FineVLA: Fine-Grained Instruction Alignment for Steerable Vision-Language-Action Policies
Pith reviewed 2026-06-29 17:16 UTC · model grok-4.3
The pith
Fine-grained language instructions improve how precisely robot policies follow execution details without lowering overall task success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fine-grained supervision does not sacrifice goal-level success and improves steerable control. FG-only improves over Raw-only by 1.4 to 8.1 success-rate points. Fine-grained and raw instructions are complementary, following a consistent inverted-U trend that peaks at FG:Raw ratios of 1:2 to 1:1. The best mixed setting reaches 86.8 percent and 82.5 percent in RoboTwin simulation and 62.7 out of 100 in real-world dual-arm manipulation, compared with 49.9 for raw-only. The largest real-world gains occur on pose, color, and approach direction.
What carries the argument
A steerable VLA policy trained with controlled mixtures of fine-grained and raw goal-level instructions.
If this is right
- Fine-grained only training improves goal success over raw-only training across multiple settings.
- The complementarity peaks at roughly equal or slightly more raw instructions than fine-grained ones.
- Steerability gains concentrate on attributes such as pose, color, and approach direction that goal-level language leaves unspecified.
- The same mixed-training pattern produces measurable lifts in both simulation and real dual-arm manipulation.
Where Pith is reading between the lines
- If the complementarity pattern holds beyond the tested datasets, then scaling the proportion of fine-grained labels in new collections could further raise both success and controllability.
- The held-out benchmark of atomic facts and VQA questions could be reused to audit whether other VLA models also benefit from explicit execution details.
- Policies trained under this mixture may transfer more readily to instructions that combine high-level goals with low-level constraints not seen in training.
Load-bearing premise
The human-verified fine-grained annotations and the robotics-specialized VLM annotator accurately capture execution-critical details such as active arm, approach direction, and contact region.
What would settle it
Train two otherwise identical policies, one on raw goal instructions alone and one on the mixed fine-grained set, then measure success rates on a held-out set of tasks that explicitly require a particular approach direction or arm choice; equal performance on those tasks would falsify the steerability claim.
Figures




read the original abstract
Vision-Language-Action (VLA) models are increasingly expected to not only complete robot tasks, but also follow human instructions about how those tasks should be executed. However, existing robot datasets usually pair trajectories with coarse goal-level language, leaving execution-critical details such as active arm, approach direction, and contact region unspecified. This limits steerable policy learning and robotic video understanding. We introduce FineVLA, an open framework for action-aligned fine-grained VLA supervision. The framework includes: (1) a data construction tool that unifies 972,247 trajectories across 85K tasks from 10 open-source robot datasets and builds FineVLA-Data, a human-verified dataset of 47,159 fine-grained trajectories; (2) a held-out benchmark with 500 videos, 10,816 atomic facts, and 1,030 VQA questions; (3) a robotics-specialized VLM annotator for scalable fine-grained annotation; and (4) a steerable VLA policy trained with controlled mixtures of fine-grained and raw goal-level instructions. Our experiments yield three findings. First, fine-grained supervision does not sacrifice goal-level success: FG-only improves over Raw-only by +1.4 to +8.1 success-rate points across settings. Second, fine-grained and raw instructions are complementary, following a consistent inverted-U trend peaking at FG:Raw = 1:2 to 1:1. The best mixed setting reaches 86.8%/82.5% in RoboTwin simulation and 62.7/100 in real-world dual-arm manipulation (vs. 49.9 Raw-only). Third, fine-grained supervision improves steerable control: the largest real-world gains appear on pose (+23), color (+18), and approach direction (+18)--factors where goal-level instructions provide no guidance. Overall, fine-grained language should augment goal-level instructions: specifying how to execute alongside what to achieve. Project page: https://finevla.xlang.ai/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FineVLA, a framework for fine-grained instruction alignment in Vision-Language-Action (VLA) policies. It unifies 972,247 trajectories from 10 open-source datasets into FineVLA-Data (47,159 human-verified fine-grained trajectories), provides a held-out benchmark (500 videos, 10,816 atomic facts, 1,030 VQA questions), deploys a robotics-specialized VLM annotator, and trains policies on controlled FG:Raw instruction mixtures. Experiments report that fine-grained supervision improves steerability on execution factors (pose +23, color +18, approach direction +18) without harming goal-level success, with peak performance at FG:Raw ratios of 1:2 to 1:1 (e.g., 86.8%/82.5% RoboTwin, 62.7/100 real-world dual-arm vs. 49.9 Raw-only).
Significance. If the empirical claims hold, the work supplies a scalable path to augment coarse goal-level robot datasets with execution-critical details, directly addressing a documented limitation in VLA training. The consistent inverted-U mixture trend and factor-specific gains on held-out simulation and real-world trials constitute a concrete, falsifiable contribution to steerable policy learning.
major comments (3)
- [Experiments] Experiments section (results on RoboTwin and real-world dual-arm): success rates are reported as point estimates (86.8%, 82.5%, 62.7/100) with no error bars, standard deviations across seeds, or statistical significance tests. This undermines assessment of whether the reported gains over Raw-only (e.g., +12.8 on real-world) are reliable, especially given the central claim that FG supervision improves steerability without sacrificing goal success.
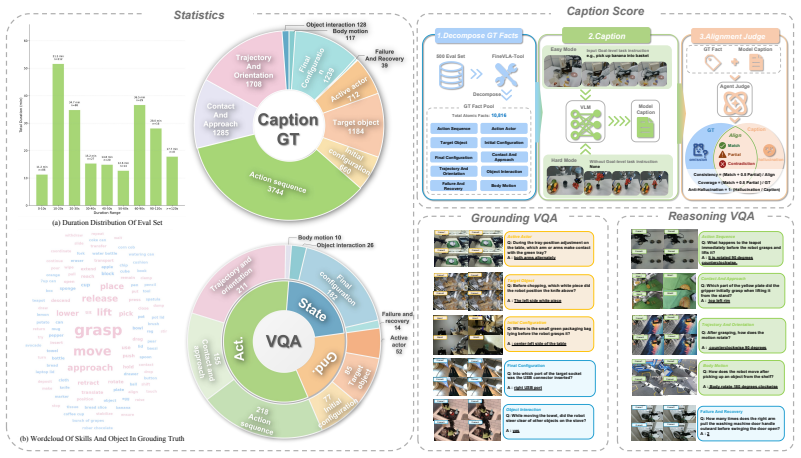
- [Data Construction] Data construction and VLM annotator (FineVLA-Data and benchmark): the manuscript states that the robotics-specialized VLM annotator produces scalable fine-grained labels verified by humans, yet provides no quantitative accuracy metrics, inter-annotator agreement, or ablation on annotator error rates for the 10,816 atomic facts. Because the weakest assumption is precisely the fidelity of these execution-critical details (active arm, contact region, approach direction), this detail is load-bearing for the data-quality premise.
- [Benchmark] Benchmark construction (held-out 500-video set): the paper does not describe the sampling procedure, task distribution, or how the 1,030 VQA questions were generated and balanced across the 10,816 facts. Without this, it is impossible to evaluate whether the steerability gains generalize beyond the specific factors highlighted or whether the benchmark inadvertently favors the FG annotations.
minor comments (1)
- [Abstract / Experiments] The abstract and results tables would benefit from explicit statement of the number of evaluation episodes per condition and whether the same policy seeds were used across mixture ratios.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section (results on RoboTwin and real-world dual-arm): success rates are reported as point estimates (86.8%, 82.5%, 62.7/100) with no error bars, standard deviations across seeds, or statistical significance tests. This undermines assessment of whether the reported gains over Raw-only (e.g., +12.8 on real-world) are reliable, especially given the central claim that FG supervision improves steerability without sacrificing goal success.
Authors: We agree that reporting only point estimates limits evaluation of reliability. In the revised manuscript we will add standard deviations across multiple random seeds for all reported success rates and include statistical significance tests (e.g., paired t-tests) comparing FG-mixed conditions against the Raw-only baseline. These additions will appear in the Experiments section and associated tables. revision: yes
-
Referee: [Data Construction] Data construction and VLM annotator (FineVLA-Data and benchmark): the manuscript states that the robotics-specialized VLM annotator produces scalable fine-grained labels verified by humans, yet provides no quantitative accuracy metrics, inter-annotator agreement, or ablation on annotator error rates for the 10,816 atomic facts. Because the weakest assumption is precisely the fidelity of these execution-critical details (active arm, contact region, approach direction), this detail is load-bearing for the data-quality premise.
Authors: The concern about missing quantitative validation of the annotator is valid. Although the 47,159 trajectories were human-verified, the original submission omitted inter-annotator agreement and accuracy metrics. We will add these in revision by reporting agreement on a sampled subset of atomic facts and any available error-rate ablations; if full retrospective computation is infeasible we will instead detail the exact human verification protocol used. revision: yes
-
Referee: [Benchmark] Benchmark construction (held-out 500-video set): the paper does not describe the sampling procedure, task distribution, or how the 1,030 VQA questions were generated and balanced across the 10,816 facts. Without this, it is impossible to evaluate whether the steerability gains generalize beyond the specific factors highlighted or whether the benchmark inadvertently favors the FG annotations.
Authors: We agree that the benchmark construction details are insufficient. In the revised manuscript we will expand the relevant section to specify the sampling procedure for the 500-video held-out set, the task distribution across source datasets, and the generation and balancing process for the 1,030 VQA questions relative to the 10,816 atomic facts. This will improve transparency and allow readers to assess potential biases. revision: yes
Circularity Check
No significant circularity; empirical results on held-out data
full rationale
The paper presents an empirical framework for constructing FineVLA-Data from existing trajectories, training VLA policies on instruction mixtures, and evaluating on a held-out benchmark (500 videos, 10,816 facts, 1,030 VQA questions) plus real-world trials. All reported gains (e.g., +1.4 to +8.1 success rate, inverted-U trend peaking at FG:Raw = 1:2 to 1:1, factor-specific improvements on pose/color/direction) are measured outcomes on separate test sets rather than quantities defined in terms of fitted parameters or self-referential equations. No derivation chain reduces a claimed result to its own inputs by construction; the central claims rest on controlled experiments and external verification steps.
Axiom & Free-Parameter Ledger
free parameters (1)
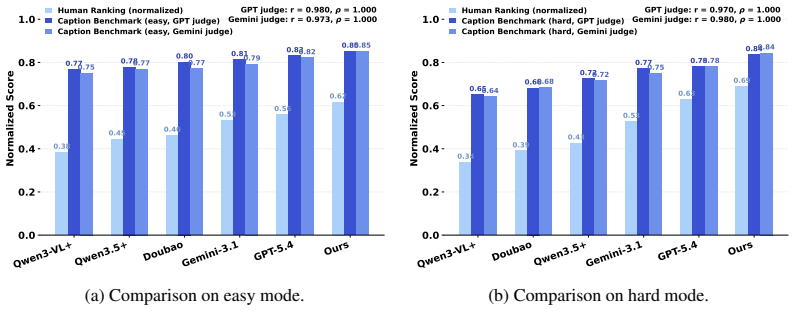
- FG:Raw mixture ratio
axioms (2)
- domain assumption Human verification of the 47,159 trajectories produces accurate execution-critical labels
- domain assumption The robotics-specialized VLM annotator produces labels of sufficient quality to support policy training at scale
Reference graph
Works this paper leans on
-
[1]
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, Vedant Choudhary, Foster Collins, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Maitrayee Dhaka, Jared DiCarlo, Danny Driess, Michael Equi, Adnan Esmail, Yunhao Fang, Chelsea Finn, Catherine...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
A Pragmatic VLA Foundation Model
Wei Wu, Fan Lu, Yunnan Wang, Shuai Yang, Shi Liu, Fangjing Wang, Qian Zhu, He Sun, Yong Wang, Shuailei Ma, Yiyu Ren, Kejia Zhang, Hui Yu, Jingmei Zhao, Shuai Zhou, Zhenqi Qiu, Houlong Xiong, Ziyu Wang, Zechen Wang, Ran Cheng, Yong-Lu Li, Yongtao Huang, Xing Zhu, Yujun Shen, and Kecheng Zheng. A pragmatic vla foundation model, 2026. URL https://arxiv.org/a...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Nvidia isaac gr00t
NVIDIA. Nvidia isaac gr00t. https://github.com/NVIDIA/Isaac-GR00T, 2026. GitHub repository, accessed April 13, 2026
2026
-
[4]
Generalist AI. Gen-1. https://generalistai.com/blog/apr-02-2026-GEN-1 , 2026. Blog post, accessed April 2, 2026
2026
-
[5]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration. Open X-Embodiment: Robotic learning datasets and RT-X models, 2023. URLhttps://arxiv.org/abs/2310.08864
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation, 2025. URLhttps://arxiv.org/abs/2410.07864
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, Debidatta Dwibedi, Keerthana Gopalakrish- nan, Christine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J. Joshi, Pete Florence, Wei Han, Robert Baruch, Yao Lu, Suvir Mirchandani, Peng Xu, Pannag Sanketi, Karol Hausman, Izhak Shafran, Brian Ichter, and Yuan Cao. RoboVQA: Multimodal long-horizon r...
-
[8]
Robobench: A comprehensive evaluation benchmark for multimodal large language models as embodied brain, 2025
Yulin Luo, Chun-Kai Fan, Menghang Dong, Jiayu Shi, Mengdi Zhao, Bo-Wen Zhang, Cheng Chi, Jiaming Liu, Gaole Dai, Rongyu Zhang, Ruichuan An, Kun Wu, Zhengping Che, Shaoxuan Xie, Guocai Yao, Zhongxia Zhao, Pengwei Wang, Guang Liu, Zhongyuan Wang, Tiejun Huang, and Shanghang Zhang. Robobench: A comprehensive evaluation benchmark for multimodal large language...
2025
-
[9]
HanDyVQA: A video QA benchmark for fine-grained hand-object interaction dynamics, 2025
Masatoshi Tateno, Gido Kato, Hirokatsu Kataoka, Yoichi Sato, and Takuma Yagi. HanDyVQA: A video QA benchmark for fine-grained hand-object interaction dynamics, 2025. URL https: //arxiv.org/abs/2512.00885
-
[10]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5
2026
-
[11]
BridgeData V2: A dataset for robot learning at scale
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, et al. BridgeData V2: A dataset for robot learning at scale. InProceedings of the Conference on Robot Learning, 2023. URL https://arxiv.org/abs/2308.12952. 14
-
[12]
Bc-z: Zero-shot task generalization with robotic imitation learning,
Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, Sergey Levine, and Chelsea Finn. Bc-z: Zero-shot task generalization with robotic imitation learning,
- [13]
-
[14]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Yevgen Chebotar, Chelsea Finn, Karol Hausman, Alexander Herzog, Daniel Ho, Julian Ibarz, Alex Irpan, Eric Jang, Ryan Julian, et al. RT-1: Robotics transformer for real-world control at scale, 2022. URLhttps://arxiv.org/abs/2212.06817
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [15]
-
[16]
RoboMIND: Benchmark on multi-embodiment intelligence normative data for robot manipulation
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Yang, Meng Li, Yinuo Zhao, Zhiyuan Xu, Guang Yang, Shichao Fan, Xinhua Wang, Fei Liao, Zhen Zhao, Guangyu Li, Zhao Jin, Lecheng Wang, Jilei Mao, Ning Liu, Pei Ren, Qiang Zhang, Yaoxu Lyu, Mengzhen Liu, He Jingyang, Yulin Luo, Zeyu Gao, Chenxuan Li, Chenyang Gu, Yankai Fu, Di Wu, Xingyu W...
-
[17]
Chengkai Hou, Kun Wu, Jiaming Liu, Zhengping Che, et al. RoboMIND 2.0: A multimodal, bimanual mobile manipulation dataset for generalizable embodied intelligence, 2025. URL https://arxiv.org/abs/2512.24653
-
[18]
RoboCOIN: An Open-Sourced Bimanual Robotic Data Collection for Integrated Manipulation
Shihan Wu, Xuecheng Liu, Shaoxuan Xie, Pengwei Wang, et al. RoboCOIN: An open- sourced bimanual robotic data collection for integrated manipulation, 2025. URL https: //arxiv.org/abs/2511.17441
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot,
Hao-Shu Fang, Hongjie Fang, Zhenyu Tang, Jirong Liu, Chenxi Wang, Junbo Wang, Haoyi Zhu, and Cewu Lu. Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot,
- [20]
-
[21]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. DROID: A large-scale in-the-wild robot manipulation dataset, 2024. URL https: //arxiv.org/abs/2403.12945
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing
StarVLA Community. Starvla: A lego-like codebase for vision-language-action model develop- ing, 2026. URLhttps://arxiv.org/abs/2604.05014
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
RoboTwin: Dual-arm robot benchmark with generative digital twins, 2024
Yao Mu, Tianxing Chen, Shijia Peng, Zanxin Chen, Zeyu Gao, Yude Zou, Lunkai Lin, Zhiqiang Xie, and Ping Luo. RoboTwin: Dual-arm robot benchmark with generative digital twins, 2024. URLhttps://arxiv.org/abs/2409.02920
-
[24]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control, 2023. URL https://arxiv.org/abs/2307.15818
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. OpenVLA: An open-source vision-language-action model, 2024. URLhttps://arxiv.org/abs/2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control, 2024. URLhttps://arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy, 2024. URL https://arxiv.org/abs/2405.12213. 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
RoboInter: A holistic intermediate representation suite towards robotic manipulation, 2026
Hao Li, Ziqin Wang, Zi-han Ding, Shuai Yang, et al. RoboInter: A holistic intermediate representation suite towards robotic manipulation, 2026. URL https://arxiv.org/abs/ 2602.09973
-
[29]
STEER: Flexible robotic manipulation via dense language ground- ing, 2024
Laura Smith, Alex Irpan, Montserrat Gonzalez Arenas, Sean Kirmani, Dmitry Kalashnikov, Dhruv Shah, and Ted Xiao. STEER: Flexible robotic manipulation via dense language ground- ing, 2024. URLhttps://arxiv.org/abs/2411.03409
-
[30]
PartInstruct: Part-level instruction following for fine- grained robot manipulation, 2025
Yifan Yin, Zhengtao Han, Shivam Aarya, Jianxin Wang, Shuhang Xu, Jiawei Peng, Angtian Wang, Alan Yuille, and Tianmin Shu. PartInstruct: Part-level instruction following for fine- grained robot manipulation, 2025. URLhttps://arxiv.org/abs/2505.21652
-
[31]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Qwen3.5-Omni technical report, 2026
Qwen Team. Qwen3.5-Omni technical report, 2026. URL https://arxiv.org/abs/2604. 15804
2026
-
[33]
Wolf: Dense video captioning with a world summarization framework, 2025
Boyi Li, Ligeng Zhu, Ran Tian, Shuhan Tan, Yuxiao Chen, Yao Lu, Yin Cui, Sushant Veer, Max Ehrlich, Jonah Philion, Xinshuo Weng, Fuzhao Xue, Linxi Fan, Yuke Zhu, Jan Kautz, Andrew Tao, Ming-Yu Liu, Sanja Fidler, Boris Ivanovic, Trevor Darrell, Jitendra Malik, Song Han, and Marco Pavone. Wolf: Dense video captioning with a world summarization framework, 20...
-
[34]
Robotic skill acquisition via instruction augmentation with vision-language models
Ted Xiao, Harris Chan, Pierre Sermanet, Ayzaan Wahid, Anthony Brohan, Karol Hausman, Sergey Levine, and Jonathan Tompson. Robotic skill acquisition via instruction augmentation with vision-language models. InRobotics: Science and Systems, 2023. URL https://arxiv. org/abs/2211.11736
-
[35]
RoboAnnotatorX: A comprehensive and universal annotation framework for accurate understanding of long-horizon robot demonstration
Longxin Kou, Fei Ni, Yan Zheng, Peilong Han, Jinyi Liu, Haiqin Cui, Rui Liu, and Jianye Hao. RoboAnnotatorX: A comprehensive and universal annotation framework for accurate understanding of long-horizon robot demonstration. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10353–10363,
-
[36]
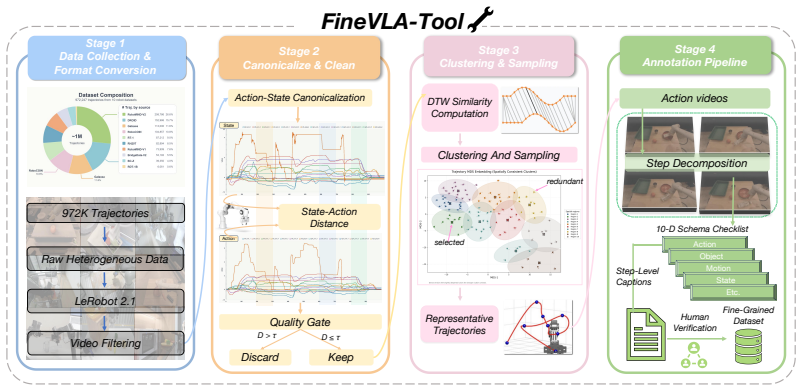
16 A Appendix Contents A.1 FineVLA-Tool Details
URL https://openaccess.thecvf.com/content/ICCV2025/html/Kou_ RoboAnnotatorX_A_Comprehensive_and_Universal_Annotation_Framework_for_ Accurate_Understanding_ICCV_2025_paper.html. 16 A Appendix Contents A.1 FineVLA-Tool Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 A.1.1 Data Sources and Format Conversion . . . . . . . . . . . . ...
-
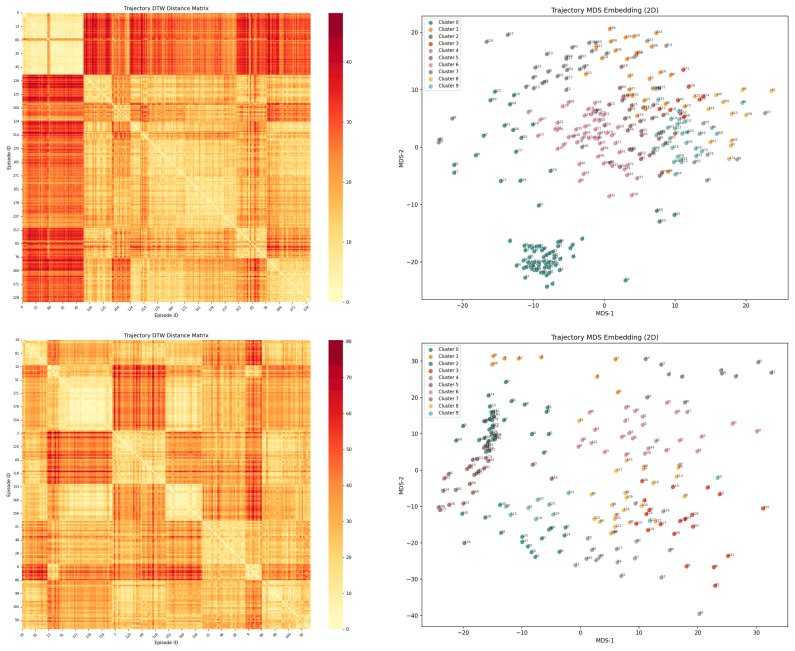
[37]
Canonicalization.All trajectories within a task are converted to their canonical action rep- resentation (joint-space or EEF-space with quaternion rotations) following the procedure in Appendix A.1.2
-
[38]
Pairwise DTW distance computation.For each pair of trajectories within a task, we compute the DTW distance using a representation-specific frame cost function (defined below)
-
[39]
Hierarchical clustering.Agglomerative clustering with average linkage is applied to the pairwise distance matrix, and the number of clusters is determined automatically via the largest relative gap in merge heights
-
[40]
Step1":
Representative selection.Two to three high-quality trajectories are selected from each cluster based on proximity to the cluster medoid and trajectory quality metrics (video integrity, action smoothness). DTW formulation.Open robot datasets are highly redundant: many demonstrations differ only in speed, minor spatial offsets, or camera viewpoint, while ex...
-
[41]
action_primitive –- fundamental action type (grasp, push, rotate, etc.)
-
[42]
actor_identity –- which arm/hand/gripper performs the action
-
[43]
object_recognition –- object category, color, material, shape, size
-
[44]
object_disambiguation –- distinguishing similar objects via spatial/attribute cues
-
[45]
contact_region –- specific part where gripper contacts the object
-
[46]
source_state_or_location –- initial state/position before manipulation
-
[47]
trajectory_and_orientation –- direction, path, or rotation during motion
-
[48]
placement_specification –- final target location or spatial relation
-
[49]
interaction_with_other_objects –- contact/disturbance of non-target objects
-
[50]
success_failure_retry –- whether the action succeeds, fails, or retries
-
[51]
gripper_state –- open/close/release state at a specific moment
-
[52]
temporal_order_and_step_boundary –- ordering of steps and boundaries
-
[53]
all/none of the above
body_motion –- robot base/torso/camera movement Dimension Balancing: For Mode B, randomly select dimensions per sample. Do NOT ask two questions on the same dimension within one sample. Across the batch, aim for roughly equal coverage. Answer Types: –- multiple_choice: 4–8 mutually exclusive options, no “all/none of the above” –- yes_no: answer exactly “y...
-
[54]
Pre-extracted GT atomic facts (structured, grouped by capability dimension)
-
[55]
A raw AI-generated caption (a list of step descriptions, NOT pre-extracted into atomic facts). Your task is to evaluate each GT atomic fact against the raw caption text and determine: – For each GT fact: is it match, partial, contradiction, or omission? – Additionally, identify any hallucinated action events in the caption that do NOT appear in the GT act...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.