Constitutional Arms Races in the Public Goods Game: Co-Evolving LLM Constitutions Under Cooperation-Defection Pressure
Pith reviewed 2026-07-01 16:53 UTC · model grok-4.3
The pith
LLM constitutions co-evolve to a stable near-parity equilibrium in public goods games when fitness couples the factions and evaluation uses enough seeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
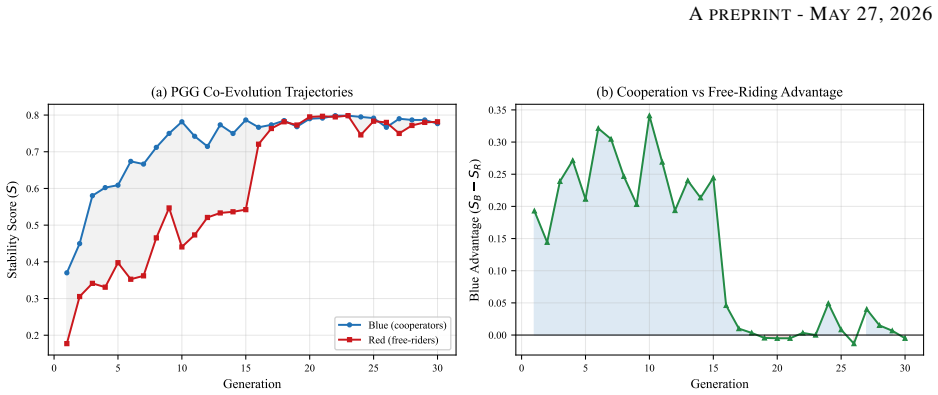
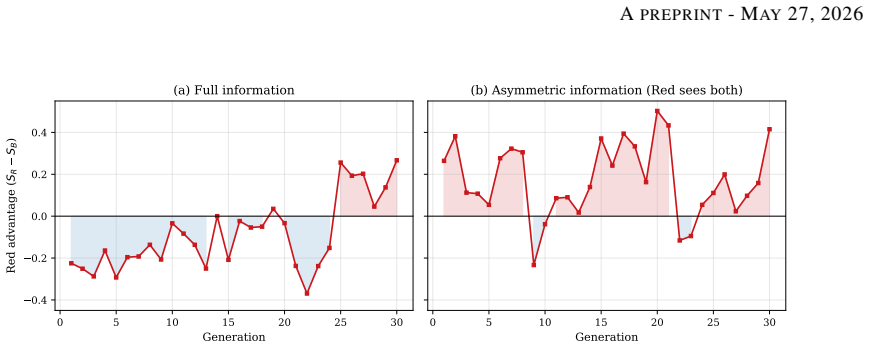
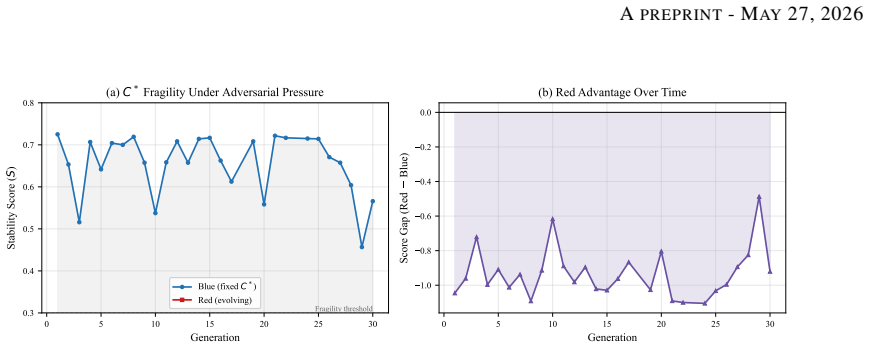
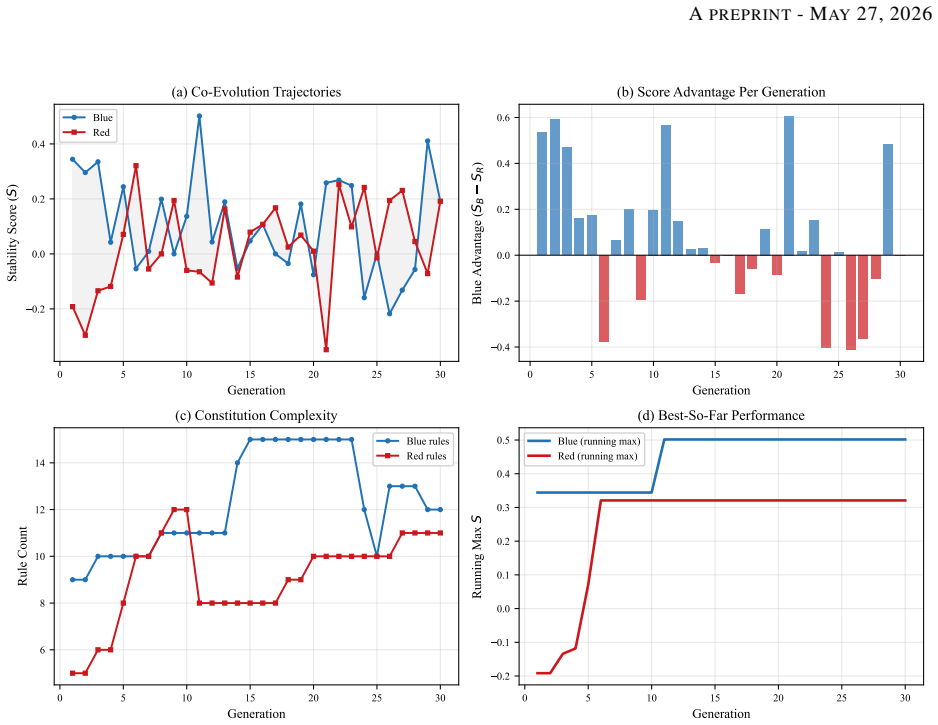
In the Public Goods Game, Blue cooperators and Red free-riders co-evolve their constitutions over 30 generations and reach a near-parity equilibrium at S approximately 0.78 that holds across multipliers m in {1.2, 1.5, 2.0, 3.0}. Independent per-faction scoring leaves outcomes uncoupled with correlation +0.088 and generates no adversarial pressure, while a score-advantage target S_own minus S_opp restores the pressure. Under pure-adversary fitness, K=2 evaluation seeds cause mode regression but K=5 sustains strong specialists across all generations. Adversarial co-evolution of natural-language constitutions is therefore feasible only under coupled fitness and adequate evaluation budget, and
What carries the argument
Adversarial constitutional co-evolution of LLM agents in a Public Goods Game driven by a score-advantage fitness function and LLM-based mutation.
If this is right
- Both factions reach stable performance parity only when fitness explicitly compares their scores.
- Score-advantage fitness is required to create measurable adversarial pressure between constitutions.
- Five evaluation seeds per generation prevent regression into weak modes for the Red specialist.
- Evolved Red constitutions supply readable test cases for checking future cooperative LLM designs.
- The near-parity outcome holds across a range of public-goods multipliers.
Where Pith is reading between the lines
- The same co-evolution setup could be applied to grid-world or other spatial environments to check whether parity still emerges.
- Red constitutions might expose recurring patterns in how LLMs fail at cooperation that could guide alignment techniques.
- Longer runs or larger populations might require proportionally larger evaluation budgets to avoid regression.
- Transfer tests could check whether constitutions evolved in the public goods game remain effective when placed in new games.
Load-bearing premise
The LLM mutation operator must continue to produce reliable changes even when the objective is specialized adversarial performance rather than cooperation.
What would settle it
Running the 30-generation co-evolution with K=5 seeds and finding that Red performance regresses relative to Blue across repeated trials would falsify the claim that adequate evaluation budget sustains specialists.
Figures
read the original abstract
Frontier LLM agents engage in blackmail, sabotage, and document leaks under goal conflicts in agentic settings, exposing limitations of alignment methods built around single-agent or cooperative assumptions. Recent work shows LLM-guided evolutionary search can discover effective cooperative constitutions, but two properties of the adversarial setting remain uncharacterized: whether the fitness function actually induces adversarial pressure, and whether the LLM mutation operator behaves reliably under adversarial-specialist objectives. We study adversarial constitutional co-evolution (Blue cooperators vs. Red free-riders, 30 generations) across a Public Goods Game (PGG) and a spatial grid-world. Three findings: (1) in the PGG, both factions converge to a near-parity equilibrium at S approximately 0.78, robust across tested multipliers m in {1.2, 1.5, 2.0, 3.0}; (2) in independently scored environments, per-faction scoring leaves outcomes statistically uncoupled, with corr(S_B, S_R) = +0.088, and produces no adversarial pressure; a score-advantage fitness target S_own - S_opp restores it; (3) under pure-adversary fitness, evaluation seed count K controls mode regression: K = 2 regresses, while K = 5 sustains a strong specialist for all 30 generations. Adversarial co-evolution of natural-language constitutions is feasible, but only under coupled fitness and adequate evaluation budget; the evolved Red constitutions serve as interpretable red-team artifacts for testing future cooperative designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical simulation study of adversarial co-evolution between Blue (cooperator) and Red (free-rider) LLM constitutions over 30 generations in a Public Goods Game (PGG) with multipliers m in {1.2,1.5,2.0,3.0} and a spatial grid-world. It claims three findings: (1) both factions converge to a near-parity equilibrium at S≈0.78; (2) per-faction scoring yields uncoupled outcomes (corr(S_B,S_R)=+0.088) with no adversarial pressure while the coupled target S_own−S_opp restores it; (3) evaluation seed count K=2 induces mode regression while K=5 sustains specialist behavior. The central conclusion is that adversarial constitutional co-evolution is feasible only under coupled fitness and adequate evaluation budget, with evolved Red constitutions serving as red-team artifacts.
Significance. If the reported equilibria and conditional feasibility hold, the work supplies directly testable red-team artifacts and characterizes the two properties left open by prior LLM-guided evolutionary search for cooperative constitutions. The explicit empirical tests of fitness coupling and mutation reliability under specialist objectives constitute a clear advance for multi-agent alignment research addressing goal conflicts.
major comments (2)
- [Results, finding (2)] Results, finding (2): the reported correlation corr(S_B, S_R)=+0.088 is presented without sample size, number of independent runs, p-value, or confidence interval, which is load-bearing for the claim that per-faction scoring produces statistically uncoupled outcomes and no adversarial pressure.
- [Results, finding (3)] Results, finding (3): the claim that K=2 produces mode regression while K=5 sustains specialist behavior for all 30 generations lacks reported variance, number of runs, or exclusion criteria, which is load-bearing for the assertion that adequate evaluation budget is required to avoid regression.
minor comments (2)
- [Abstract] Abstract: the symbol S is used without an explicit definition or reference to its computation in the PGG payoff structure.
- [Methods] The manuscript should include a table or figure caption that reports the exact number of generations, population size, and LLM model version used in all runs.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and for identifying the need for additional statistical detail in the reported results. We address both major comments below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Results, finding (2)] Results, finding (2): the reported correlation corr(S_B, S_R)=+0.088 is presented without sample size, number of independent runs, p-value, or confidence interval, which is load-bearing for the claim that per-faction scoring produces statistically uncoupled outcomes and no adversarial pressure.
Authors: We agree that the statistical details are required to substantiate the claim. The correlation value was obtained from the full set of independent evolutionary runs performed in the study. In the revised manuscript we will explicitly state the sample size (number of independent runs), report the associated p-value, and include a confidence interval to confirm that the outcomes remain statistically uncoupled under per-faction scoring. revision: yes
-
Referee: [Results, finding (3)] Results, finding (3): the claim that K=2 produces mode regression while K=5 sustains specialist behavior for all 30 generations lacks reported variance, number of runs, or exclusion criteria, which is load-bearing for the assertion that adequate evaluation budget is required to avoid regression.
Authors: We agree that variance, run count, and any exclusion criteria should be reported. The K=2 versus K=5 comparison was conducted across multiple independent runs; we will add the observed variance, the exact number of runs, and a clear statement of exclusion criteria (if any) to the revised text so that the requirement for adequate evaluation budget is fully supported. revision: yes
Circularity Check
No significant circularity
full rationale
This paper reports an empirical simulation study of adversarial co-evolution between LLM-generated constitutions in a Public Goods Game and spatial grid-world. All headline results (equilibrium scores near 0.78, correlation under different fitness targets, effect of evaluation seed count K) are direct outputs of running the described evolutionary process for 30 generations under explicitly varied conditions. No equations, uniqueness theorems, or predictions are derived; the work contains no mathematical chain that could reduce outputs to inputs by construction, and the two uncharacterized properties are addressed via independent empirical tests rather than self-referential definitions or self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Shiyang Lai, Yujin Potter, Junsol Kim, Richard Zhuang, Dawn Song, and James Evans. Evolving ai collectives to enhance human diversity and enable self-regulation.arXiv preprint arXiv:2402.12590, 2024
-
[3]
Florian Carichon, Aditi Khandelwal, Marylou Fauchard, and Golnoosh Farnadi. The coming crisis of multi-agent misalignment: Ai alignment must be a dynamic and social process.arXiv preprint arXiv:2506.01080, 2025
-
[4]
Alexander Meinke, Bronson Schoen, Jérémy Scheurer, Mikita Balesni, Rusheb Shah, and Marius Hobbhahn
Aengus Lynch, Benjamin Wright, Caleb Larson, Stuart J. Ritchie, Sören Mindermann, Evan Hubinger, Ethan Perez, and Kevin K. Troy. Agentic misalignment: How llms could be insider threats.arXiv preprint arXiv:2510.05179, 2025
-
[5]
Ujwal Kumar, Alice Saito, Hershraj Niranjani, Rayan Yessou, and Phan Xuan Tan. Evolving interpretable constitutions for multi-agent coordination.arXiv preprint arXiv:2602.00755, 2026
-
[6]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Hamilton
Robert Axelrod and William D. Hamilton. The evolution of cooperation.Science, 211(4489):1390–1396, 1981
1981
-
[8]
Leibo, Vinicius Zambaldi, Marc Lanctot, Janusz Marecki, and Thore Graepel
Joel Z. Leibo, Vinicius Zambaldi, Marc Lanctot, Janusz Marecki, and Thore Graepel. Multi-agent reinforcement learning in sequential social dilemmas. InProceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems (AAMAS), pages 464–473, 2017
2017
-
[9]
Leibo, Matthew Phillips, Karl Tuyls, Edgar Dueñez-Guzman, Antonio García Castañeda, Iain Dunning, Tina Zhu, Kevin McKee, Raphael Koster, et al
Edward Hughes, Joel Z. Leibo, Matthew Phillips, Karl Tuyls, Edgar Dueñez-Guzman, Antonio García Castañeda, Iain Dunning, Tina Zhu, Kevin McKee, Raphael Koster, et al. Inequity aversion improves cooperation in intertemporal social dilemmas. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[10]
Natasha Jaques, Angeliki Lazaridou, Edward Hughes, Caglar Gulcehre, Pedro Ortega, D. J. Strouse, Joel Z. Leibo, and Nando De Freitas. Social influence as intrinsic motivation for multi-agent deep reinforcement learning. In Proceedings of the 36th International Conference on Machine Learning (ICML), 2019
2019
-
[11]
Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C. O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior.arXiv preprint arXiv:2304.03442, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of Go with deep neural networks and tree search.Nature, 529(7587):484–489, 2016
2016
-
[13]
Dota 2 with Large Scale Deep Reinforcement Learning
OpenAI, Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław D˛ ebiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, et al. Dota 2 with large scale deep reinforcement learning.arXiv preprint arXiv:1912.06680, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[14]
Rui Wang, Joel Lehman, Jeff Clune, and Kenneth O. Stanley. Paired Open-Ended Trailblazer (POET): End- lessly generating increasingly complex and diverse learning environments and their solutions.arXiv preprint arXiv:1901.01753, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[15]
Udaya Sankar, Vishisht Srihari Rao, Mayank Ratan Bhardwaj, and Y
V . Udaya Sankar, Vishisht Srihari Rao, Mayank Ratan Bhardwaj, and Y . Narahari. Deep learning meets mechanism design: Key results and some novel applications.arXiv preprint arXiv:2401.05683, 2024
-
[16]
Jiayuan Liu, Mingyu Guo, and Vincent Conitzer. An interpretable automated mechanism design framework with large language models.arXiv preprint arXiv:2502.12203, 2025
-
[17]
Human-centred mechanism design with democratic AI.Nature Human Behaviour, 6(10):1398–1407, 2022
Raphael Koster, Jan Balaguer, Andrea Tacchetti, Ari Weinstein, Tina Zhu, Oliver Hauser, Duncan Williams, Lucy Campbell-Gillingham, Phoebe Thacker, Matthew Botvinick, and Christopher Summerfield. Human-centred mechanism design with democratic AI.Nature Human Behaviour, 6(10):1398–1407, 2022
2022
-
[18]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models.Nature, 625(7995):468–475, 2024
2024
-
[19]
AlphaEvolve: A Gemini-powered coding agent for designing advanced algorithms
AlphaEvolve Team. AlphaEvolve: A Gemini-powered coding agent for designing advanced algorithms. Google DeepMind Blog, 2025
2025
- [20]
-
[21]
OpenEvolve: An open-source evolutionary coding agent
Asankhaya Sharma. OpenEvolve: An open-source evolutionary coding agent. https://github.com/ algorithmicsuperintelligence/openevolve, 2025
2025
-
[22]
Illuminating search spaces by mapping elites
Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
Cooperation and punishment in public goods experiments.American Economic Review, 90(4):980–994, 2000
Ernst Fehr and Simon Gächter. Cooperation and punishment in public goods experiments.American Economic Review, 90(4):980–994, 2000
2000
-
[24]
V olunteering as Red Queen mechanism for cooperation in public goods games.Science, 296(5570):1129–1132, 2002
Christoph Hauert, Silvia De Monte, Josef Hofbauer, and Karl Sigmund. V olunteering as Red Queen mechanism for cooperation in public goods games.Science, 296(5570):1129–1132, 2002
2002
-
[25]
Rand, Anna Dreber, Tore Ellingsen, Drew Fudenberg, and Martin A
David G. Rand, Anna Dreber, Tore Ellingsen, Drew Fudenberg, and Martin A. Nowak. Positive interactions promote public cooperation.Science, 325(5945):1272–1275, 2009
2009
-
[26]
win” from killing Blue agents is indistinguishable from a Red “win
OpenAI. GPT-OSS-120B.https://openrouter.ai/openai/gpt-oss-120b, 2025. 10 APREPRINT- MAY27, 2026 Appendix A Formal Algorithm and Optimization Definition The framework summary in Section 5.1 omitted formal details for brevity. Here we give them explicitly. Definition A.1(Co-Evolution).Given environment E, initial constitutions C 0 B, C0 R, and scoring funct...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.