on-policy rollout generation throughout train...
2048
-
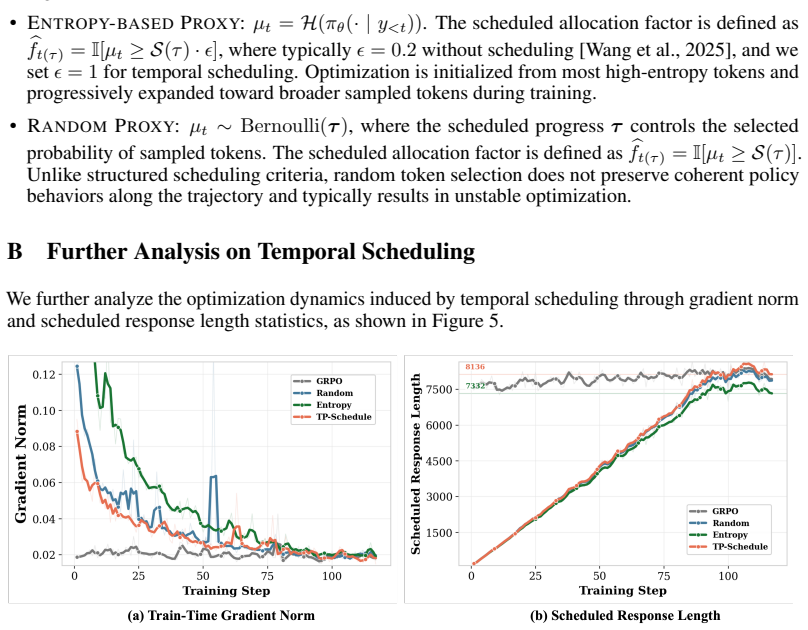
[29]
The scheduled allocation factor is defined as bft(τ) =I[µ t ≥ S(τ)·ϵ], where typicallyϵ= 0.2without scheduling [Wang et al., 2025], and we setϵ= 1for temporal scheduling
• ENTROPY-BASEDPROXY: µt =H(π θ(· |y <t)). The scheduled allocation factor is defined as bft(τ) =I[µ t ≥ S(τ)·ϵ], where typicallyϵ= 0.2without scheduling [Wang et al., 2025], and we setϵ= 1for temporal scheduling. Optimization is initialized from most high-entropy tokens and progressively expanded toward broader sampled tokens during training. • RANDOMPRO...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.