LongAV-Compass: Towards Unified Evaluation of Minute-Scale Audio-Visual Generation Across T2AV, I2AV, and V2AV
Pith reviewed 2026-06-29 22:50 UTC · model grok-4.3
The pith
LongAV-Compass supplies 284 test cases and a multi-metric framework to diagnose coherence and alignment failures in minute-scale audio-visual generation across text, image, and video conditioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
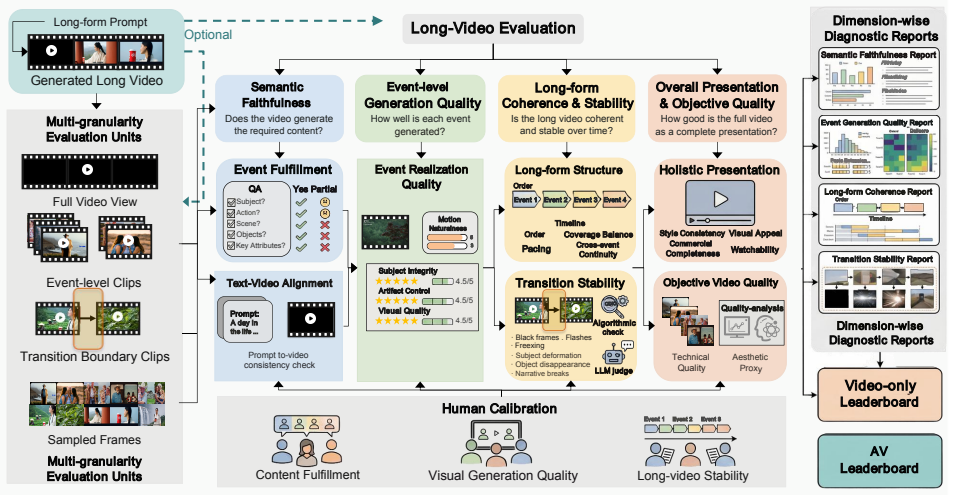
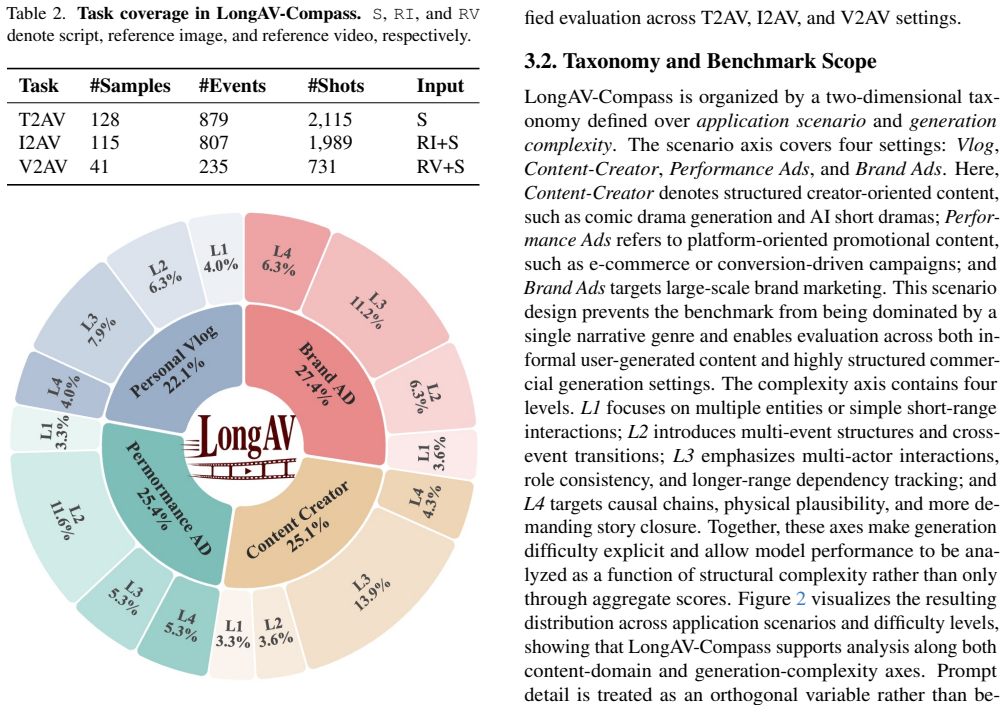
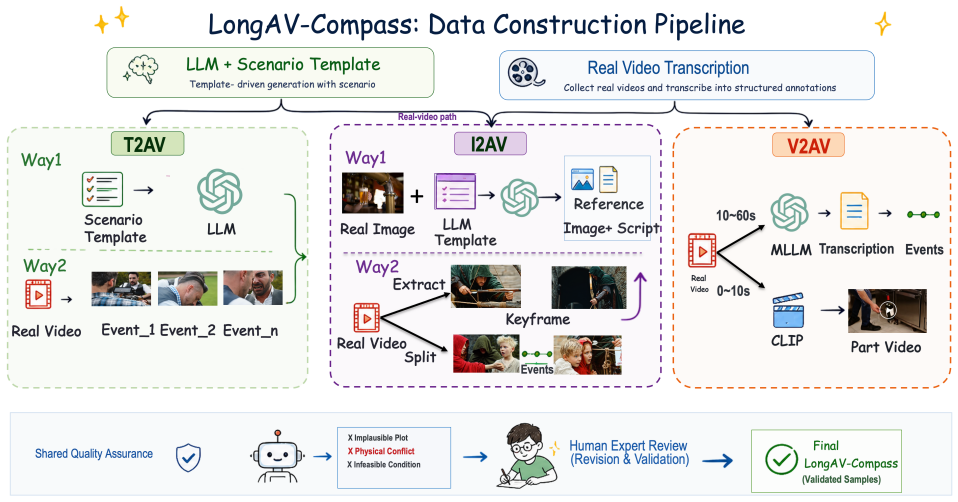
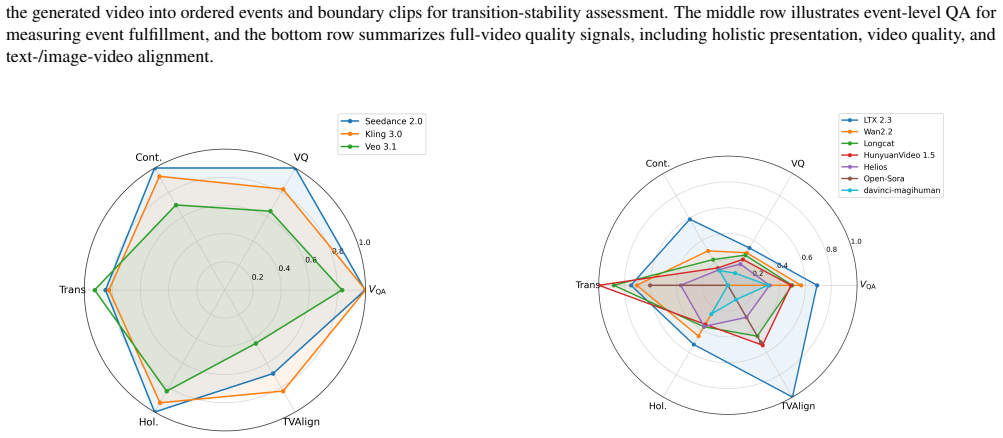
LongAV-Compass is a benchmark of 284 curated test cases spanning text-to-audio-video, image-to-audio-video, and video-to-audio-video generation, built through taxonomy-guided construction and evaluated via an integrated framework of MLLM-assisted assessment together with complementary metrics such as DINO-v2, ArcFace, CLIP, and ImageBind; the framework measures fine-grained dimensions of within-segment quality, cross-segment consistency, global narrative coherence, semantic alignment, and audio-visual synchronization, and experiments on eleven models with human validation demonstrate its utility in revealing limitations of current systems for sustaining coherent minute-scale outputs.
What carries the argument
LongAV-Compass benchmark, whose taxonomy-guided test construction and unified evaluation framework integrate MLLM-assisted assessment with perceptual and multimodal metrics (DINO-v2, ArcFace, CLIP, ImageBind) to score over twenty dimensions of quality, consistency, and alignment.
If this is right
- Current models show measurable drops in identity consistency and narrative coherence as generation length reaches one minute.
- A single framework can now compare performance across three conditioning modalities on the same set of long-form criteria.
- The multi-metric approach isolates specific failure modes such as cross-segment drift and synchronization loss.
- Human validation confirms that the automated scores track human judgments on the targeted dimensions of quality and alignment.
Where Pith is reading between the lines
- Model developers could target the identified failure modes by retraining on subsets of the benchmark that isolate particular consistency dimensions.
- The benchmark construction method could be extended to longer sequences or new modalities to test whether the observed degradation patterns continue or saturate.
- Integration into training loops might allow direct optimization against the fine-grained scores rather than short-clip proxies.
- The diagnostic results could guide selection of conditioning modality for specific application scenarios that require sustained narrative.
- keywords:[
Load-bearing premise
The 284 curated test cases together with the chosen MLLM-assisted metrics and perceptual measures accurately capture degradation in identity consistency, narrative coherence, and audio-visual alignment over minute-scale durations.
What would settle it
Running the eleven models on the 284 cases and finding that high automated scores on all metrics correspond to low human ratings for overall coherence and alignment would falsify the benchmark's measurement validity.
Figures










read the original abstract
Audio-visual generation is rapidly advancing from short clips to minute-long content, while existing evaluation protocols remain largely confined to short-form settings. Existing benchmarks primarily focus on 5--10 second text-conditioned generation and rarely support unified evaluation across text, image, and video conditioning modalities. Moreover, they provide limited insight into how identity consistency, narrative coherence, and audio-visual alignment degrade over extended temporal horizons. To bridge this gap, we introduce LongAV-Compass, a systematic benchmark for minute-long audio-visual generation. LongAV-Compass contains 284 curated test cases spanning text-to-audio-video (T2AV), image-to-audio-video (I2AV), and video-to-audio-video (V2AV), organized by application scenario and generation complexity. The benchmark combines taxonomy-guided benchmark construction with a unified evaluation framework that integrates MLLM-assisted assessment with complementary perceptual and multimodal metrics, including DINO-v2, ArcFace, CLIP, and ImageBind. The framework evaluates more than 20 fine-grained dimensions covering within-segment quality, cross-segment consistency, global narrative coherence, semantic alignment, and audio-visual synchronization. Through experiments on 11 representative models together with human-alignment validation, LongAV-Compass provides a diagnostic testbed for analyzing the limitations of current systems in sustaining coherent, semantically aligned, and temporally consistent minute-scale audio-visual generation across diverse input modalities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LongAV-Compass, a benchmark for minute-scale audio-visual generation containing 284 curated test cases spanning T2AV, I2AV, and V2AV modalities. Cases are organized by application scenario and generation complexity using a taxonomy-guided approach. The unified evaluation framework integrates MLLM-assisted assessment with perceptual and multimodal metrics (DINO-v2, ArcFace, CLIP, ImageBind) to score more than 20 fine-grained dimensions covering within-segment quality, cross-segment consistency, global narrative coherence, semantic alignment, and audio-visual synchronization. Experiments on 11 representative models are paired with human-alignment validation to position the benchmark as a diagnostic testbed for limitations in sustaining coherent, semantically aligned, and temporally consistent minute-scale generation across input modalities.
Significance. If the curation, metrics, and human validation hold, the work addresses a genuine gap in existing short-clip benchmarks by enabling analysis of temporal degradation in identity consistency, narrative coherence, and audio-visual alignment. The multi-modality coverage and fine-grained dimensions could serve as a practical reference for diagnosing model weaknesses in long-form generation, with the human-alignment step providing a useful check on automated metrics.
major comments (2)
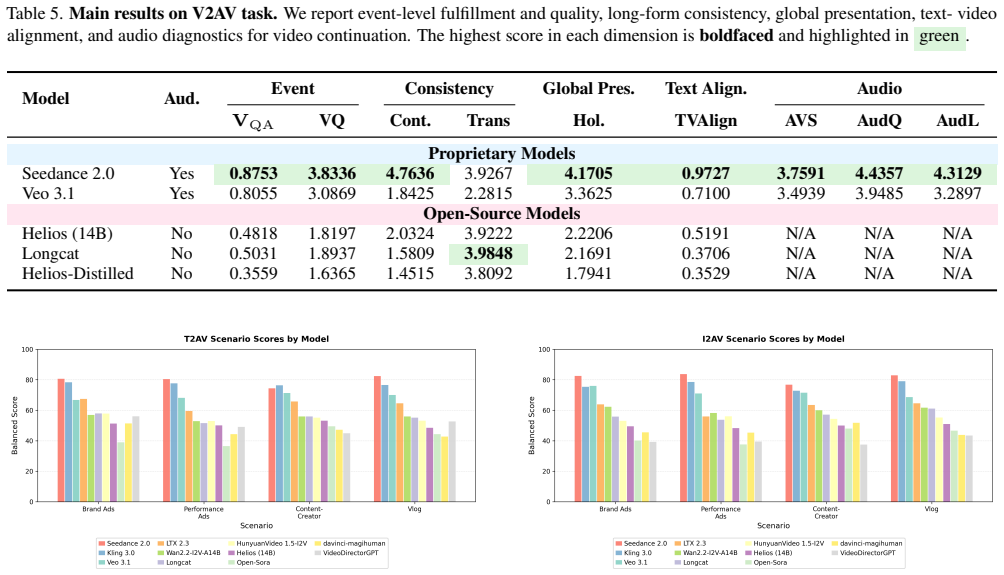
- [Abstract / Experiments] Abstract and Experiments section: The central claim that LongAV-Compass supplies a usable diagnostic testbed rests on experiments with 11 models and human validation, yet the manuscript provides no quantitative results, per-model scores, degradation trends, or error analysis. Without these, the diagnostic utility remains asserted rather than demonstrated.
- [Benchmark Construction] Benchmark Construction section: The 284 test cases are described as taxonomy-guided and spanning 20+ dimensions, but the manuscript supplies no explicit selection criteria, inter-annotator agreement statistics, or ablation showing that the chosen cases reliably surface degradation in identity consistency and narrative coherence over minute-scale horizons.
minor comments (2)
- [Benchmark Construction] A table or figure summarizing the distribution of the 284 cases across modalities (T2AV/I2AV/V2AV) and complexity levels would improve readability of the benchmark composition.
- [Evaluation Framework] The description of how MLLM-assisted scores are aggregated with DINO-v2/ArcFace/CLIP/ImageBind metrics would benefit from an explicit formula or pseudocode in the Evaluation Framework section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the empirical demonstration and construction transparency.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The central claim that LongAV-Compass supplies a usable diagnostic testbed rests on experiments with 11 models and human validation, yet the manuscript provides no quantitative results, per-model scores, degradation trends, or error analysis. Without these, the diagnostic utility remains asserted rather than demonstrated.
Authors: We agree that the current manuscript version does not present the quantitative results, per-model scores, degradation trends, or error analysis. In the revised version we will add these elements from the experiments on the 11 models together with the human-alignment validation results, thereby demonstrating rather than asserting the benchmark's diagnostic value. revision: yes
-
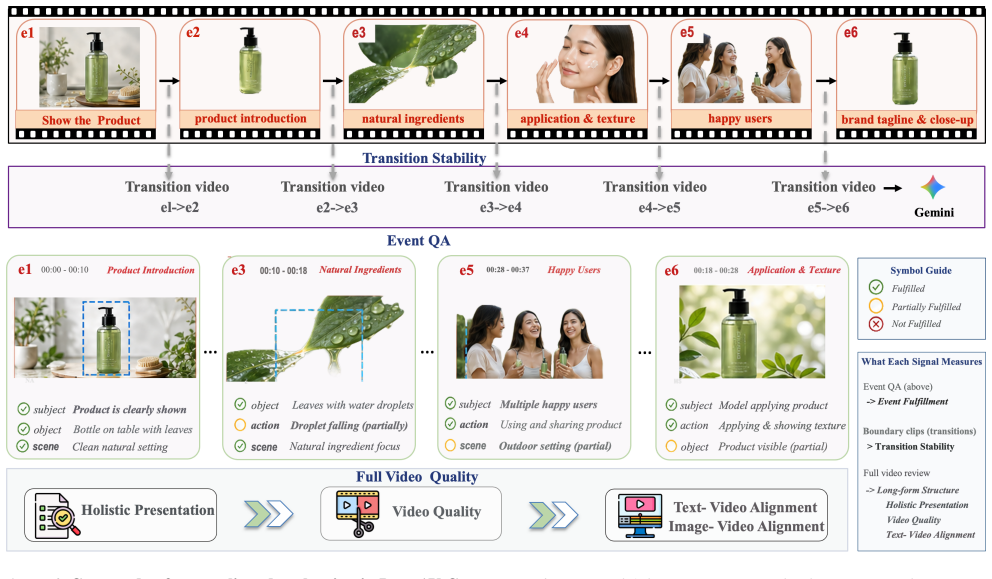
Referee: [Benchmark Construction] Benchmark Construction section: The 284 test cases are described as taxonomy-guided and spanning 20+ dimensions, but the manuscript supplies no explicit selection criteria, inter-annotator agreement statistics, or ablation showing that the chosen cases reliably surface degradation in identity consistency and narrative coherence over minute-scale horizons.
Authors: We acknowledge the absence of these details. The revised Benchmark Construction section will include explicit selection criteria, inter-annotator agreement statistics, and an ablation study confirming that the 284 cases surface the targeted degradations in identity consistency and narrative coherence. revision: yes
Circularity Check
No significant circularity in benchmark construction
full rationale
The paper presents LongAV-Compass as a benchmark with 284 test cases, taxonomy-guided construction, MLLM-assisted assessment, and external metrics (DINO-v2, ArcFace, CLIP, ImageBind) evaluated on 11 models plus human validation. No derivations, equations, fitted parameters, predictions, or self-citation chains appear in the provided text. The central claim reduces to standard benchmark practice using independent external components, with no load-bearing step that reduces to its own inputs by construction. This matches the default expectation for non-circular benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLLM-assisted assessment combined with metrics such as DINO-v2, ArcFace, CLIP, and ImageBind reliably measures fine-grained dimensions including cross-segment consistency and audio-visual synchronization
Reference graph
Works this paper leans on
-
[1]
Storybench: A multifaceted benchmark for continuous story visualization.Advances in Neural Information Processing Systems (NeurIPS), 36:78095– 78125, 2023
Emanuele Bugliarello, H Hernan Moraldo, Ruben Villegas, Mohammad Babaeizadeh, Mohammad Taghi Saffar, Han Zhang, Dumitru Erhan, Vittorio Ferrari, Pieter-Jan Kinder- mans, and Paul V oigtlaender. Storybench: A multifaceted benchmark for continuous story visualization.Advances in Neural Information Processing Systems (NeurIPS), 36:78095– 78125, 2023
2023
-
[2]
T2AV-Compass: Towards Unified Evaluation for Text-to-Audio-Video Generation
Zhe Cao, Tao Wang, Jiaming Wang, Yanghai Wang, Yuanx- ing Zhang, Jialu Chen, Miao Deng, Jiahao Wang, Yubin Guo, Chenxi Liao, et al. T2av-compass: Towards unified eval- uation for text-to-audio-video generation.arXiv preprint arXiv:2512.21094, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Ethan Chern, Hansi Teng, Hanwen Sun, Hao Wang, Hong Pan, Hongyu Jia, Jiadi Su, Jin Li, Junjie Yu, Lijie Liu, et al. Speed by simplicity: A single-stream architecture for fast audio-video generative foundation model.arXiv preprint arXiv:2603.21986, 2026
-
[4]
Gemini 3.1 pro
Google DeepMind. Gemini 3.1 pro. https://deepmind. google / models / gemini / pro/, 2026. Accessed: 2026-05-26
2026
-
[5]
Weixi Feng, Jiachen Li, Michael Saxon, Tsu-jui Fu, Wenhu Chen, and William Yang Wang. Tc-bench: Benchmark- ing temporal compositionality in text-to-video and image- to-video generation.arXiv preprint arXiv:2406.08656, 2024
-
[6]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
VABench: A Comprehensive Benchmark for Audio-Video Generation
Daili Hua, Xizhi Wang, Bohan Zeng, Xinyi Huang, Hao Liang, Junbo Niu, Xinlong Chen, Quanqing Xu, and Wentao Zhang. Vabench: A comprehensive benchmark for audio- video generation.arXiv preprint arXiv:2512.09299, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21807–21818, 2024
2024
-
[9]
Vbench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transac- tions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, et al. Vbench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transac- tions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
2025
-
[10]
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dan Kondratyuk, Lijun Yu, Xiuye Gu, Jose Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vighnesh Birodkar, Jimmy Yan, Ming-Chang Chiu, et al. Videopoet: A large language model for zero-shot video generation.arXiv preprint arXiv:2312.14125, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Vintage: Joint video and text conditioning for holistic audio generation
Saksham Singh Kushwaha and Yapeng Tian. Vintage: Joint video and text conditioning for holistic audio generation. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 13529–13539, 2025
2025
-
[12]
Han Lin, Abhay Zala, Jaemin Cho, and Mohit Bansal. Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning.arXiv preprint arXiv:2309.15091, 2023
-
[13]
Yuanxin Liu, Lei Li, Shuhuai Ren, Rundong Gao, Shicheng Li, Sishuo Chen, Xu Sun, and Lu Hou. Fetv: A benchmark for fine-grained evaluation of open-domain text-to-video gen- eration.arXiv preprint arXiv:2311.01813, 2023
-
[14]
Evalcrafter: Benchmarking and eval- uating large video generation models
Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, and Ying Shan. Evalcrafter: Benchmarking and eval- uating large video generation models. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 22139–22149, 2024
2024
-
[15]
Simian Luo, Chuanhao Yan, Chenxu Hu, and Hang Zhao. Diff-foley: Synchronized video-to-audio synthesis with latent diffusion models.arXiv preprint arXiv:2306.17203, 2023
-
[16]
Movie Gen: A Cast of Media Foundation Models
Meta Movie Gen Team. Movie gen: A cast of media founda- tion models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[19]
Yong Ren, Chenxing Li, Manjie Xu, Wei Liang, Yu Gu, Rilin Chen, and Dong Yu. Sta-v2a: Video-to-audio gen- eration with semantic and temporal alignment.arXiv preprint arXiv:2409.08601, 2024
-
[20]
Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation
Ludan Ruan, Yiyang Ma, Huan Yang, Huiguo He, Bei Liu, Jianlong Fu, Nicholas Jing Yuan, Qin Jin, and Bain- ing Guo. Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10219–10228, 2023
2023
-
[21]
Seedance 2.0: Advancing Video Generation for World Complexity
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, et al. Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2604.14148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Haoyuan Shi, Yunxin Li, Nanhao Deng, Zhenran Xu, Xinyu Chen, Longyue Wang, Baotian Hu, and Min Zhang. Msvbench: Towards human-level evaluation of multi-shot video generation.arXiv preprint arXiv:2602.23969, 2026
-
[23]
Ve-bench: subjective-aligned benchmark suite for text-driven video editing quality assessment
Shangkun Sun, Xiaoyu Liang, Songlin Fan, Wenxu Gao, and Wei Gao. Ve-bench: subjective-aligned benchmark suite for text-driven video editing quality assessment. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 7105–7113, 2025
2025
-
[24]
Kling Team, Jialu Chen, Yuanzheng Ci, Xiangyu Du, Zipeng Feng, Kun Gai, Sainan Guo, Feng Han, Jingbin He, Kang He, et al. Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Longcat-video technical report.arXiv preprint arXiv:2510.22200, 2025
Meituan LongCat Team, Xunliang Cai, Qilong Huang, Zhuo- liang Kang, Hongyu Li, Shijun Liang, Liya Ma, Siyu Ren, Xiaoming Wei, Rixu Xie, et al. Longcat-video technical report.arXiv preprint arXiv:2510.22200, 2025
-
[26]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
HunyuanVideo 1.5 Technical Report
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Tianxin Xie, Wentao Lei, Kai Jiang, Guanjie Huang, Pengfei Zhang, Chunhui Zhang, Fengji Ma, Haoyu He, Han Zhang, Jiangshan He, et al. Phyavbench: A challenging audio physics-sensitivity benchmark for physically grounded text- to-audio-video generation.arXiv preprint arXiv:2512.23994, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Helios: Real real-time long video generation model.arXiv preprint arXiv:2603.04379, 2026
Shenghai Yuan, Yuanyang Yin, Zongjian Li, Xinwei Huang, Xiao Yang, and Li Yuan. Helios: Real real-time long video generation model.arXiv preprint arXiv:2603.04379, 2026
-
[30]
Yiming Zhang, Yicheng Gu, Yanhong Zeng, Zhening Xing, Yuancheng Wang, Zhizheng Wu, and Kai Chen. Foleycrafter: Bring silent videos to life with lifelike and synchronized sounds.arXiv preprint arXiv:2407.01494, 2024
-
[31]
Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Zangwei Zheng, Xiangyu Peng, Yuxuan Lou, Chenhui Shen, Tom Young, Xinying Guo, Binluo Wang, Hang Xu, Hongxin Liu, Mingyan Jiang, et al. Open-sora 2.0: Training a commercial-level video generation model in 200k.arXiv preprint arXiv:2503.09642, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
AVGen-Bench: A Task-Driven Benchmark for Multi-Granular Evaluation of Text-to-Audio-Video Generation
Ziwei Zhou, Zeyuan Lai, Rui Wang, Yifan Yang, Zhen Xing, Yuqing Yang, Qi Dai, Lili Qiu, and Chong Luo. Avgen-bench: A task-driven benchmark for multi-granular evaluation of text- to-audio-video generation.arXiv preprint arXiv:2604.08540, 2026. A. Data Construction Details A.1. Prompt Design Templates Our benchmark constructs structured long-form scripts t...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
subject: Is the main subject/product present?
-
[34]
action/interaction: Does the core action occur?
-
[35]
Prompt template for T2A V LLM-template generation
attribute/scene/text brand: Are key visual details correct? Figure 12. Prompt template for T2A V LLM-template generation. reveals that L2–L3 dominate across all tasks, with V2A V containing no L1 samples due to the inherent complexity of video continuation. Panels (d) and (e) show that T2A V and I2A V have similar event counts (avg 6.9–7.0, range 2–
-
[36]
image summary
and shot counts (avg 16.5–17.3), while V2A V is more I2A V Image Prior Extraction Prompt Analyze this image and produce a structured prior in JSON: { "image summary": "<one-sentence summary>", "detailed visual description": "<full visual analysis>", "subjects": [...], "key objects": [...], "environment and setting": "<scene description>", "composition and...
-
[37]
(subject) Are two women and a skincare product visi- ble?
-
[38]
(interaction) Does one woman hand the product to the other?
-
[39]
water-burst
(scene) Is the setting a bright indoor window area? Generation Challenges.This case tests: (1) two-person interaction with distinct roles, (2) product close-up with texture demonstration (“water-burst” effect), (3) facial ex- pression transitions, and (4) brand packaging consistency across shots. C.2. V2A V Case: Content-Creator Short Film Con- tinuation ...
-
[40]
(0–9s) Camera establishes the desk scene; watch receives a notification
-
[41]
(9–20s) A hand enters frame, picks up the watch, puts it on wrist
-
[42]
(20–35s) Close-up: watch face shows fitness rings filling; demonstrates health tracking
-
[43]
(35–48s) Quick-cut montage of different watch faces and complications
-
[44]
After the reference video, the scene continues with: {event2.visual description}; {event3.visual description}
(48–60s) Return to desk scene; brand logo and CTA ap- pear. Generation Challenges.This case tests: (1) precise preser- vation of the reference image’s visual style and objects, (2) natural transition from still product shot to dynamic video, (3) fine-grained UI animation on the watch screen, and (4) return to the original composition for the ending. C.4. ...
-
[45]
Videos are saved as full video.mp4 under each model’s output directory
-
[46]
Event-aligned clips are extracted based on canonical event boundaries fromcanonical events.json
-
[47]
Boundary clips (2 s before and after each event boundary) are extracted for transition evaluation
-
[48]
For audio evaluation, audio-bearing event clips are re- extracted from full video.mp4 to ensure audio con- tinuity
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.