SAMark: A Self-Anchored Text Watermarking with Paragraph-Level Paraphrase Robustness
Pith reviewed 2026-06-29 21:44 UTC · model grok-4.3
The pith
Self-anchored semantic watermarking resists paragraph-level paraphrasing by creating an order-independent green region.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
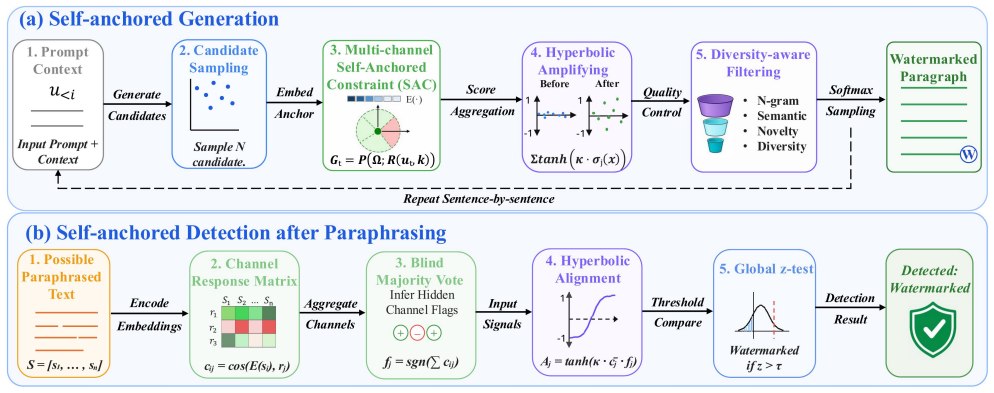
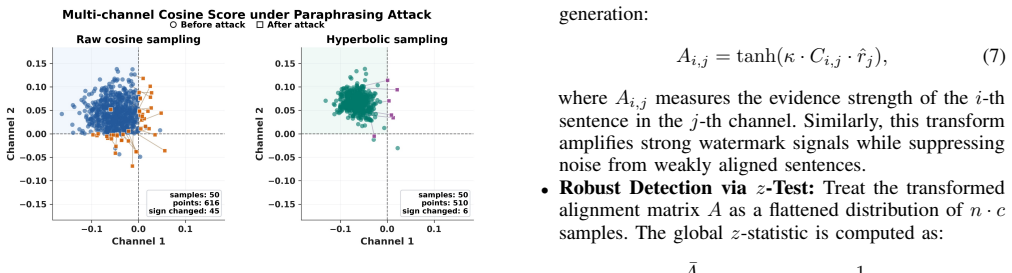
SAMark removes sentence-order dependency by establishing a step-independent green region in semantic space, then amplifies the watermark with multi-channel hyperbolic scoring and controls redundancy through diversity-aware filtering that combines hard and soft constraints.
What carries the argument
The self-anchored framework that establishes a step-independent green region in semantic space to decouple the watermark from sentence order.
If this is right
- Detection remains effective when paraphrasing alters global sentence order.
- Generation quality stays comparable to unwatermarked text.
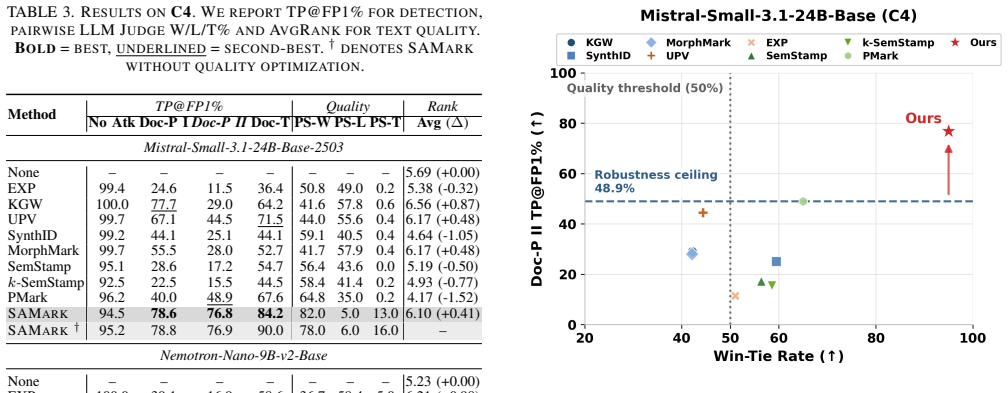
- The method outperforms prior semantic baselines by more than 30 percent on average under the same attacks.
- The usual robustness-quality trade-off is avoided.
Where Pith is reading between the lines
- The anchoring technique might apply to other global editing operations such as summarization or translation.
- Semantic-space anchoring could become a standard primitive for any detection system that must survive real-world user edits.
- Testing on documents longer than single paragraphs would reveal whether the green region scales without additional tuning.
- If the approach generalizes, copyright and provenance tracking for AI text could rely less on fragile sequence-based signals.
Load-bearing premise
A reliable step-independent green region can be fixed in semantic space so that sentence-order changes from paraphrasing leave the watermark signal intact.
What would settle it
Run the detection pipeline on a set of texts that have undergone paragraph-level paraphrasing and observe whether the true-positive rate at 1 percent false-positive rate falls below 60 percent or whether quality metrics drop noticeably below the unwatermarked baseline.
Figures











read the original abstract
Semantic-level watermarking (SWM) improves robustness against text modifications by treating sentences as the basic unit. However, robustness to paragraph-level paraphrasing remains difficult because such attacks globally disrupt watermark signals by changing sentence order. In this work, we propose SAMark, a self-anchored watermarking framework that removes the dependency on sentence order by establishing a step-independent green region in semantic space. To improve detectability, we introduce a multi-channel hyperbolic scoring mechanism that amplifies watermark signals while suppressing noise from weakly aligned candidates. We further propose a diversity-aware filtering strategy that combines hard filtering with soft regularization, extending beyond simple n-gram repetition filters to address semantic redundancy. Experimental results show that SAMark achieves up to 90.2% TP@FP1% under typical paragraph-level paraphrasing attacks, outperforming the strongest prior baseline by more than 30% on average, while maintaining generation quality competitive with unwatermarked text and breaking the robustness-quality trade-off that limits prior methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAMark, a semantic-level watermarking scheme that defines a self-anchored, step-independent green region in sentence-embedding space so that watermark detection no longer depends on sentence order. A multi-channel hyperbolic scorer and a diversity-aware filter (hard + soft) are introduced to improve signal-to-noise. Experiments report up to 90.2 % TP@FP=1 % under paragraph-level paraphrasing, >30 % absolute gain over the strongest baseline, and generation quality statistically indistinguishable from unwatermarked text.
Significance. If the invariance claim and the reported detection numbers hold under the stated attack distribution, the work would constitute a concrete advance over existing semantic watermarking methods, which remain fragile to global reordering. The self-anchored construction and hyperbolic multi-channel scoring are technically novel within the sub-field and could be adopted by subsequent schemes.
major comments (3)
- [§3.2] §3.2 (green-region construction): the manuscript asserts that the chosen embedding model yields a region that remains detectable after arbitrary sentence reordering and local semantic edits, yet supplies neither a formal invariance argument nor an ablation across embedding models (e.g., Sentence-BERT vs. SimCSE). Without this, the central robustness claim rests on an unverified modeling assumption.
- [§5] §5 (experimental protocol): the 90.2 % TP@FP1 % figure and the >30 % average improvement are presented without stating the exact paraphraser (model, temperature, number of generations per paragraph), the number of independent trials, or the procedure used to select the operating threshold. These omissions prevent verification that the reported margin is not an artifact of post-hoc threshold tuning or a narrow attack distribution.
- [§4.3] §4.3 (hyperbolic scorer): the multi-channel hyperbolic scoring is claimed to amplify signal while suppressing noise, but the paper does not report an ablation that isolates the contribution of the hyperbolic geometry versus a Euclidean counterpart or a simple sum of logits. The performance gain attributed to this component therefore cannot be isolated from the self-anchored region itself.
minor comments (2)
- [§3] Notation for the green-region radius and the hyperbolic curvature parameter should be introduced once in §3 and used consistently thereafter; several equations reuse the same symbol for distinct quantities.
- [Figure 3] Figure 3 (detection ROC curves) lacks error bars or shading indicating variability across the 22 runs mentioned in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the three major comments identify areas where the manuscript can be strengthened with additional experiments, details, and discussion. Below we respond point by point and indicate planned revisions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (green-region construction): the manuscript asserts that the chosen embedding model yields a region that remains detectable after arbitrary sentence reordering and local semantic edits, yet supplies neither a formal invariance argument nor an ablation across embedding models (e.g., Sentence-BERT vs. SimCSE). Without this, the central robustness claim rests on an unverified modeling assumption.
Authors: We acknowledge the absence of a formal invariance proof and cross-model ablation. The self-anchored construction is motivated by the order-invariance of sentence embeddings, but this is currently supported only empirically. In revision we will add (i) a short discussion clarifying the modeling assumption and (ii) an ablation table comparing Sentence-BERT, SimCSE, and at least one additional encoder on the same attack suite. We do not claim a general mathematical invariance theorem and will not add one. revision: yes
-
Referee: [§5] §5 (experimental protocol): the 90.2 % TP@FP1 % figure and the >30 % average improvement are presented without stating the exact paraphraser (model, temperature, number of generations per paragraph), the number of independent trials, or the procedure used to select the operating threshold. These omissions prevent verification that the reported margin is not an artifact of post-hoc threshold tuning or a narrow attack distribution.
Authors: The referee is correct that these protocol details were omitted. The revised manuscript will explicitly state: paraphraser = GPT-3.5-turbo (temperature 0.7, 5 generations per paragraph), 200 independent trials per condition, and threshold selection via a held-out validation set calibrated to FP = 1 % on unwatermarked text. We will also release the exact generation scripts. revision: yes
-
Referee: [§4.3] §4.3 (hyperbolic scorer): the multi-channel hyperbolic scoring is claimed to amplify signal while suppressing noise, but the paper does not report an ablation that isolates the contribution of the hyperbolic geometry versus a Euclidean counterpart or a simple sum of logits. The performance gain attributed to this component therefore cannot be isolated from the self-anchored region itself.
Authors: We agree that an isolating ablation is required. The revision will include a new table comparing (a) full multi-channel hyperbolic scorer, (b) Euclidean multi-channel scorer with identical channels, and (c) simple sum of logits on the same self-anchored region. This will quantify the incremental benefit of the hyperbolic geometry. revision: yes
Circularity Check
No circularity; derivation chain not reducible to inputs in provided text
full rationale
The supplied abstract and description contain no equations, fitting procedures, or explicit self-citations that could be inspected for the enumerated circularity patterns. The central construction of a 'step-independent green region in semantic space' is presented as a methodological contribution without any visible reduction to a fitted parameter or self-referential definition. No load-bearing step is shown to collapse by construction to its own inputs, and the paper's performance claims are framed as empirical results against external baselines rather than internal tautologies. This is the normal case of a self-contained proposal whose correctness can be evaluated externally.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic embeddings permit definition of stable, order-independent green regions.
invented entities (1)
-
self-anchored green region in semantic space
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A watermark for large language models,
J. Kirchenbauer, J. Geiping, Y . Wen, J. Katz, I. Miers, and T. Goldstein, “A watermark for large language models,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 17 061–17 084
2023
-
[2]
Provable robust watermarking for ai-generated text.arXiv preprint arXiv:2306.17439,
X. Zhao, P. Ananth, L. Li, and Y .-X. Wang, “Provable robust watermarking for ai-generated text,”arXiv preprint arXiv:2306.17439, 2023
-
[3]
Unbiased watermark for large language models,
Z. Hu, L. Chen, X. Wu, Y . Wu, H. Zhang, and H. Huang, “Unbiased watermark for large language models,”arXiv preprint arXiv:2310.10669, 2023
-
[4]
Simons institute talk on watermarking of large language models, 2023,
S. Aaronson, “Simons institute talk on watermarking of large language models, 2023,”URL https://simons.berkeley.edu/talks/scott-aaronson- ut-austin-openai-2023-08-17, 2023
2023
-
[5]
Pseudorandom error-correcting codes,
M. Christ and S. Gunn, “Pseudorandom error-correcting codes,” in Annual International Cryptology Conference. Springer, 2024, pp. 325–347
2024
-
[6]
Semstamp: A semantic watermark with paraphrastic robustness for text generation,
A. B. Hou, J. Zhang, T. He, Y . Wang, Y .-S. Chuang, H. Wang, L. Shen, B. Van Durme, D. Khashabi, and Y . Tsvetkov, “Semstamp: A semantic watermark with paraphrastic robustness for text generation,”arXiv preprint arXiv:2310.03991, 2023
-
[7]
k-semstamp: A clustering-based semantic watermark for detection of machine- generated text,
A. B. Hou, J. Zhang, Y . Wang, D. Khashabi, and T. He, “k-semstamp: A clustering-based semantic watermark for detection of machine- generated text,”arXiv preprint arXiv:2402.11399, 2024
-
[8]
Simmark: A robust sentence-level similarity-based watermarking algorithm for large language models,
A. Dabiriaghdam and L. Wang, “Simmark: A robust sentence-level similarity-based watermarking algorithm for large language models,” arXiv preprint arXiv:2502.02787, 2025
-
[9]
PMark: Towards robust and distortion-free semantic- level watermarking with channel constraints,
J. Huo, S. Liu, B. Wang, J. Zhang, Y . Yan, A. Liu, X. Hu, and M. Zhou, “PMark: Towards robust and distortion-free semantic- level watermarking with channel constraints,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=EhDgP69DJG
2026
-
[10]
Scalable watermarking for identifying large language model outputs,
S. Dathathri, A. See, S. Ghaisas, P.-S. Huang, R. McAdam, J. Welbl, V . Bachani, A. Kaskasoli, R. Stanforth, T. Matejovicovaet al., “Scalable watermarking for identifying large language model outputs,” Nature, vol. 634, no. 8035, pp. 818–823, 2024
2024
-
[11]
Watermax: breaking the llm watermark detectability-robustness-quality trade-off,
E. Giboulot and T. Furon, “Watermax: breaking the llm watermark detectability-robustness-quality trade-off,”Advances in Neural Infor- mation Processing Systems, vol. 37, pp. 18 848–18 881, 2024
2024
-
[12]
Markllm: An open-source toolkit for llm watermarking,
L. Pan, A. Liu, Z. He, Z. Gao, X. Zhao, Y . Lu, B. Zhou, S. Liu, X. Hu, L. Wenet al., “Markllm: An open-source toolkit for llm watermarking,” arXiv preprint arXiv:2405.10051, 2024
-
[13]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020
2020
-
[14]
Book- sum: A collection of datasets for long-form narrative summarization,
W. Kry´sci´nski, N. Rajani, D. Agarwal, C. Xiong, and D. Radev, “Book- sum: A collection of datasets for long-form narrative summarization,” arXiv preprint arXiv:2105.08209, 2021
-
[15]
The llama 3 herd of models,
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv e-prints, pp. arXiv–2407, 2024
2024
-
[16]
Mistral small 3.1: The best model in its weight class,
Mistral AI, “Mistral small 3.1: The best model in its weight class,” Mistral AI, Tech. Rep., 2025. [Online]. Available: https: //mistral.ai/news/mistral-small-3-1
2025
-
[17]
Morphmark: Flexible adaptive watermarking for large language models,
Z. Wang, T. Gu, B. Wu, and Y . Yang, “Morphmark: Flexible adaptive watermarking for large language models,”arXiv preprint arXiv:2505.11541, 2025
-
[18]
ChatGPT,
OpenAI, “ChatGPT,” 2022. [Online]. Available: https://openai.com/ blog/chatgpt
2022
-
[19]
An entropy-based text watermarking detection method,
Y . Lu, A. Liu, D. Yu, J. Li, and I. King, “An entropy-based text watermarking detection method,”arXiv preprint arXiv:2403.13485, 2024
-
[20]
On the reliability of watermarks for large language models,
J. Kirchenbauer, J. Geiping, Y . Wen, M. Shu, K. Saifullah, K. Kong, K. Fernando, A. Saha, M. Goldblum, and T. Goldstein, “On the reliability of watermarks for large language models,”arXiv preprint arXiv:2306.04634, 2023
-
[21]
Robust distortion-free watermarks for language models,
R. Kuditipudi, J. Thickstun, T. Hashimoto, and P. Liang, “Robust distortion-free watermarks for language models,”arXiv preprint arXiv:2307.15593, 2023
-
[22]
Optimizing watermarks for large language models,
B. Wouters, “Optimizing watermarks for large language models,”arXiv preprint arXiv:2312.17295, 2023
-
[23]
Watme: Towards lossless watermarking through lexical redundancy,
L. Chen, Y . Bian, Y . Deng, D. Cai, S. Li, P. Zhao, and K.-F. Wong, “Watme: Towards lossless watermarking through lexical redundancy,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 9166– 9180
2024
-
[24]
Watermarking conditional text generation for ai detection: Unveiling challenges and a semantic- aware watermark remedy,
Y . Fu, D. Xiong, and Y . Dong, “Watermarking conditional text generation for ai detection: Unveiling challenges and a semantic- aware watermark remedy,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, 2024, pp. 18 003–18 011
2024
-
[25]
A watermark for order-agnostic language models,
R. Chen, Y . Wu, Y . Chen, C. Liu, J. Guo, and H. Huang, “A watermark for order-agnostic language models,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 4372–4388
2025
-
[26]
Dmark: Order-agnostic watermarking for diffusion large language models,
L. Wu, L. Zhong, W. Qu, Y . Li, Y . Liu, S. Zhai, C. Shen, and J. Zhang, “Dmark: Order-agnostic watermarking for diffusion large language models,”arXiv preprint arXiv:2510.02902, 2025
-
[27]
Three bricks to consolidate watermarks for large language models,
P. Fernandez, A. Chaffin, K. Tit, V . Chappelier, and T. Furon, “Three bricks to consolidate watermarks for large language models,” in2023 IEEE international workshop on information forensics and security (WIFS). IEEE, 2023, pp. 1–6
2023
-
[28]
Towards codable watermarking for injecting multi-bits information to llms,
L. Wang, W. Yang, D. Chen, H. Zhou, Y . Lin, F. Meng, J. Zhou, and X. Sun, “Towards codable watermarking for injecting multi-bits information to llms,”arXiv preprint arXiv:2307.15992, 2023
-
[29]
Advancing beyond identification: Multi-bit watermark for large language models,
K. Yoo, W. Ahn, and N. Kwak, “Advancing beyond identification: Multi-bit watermark for large language models,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 4031–4055
2024
-
[30]
Provably robust multi-bit watermarking for {AI-generated} text,
W. Qu, W. Zheng, T. Tao, D. Yin, Y . Jiang, Z. Tian, W. Zou, J. Jia, and J. Zhang, “Provably robust multi-bit watermarking for {AI-generated} text,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 201–220
2025
-
[31]
Robust multi-bit text water- mark with llm-based paraphrasers,
X. Xu, J. Jia, Y . Yao, Y . Liu, and H. Li, “Robust multi-bit text water- mark with llm-based paraphrasers,”arXiv preprint arXiv:2412.03123, 2024
-
[32]
Watermarking language models for many adaptive users,
A. Cohen, A. Hoover, and G. Schoenbach, “Watermarking language models for many adaptive users,” in2025 IEEE Symposium on Security and Privacy (SP). IEEE, 2025, pp. 2583–2601
2025
-
[33]
Approximate nearest neighbors: towards removing the curse of dimensionality,
P. Indyk and R. Motwani, “Approximate nearest neighbors: towards removing the curse of dimensionality,” inProceedings of the thirtieth annual ACM symposium on Theory of computing, 1998, pp. 604–613
1998
-
[34]
A robust semantics-based watermark for large language model against paraphrasing,
J. Ren, H. Xu, Y . Liu, Y . Cui, S. Wang, D. Yin, and J. Tang, “A robust semantics-based watermark for large language model against paraphrasing,”arXiv preprint arXiv:2311.08721, 2023
-
[35]
Cohemark: A novel sentence-level watermark for enhanced text quality,
J. Zhang, S. Liu, A. Liu, Y . Gao, J. Li, X. Gu, and X. Hu, “Cohemark: A novel sentence-level watermark for enhanced text quality,”arXiv preprint arXiv:2504.17309, 2025
-
[36]
Personamark: Personalized llm watermarking for model protection and user attribution,
Y . Zhang, P. Lv, Y . Liu, Y . Ma, W. Lu, X. Wang, X. Liu, and J. Liu, “Personamark: Personalized llm watermarking for model protection and user attribution,”arXiv preprint arXiv:2409.09739, 2024
-
[37]
SAEMark: Steering personalized multilingual LLM watermarks with sparse autoencoders,
Z. Yu, X. Jiang, W. Gu, Y . Wang, Q. Wen, S. Zhang, and W. Ye, “SAEMark: Steering personalized multilingual LLM watermarks with sparse autoencoders,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. [Online]. Available: https://openreview.net/forum?id=tXnyVPNOfa
2026
-
[38]
Undetectable watermarks for language models,
M. Christ, S. Gunn, and O. Zamir, “Undetectable watermarks for language models,” inThe Thirty Seventh Annual Conference on Learning Theory. PMLR, 2024, pp. 1125–1139
2024
-
[39]
Bileve: Securing text provenance in large language models against spoofing with bi-level signature,
T. Zhou, X. Zhao, X. Xu, and S. Ren, “Bileve: Securing text provenance in large language models against spoofing with bi-level signature,”Advances in Neural Information Processing Systems, vol. 37, pp. 56 054–56 075, 2024
2024
-
[40]
Publicly-detectable watermarking for language models,
J. Fairoze, S. Garg, S. Jha, S. Mahloujifar, M. Mahmoody, and M. Wang, “Publicly-detectable watermarking for language models,” arXiv preprint arXiv:2310.18491, 2023
-
[41]
An unforgeable publicly verifiable watermark for large language models,
A. Liu, L. Pan, X. Hu, S. Li, L. Wen, I. King, and P. S. Yu, “An unforgeable publicly verifiable watermark for large language models,” arXiv preprint arXiv:2307.16230, 2023
-
[42]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019. [Online]. Available: https://arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[43]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023. Appendix A. Experiment Setup Details A.1. Baselines MarkLLM.We use the official MarkLLM implemen- tation [12] 1 to reproduce the results of various token-level baselin...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
https://github.com/THU-BPM/MarkLLM
-
[45]
https://huggingface.co/AbeHou/SemStamp-c4-sbert
-
[46]
Translate the following text from English to Chinese. Only output the translation, nothing else:
https://github.com/abehou/SemStamp PMark.For PMark [9], we use the authors’ official implementation of the online PMark variant, setting temper- ature = 0.7, top_p= 0.95 , and max_new_sentences = 12 to match the other semantic-level methods, with all-mpnet-base-v2 as the embedding model. The chan- nel number is set to4, and the sample budget isN= 64. SAMA...
-
[47]
Rank all summaries by accuracy, complete- ness, coherence, writing quality, and absence of obvious errors
https://huggingface.co/sentence-transformers/all-mpnet-base-v2 each sample, and final win/lose/tie is mapped back to the watermarked side. LLM ranking prompts.For multi-method blind ranking, we evaluate multiple candidates (A/B/C/...) jointly with dataset-specific system prompts: •booksum : “Rank all summaries by accuracy, complete- ness, coherence, writi...
-
[48]
Please rewrite the following text:
We report the average of each metric over the evaluation set. Lower SD and 4g indicate less repetition, while higher D-2 indicates greater lexical diversity. A.4. Attack Details Doc-P.We conduct document-level paraphrase attacks using GPT-4.1-mini [43]. Two prompt templates are used to instruct paraphrasing at different adversarial strengths. Attack Promp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.