Trust Region Q Adjoint Matching
Pith reviewed 2026-06-29 19:00 UTC · model grok-4.3
The pith
Optimizing the trust-region parameter λ gives closed-form control over path-space KL divergence from pretrained flow policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
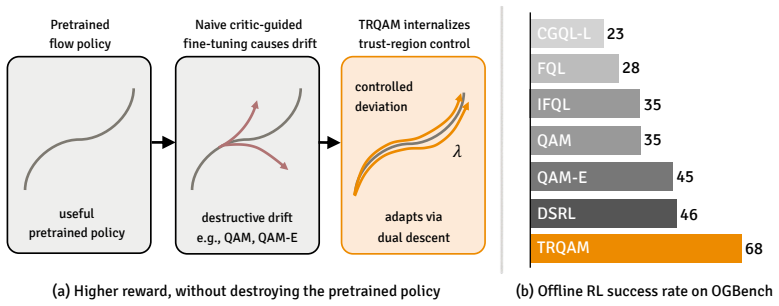
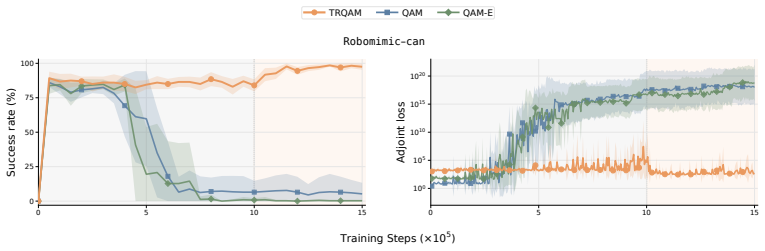
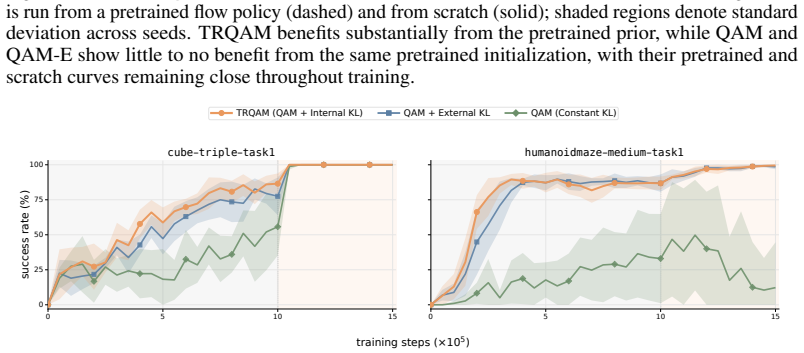
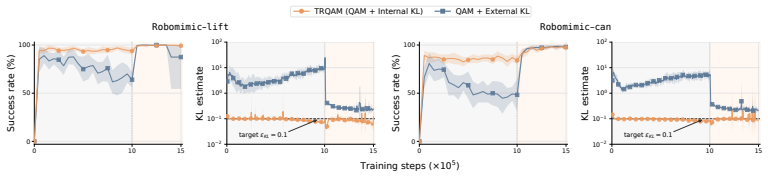
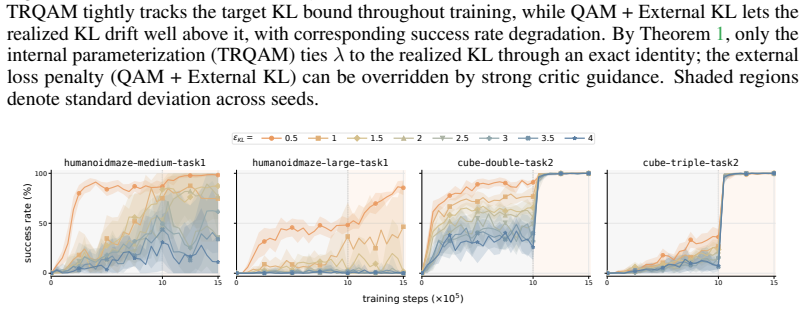
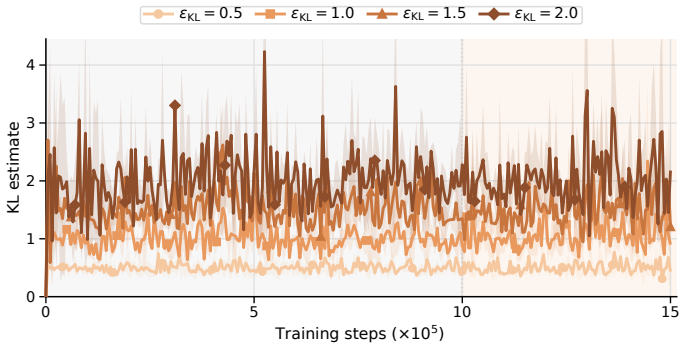
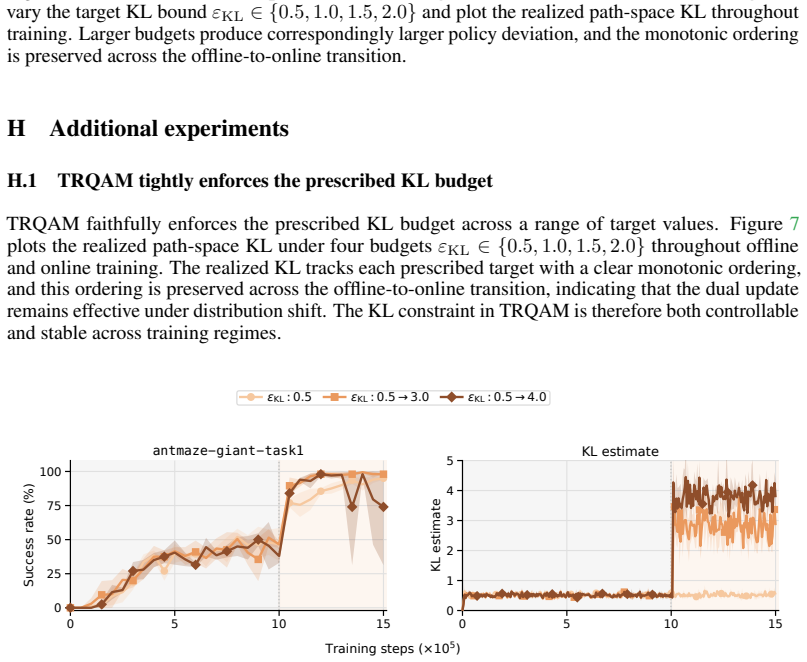
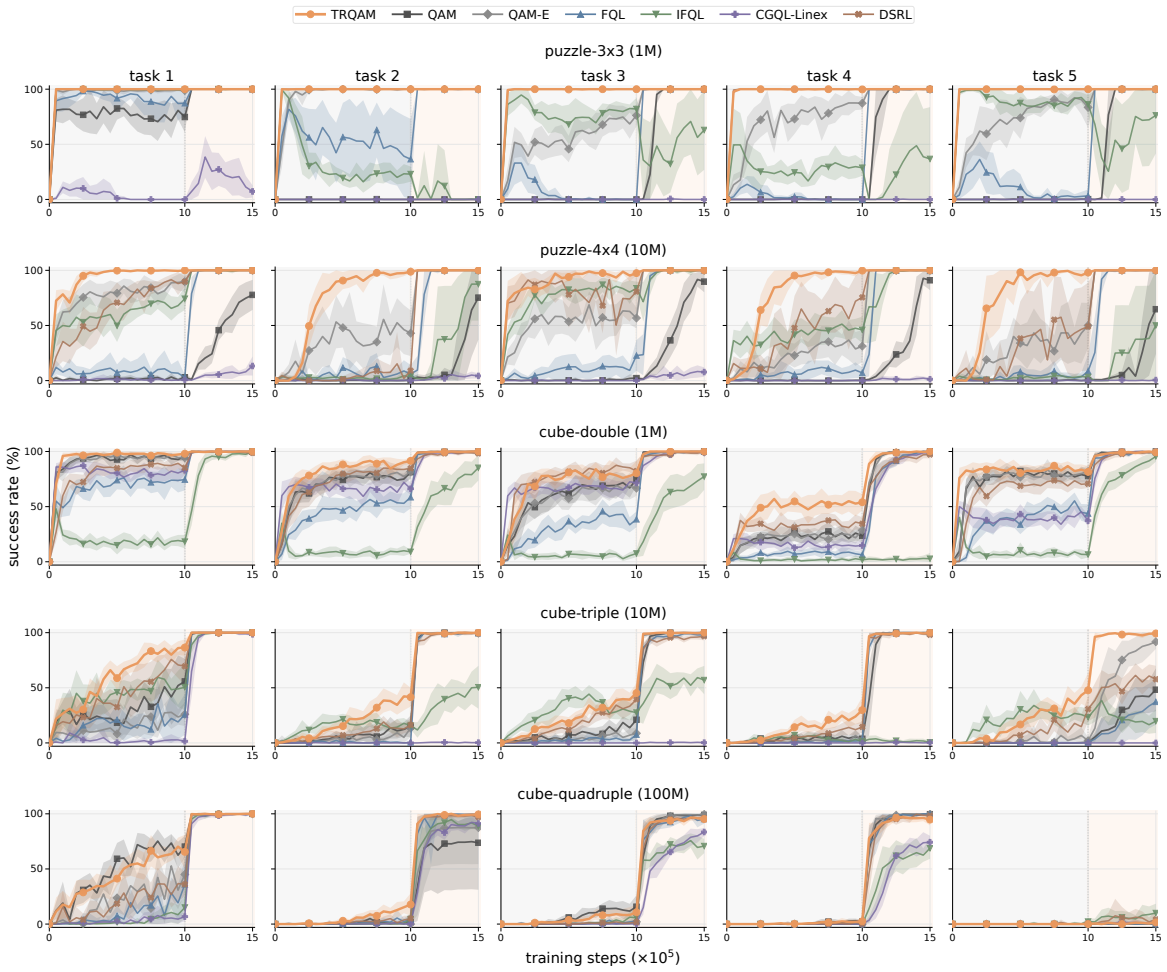
TRQAM optimizes the trust-region parameter λ inside the stochastic optimal control dynamics and shows that the path-space KL divergence admits a closed-form expression in λ. Projected dual descent on this expression therefore yields precise, adaptive control over the exact deviation from the pretrained flow policy, which in turn produces stable off-policy reinforcement learning.
What carries the argument
Projected dual descent on the trust-region parameter λ, where path-space KL divergence is a closed-form function of λ.
If this is right
- Precise control of deviation prevents the amplification of critic errors that destabilizes prior QAM methods.
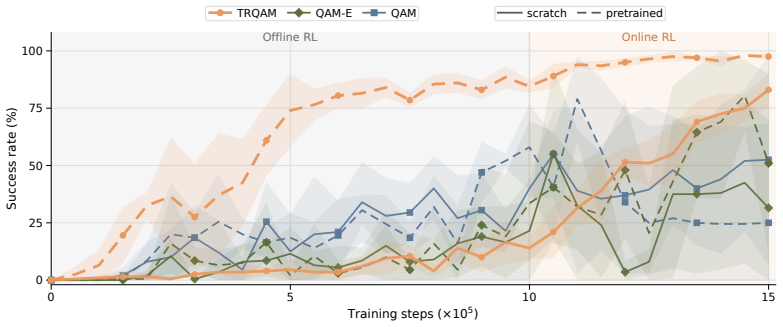
- The algorithm maintains stability across both offline RL and offline-to-online RL settings.
- On 50 OGBench tasks TRQAM reaches an overall success rate of 68 percent, exceeding the strongest baseline at 46 percent.
Where Pith is reading between the lines
- The same closed-form KL representation may let practitioners set explicit safety bounds on policy change during fine-tuning without extra regularization terms.
- Because the control acts directly on the path measure, the method could extend to other multi-step generative policies that currently suffer from critic-guided drift.
- If the closed-form relation holds under distribution shift, TRQAM might reduce the amount of online interaction needed to recover performance after offline pretraining.
Load-bearing premise
The path-space KL divergence can be expressed as a closed-form function of the trust-region parameter λ.
What would settle it
An experiment in which adjusting λ according to the closed-form expression still allows critic errors to produce policy collapse on held-out tasks would falsify the stability claim.
Figures

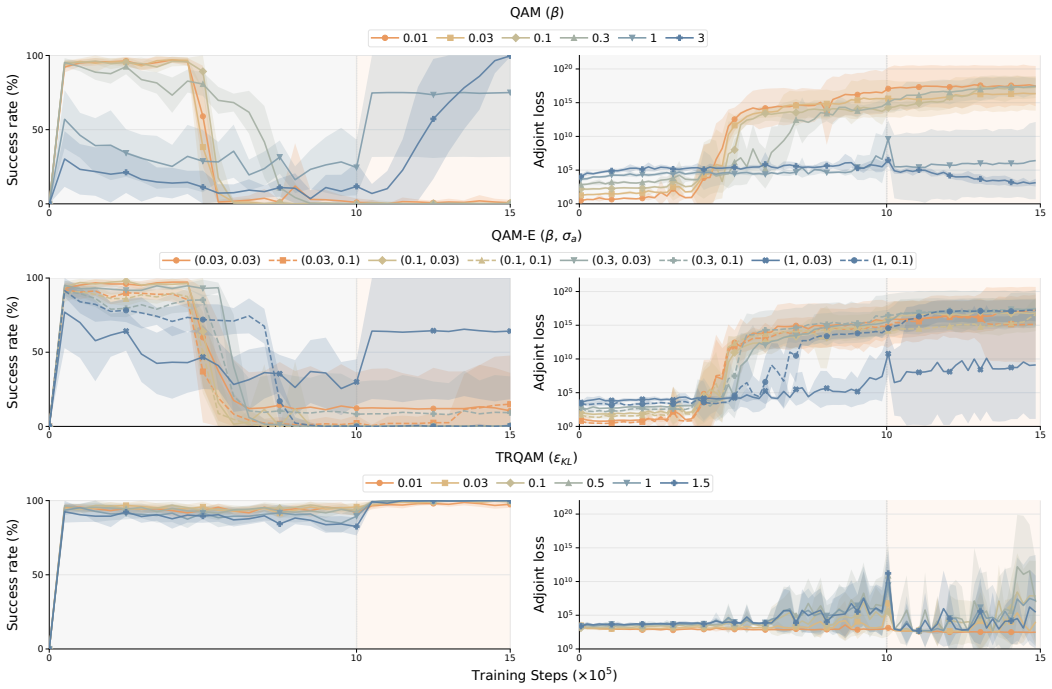
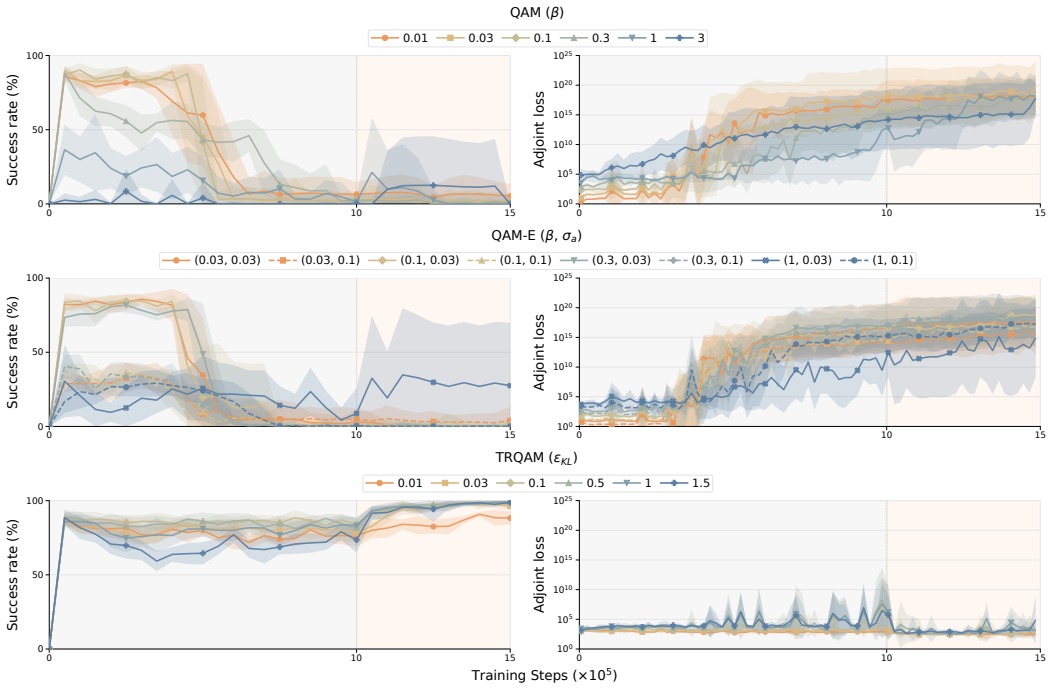
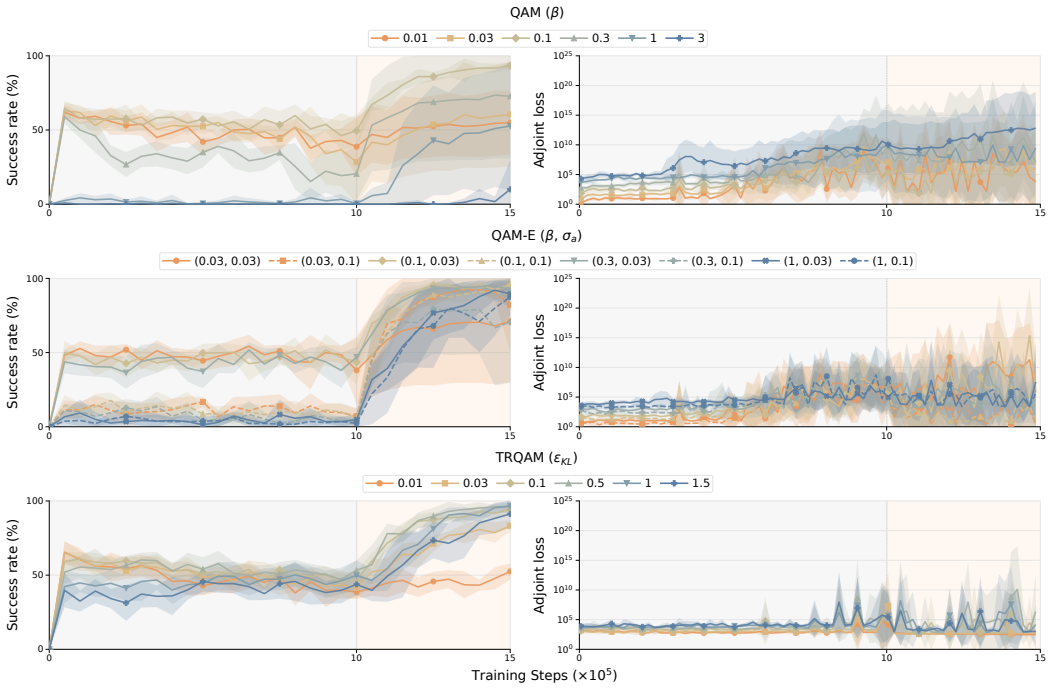
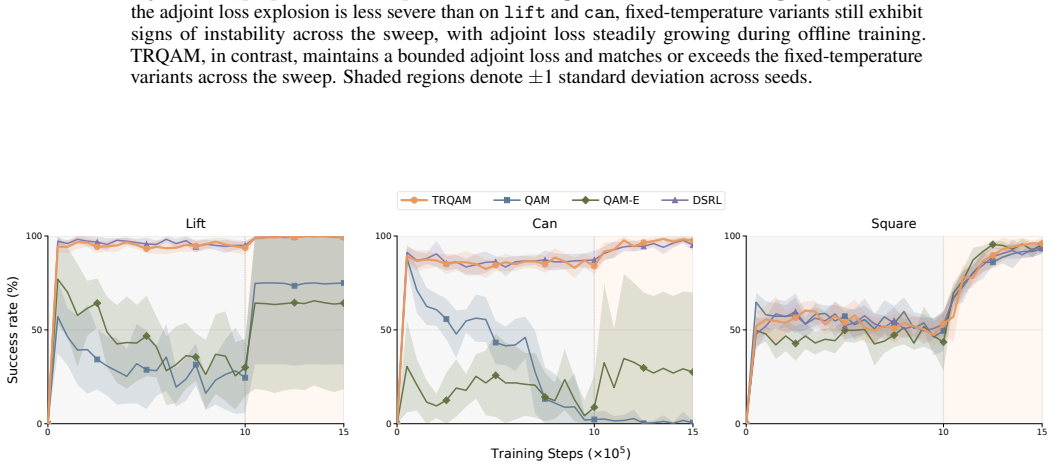
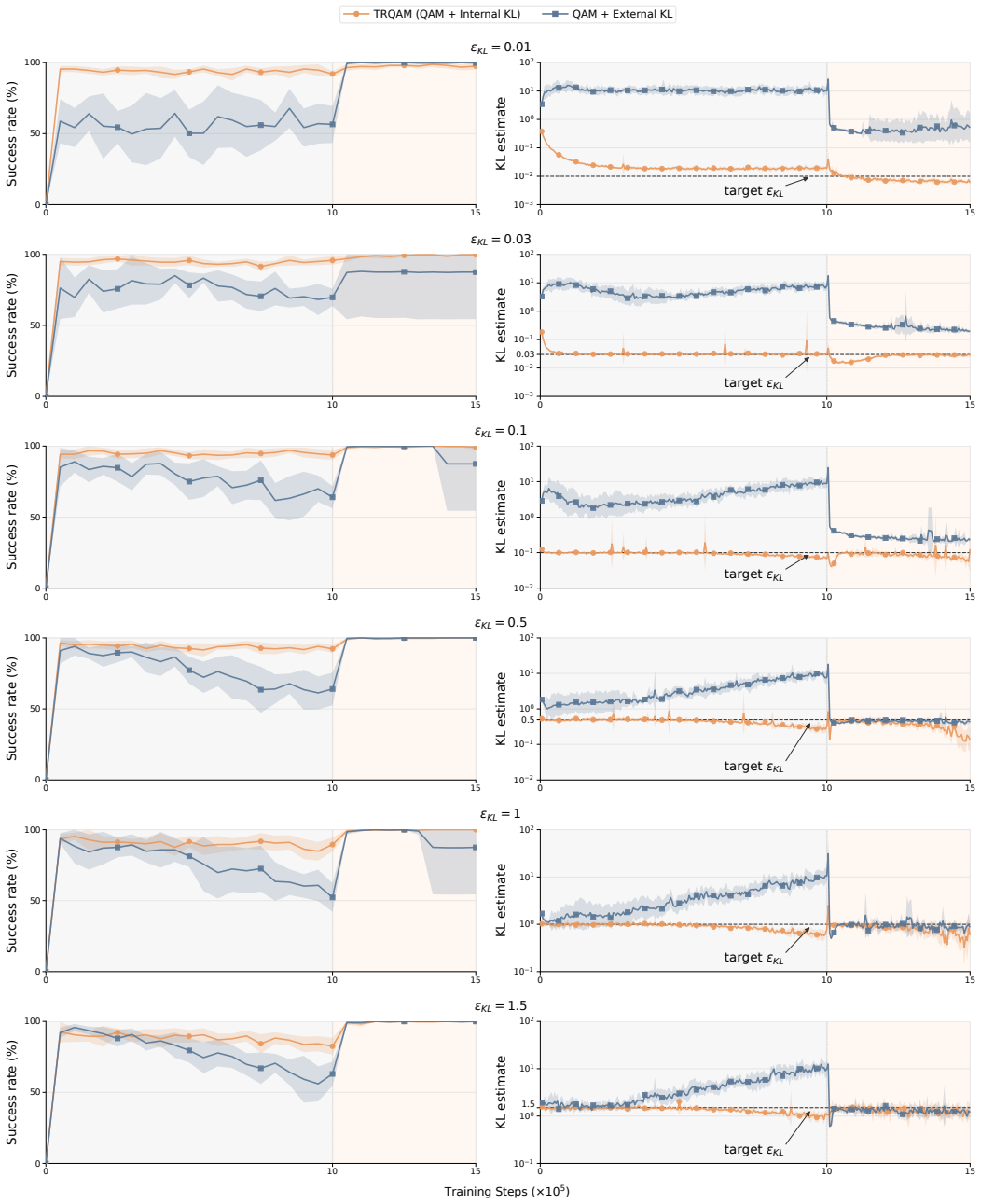
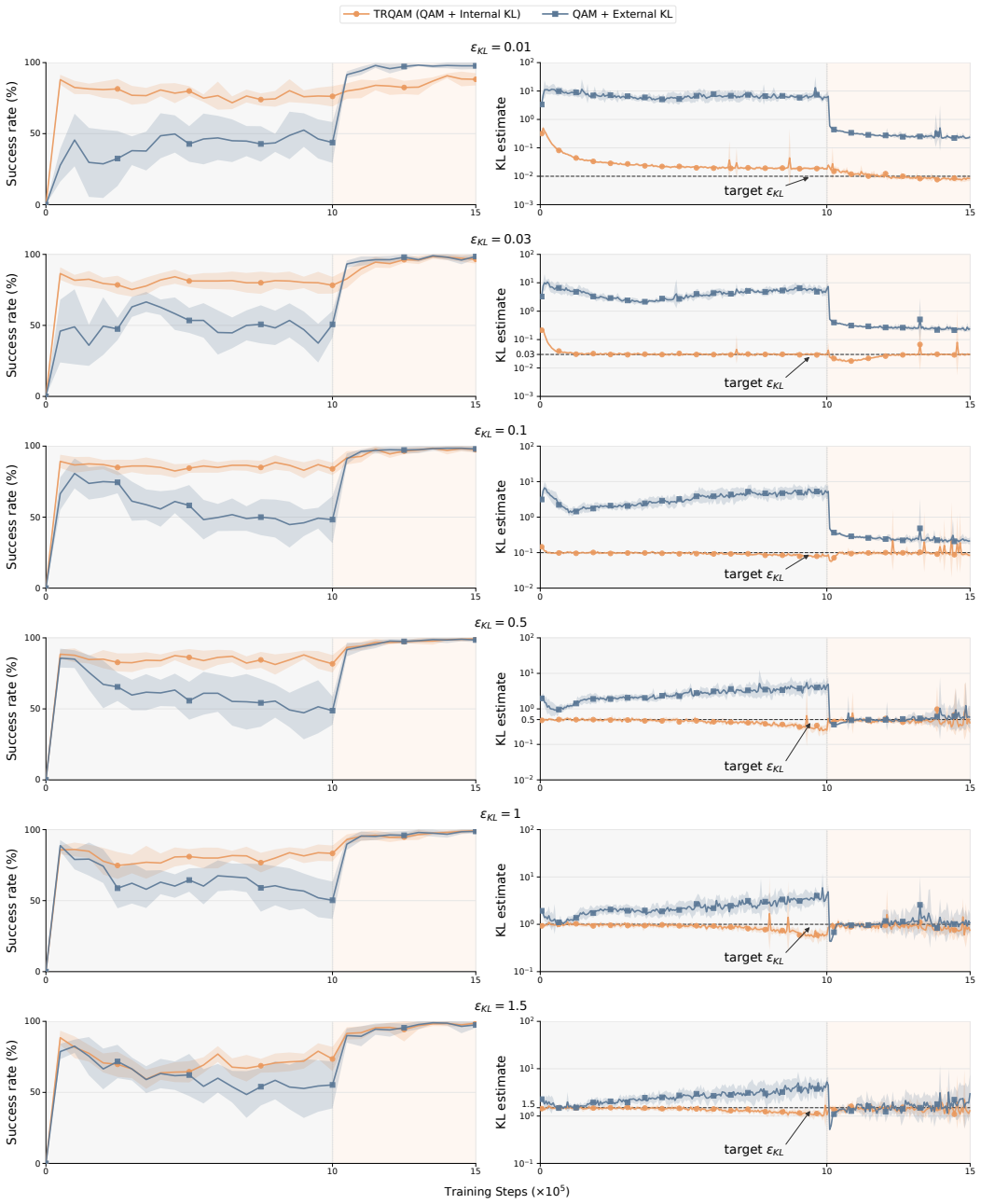
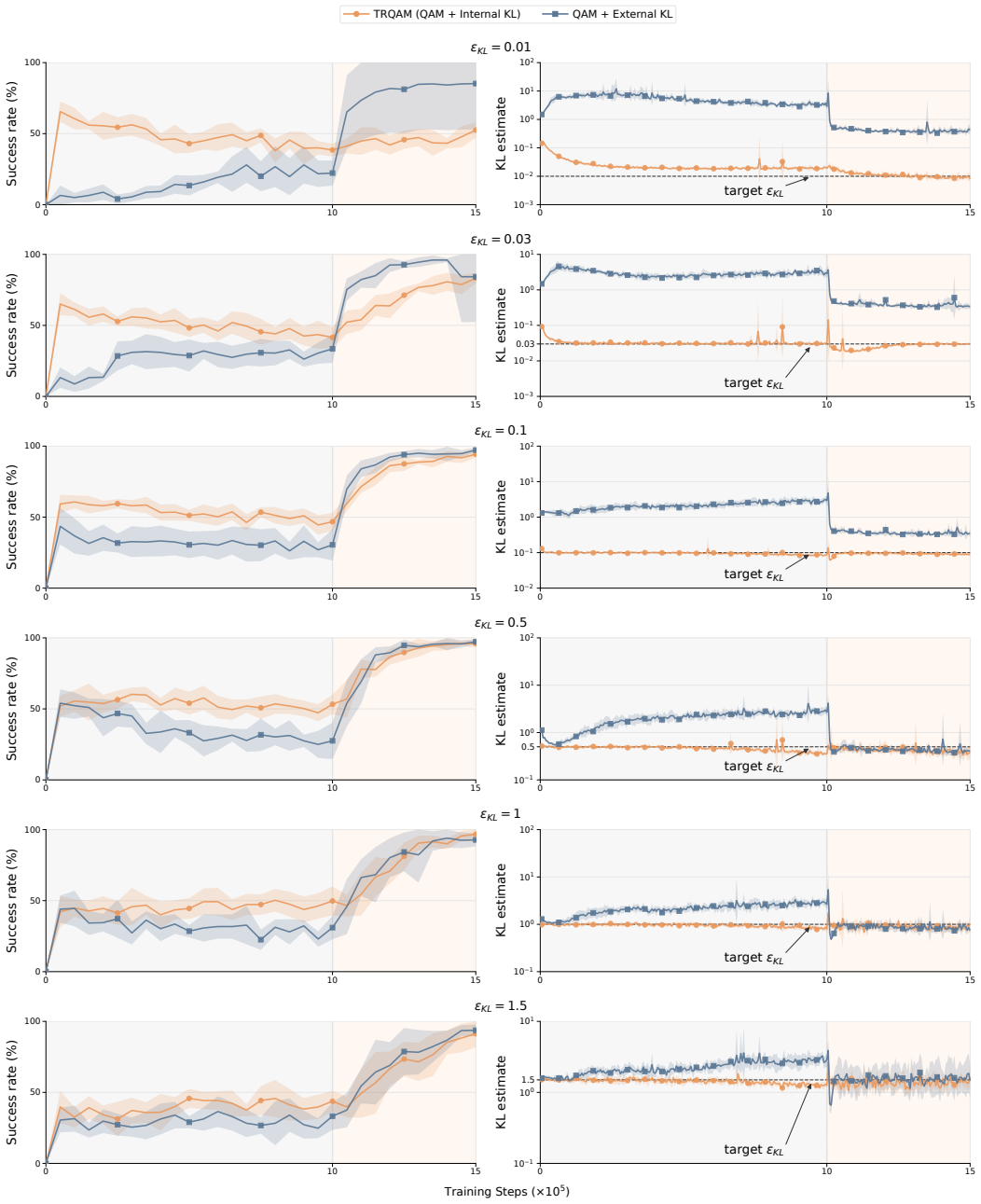
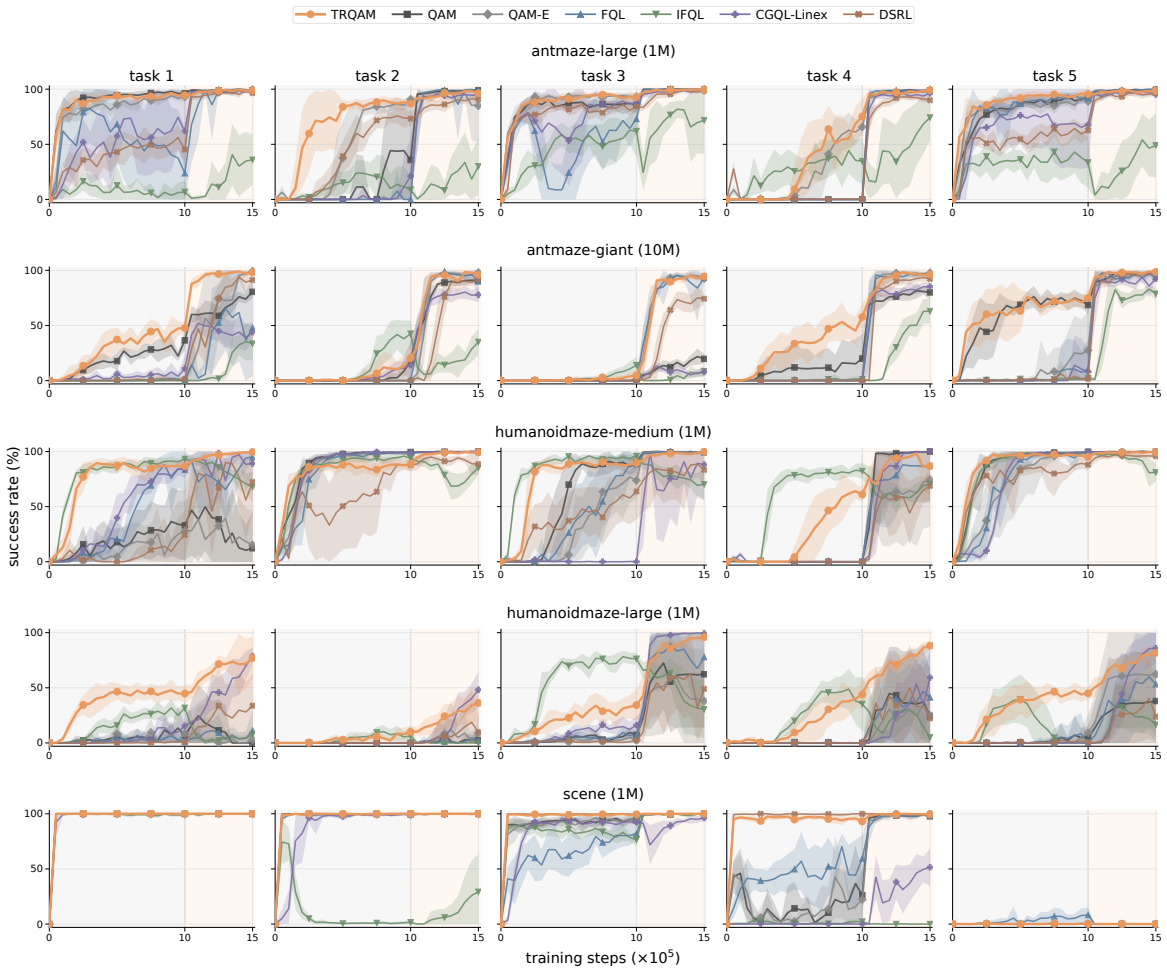
read the original abstract
Off-policy reinforcement learning of pretrained flow policies remains challenging due to the instability of optimization arising from the multi-step sampling process. Recently, Q-learning with Adjoint Matching (QAM) addressed this issue by reformulating into a memoryless stochastic optimal control (SOC) problem with a learned critic. However, QAM inherits a fundamental fragility of critic-guided improvement: small critic errors are amplified when critics are ill-conditioned, often leading to model collapse. This paper introduces Trust Region Q-Adjoint Matching (TRQAM), a stable off-policy fine-tuning algorithm that adaptively controls the path-space KL with pretrained flow policies through projected dual descent. Specifically, we optimize the trust-region parameter $\lambda$ in SOC dynamics, and theoretically show that the path-space KL can be represented by a closed-form function of $\lambda$. As a result, our method can precisely control the exact deviation from pretrained flow policies, achieving stable off-policy RL. Through experiments on 50 OGBench tasks, TRQAM consistently outperforms prior arts in both offline RL and offline-to-online RL. In particular, TRQAM achieves an overall success rate of 68% in offline RL, substantially improves the strongest baseline at 46%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Trust Region Q-Adjoint Matching (TRQAM) to stabilize off-policy fine-tuning of pretrained flow policies. Building on QAM's memoryless SOC reformulation with a learned critic, TRQAM applies projected dual descent to optimize the trust-region parameter λ and asserts that the path-space KL between fine-tuned and pretrained policies admits an exact closed-form expression in λ. This is claimed to enable precise deviation control without amplifying critic errors. Experiments across 50 OGBench tasks report an overall 68% success rate in offline RL, outperforming the strongest baseline at 46%, with similar gains in offline-to-online settings.
Significance. If the closed-form KL(λ) result is rigorously derived and the control mechanism demonstrably decouples from critic conditioning, the approach could provide a principled stabilization technique for critic-guided improvement of flow policies, addressing a known fragility in off-policy RL. The scale of the empirical evaluation (50 tasks) would be a strength if supported by proper statistical reporting.
major comments (3)
- [Abstract] Abstract (theoretical contribution paragraph): The central claim that 'the path-space KL can be represented by a closed-form function of λ' is asserted without any derivation steps, stated regularity conditions (e.g., Lipschitz continuity of the vector field or invertibility of the adjoint map), or explicit equations. This is load-bearing for the 'precise control' and 'stable off-policy RL' assertions and cannot be verified from the given text.
- [Abstract] Abstract (experimental results): The reported overall success rates (68% vs. 46%) are presented without error bars, number of independent runs, statistical significance tests, or details of the evaluation protocol (e.g., task splits, seed averaging, or success criteria). This undermines assessment of whether the performance improvement is reliable or reproducible.
- [Abstract] Abstract (SOC dynamics paragraph): The optimization of λ to control KL(λ) risks circularity because λ is simultaneously the trust-region parameter being optimized and the argument of the asserted closed-form KL; the manuscript must clarify how the closed-form expression is obtained independently of the jointly optimized critic to avoid the control being defined in terms of the fitted quantity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our manuscript. We address each major comment below, clarifying the theoretical derivation (present in the main text), experimental reporting, and independence of the KL expression. Revisions will be made to the abstract where feasible to improve clarity without exceeding length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract (theoretical contribution paragraph): The central claim that 'the path-space KL can be represented by a closed-form function of λ' is asserted without any derivation steps, stated regularity conditions (e.g., Lipschitz continuity of the vector field or invertibility of the adjoint map), or explicit equations. This is load-bearing for the 'precise control' and 'stable off-policy RL' assertions and cannot be verified from the given text.
Authors: The full derivation, including regularity conditions (Lipschitz continuity of the vector field under Assumption 2 and invertibility of the adjoint map in Lemma 1) and the explicit closed-form equation, appears in Section 3.2 and Theorem 1 of the manuscript. The abstract is necessarily concise, but we will revise it to include a parenthetical reference to the key equation and section number for easier verification. revision: partial
-
Referee: [Abstract] Abstract (experimental results): The reported overall success rates (68% vs. 46%) are presented without error bars, number of independent runs, statistical significance tests, or details of the evaluation protocol (e.g., task splits, seed averaging, or success criteria). This undermines assessment of whether the performance improvement is reliable or reproducible.
Authors: The full manuscript (Section 5) reports results averaged over 5 independent runs per task with standard deviation error bars, using OGBench's standard success criteria and seed averaging. We will revise the abstract to note 'averaged over 5 seeds' and direct readers to the experimental section for full statistical details and protocol. revision: yes
-
Referee: [Abstract] Abstract (SOC dynamics paragraph): The optimization of λ to control KL(λ) risks circularity because λ is simultaneously the trust-region parameter being optimized and the argument of the asserted closed-form KL; the manuscript must clarify how the closed-form expression is obtained independently of the jointly optimized critic to avoid the control being defined in terms of the fitted quantity.
Authors: The closed-form KL(λ) is derived analytically from the SOC dynamics and flow policy structure (via adjoint equations) before and independently of the critic; the critic affects only the policy parameter updates, not the KL expression itself. Theorem 1 explicitly shows this decoupling. We will add a clarifying clause in the abstract emphasizing that the KL control is obtained independently of the fitted critic. revision: yes
Circularity Check
Closed-form path-space KL(λ) asserted as theoretical result but used to define control of deviation
specific steps
-
self definitional
[abstract]
"we optimize the trust-region parameter λ in SOC dynamics, and theoretically show that the path-space KL can be represented by a closed-form function of λ. As a result, our method can precisely control the exact deviation from pretrained flow policies"
The method claims to achieve control over deviation by optimizing λ, yet simultaneously asserts that KL is exactly a closed-form function of that same λ; the 'precise control' therefore holds by the asserted functional dependence rather than by an independent derivation or external constraint.
full rationale
The abstract presents the core theoretical step as optimizing λ in SOC dynamics and showing path-space KL admits a closed-form in λ, enabling precise control. This structure makes the claimed 'precise control' reduce directly to the choice of λ by the asserted representation, matching the self-definitional pattern. No independent external benchmark or non-tautological derivation is quoted in the provided text. The result is not fully forced to a fit, but the load-bearing claim is internal to the parameterization, warranting a moderate circularity score. No other steps are identifiable without equations.
Axiom & Free-Parameter Ledger
free parameters (1)
- trust-region parameter λ
axioms (2)
- domain assumption Path-space KL divergence admits a closed-form representation as a function of the trust-region parameter λ in the SOC dynamics
- domain assumption Small critic errors are amplified when critics are ill-conditioned in QAM
Forward citations
Cited by 1 Pith paper
-
Q-VGM: Q-Guided Value-Gradient Matching for Flow-Matching VLA Policies
Q-VGM introduces value-gradient matching via VGG-Flow to improve flow-matching VLA policies with a Cal-QL critic, achieving success rate lifts on LIBERO, RoboTwin, and real-robot tasks.
Reference graph
Works this paper leans on
-
[1]
Abdolmaleki, J
A. Abdolmaleki, J. T. Springenberg, Y . Tassa, R. Munos, N. Heess, and M. Riedmiller. Maxi- mum a posteriori policy optimisation. InInternational Conference on Learning Representations, 2018
2018
-
[2]
M. S. Albergo, N. M. Boffi, and E. Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions. InJournal of Machine Learning Research, 2025
2025
-
[3]
P. J. Ball, L. Smith, I. Kostrikov, and S. Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, 2023
2023
-
[4]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Castañeda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots, 2025. URLhttps://arxiv.org/abs/2503.14734
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π0: A vision-language- action flow model for general robot control. InRobotics: Science and Sys...
2025
- [6]
-
[7]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems, 2023
2023
-
[8]
Dhariwal and A
P. Dhariwal and A. Nichol. Diffusion models beat gans on image synthesis. InAdvances in Neural Information Processing Systems, 2021
2021
-
[9]
Domingo-Enrich, J
C. Domingo-Enrich, J. Han, B. Amos, J. Bruna, and R. T. Q. Chen. Stochastic optimal control matching. InAdvances in Neural Information Processing Systems, 2024
2024
-
[10]
Domingo-Enrich, M
C. Domingo-Enrich, M. Drozdzal, B. Karrer, and R. T. Q. Chen. Adjoint matching: Fine- tuning flow and diffusion generative models with memoryless stochastic optimal control. In International Conference on Learning Representations, 2025
2025
-
[11]
P. Dong, Q. Li, D. Sadigh, and C. Finn. Expo: Stable reinforcement learning with expressive policies. InInternational Conference on Learning Representations, 2026
2026
-
[12]
Fujimoto, H
S. Fujimoto, H. van Hoof, and D. Meger. Addressing function approximation error in actor-critic methods. InInternational Conference on Machine Learning, 2018
2018
-
[13]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational Conference on Machine Learning, 2018
2018
-
[14]
Hansen-Estruch, I
P. Hansen-Estruch, I. Kostrikov, M. Janner, J. G. Kuba, and S. Levine. Idql: Implicit q-learning as an actor-critic method with diffusion policies, 2023. URLhttps://arxiv.org/abs/2304. 10573
2023
-
[15]
Hester, M
T. Hester, M. Vecerik, O. Pietquin, M. Lanctot, T. Schaul, B. Piot, D. Horgan, J. Quan, A. Sendonaris, G. Dulac-Arnold, I. Osband, J. Agapiou, J. Z. Leibo, and A. Gruslys. Deep q-learning from demonstrations. InAAAI Conference on Artificial Intelligence, 2018. 10
2018
-
[16]
H. Hu, S. Mirchandani, and D. Sadigh. Imitation bootstrapped reinforcement learning. In International Conference on Learning Representations, 2024
2024
- [17]
-
[18]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glossop, T. Godden, I. Goryachev, L. Groom, H. Hancock, K. Hausman, G. Hussein, B. Ichter, S. Jakubczak, R. Jen, T. Jones, B. Katz, L. Ke, C. Kuchi, M. Lamb, D. LeBlanc, S. Levin...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Intelligence, K
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
2025
-
[20]
Galaxea open-world dataset and g0 dual-system vla model.arXiv preprint arXiv:2509.00576, 2025
T. Jiang, T. Yuan, Y . Liu, C. Lu, J. Cui, X. Liu, S. Cheng, J. Gao, H. Xu, and H. Zhao. Galaxea open-world dataset and g0 dual-system vla model, 2025. URL https://arxiv.org/abs/ 2509.00576
-
[21]
C. Kim, H. Lee, Y . Seo, K. Lee, and Y . Zhu. Deas: Detached value learning with action sequence for scalable offline rl. InInternational Conference on Learning Representations, 2026
2026
-
[22]
Kostrikov, A
I. Kostrikov, A. Nair, and S. Levine. Offline reinforcement learning with implicit q-learning. In International Conference on Learning Representations, 2022
2022
-
[23]
Kumar, A
A. Kumar, A. Zhou, G. Tucker, and S. Levine. Conservative q-learning for offline reinforcement learning. InAdvances in Neural Information Processing Systems, 2020
2020
-
[24]
K. Lei, Z. He, C. Lu, K. Hu, Y . Gao, and H. Xu. Uni-o4: Unifying online and offline deep reinforcement learning with multi-step on-policy optimization. InInternational Conference on Learning Representations, 2024
2024
-
[25]
Li and S
Q. Li and S. Levine. Q-learning with adjoint matching. InInternational Conference on Learning Representations, 2026
2026
-
[26]
Q. Li, Z. Zhou, and S. Levine. Reinforcement learning with action chunking. InAdvances in Neural Information Processing Systems, 2025
2025
-
[27]
Lipman, R
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023
2023
-
[28]
J. Liu, G. Liu, J. Liang, Y . Li, J. Liu, X. Wang, P. Wan, D. Zhang, and W. Ouyang. Flow-grpo: Training flow matching models via online rl. InAdvances in Neural Information Processing Systems, 2025
2025
-
[29]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations, 2023
2023
-
[30]
J. Luo, Z. Hu, C. Xu, Y . L. Tan, J. Berg, A. Sharma, S. Schaal, C. Finn, A. Gupta, and S. Levine. Serl: A software suite for sample-efficient robotic reinforcement learning. InIEEE International Conference on Robotics and Automation, 2024
2024
-
[31]
N. Ma, M. Goldstein, M. S. Albergo, N. M. Boffi, E. Vanden-Eijnden, and S. Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InEuropean Conference on Computer Vision, 2024. 11
2024
-
[32]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning, 2021
2021
-
[33]
Myers, B
V . Myers, B. Zheng, B. Eysenbach, and S. Levine. Offline goal-conditioned reinforcement learning with quasimetric representations. InAdvances in Neural Information Processing Systems, 2025
2025
-
[34]
A. Nair, A. Gupta, M. Dalal, and S. Levine. Awac: Accelerating online reinforcement learning with offline datasets. InInternational Conference on Learning Representations, 2021
2021
-
[35]
Nakamoto, Y
M. Nakamoto, Y . Zhai, A. Singh, M. S. Mark, Y . Ma, C. Finn, A. Kumar, and S. Levine. Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[36]
Nüsken and L
N. Nüsken and L. Richter. Solving high-dimensional Hamilton–Jacobi–Bellman pdes using neural networks: perspectives from the theory of controlled diffusions and measures on path space.Partial differential equations and applications, 2:1–48, 2021
2021
-
[37]
Øksendal.Stochastic differential equations
B. Øksendal.Stochastic differential equations. Springer, 2003
2003
-
[38]
S. Park, K. Frans, B. Eysenbach, and S. Levine. Ogbench: Benchmarking offline goal- conditioned rl. InInternational Conference on Learning Representations, 2025
2025
-
[39]
S. Park, Q. Li, and S. Levine. Flow q-learning. InInternational Conference on Machine Learning, 2025
2025
-
[40]
Parsian and S
A. Parsian and S. Kirmani. Estimation under linex loss function. InHandbook of applied econometrics and statistical inference, pages 75–98. CRC Press, 2002
2002
-
[41]
X. B. Peng, A. Kumar, G. Zhang, and S. Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. InInternational Conference on Learning Representations, 2021
2021
-
[42]
Polyanskiy and Y
Y . Polyanskiy and Y . Wu.Information Theory: From Coding to Learning. Cambridge University Press, 2025
2025
-
[43]
Rajeswaran, V
A. Rajeswaran, V . Kumar, A. Gupta, G. Vezzani, J. Schulman, E. Todorov, and S. Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. InRobotics: Science and Systems, 2018
2018
-
[44]
A. Z. Ren, J. Lidard, L. L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz. Diffusion policy policy optimization. InInternational Conference on Learning Representations, 2025
2025
-
[45]
Reuss, H
M. Reuss, H. Zhou, M. Rühle, Ö. E. Ya˘gmurlu, F. Otto, and R. Lioutikov. FLOWER: Democra- tizing generalist robot policies with efficient vision-language-flow models. InConference on Robot Learning, 2025
2025
-
[46]
Schulman, S
J. Schulman, S. Levine, P. Moritz, M. I. Jordan, and P. Abbeel. Trust region policy optimization. InInternational Conference on Machine Learning, 2015
2015
-
[47]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms, 2017. URLhttps://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, S. Alibert, M. Cord, T. Wolf, and R. Cadene. Smolvla: A vision-language-action model for affordable and efficient robotics, 2025. URL https: //arxiv.org/abs/2506.01844
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
R. S. Sutton and A. G. Barto.Reinforcement learning: An introduction. MIT press, 2018
2018
-
[50]
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
M. Vecerik, T. Hester, J. Scholz, F. Wang, O. Pietquin, B. Piot, N. Heess, T. Rothörl, T. Lampe, and M. Riedmiller. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards, 2018. URLhttps://arxiv.org/abs/1707.08817. 12
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[51]
Wagenmaker, M
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning. In Conference on Robot Learning, 2025
2025
-
[52]
Z. Wang, J. J. Hunt, and M. Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. InInternational Conference on Learning Representations, 2023
2023
-
[53]
Wołczyk, B
M. Wołczyk, B. Cupiał, M. Ostaszewski, M. Bortkiewicz, M. Zaj ˛ ac, R. Pascanu, Ł. Kuci´nski, and P. Miło´s. Fine-tuning reinforcement learning models is secretly a forgetting mitigation problem. InInternational Conference on Machine Learning, 2024
2024
-
[54]
Y . Wu, G. Tucker, and O. Nachum. Behavior regularized offline reinforcement learning. In International Conference on Learning Representations, 2020
2020
-
[55]
W. Xiao, H. Lin, A. Peng, H. Xue, T. He, Y . Xie, F. Hu, J. Wu, Z. Luo, L. J. Fan, G. Shi, and Y . Zhu. Self-improving vision-language-action models with data generation via residual rl. In International Conference on Learning Representations, 2026
2026
-
[56]
C. Xu, J. T. Springenberg, M. Equi, A. Amin, A. Esmail, S. Levine, and L. Ke. Rl token: Bootstrapping online rl with vision-language-action models, 2026. URL https://arxiv. org/abs/2604.23073
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [57]
-
[58]
Zhang, C
T. Zhang, C. Yu, S. Su, and Y . Wang. Reinflow: Fine-tuning flow matching policy with online reinforcement learning. InAdvances in Neural Information Processing Systems, 2025
2025
-
[59]
Zhang, S
Y . Zhang, S. Yu, T. Zhang, M. Guang, H. Hui, K. Long, Y . Wang, C. Yu, and W. Ding. Sac flow: Sample-efficient reinforcement learning of flow-based policies via velocity-reparameterized sequential modeling. InInternational Conference on Learning Representations, 2026
2026
-
[60]
worse”, two “okay
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, T. Wang, Y .-Q. Zhang, J. Liu, and X. Zhan. X-VLA: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. InInternational Conference on Learning Representations, 2026. 13 Contents A Algorithm 15 B Baselines 15 C Experimental details 17 ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.