R³: 3D Reconstruction via Relative Regression
Pith reviewed 2026-06-29 17:53 UTC · model grok-4.3
The pith
R³ uses relative regression via a lightweight MLP to predict confidence-weighted constraints, removing the global coordinate frame bottleneck for long-context and streaming 3D reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
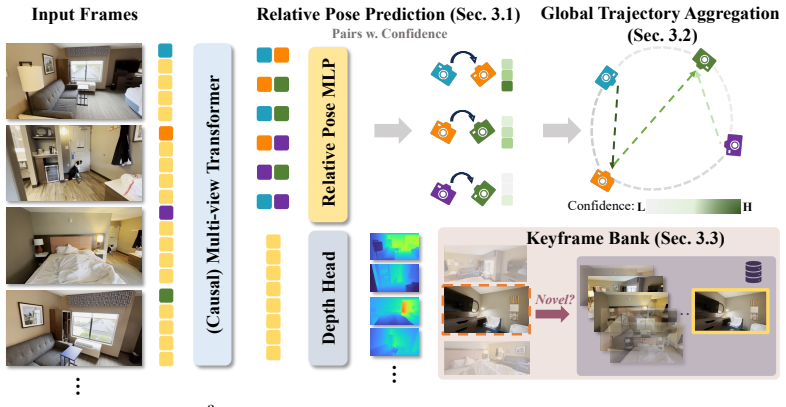
R³ employs relative regression. We employ a lightweight MLP to predict confidence-weighted relative constraints. These confidences serve as a unified anchor: weighting losses during training and guiding pose aggregation during inference. R³ supports both full-context offline reconstruction and causal, bounded-memory streaming.
What carries the argument
Confidence-weighted relative constraints output by a lightweight MLP, acting as the single anchor for loss weighting in training and pose aggregation in inference.
If this is right
- Full-context offline reconstruction becomes possible without global-frame constraints.
- Causal streaming reconstruction runs with bounded memory and no need to maintain an arbitrary temporal origin.
- Translation magnitudes no longer grow unbounded, avoiding the scaling issues that appear in long sequences.
- The same predicted confidences improve training stability and inference aggregation in both modes.
Where Pith is reading between the lines
- The bounded-memory streaming mode opens the door to real-time applications such as live AR or robot navigation where memory must stay fixed.
- Relative regression may transfer to other sequential geometry tasks like video-based SLAM where global frames produce similar drift.
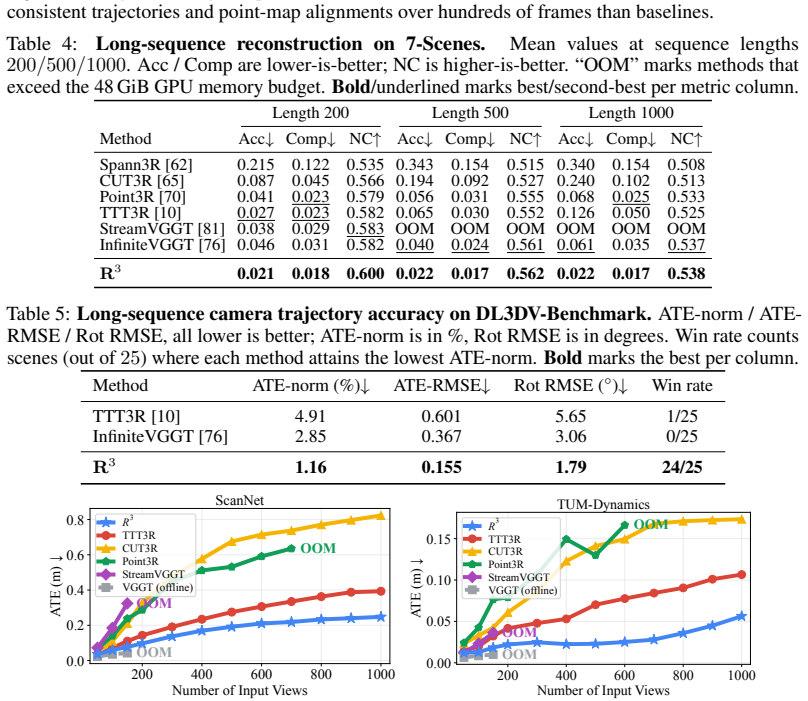
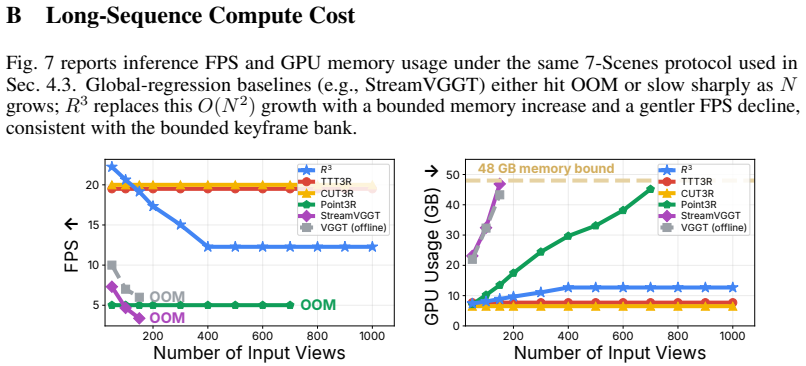
- Direct comparisons of cumulative error on hour-long sequences would test whether the unified anchor fully eliminates the accumulation problem.
Load-bearing premise
The MLP can produce relative constraints and confidences accurate enough to prevent error accumulation or drift when used for streaming inference over long sequences.
What would settle it
Measuring large pose drift or reconstruction collapse on extended streaming video sequences when the relative mechanism is applied would show the central claim does not hold.
Figures







read the original abstract
Recent feed-forward geometry foundation models have demonstrated impressive generalization by recovering depth and poses in a single forward pass. However, these models are typically constrained by a global coordinate frame assumption. This dependency becomes a significant bottleneck for long-context and streaming reconstruction, as it forces the network to maintain an arbitrary temporal origin and handle translation magnitudes that grow unbounded over time. Our solution, which we call $R^3$, employs relative regression. We employ a lightweight MLP to predict confidence-weighted relative constraints. These confidences serve as a unified anchor: weighting losses during training and guiding pose aggregation during inference. $R^3$ supports both full-context offline reconstruction and causal, bounded-memory streaming. Our evaluation in both offline and streaming settings validates the effectiveness of our relative mechanism. Project page: https://kevinxu02.github.io/r3-site
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes $R^3$, a feed-forward 3D reconstruction method that replaces global coordinate frame regression with relative regression. A lightweight MLP predicts confidence-weighted relative constraints; these confidences weight the training losses and, at inference, guide pose aggregation. The method is claimed to support both full-context offline reconstruction and causal streaming reconstruction with bounded memory. Evaluation in both regimes is said to validate the relative mechanism.
Significance. If the confidence-weighted aggregation demonstrably bounds drift, the unified-anchor design would be a practical contribution to long-sequence and streaming reconstruction, removing the need to regress unbounded translations. The idea of reusing the same predicted confidences for both loss weighting and inference-time aggregation is a clean architectural choice.
major comments (1)
- [Abstract] Abstract: the central claim that the MLP-predicted confidences prevent unbounded error growth during causal streaming aggregation is load-bearing, yet the text supplies neither the aggregation equations, a drift bound, nor an ablation isolating the confidence mechanism; without these the effectiveness statement cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below and will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the MLP-predicted confidences prevent unbounded error growth during causal streaming aggregation is load-bearing, yet the text supplies neither the aggregation equations, a drift bound, nor an ablation isolating the confidence mechanism; without these the effectiveness statement cannot be evaluated.
Authors: We agree that the abstract's claim about bounded error growth in causal streaming would be stronger with explicit technical support. The current manuscript describes the relative regression and the dual use of MLP-predicted confidences for loss weighting and pose aggregation, but does not present the aggregation equations, a drift analysis, or a dedicated ablation in the main text or appendix. In the revision we will (1) add the aggregation equations and a simple drift bound to Section 3, (2) include an ablation isolating the confidence weights in the streaming setting in Section 4, and (3) revise the abstract to reference these additions rather than stating the effectiveness claim without support. These changes directly address the concern. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The abstract and description present R³ as employing relative regression via a lightweight MLP for confidence-weighted constraints that act as a unified anchor, but contain no equations, derivations, self-citations, or fitted parameters renamed as predictions. No load-bearing step reduces to its own inputs by construction. The method is described at a conceptual level with evaluation claimed to validate it, making the derivation self-contained against external benchmarks with no circularity indicators.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Map-free visual relocalization: Metric pose relative to a single image
Eduardo Arnold, Jamie Wynn, Sara Vicente, Guillermo Garcia-Hernando, Áron Monszpart, Vic- tor Prisacariu, Daniyar Turmukhambetov, and Eric Brachmann. Map-free visual relocalization: Metric pose relative to a single image. InEuropean Conference on Computer Vision (ECCV), 2022
2022
-
[2]
Neural rgb-d surface reconstruction
Dejan Azinovi´c, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural rgb-d surface reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6290–6301, June 2022
2022
-
[3]
ARKitScenes: A diverse real-world dataset for 3D indoor scene understanding using mobile RGB-D data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, and Elad Shulman. ARKitScenes: A diverse real-world dataset for 3D indoor scene understanding using mobile RGB-D data. In Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2021
2021
-
[4]
Butler, Jonas Wulff, Garrett B
Daniel J. Butler, Jonas Wulff, Garrett B. Stanley, and Michael J. Black. A naturalistic open source movie for optical flow evaluation. InEuropean Conference on Computer Vision (ECCV), 2012
2012
-
[5]
Yohann Cabon, Naila Murray, and Martin Humenberger. Virtual KITTI 2.arXiv preprint arXiv:2001.10773, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[6]
MUSt3R: Multi-view network for stereo 3D reconstruction
Yohann Cabon, Lucas Stoffl, Leonid Antsfeld, Gabriela Csurka, Boris Chidlovskii, Jérôme Revaud, and Vincent Leroy. MUSt3R: Multi-view network for stereo 3D reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[7]
Gómez Rodríguez, J
Carlos Campos, Richard Elvira, Juan J. Gómez Rodríguez, J. M. M. Montiel, and Juan D. Tardós. ORB-SLAM3: An accurate open-source library for visual, visual-inertial, and multimap SLAM.IEEE Transactions on Robotics, 37(6):1874–1890, 2021
2021
-
[8]
Geometric Context Transformer for Streaming 3D Reconstruction
Lin-Zhuo Chen, Jian Gao, Yihang Chen, Ka Leong Cheng, Yipengjing Sun, Liangxiao Hu, Nan Xue, Xing Zhu, Yujun Shen, Yao Yao, and Yinghao Xu. Geometric context transformer for streaming 3D reconstruction.arXiv preprint arXiv:2604.14141, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Easi3R: Estimat- ing disentangled motion from DUSt3R without training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Easi3R: Estimat- ing disentangled motion from DUSt3R without training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. arXiv:2503.24391
-
[10]
TTT3R: 3D Reconstruction as Test-Time Training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. TTT3R: 3D recon- struction as test-time training.arXiv preprint arXiv:2509.26645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
arXiv preprint arXiv:2510.06219 , year=
Yue Chen, Xingyu Chen, Yuxuan Xue, Anpei Chen, Yuliang Xiu, and Gerard Pons-Moll. Human3R: Everyone everywhere all at once. InInternational Conference on Learning Repre- sentations (ICLR), 2026. arXiv:2510.06219
-
[12]
LONG3R: Long se- quence streaming 3D reconstruction
Zhuoguang Chen, Minghui Qin, Tianyuan Yuan, Zhe Liu, and Hang Zhao. LONG3R: Long se- quence streaming 3D reconstruction. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. arXiv:2507.18255
-
[13]
Chong Cheng, Xianda Chen, Tao Xie, Wei Yin, Weiqiang Ren, Qian Zhang, Xiaoyang Guo, and Hao Wang. LongStream: Long-sequence streaming autoregressive visual geometry.arXiv preprint arXiv:2602.13172, 2026. 10
-
[14]
Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. ScanNet: Richly-annotated 3D reconstructions of indoor scenes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
2017
-
[15]
SuperPoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperPoint: Self-supervised interest point detection and description. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2018
2018
-
[16]
Flex Attention: A Programming Model for Generating Optimized Attention Kernels
Juechu Dong, Boyuan Feng, Driss Guessous, Yanbo Liang, and Horace He. Flex attention: A pro- gramming model for generating optimized attention kernels.arXiv preprint arXiv:2412.05496, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
MASt3R-SfM: A fully-integrated solution for unconstrained structure- from-motion
Bardienus Pieter Duisterhof, Lojze Zust, Philippe Weinzaepfel, Vincent Leroy, Yohann Cabon, and Jérôme Revaud. MASt3R-SfM: A fully-integrated solution for unconstrained structure- from-motion. InInternational Conference on 3D Vision (3DV), 2025
2025
-
[18]
VGG-T 3: Offline feed-forward 3D reconstruction at scale.arXiv preprint arXiv:2602.23361, 2026
Sven Elflein, Ruilong Li, Sérgio Agostinho, Zan Gojcic, Laura Leal-Taixé, Qunjie Zhou, and Aljosa Osep. VGG-T 3: Offline feed-forward 3D reconstruction at scale.arXiv preprint arXiv:2602.23361, 2026
-
[19]
Direct sparse odometry.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 40(3):611–625, 2018
Jakob Engel, Vladlen Koltun, and Daniel Cremers. Direct sparse odometry.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 40(3):611–625, 2018
2018
-
[20]
Accurate, dense, and robust multi-view stereopsis.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 32(8):1362–1376, 2010
Yasutaka Furukawa and Jean Ponce. Accurate, dense, and robust multi-view stereopsis.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 32(8):1362–1376, 2010
2010
-
[21]
Are we ready for autonomous driving? the KITTI vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the KITTI vision benchmark suite. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012
2012
-
[22]
Jisang Han, Sunghwan Hong, Jaewoo Jung, Wooseok Jang, Honggyu An, Qianqian Wang, Seungryong Kim, and Chen Feng. Emergent outlier view rejection in visual geometry grounded transformers.arXiv preprint arXiv:2512.04012, 2025
-
[23]
DeepMVS: Learning multi-view stereopsis
Po-Han Huang, Kevin Matzen, Johannes Kopf, Narendra Ahuja, and Jia-Bin Huang. DeepMVS: Learning multi-view stereopsis. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[24]
Pow3R: Empowering unconstrained 3D reconstruction with camera and scene priors
Wonbong Jang, Philippe Weinzaepfel, Vincent Leroy, Lourdes Agapito, and Jérôme Revaud. Pow3R: Empowering unconstrained 3D reconstruction with camera and scene priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1071–1081, 2025
2025
-
[25]
Barron, Noah Snavely, and Aleksander Hoły´nski
Haian Jin, Rundi Wu, Tianyuan Zhang, Ruiqi Gao, Jonathan T. Barron, Noah Snavely, and Aleksander Hoły´nski. ZipMap: Linear-time stateful 3D reconstruction via test-time training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
-
[26]
DynamicStereo: Consistent dynamic depth from stereo videos
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. DynamicStereo: Consistent dynamic depth from stereo videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[27]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, To- bias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, Jonathon Luiten, Manuel Lopez-Antequera, Samuel Rota Bulò, Christian Richardt, Deva Ramanan, Sebastian Scherer, and Peter Kontschieder. MapAnything: Universal feed-forward metric 3D reconstruc- tion....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Parallel tracking and mapping for small AR workspaces
Georg Klein and David Murray. Parallel tracking and mapping for small AR workspaces. In IEEE and ACM International Symposium on Mixed and Augmented Reality (ISMAR), 2007. 11
2007
-
[29]
Yushi Lan, Yihang Luo, Fangzhou Hong, Shangchen Zhou, Honghua Chen, Zhaoyang Lyu, Shuai Yang, Bo Dai, Chen Change Loy, and Xingang Pan. STream3R: Scalable sequential 3D reconstruction with causal transformer.arXiv preprint arXiv:2508.10893, 2025
-
[30]
Grounding image matching in 3D with MASt3R
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3D with MASt3R. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[31]
MegaSaM: Accurate, fast, and robust structure and motion from casual dynamic videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Hoły´nski, and Noah Snavely. MegaSaM: Accurate, fast, and robust structure and motion from casual dynamic videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10486–10496, 2025
2025
-
[32]
WinT3R: Window-based streaming reconstruction with camera token pool
Zizun Li, Jianjun Zhou, Yifan Wang, Haoyu Guo, Wenzheng Chang, Yang Zhou, Haoyi Zhu, Junyi Chen, Chunhua Shen, and Tong He. WinT3R: Window-based streaming reconstruction with camera token pool. InInternational Conference on Learning Representations (ICLR),
-
[33]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
LightGlue: Local feature matching at light speed
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Pollefeys. LightGlue: Local feature matching at light speed. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17627–17638, 2023
2023
-
[35]
DL3DV-10K: A large-scale scene dataset for deep learning-based 3D vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, Xuanmao Li, Xingpeng Sun, Rohan Ashok, Aniruddha Mukherjee, Hao Kang, Xiangrui Kong, Gang Hua, Tianyi Zhang, Bedrich Benes, and Aniket Bera. DL3DV-10K: A large-scale scene dataset for deep learning-based 3D vision. InProceedings of the IEEE/CVF Conf...
2024
-
[36]
SLAM3R: Real-time dense scene reconstruction from monocular RGB videos
Yuzheng Liu, Siyan Dong, Shuzhe Wang, Yingda Yin, Yanchao Yang, Qingnan Fan, and Baoquan Chen. SLAM3R: Real-time dense scene reconstruction from monocular RGB videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. arXiv:2412.09401
-
[37]
OVGGT: O(1) Constant-Cost Streaming Visual Geometry Transformer
Si-Yu Lu, Po-Ting Chen, Hui-Che Hsu, Sin-Ye Jhong, Wen-Huang Cheng, and Yung-Yao Chen. OVGGT: O(1) constant-cost streaming visual geometry transformer.arXiv preprint arXiv:2603.05959, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
VGGT-SLAM: Dense RGB SLAM Optimized on the SL(4) Manifold
Dominic Maggio, Hyungtae Lim, and Luca Carlone. VGGT-SLAM: Dense RGB SLAM optimized on the SL(4) manifold.arXiv preprint arXiv:2505.12549, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo
Lukas Mehl, Jenny Schmalfuss, Azin Jahedi, Yaroslava Nalivayko, and Andrés Bruhn. Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[40]
Raúl Mur-Artal and Juan D. Tardós. ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras.IEEE Transactions on Robotics, 33(5):1255–1262, 2017
2017
-
[41]
Raúl Mur-Artal, J. M. M. Montiel, and Juan D. Tardós. ORB-SLAM: A versatile and accurate monocular SLAM system.IEEE Transactions on Robotics, 31(5):1147–1163, 2015
2015
- [42]
-
[43]
DINOv2: Learning robust visual features without supervision.Transactions on Machine Learning Research (TMLR), 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick La...
2024
-
[44]
ReFusion: 3D reconstruction in dynamic environments for RGB-D cameras exploiting residuals
Emanuele Palazzolo, Jens Behley, Philipp Lottes, Philippe Giguère, and Cyrill Stachniss. ReFusion: 3D reconstruction in dynamic environments for RGB-D cameras exploiting residuals. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019
2019
-
[45]
Global structure- from-motion revisited
Linfei Pan, Daniel Barath, Marc Pollefeys, and Johannes Lutz Schönberger. Global structure- from-motion revisited. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[46]
Aria synthetic environments dataset
Project Aria. Aria synthetic environments dataset. https://www.projectaria.com/ datasets/ase/, 2024. Meta Reality Labs Research
2024
-
[47]
Common objects in 3D: Large-scale learning and evaluation of real-life 3D category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Common objects in 3D: Large-scale learning and evaluation of real-life 3D category reconstruction. InIEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[48]
Susskind
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InIEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[49]
Fleet, and Andrea Tagliasac- chi
Sara Sabour, Suhani V ora, Daniel Duckworth, Ivan Krasin, David J. Fleet, and Andrea Tagliasac- chi. RobustNeRF: Ignoring distractors with robust losses. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20626–20636, June 2023
2023
-
[50]
SuperGlue: Learning feature matching with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperGlue: Learning feature matching with graph neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[51]
Structure-from-motion revisited
Johannes Lutz Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[52]
Pixelwise view selection for unstructured multi-view stereo
Johannes Lutz Schönberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. InEuropean Conference on Computer Vision (ECCV), 2016
2016
-
[53]
Schönberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger
Thomas Schöps, Johannes L. Schönberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger. A multi-view stereo benchmark with high-resolution images and multi-camera videos. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
2017
-
[54]
FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
You Shen, Zhipeng Zhang, Yansong Qu, Xiawu Zheng, Jiayi Ji, Shengchuan Zhang, and Liujuan Cao. FastVGGT: Training-free acceleration of visual geometry transformer. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2509.02560
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Scene coordinate regression forests for camera relocalization in RGB-D images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene coordinate regression forests for camera relocalization in RGB-D images. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2013
2013
-
[56]
A benchmark for the evaluation of RGB-D SLAM systems
Jürgen Sturm, Nikolas Engelhard, Felix Endres, Wolfram Burgard, and Daniel Cremers. A benchmark for the evaluation of RGB-D SLAM systems. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012
2012
-
[57]
LoFTR: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. LoFTR: Detector-free local feature matching with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
- [58]
-
[59]
DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras
Zachary Teed and Jia Deng. DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. 13
2021
-
[60]
Deep patch visual odometry
Zachary Teed, Lahav Lipson, and Jia Deng. Deep patch visual odometry. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[61]
Hengyi Wang and Lourdes Agapito. AMB3R: Accurate feed-forward metric-scale 3D recon- struction with backend.arXiv preprint arXiv:2511.20343, 2025
-
[62]
3D reconstruction with spatial memory
Hengyi Wang and Lourdes Agapito. 3D reconstruction with spatial memory. InInternational Conference on 3D Vision (3DV), 2025
2025
-
[63]
VGGSfM: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. VGGSfM: Visual geometry grounded deep structure from motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[64]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[65]
Efros, and Angjoo Kanazawa
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A. Efros, and Angjoo Kanazawa. Continuous 3D perception model with persistent state. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[66]
DUSt3R: Geometric 3D vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. DUSt3R: Geometric 3D vision made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[67]
TartanAir: A dataset to push the limits of visual SLAM
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Sebastian Scherer. TartanAir: A dataset to push the limits of visual SLAM. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020
2020
-
[68]
Efficient LoFTR: Semi- dense local feature matching with sparse-like speed
Yifan Wang, Xingyi He, Sida Peng, Dongli Tan, and Xiaowei Zhou. Efficient LoFTR: Semi- dense local feature matching with sparse-like speed. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[69]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Permutation-equivariant visual geometry learning. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2507.13347
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[70]
Point3R: Streaming 3D reconstruction with explicit spatial pointer memory
Yuqi Wu, Wenzhao Zheng, Jie Zhou, and Jiwen Lu. Point3R: Streaming 3D reconstruction with explicit spatial pointer memory. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[71]
RGBD objects in the wild: Scaling real-world 3D object learning from RGB-D videos
Hongchi Xia, Yang Fu, Sifei Liu, and Xiaolong Wang. RGBD objects in the wild: Scaling real-world 3D object learning from RGB-D videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[72]
Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction
Tao Xie, Peishan Yang, Yudong Jin, Yingfeng Cai, Wei Yin, Weiqiang Ren, Qian Zhang, Wei Hua, Sida Peng, Xiaoyang Guo, and Xiaowei Zhou. Scal3R: Scalable test-time training for large-scale 3D reconstruction.arXiv preprint arXiv:2604.08542, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[73]
Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli
Jianing Yang, Alexander Sax, Kevin J. Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3R: Towards 3D reconstruction of 1000+ images in one forward pass. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[74]
MVSNet: Depth inference for unstructured multi-view stereo
Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. MVSNet: Depth inference for unstructured multi-view stereo. InEuropean Conference on Computer Vision (ECCV), 2018
2018
-
[75]
ScanNet++: A high-fidelity dataset of 3D indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. ScanNet++: A high-fidelity dataset of 3D indoor scenes. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[76]
InfiniteVGGT: Visual geometry grounded transformer for endless streams
Shuai Yuan, Yantai Yang, Xiaotian Yang, Xupeng Zhang, Zhonghao Zhao, Lingming Zhang, and Zhipeng Zhang. InfiniteVGGT: Visual geometry grounded transformer for endless streams. arXiv preprint arXiv:2601.02281, 2026. 14
-
[77]
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jampani, Trevor Darrell, Forrester Cole, Deqing Sun, and Ming-Hsuan Yang. MonST3R: A simple approach for estimating geometry in the presence of motion. InInternational Conference on Learning Representations (ICLR), 2025. arXiv:2410.03825
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
LoGeR: Long-Context Geometric Reconstruction with Hybrid Memory
Junyi Zhang, Charles Herrmann, Junhwa Hur, Chen Sun, Ming-Hsuan Yang, Forrester Cole, Trevor Darrell, and Deqing Sun. LoGeR: Long-context geometric reconstruction with hybrid memory.arXiv preprint arXiv:2603.03269, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[79]
FLARE: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views
Shangzhan Zhang, Jianyuan Wang, Yinghao Xu, Nan Xue, Christian Rupprecht, Xiaowei Zhou, Yujun Shen, and Gordon Wetzstein. FLARE: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21936–21947, 2025
2025
-
[80]
Yang Zhou, Yifan Wang, Jianjun Zhou, Wenzheng Chang, Haoyu Guo, Zizun Li, Kaijing Ma, Xinyue Li, Yating Wang, Haoyi Zhu, Mingyu Liu, Dingning Liu, Jiange Yang, Zhoujie Fu, Junyi Chen, Chunhua Shen, Jiangmiao Pang, Kaipeng Zhang, and Tong He. OmniWorld: A multi- domain and multi-modal dataset for 4D world modeling.arXiv preprint arXiv:2509.12201, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.