Credit-assigned Policy Gradient for Early Stage Retrieval in Two-stage Ranking
Pith reviewed 2026-06-29 20:02 UTC · model grok-4.3
The pith
Credit-assigned policy gradients reduce variance in training early-stage rankers by marginalizing over candidate sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
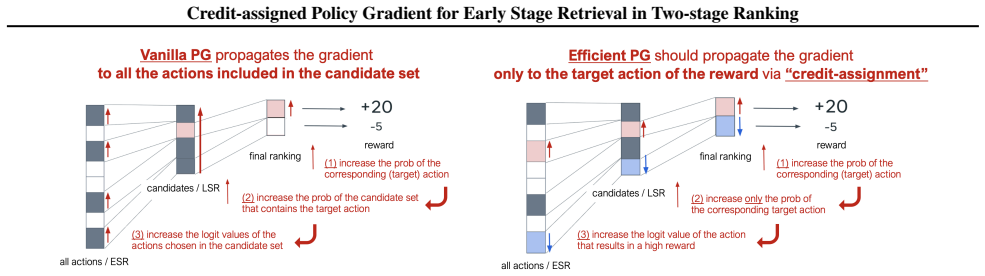
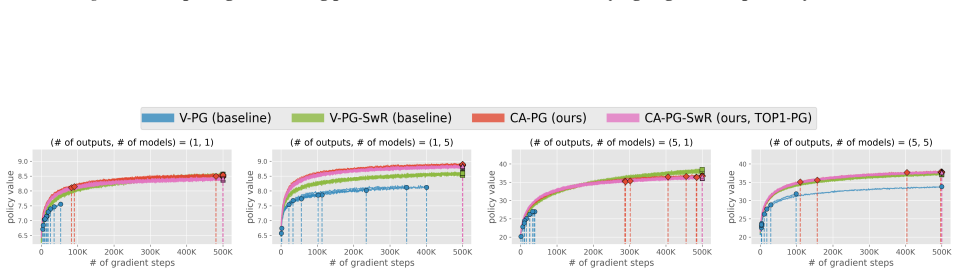
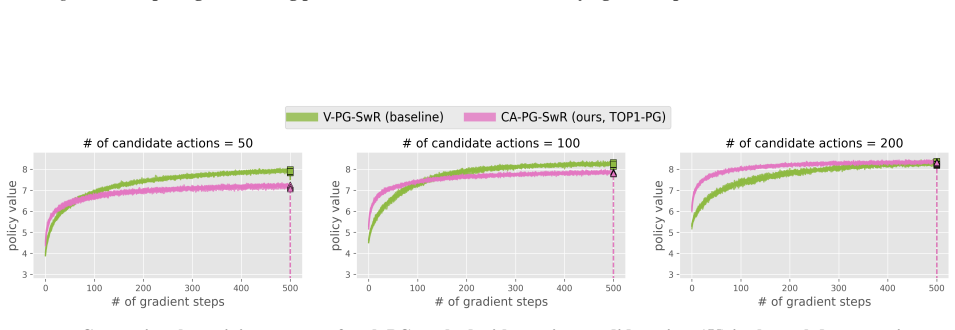
The credit-assigned policy gradient computes gradients with respect to the probability that the target item is chosen in any candidate set, i.e., marginalizing over all candidate sets that contain it. This marginalization significantly reduces the variance of the vanilla policy gradient while still allowing the early-stage model to learn the correct ranking of items under a reasonably aligned late-stage ranker policy.
What carries the argument
The credit-assigned policy gradient (CA-PG), which replaces the joint probability of a full candidate set with the marginal inclusion probability of each individual item.
If this is right
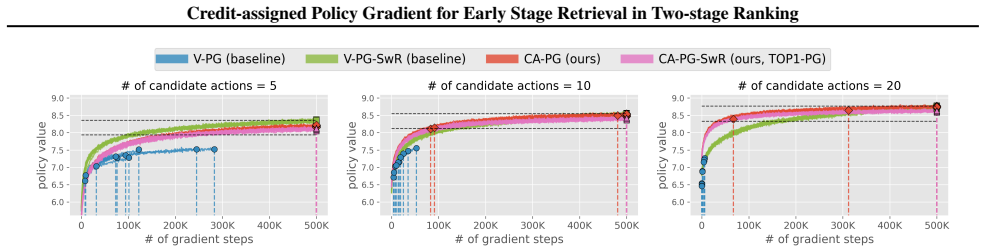
- CA-PG enables end-to-end training of early-stage rankers at candidate-set sizes where vanilla policy gradient variance becomes prohibitive.
- Convergence speed and training stability improve for Plackett-Luce early-stage models as candidate-set size increases.
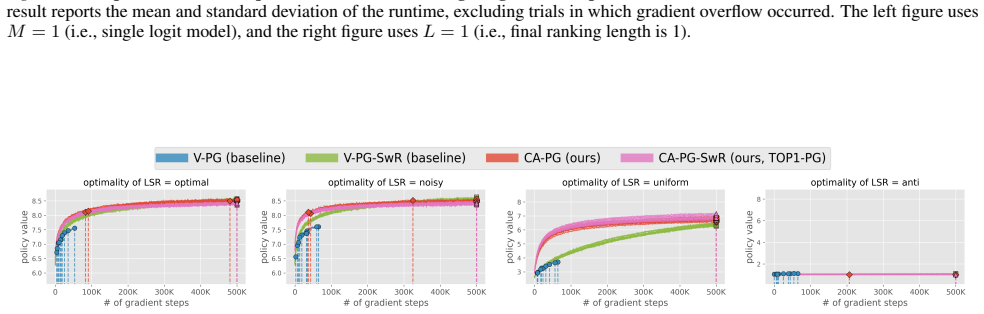
- The method still recovers correct item orderings when the late-stage ranker remains aligned with the objective.
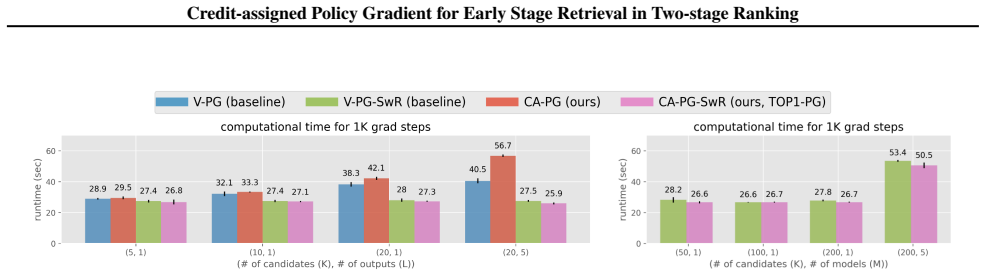
- Practical gains appear in both synthetic environments and real-world retrieval tasks.
Where Pith is reading between the lines
- The same marginalization approach could apply to retrieval-augmented generation pipelines where the first stage selects context passages.
- Analogous credit-assignment techniques may help other combinatorial action spaces that suffer from high-variance policy gradients.
- If the late-stage ranker is updated concurrently, periodic re-alignment checks may be needed to keep credit assignment accurate.
Load-bearing premise
The late-stage ranker policy must be reasonably aligned with the target ranking objective so marginal gradients correctly assign credit to items.
What would settle it
Direct measurement of gradient variance on synthetic data across candidate-set sizes from 10 to several hundred, comparing CA-PG to vanilla policy gradient, would confirm or refute the claimed variance reduction.
Figures

read the original abstract
Large-scale search, recommendation, and retrieval-augmented generation (RAG) systems typically employ a two-stage architecture: an early-stage ranker (ESR) generates a candidate set, which is subsequently re-ranked by a late-stage ranker (LSR). While there are many reinforcement learning (RL) methods for training the LSR, end-to-end training of the ESR has proven challenging. In particular, naive application of "vanilla" policy gradient (V-PG) is not scalable for candidate-set sizes relevant for practical use due to exploding variance. This issue arises because V-PG propagates the gradient to the joint probability of the candidate sets, ignoring the contribution of each specific item in the candidate set to the reward. To mitigate this issue, we propose a novel "credit-assigned" policy gradient (CA-PG), which computes gradients with respect to the probability that the target item is chosen in any candidate set, i.e. marginalizing over all candidate sets that contain it. Our theoretical analysis reveals that CA-PG significantly reduces the variance of V-PG by marginalizing over the specific composition of the candidate set, while preserving the ability to learn the correct ranking of items under a reasonably aligned LSR policy. Experiments on both synthetic and real-world data demonstrate that CA-PG improves the convergence speed and training stability for ESRs utilizing the canonical Plackett-Luce model, especially when the candidate-set size is large.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Credit-assigned Policy Gradient (CA-PG) for end-to-end training of early-stage rankers (ESRs) in two-stage retrieval systems. It claims that vanilla policy gradient (V-PG) suffers from exploding variance because it operates on joint candidate-set probabilities; CA-PG instead computes gradients with respect to the marginal probability that a target item appears in any candidate set. Theoretical analysis asserts that this marginalization reduces variance while still permitting correct item ranking under a 'reasonably aligned' late-stage ranker (LSR) policy. Experiments on synthetic and real-world data report improved convergence speed and training stability for the Plackett-Luce ESR, especially at large candidate-set sizes.
Significance. If the claims hold, the work supplies a concrete mechanism for scaling policy-gradient training to the ESR stage, a long-standing obstacle in large-scale search, recommendation, and RAG pipelines. The variance-reduction argument via explicit marginalization over candidate-set composition is a direct statistical device that could be reusable. The paper receives credit for stating both a theoretical variance comparison and empirical results on real data rather than synthetic-only validation.
major comments (1)
- [Theoretical analysis] Theoretical analysis section: the central claim that CA-PG 'preserves the ability to learn the correct ranking of items' rests on the LSR policy being 'reasonably aligned' with the target objective. No quantitative condition (e.g., bound on KL divergence, ranking correlation, or reward correlation) is supplied that would guarantee the marginal gradients remain credit-correct when alignment is imperfect. This assumption is load-bearing for the correctness guarantee.
minor comments (1)
- [Abstract and §3] The abstract and §3 refer to the 'canonical Plackett-Luce model' without an explicit equation reference; the parameterization used for the ESR policy should be stated with equation number.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the constructive comment on the theoretical analysis. We address the major comment below.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis section: the central claim that CA-PG 'preserves the ability to learn the correct ranking of items' rests on the LSR policy being 'reasonably aligned' with the target objective. No quantitative condition (e.g., bound on KL divergence, ranking correlation, or reward correlation) is supplied that would guarantee the marginal gradients remain credit-correct when alignment is imperfect. This assumption is load-bearing for the correctness guarantee.
Authors: We agree that the 'reasonably aligned' assumption is qualitative and load-bearing for the correctness guarantee. The marginalization in CA-PG reduces variance independently of alignment, but the direction of the gradient for item inclusion depends on the LSR providing a reward signal whose expectation is monotonically related to true item utility. In the revised manuscript we will introduce an explicit quantitative condition: the LSR must induce a ranking whose Kendall-tau correlation with ground-truth relevance exceeds 0.5. Under this condition we will prove that the expected CA-PG update increases the marginal inclusion probability of higher-utility items. A tighter bound expressed via KL divergence between LSR and target policies would require further assumptions on the reward model and is noted as future work. revision: yes
Circularity Check
No circularity: marginalization is a direct statistical identity independent of fitted inputs or self-citations
full rationale
The derivation defines CA-PG explicitly as the gradient w.r.t. the marginal probability of an item appearing in any candidate set. This is a straightforward summation over the joint policy probabilities, yielding variance reduction as a mathematical consequence rather than a fitted or self-defined quantity. The claim of preserving correct ranking under a 'reasonably aligned' LSR is an external assumption stated separately from the gradient derivation itself; it does not reduce the result to the paper's own inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked in the abstract or described derivation chain. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The late-stage ranker provides a reasonably aligned policy that allows marginal probabilities to assign correct credit.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Burges, C. J. From ranknet to lambdarank to lambdamart: An overview. Learning, 11 0 (23-581): 0 81, 2010
2010
-
[3]
and Goldstein, J
Carbonell, J. and Goldstein, J. The use of mmr, diversity-based reranking for reordering documents and producing summaries. In Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval, pp.\ 335--336, 1998
1998
-
[4]
and Verma, V
Chakraborty, J. and Verma, V. A survey of diversification techniques in recommendation systems. In 2016 International Conference on Data Mining and Advanced Computing (SAPIENCE), pp.\ 35--40. IEEE, 2016
2016
-
[5]
Chen, M., Beutel, A., Covington, P., Jain, S., Belletti, F., and Chi, E. H. Top-k off-policy correction for a reinforce recommender system. In Proceedings of the 12th ACM International Conference on Web Search and Data Mining, pp.\ 456--464, 2019
2019
-
[6]
Achieving a better tradeoff in multi-stage recommender systems through personalization
Evnine, A., Ioannidis, S., Kalimeris, D., Kalyanaraman, S., Li, W., Nir, I., Sun, W., and Weinsberg, U. Achieving a better tradeoff in multi-stage recommender systems through personalization. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp.\ 4939--4950, 2024
2024
-
[7]
Kuairec: A fully-observed dataset and insights for evaluating recommender systems
Gao, C., Li, S., Lei, W., Chen, J., Li, B., Jiang, P., He, X., Mao, J., and Chua, T.-S. Kuairec: A fully-observed dataset and insights for evaluating recommender systems. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, pp.\ 540--550, 2022
2022
-
[8]
D., Cardie, C., Brantley, K., and Joachim, T
Gao, G., Chang, J. D., Cardie, C., Brantley, K., and Joachim, T. Policy-gradient training of language models for ranking. arXiv preprint arXiv:2310.04407, 2023
-
[9]
and Sharma, A
Gollapudi, S. and Sharma, A. An axiomatic approach for result diversification. In Proceedings of the 18th international conference on World wide web, pp.\ 381--390, 2009
2009
-
[10]
and Snelson, E
Guiver, J. and Snelson, E. Bayesian inference for plackett-luce ranking models. In Proceedings of the 26th International Conference on Machine Learning, pp.\ 377--384, 2009
2009
-
[11]
The stereotyping problem in collaboratively filtered recommender systems
Guo, W., Krauth, K., Jordan, M., and Garg, N. The stereotyping problem in collaboratively filtered recommender systems. In Proceedings of the 1st ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization, pp.\ 1--10, 2021
2021
-
[12]
Balancing exploration and exploitation in learning to rank online
Hofmann, K., Whiteson, S., and De Rijke, M. Balancing exploration and exploitation in learning to rank online. In Proceedings of the 33rd European conference on Advances in Information Retrieval, pp.\ 251--263, 2011
2011
-
[13]
On component interactions in two-stage recommender systems
Hron, J., Krauth, K., Jordan, M., and Kilbertus, N. On component interactions in two-stage recommender systems. Advances in Neural Information Processing Systems, 34: 0 2744--2757, 2021
2021
-
[14]
Personalized review recommendation based on users’ aspect sentiment
Huang, C., Jiang, W., Wu, J., and Wang, G. Personalized review recommendation based on users’ aspect sentiment. ACM Transactions on Internet Technology, 20 0 (4): 0 1--26, 2020
2020
-
[15]
a rvelin, K. and Kek \
J \"a rvelin, K. and Kek \"a l \"a inen, J. Cumulated gain-based evaluation of ir techniques. ACM Transactions on Information Systems (TOIS), 20 0 (4): 0 422--446, 2002
2002
-
[16]
Unbiased learning-to-rank with biased feedback
Joachims, T., Swaminathan, A., and Schnabel, T. Unbiased learning-to-rank with biased feedback. In Proceedings of the 10th ACM International Conference on Web Search and Data Mining, pp.\ 781--789, 2017
2017
-
[17]
Doubly robust off-policy evaluation for ranking policies under the cascade behavior model
Kiyohara, H., Saito, Y., Matsuhiro, T., Narita, Y., Shimizu, N., and Yamamoto, Y. Doubly robust off-policy evaluation for ranking policies under the cascade behavior model. In Proceedings of the 15th ACM International Conference on Web Search and Data Mining, pp.\ 487–497, 2022
2022
-
[18]
Off-policy learning for diversity-aware candidate retrieval in two-stage decisions
Kiyohara, H., Khanna, R., and Joachims, T. Off-policy learning for diversity-aware candidate retrieval in two-stage decisions. In ICML 2025 Workshop on Scaling Up Intervention Models, 2025
2025
-
[19]
and Raghu, M
Kleinberg, J. and Raghu, M. Team performance with test scores. ACM Transactions on Economics and Computation (TEAC), 6 0 (3-4): 0 1--26, 2018
2018
-
[20]
and Tsitsiklis, J
Konda, V. and Tsitsiklis, J. Actor-critic algorithms. Advances in Neural Information Processing Systems, 12, 1999
1999
-
[21]
Stochastic beams and where to find them: The gumbel-top-k trick for sampling sequences without replacement
Kool, W., Van Hoof, H., and Welling, M. Stochastic beams and where to find them: The gumbel-top-k trick for sampling sequences without replacement. In Proceedings of the 36th International Conference on Machine Learning, pp.\ 3499--3508, 2019
2019
-
[22]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Levine, S., Kumar, A., Tucker, G., and Fu, J. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[23]
u ttler, H., Lewis, M., Yih, W.-t., Rockt \
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., K \"u ttler, H., Lewis, M., Yih, W.-t., Rockt \"a schel, T., et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33: 0 9459--9474, 2020
2020
-
[24]
Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms
Li, L., Chu, W., Langford, J., and Wang, X. Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms. In Proceedings of the fourth ACM international conference on Web search and data mining, pp.\ 297--306, 2011
2011
-
[25]
Liu, T.-Y. et al. Learning to rank for information retrieval. Foundations and Trends in Information Retrieval , 3 0 (3): 0 225--331, 2009
2009
-
[26]
Ma, J., Zhao, Z., Yi, X., Yang, J., Chen, M., Tang, J., Hong, L., and Chi, E. H. Off-policy learning in two-stage recommender systems. In Proceedings of The Web Conference 2020, pp.\ 463--473, 2020
2020
-
[27]
Learning-to-rank with partitioned preference: Fast estimation for the plackett-luce model
Ma, J., Yi, X., Tang, W., Zhao, Z., Hong, L., Chi, E., and Mei, Q. Learning-to-rank with partitioned preference: Fast estimation for the plackett-luce model. In International Conference on Artificial Intelligence and Statistics, pp.\ 928--936. PMLR, 2021
2021
-
[28]
and Grossglauser, M
Maystre, L. and Grossglauser, M. Fast and accurate inference of plackett--luce models. Advances in Neural Information Processing Systems, 28, 2015
2015
-
[29]
Hitting the high notes: Subset selection for maximizing expected order statistics
Mehta, A., Nadav, U., Psomas, A., and Rubinstein, A. Hitting the high notes: Subset selection for maximizing expected order statistics. Advances in Neural Information Processing Systems, 33: 0 15800--15810, 2020
2020
-
[30]
Computationally efficient optimization of plackett-luce ranking models for relevance and fairness
Oosterhuis, H. Computationally efficient optimization of plackett-luce ranking models for relevance and fairness. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp.\ 1023--1032, 2021
2021
-
[31]
Pytorch: An imperative style, high-performance deep learning library
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al. Pytorch: An imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems, 32, 2019
2019
-
[32]
D., Ermon, S., and Finn, C
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36: 0 53728--53741, 2023
2023
-
[33]
Fast slate policy optimization: Going beyond plackett-luce
Sakhi, O., Rohde, D., and Chopin, N. Fast slate policy optimization: Going beyond plackett-luce. arXiv preprint arXiv:2308.01566, 2023
-
[34]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
S., Barto, A
Sutton, R. S., Barto, A. G., et al. Reinforcement learning. Journal of Cognitive Neuroscience, 11 0 (1): 0 126--134, 1999
1999
-
[37]
and Joachims, T
Swaminathan, A. and Joachims, T. Counterfactual risk minimization: Learning from logged bandit feedback. In International Conference on Machine Learning, pp.\ 814--823, 2015
2015
-
[38]
and Joachims, T
Wang, L. and Joachims, T. User fairness, item fairness, and diversity for rankings in two-sided markets. In Proceedings of the 44th ACM SIGIR International Conference on Theory of Information Retrieval, pp.\ 23--41, 2021
2021
-
[39]
Williams, R. J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8 0 (3): 0 229--256, 1992
1992
-
[40]
Result diversification in search and recommendation: A survey
Wu, H., Zhang, Y., Ma, C., Lyu, F., He, B., Mitra, B., and Liu, X. Result diversification in search and recommendation: A survey. IEEE Transactions on Knowledge and Data Engineering, 36 0 (10): 0 5354--5373, 2024
2024
-
[41]
It takes variety to make a world: diversification in recommender systems
Yu, C., Lakshmanan, L., and Amer-Yahia, S. It takes variety to make a world: diversification in recommender systems. In Proceedings of the 12th international conference on extending database technology: Advances in database technology, pp.\ 368--378, 2009
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.