Mapping the Schedule x Bit-Width Boundary in Sub-100M Quantisation-Aware Training
Pith reviewed 2026-06-29 23:08 UTC · model grok-4.3
The pith
Optimal warmdown fraction stays 33 percent from FP16 through INT6 in sub-100M QAT, with INT4 showing a noise-to-decisive transition at 50M parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A 720-run grid over bit-width, warmdown fraction, learning-rate magnitude, model size and seed shows the optimal warmdown is 33 percent at every FP16/INT8/INT6 cell; the null result survives five axes of variation in a 625-run follow-up and is supported by a log-linear INT6 penalty that predicts held-out sizes. For INT4 the regime shifts from noise-dominated below 50M to decisive 33 percent preference at and above 50M.
What carries the argument
Factorial grid of bit-width by warmdown fraction by model size experiments that isolate schedule-bit-width interaction while measuring weight-to-grid distance to rule out rapid snapping.
If this is right
- At sub-100M scale the learning-rate schedule can be tuned once at FP16 and reused for INT8 and INT6 QAT without loss of optimality.
- INT4 training at 50M parameters and above requires the 33 percent warmdown; below 50M no schedule choice stands out from seed variation.
- The INT6 penalty follows a log-linear scaling law that extrapolates accurately to unseen sizes.
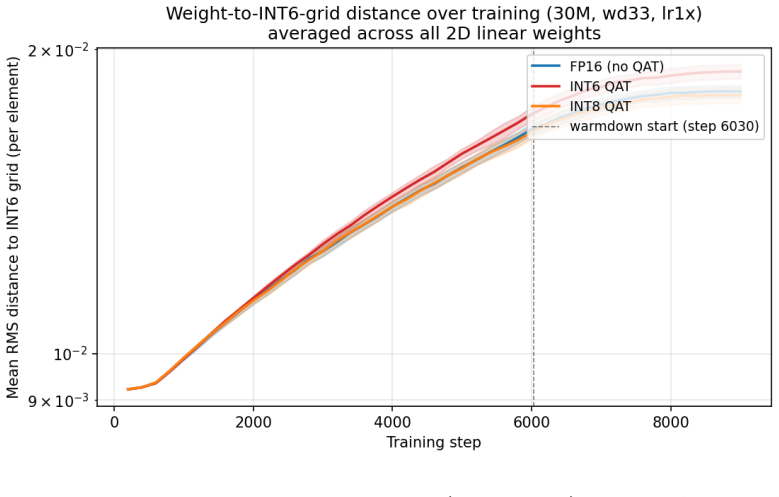
- Weight distance to the quantisation grid before warmdown is essentially identical between FP16 and INT6, ruling out simple snapping as the reason the null holds.
Where Pith is reading between the lines
- If the 50M transition for INT4 generalises, practitioners could use a simple size threshold rather than per-model schedule search when moving to 4-bit training.
- The robustness of the null across optimiser, schedule shape and training length suggests the result may extend to other common training choices not yet tested.
- A direct measurement of per-layer gradient quantisation noise at different sizes could explain why schedule preference appears only above 50M for INT4.
Load-bearing premise
The factorial design over bit-width, warmdown, learning rate, size and seed isolates the schedule-bit-width interaction without unmeasured effects from batch size or data order.
What would settle it
Finding a statistically significant schedule preference different from 33 percent warmdown at INT6 or INT8 in any of the tested sizes would falsify the central null result.
Figures


read the original abstract
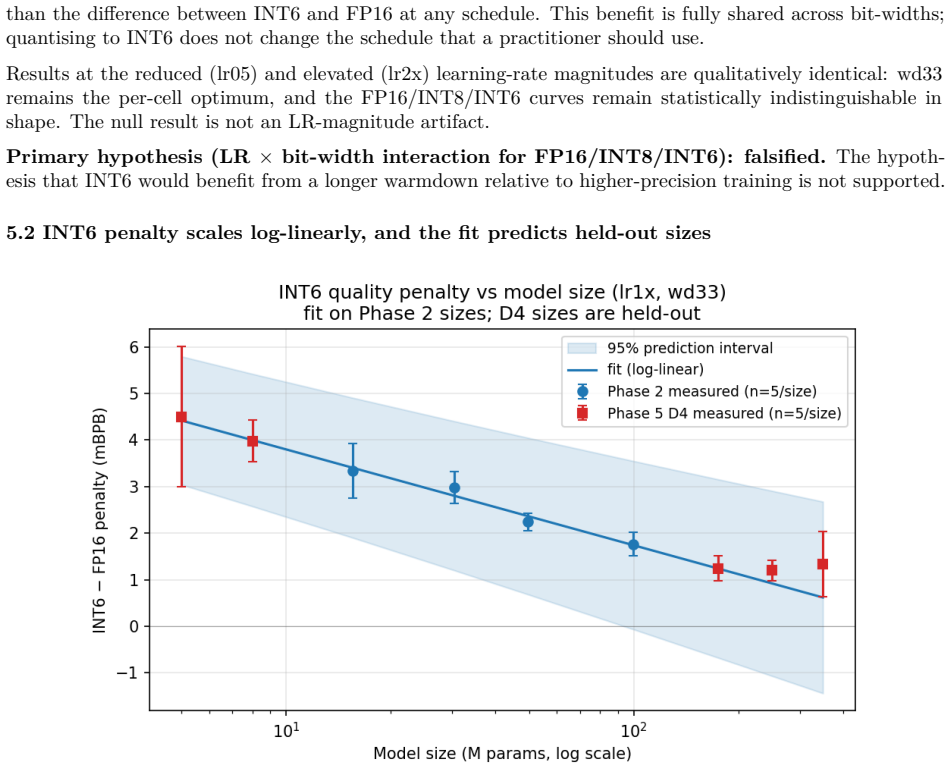
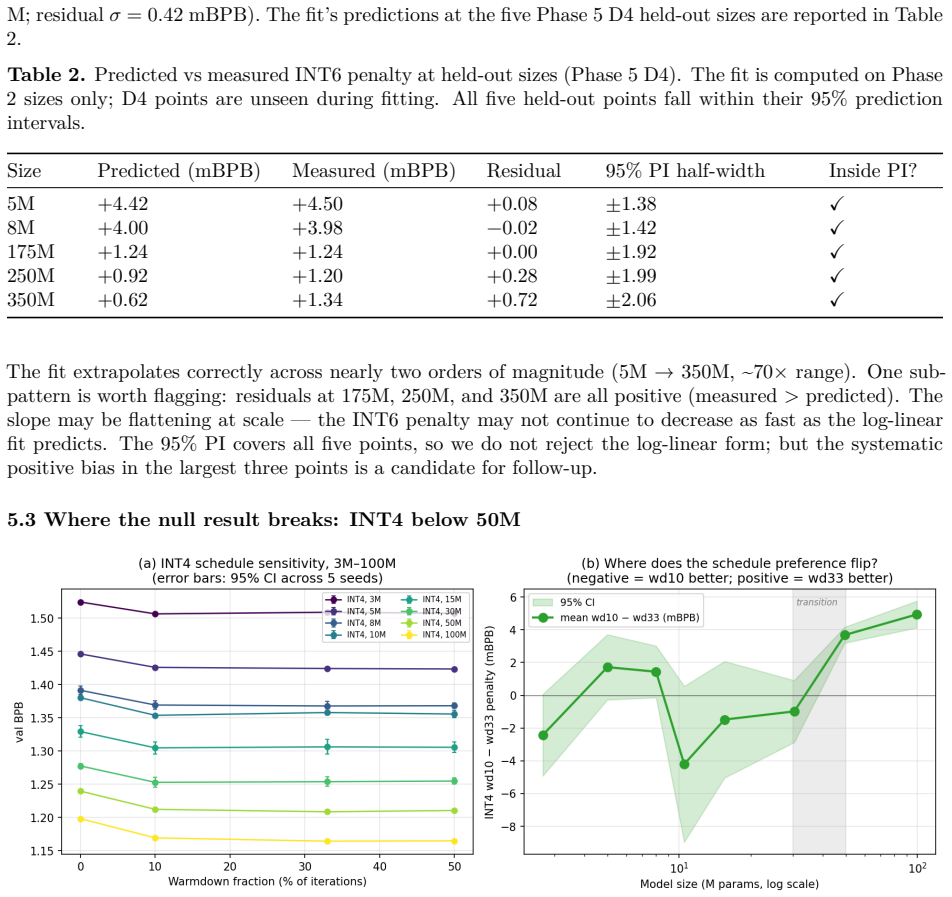
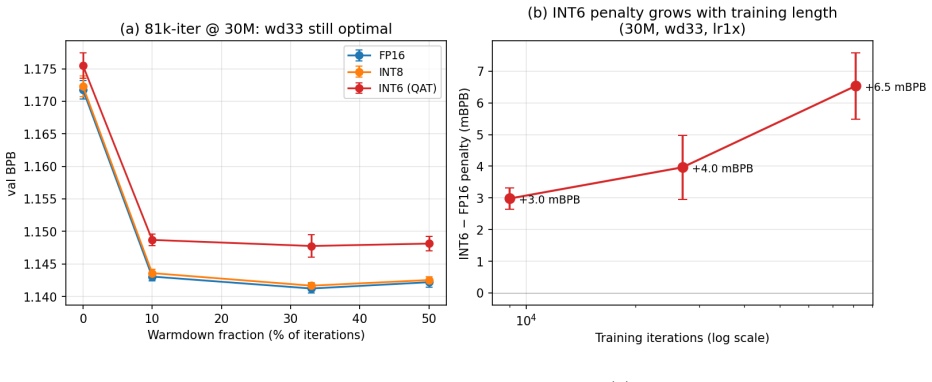
We test whether the optimal learning-rate schedule depends on bit-width during from-initialisation quantisation-aware training (QAT) for sub-100M decoder language models. A 720-run factorial grid (Phase 2) over bit-width x warmdown fraction x LR magnitude x model size x seed (FP16/INT8/INT6, 15M-100M, 5 seeds) finds the optimal warmdown is 33% at every (bit-width, size) cell. The primary hypothesis -- that INT6 QAT requires a different schedule than higher-precision training -- is falsified at FP16/INT8/INT6. A 625-run follow-up (Phase 5) probes the null along five axes: optimiser (AdamW), schedule shape (cosine), training length (up to 9x more iterations), an extended size sweep (5M-350M), and an INT4 sweep from 3M to 100M. The null is robust under all three setup changes. The INT6 penalty follows a log-linear scaling law whose fit on Phase 2 predicts the five held-out Phase 5 sizes (5M, 8M, 175M, 250M, 350M) within their 95% prediction intervals (5/5). For INT4 the picture is sharper than the higher precisions: at 50M and 100M, wd33 is decisively optimal (paired z ~ 12-15, 10/10 seeds); below 50M, across the six tested sizes from 3M to 30M, no individual size shows a statistically significant schedule preference and the per-size mean penalty oscillates within seed-level noise. The boundary is therefore a transition between a noise-dominated regime below 50M and a decisive wd33 regime at and above 50M, not a clean wd10 region. A weight-to-grid-distance probe falsifies the simplest mechanism for the FP16/INT8/INT6 null result (rapid grid-snapping): pre-warmdown, INT6-QAT weights sit at essentially the same distance from the INT6 grid as FP16 weights (ratio ~ 1.04). Practical recommendation: at sub-100M scale, tune the LR schedule once at FP16 and apply unchanged to INT8/INT6 QAT; for INT4 at 50M+ use wd33; for INT4 below 50M the schedule choice is in the noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from a 720-run factorial experiment (Phase 2) and a 625-run follow-up (Phase 5) on the dependence of optimal learning rate warmdown fraction on bit-width in from-initialization QAT for decoder language models from 3M to 350M parameters. It concludes that the optimal warmdown is 33% for FP16, INT8 and INT6 at all tested sizes, falsifying the primary hypothesis of a different schedule for INT6 QAT, while for INT4 the preference for 33% warmdown is decisive only at and above 50M parameters. A log-linear scaling law fitted on Phase 2 data for the INT6 penalty predicts held-out Phase 5 sizes within 95% intervals.
Significance. If the central empirical findings hold, the work offers clear practical recommendations for QAT at sub-100M scales and demonstrates the utility of large-scale factorial designs with held-out validation for mapping hyperparameter interactions. Strengths include the scale of the experiment (over 1300 runs total), successful prediction of held-out sizes, explicit falsification of a proposed mechanism via weight-to-grid-distance probe, and robustness checks across multiple axes in Phase 5. This contributes to understanding quantization effects on training dynamics.
major comments (1)
- [Phase 5 description] Phase 5 description: batch size and data order are held fixed across bit-widths. Since quantization noise can interact with gradient variance in a batch-size-dependent manner, the observed invariance of optimal warmdown fraction to bit-width (FP16/INT8/INT6) may be conditional on these fixed choices rather than isolating the schedule-bit-width interaction in general. The robustness checks on other axes do not address this potential confound.
minor comments (1)
- [Abstract] Abstract: the phrase 'paired z ~ 12-15' should be expanded to specify the exact statistical procedure (e.g., paired z-test statistic) for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: Phase 5 description: batch size and data order are held fixed across bit-widths. Since quantization noise can interact with gradient variance in a batch-size-dependent manner, the observed invariance of optimal warmdown fraction to bit-width (FP16/INT8/INT6) may be conditional on these fixed choices rather than isolating the schedule-bit-width interaction in general. The robustness checks on other axes do not address this potential confound.
Authors: We agree that the results are conditional on the fixed batch size and data order. The Phase 5 design deliberately holds these factors constant to isolate the schedule-bit-width interaction under a single, practical training configuration rather than varying every hyperparameter simultaneously. This choice follows directly from the Phase 2 factorial structure and allows direct comparison across bit-widths. While an interaction between quantization noise and batch-size-dependent gradient variance is plausible in principle, the manuscript does not claim the invariance holds for arbitrary batch sizes; the practical recommendation is scoped to the tested regime. We will add an explicit limitations paragraph noting this design decision and its scope. revision: partial
Circularity Check
No circularity: empirical factorial experiments and held-out validation of scaling law
full rationale
The paper's core claims rest on a 720-run Phase 2 factorial grid over bit-width, warmdown fraction, LR, size and seed, followed by a 625-run Phase 5 probe that varies optimiser, schedule shape, length, size and INT4 while holding batch size and data order fixed. The log-linear scaling law is explicitly fitted on Phase 2 data and then tested for predictive accuracy on five held-out Phase 5 sizes (5/5 within 95% intervals). No derivation reduces a fitted parameter to a prediction by construction, no self-citation chain is load-bearing, and no ansatz or uniqueness theorem is imported. The falsification of the INT6 schedule hypothesis and the noise-dominated vs decisive regime boundary for INT4 are direct statistical outcomes of the experimental design rather than definitional or self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
“GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. ” Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023). https://arxiv.org/abs/2305.13245. Banchelli, Fabio, Marta Garcia-Gasulla, Filippo Mantovani, et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
https://arxiv.org/abs/2503.09917
Introducing MareNostrum5: A Eu- ropean Pre-Exascale Energy-Efficient System Designed to Serve a Broad Spectrum of Scientific Workloads . https://arxiv.org/abs/2503.09917. 16 Bengio, Yoshua, Nicholas Léonard, and Aaron Courville
-
[3]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation . https://arxiv.org/abs/1308.3432. Bondarenko, Yelysei, Riccardo Del Chiaro, and Markus Nagel
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
https://arxiv.org/abs/2406.06385
Low-Rank Quantization-Aware Training for LLMs . https://arxiv.org/abs/2406.06385. Chen, Mengzhao, Wenqi Shao, Peng Xu, et al
-
[5]
arXiv preprint arXiv:2407.11062 , year=
https://arxiv.org/abs/2407.11062. Dremov, Aleksandr, David Grangier, Angelos Katharopoulos, and Awni Hannun
-
[6]
https://arxiv.org/abs/2509.22935
Compute-Optimal Quantization-Aware Training. https://arxiv.org/abs/2509.22935. Electricity Maps
-
[7]
Https://www.electricitymaps.com/grid-in- review-2025/spain
Electricity Grid Review 2025: Spain . Https://www.electricitymaps.com/grid-in- review-2025/spain. Frantar, Elias, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh
2025
-
[8]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
https://arxiv.org/abs/2210.17323. Henderson, Peter, Jieru Hu, Joshua Romoff, Emma Brunskill, Dan Jurafsky, and Joelle Pineau
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning
“Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning. ” Journal of Machine Learning Research 21 (248): 1–43. https://arxiv.org/abs/2002.05651. Hu, Shengding, Yuge Tu, Xu Han, et al
-
[10]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies . https://arxiv.org/abs/2404.06395. Lacoste, Alexandre, Alexandra Luccioni, Victor Schmidt, and Thomas Dandres
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Quantifying the Carbon Emissions of Machine Learning
Quantifying the Carbon Emissions of Machine Learning . https://arxiv.org/abs/1910.09700. Lin, Ji, Jiaming Tang, Haotian Tang, et al
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[12]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
https://arxiv.org/abs/2306.00978. Liu, Jingyuan, Jianlin Su, Xingcheng Yao, et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Muon is Scalable for LLM Training
Muon Is Scalable for LLM Training . https: //arxiv.org/abs/2502.16982. Liu, Zechun, Changsheng Zhao, Forrest Iandola, et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Ma, Shuming, Hongyu Wang, Lingxiao Ma, et al
https://arxiv.org/abs/2402.14905. Ma, Shuming, Hongyu Wang, Lingxiao Ma, et al
-
[15]
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
The Era of 1-Bit LLMs: All Large Language Models Are in 1.58 Bits . https://arxiv.org/abs/2402.17764. Morreale, Luca, Alberto Gil C. P. Ramos, Malcolm Chadwick, et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
https://arxiv.org/abs/2510.14823
FraQAT: Quantization Aware Training with Fractional Bits . https://arxiv.org/abs/2510.14823. Nagel, Markus, Marios Fournarakis, Yelysei Bondarenko, and Tijmen Blankevoort
-
[17]
Nielsen, Jacob, and Peter Schneider-Kamp
https://arxiv.org/abs/2203.11086. Nielsen, Jacob, and Peter Schneider-Kamp
-
[18]
https://arxiv.org/abs/2407.09527
BitNet b1.58 Reloaded: State-of-the-Art Performance Also on Smaller Networks . https://arxiv.org/abs/2407.09527. 17 Nielsen, Jacob, Peter Schneider-Kamp, and Lukas Galke
-
[19]
Patterson, David, Joseph Gonzalez, Quoc Le, et al
Continual Quantization-Aware Pre-Training: When to Transition from 16-Bit to 1.58-Bit Pre-Training for BitNet Language Models? https://arxiv.or g/abs/2502.11895. Patterson, David, Joseph Gonzalez, Quoc Le, et al
-
[20]
Carbon Emissions and Large Neural Network Training
Carbon Emissions and Large Neural Network Training. https://arxiv.org/abs/2104.10350. Penedo, Guilherme, Hynek Kydlíček, Loubna Ben Allal, et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Datasets and Benchmarks Track . https://arxiv.org/abs/2406.17557. Ronneberger, Olaf, Philipp Fischer, and Thomas Brox
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
U-Net: Convolutional Networks for Biomedical Image Segmentation
“U-Net: Convolutional Networks for Biomed- ical Image Segmentation. ” Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015). https://arxiv.org/abs/1505.04597. So, David R., Wojciech Mańke, Hanxiao Liu, Zihang Dai, Noam Shazeer, and Quoc V. Le
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
https://arxiv.org/abs/2109.08668
Primer: Searching for Efficient Transformers for Language Modeling . https://arxiv.org/abs/2109.08668. Strubell, Emma, Ananya Ganesh, and Andrew McCallum
-
[24]
Energy and Policy Considerations for Deep Learning in NLP ,
https://arxiv.org/abs/1906.02243. Su, Jianlin, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[25]
RoFormer: Enhanced Transformer with Rotary Position Embedding
RoFormer: En- hanced Transformer with Rotary Position Embedding . https://arxiv.org/abs/2104.09864. Wang, Hongyu, Shuming Ma, Li Dong, et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
BitNet: Scaling 1-bit Transformers for Large Language Models
BitNet: Scaling 1-Bit Transformers for Large Language Models. https://arxiv.org/abs/2310.11453. Zhang, Biao, and Rico Sennrich
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Root Mean Square Layer Normalization
https://arxiv.org/abs/1910.07467. Zhang, Hao, Aining Jia, Weifeng Bu, et al
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[28]
https://arxiv.org/abs/2508.04405
FlexQ: Efficient Post-Training INT6 Quantization for LLM Serving via Algorithm-System Co-Design . https://arxiv.org/abs/2508.04405. 18 Appendix A — Computational Footprint We report the energy, carbon, and indirect-water footprint of the experiments in this paper following the systematic-reporting framework of Henderson et al. (2020) and the methodology of...
-
[29]
— reflects an explicit efficiency posture, but we could not locate a primary disclosure of BSC’s electricity procurement contracts during the preparation of this paper. Under a hypothetical market-based Scope 2 accounting that credits a 100% renewable supply contract at the lifecycle intensity of utility-scale solar/wind (~10–50 gCO 2eq/kWh), the figure wo...
2021
-
[30]
Grid carbon intensity (gCO2eq/kWh) 132 Spain 2025 flow-traced (Electricity Maps
2025
-
[31]
Each value is intended to be replaceable: readers preferring different conventions (e.g., setting 𝑃GPU to TDP for an upper-bound estimate) can recompute the totals trivially
Renewable-PPA scenario (gCO2eq/kWh) 10–50 Lifecycle intensity of utility-scale solar/wind Indirect water (L/kWh) 1.8 Generic European-grid estimate; no Spain-specific primary cited Table A.1 — Assumptions used in the footprint estimates. Each value is intended to be replaceable: readers preferring different conventions (e.g., setting 𝑃GPU to TDP for an up...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.