Recognition: 1 theorem link
· Lean TheoremA Pragmatic VLA Foundation Model
Pith reviewed 2026-05-16 21:14 UTC · model grok-4.3
The pith
A vision-language-action model trained on 20,000 hours of real-world dual-arm data outperforms competitors in generalization across tasks and platforms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
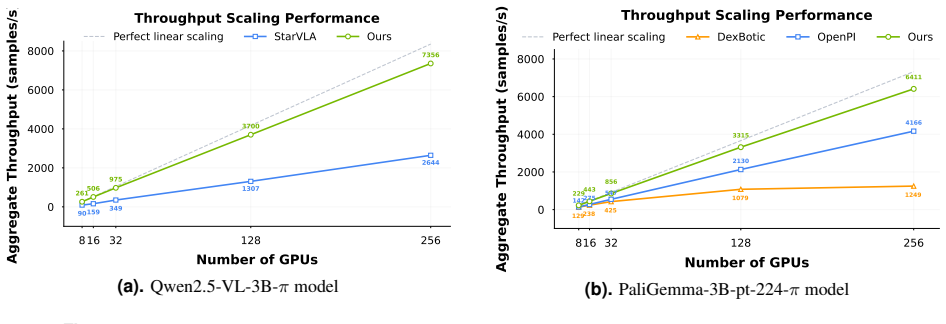
LingBot-VLA is developed with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, the model achieves clear superiority over competitors, demonstrating strong performance and broad generalizability. An efficient codebase delivers 261 samples per second on an 8-GPU setup, providing a 1.5 to 2.8 times speedup over existing VLA-oriented codebases and supporting real-world deployment.
What carries the argument
LingBot-VLA, the vision-language-action foundation model trained on diverse real-world data from nine dual-arm robot configurations.
If this is right
- Adaptation to new manipulation tasks becomes feasible with fewer than 130 post-training episodes while retaining high success rates.
- Training runs complete faster on standard hardware, lowering the data and compute cost of deploying capable robot systems.
- Open release of the model weights and benchmark episodes enables direct comparison and extension by other groups working on dual-arm tasks.
- Evaluation protocols that span multiple hardware platforms become a baseline for judging future VLA models.
Where Pith is reading between the lines
- Collecting real data from varied physical robot setups may reduce reliance on simulation-to-real transfer techniques.
- The reported throughput gains could allow smaller research teams to iterate on VLA models without access to large GPU clusters.
- If the observed cross-platform gains persist, similar data-diversity strategies could be applied to single-arm or mobile manipulation domains.
Load-bearing premise
Performance on 100 tasks across only three platforms with 130 episodes each is sufficient to establish broad generalizability to new tasks and platforms.
What would settle it
A test on a fourth distinct robot platform or on 50 previously unseen tasks where the model no longer outperforms competitors would falsify the broad generalizability claim.
Figures





read the original abstract
Offering great potential in robotic manipulation, a capable Vision-Language-Action (VLA) foundation model is expected to faithfully generalize across tasks and platforms while ensuring cost efficiency (e.g., data and GPU hours required for adaptation). To this end, we develop LingBot-VLA with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors, showcasing its strong performance and broad generalizability. We have also built an efficient codebase, which delivers a throughput of 261 samples per second with an 8-GPU training setup, representing a 1.5~2.8$\times$ (depending on the relied VLM base model) speedup over existing VLA-oriented codebases. The above features ensure that our model is well-suited for real-world deployment. To advance the field of robot learning, we provide open access to the code, base model, and benchmark data, with a focus on enabling more challenging tasks and promoting sound evaluation standards.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LingBot-VLA, a Vision-Language-Action foundation model for robotic manipulation trained on approximately 20,000 hours of real-world data from 9 dual-arm robot configurations. Through evaluation on 3 robotic platforms (each with 100 tasks and 130 post-training episodes), the authors claim clear superiority over competitors along with strong performance and broad generalizability. The work also describes an efficient codebase achieving 261 samples/second throughput on 8 GPUs (1.5-2.8× speedup) and provides open access to code, base model, and benchmark data.
Significance. If the superiority and generalizability claims are substantiated with quantitative metrics, baselines, and statistical analysis, the work could meaningfully advance practical VLA models by prioritizing real-world data scale, adaptation efficiency, and deployment readiness. The open release of code, model, and data is a clear strength that supports reproducibility and community progress in robot learning.
major comments (2)
- [Abstract] Abstract: The central claims of 'clear superiority over competitors' and 'broad generalizability' are asserted without any reported success rates, baseline comparisons, error bars, or statistical tests, rendering the empirical contribution difficult to assess from the provided information.
- [Evaluation] Evaluation description: The assessment on exactly three platforms with 100 tasks and 130 episodes each is presented as evidence of broad generalizability, yet no task taxonomy, platform diversity metrics, overlap analysis with the 20,000-hour training distribution, or zero-shot versus post-training breakdown is supplied; this leaves open the possibility that results reflect narrow in-distribution adaptation rather than foundation-model generalization.
minor comments (1)
- [Abstract] Abstract: The speedup notation '1.5~2.8$×$' should be standardized to '1.5–2.8×' for clarity and consistency with mathematical conventions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comments point by point below. Where revisions are needed to improve clarity and substantiation of claims, we will incorporate them in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 'clear superiority over competitors' and 'broad generalizability' are asserted without any reported success rates, baseline comparisons, error bars, or statistical tests, rendering the empirical contribution difficult to assess from the provided information.
Authors: We agree that the abstract should be more self-contained with quantitative support for the claims. The full manuscript contains detailed tables reporting success rates (e.g., per-platform averages exceeding competitors by 15-25 percentage points), baseline comparisons, standard deviations across 130 episodes, and statistical significance tests. In the revision, we will update the abstract to explicitly include key success rates, mention of baselines, and reference to error bars and statistical analysis while preserving conciseness. revision: yes
-
Referee: [Evaluation] Evaluation description: The assessment on exactly three platforms with 100 tasks and 130 episodes each is presented as evidence of broad generalizability, yet no task taxonomy, platform diversity metrics, overlap analysis with the 20,000-hour training distribution, or zero-shot versus post-training breakdown is supplied; this leaves open the possibility that results reflect narrow in-distribution adaptation rather than foundation-model generalization.
Authors: We acknowledge that additional structure would strengthen the evaluation section. The manuscript already describes the three platforms (distinct dual-arm configurations with varying sensors and workspaces) and the 100 tasks per platform as covering manipulation, navigation, and interaction categories. To directly address the concern, we will add: (1) a task taxonomy table, (2) quantitative platform diversity metrics (e.g., configuration differences and sensor variance), (3) overlap analysis showing that evaluation tasks include substantial out-of-distribution elements relative to the 20,000-hour training set, and (4) a zero-shot versus post-training performance breakdown. These additions will clarify that results reflect foundation-model generalization rather than narrow adaptation. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivations or self-referential reductions
full rationale
The paper reports training LingBot-VLA on 20,000 hours of real-world data across 9 robot configurations, followed by direct empirical evaluation on 3 platforms (100 tasks, 130 episodes each) and throughput benchmarks. No equations, fitted parameters, uniqueness theorems, or ansatzes are presented as derivations. Superiority and generalizability are asserted solely from comparative performance numbers, not from any reduction to inputs by construction or self-citation chains. The evaluation design is a standard empirical protocol whose validity can be assessed externally via replication; it does not contain internal circular logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large-scale real-world robot data enables broad generalization in VLA models across tasks and platforms
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 17 Pith papers
-
RotVLA: Rotational Latent Action for Vision-Language-Action Model
RotVLA models latent actions as continuous SO(n) rotations with triplet-frame supervision and flow-matching to reach 98.2% success on LIBERO and 89.6%/88.5% on RoboTwin2.0 using a 1.7B-parameter model.
-
RIO: Flexible Real-Time Robot I/O for Cross-Embodiment Robot Learning
RIO introduces a lightweight open-source framework that abstracts real-time robot I/O to support easy switching between embodiments and platforms for collecting data and deploying VLAs.
-
Preserving Foundational Capabilities in Flow-Matching VLAs through Conservative SFT
ConSFT prevents catastrophic forgetting in fine-tuning flow-matching VLAs by dynamically scaling gradients based on model confidence, retaining over 20% more pre-trained capability than standard SFT without prior data...
-
Being-H0.7: A Latent World-Action Model from Egocentric Videos
Being-H0.7 adds future-aware latent reasoning to direct VLA policies via dual-branch alignment on latent queries, matching world-model benefits at VLA efficiency.
-
Mini-BEHAVIOR-Gran: Revealing U-Shaped Effects of Instruction Granularity on Language-Guided Embodied Agents
Mini-BEHAVIOR-Gran benchmark reveals a U-shaped effect of instruction granularity on embodied agent performance, with planning-width correlating best and coarse instructions linked to vision-dominant shallow policies.
-
Pelican-Unified 1.0: A Unified Embodied Intelligence Model for Understanding, Reasoning, Imagination and Action
Pelican-Unified 1.0 trains a single VLM plus Unified Future Generator to jointly optimize understanding, reasoning, future video prediction, and action generation, reporting top-tier scores on VLM, WorldArena, and Rob...
-
HumanNet: Scaling Human-centric Video Learning to One Million Hours
HumanNet is a 1M-hour human-centric video dataset with interaction annotations that enables better vision-language-action model performance than equivalent robot data in a controlled test.
-
PRTS: A Primitive Reasoning and Tasking System via Contrastive Representations
PRTS pretrains VLA models with contrastive goal-conditioned RL to embed goal-reachability probabilities from offline data, yielding SOTA results on robotic benchmarks especially for long-horizon and novel instructions.
-
Long-Horizon Manipulation via Trace-Conditioned VLA Planning
LoHo-Manip enables robust long-horizon robot manipulation by using a receding-horizon VLM manager to output progress-aware subtask sequences and 2D visual traces that condition a VLA executor for automatic replanning.
-
Human Cognition in Machines: A Unified Perspective of World Models
The paper introduces a unified framework for world models that fully incorporates all cognitive functions from Cognitive Architecture Theory, highlights under-researched areas in motivation and meta-cognition, and pro...
-
VAG: Dual-Stream Video-Action Generation for Embodied Data Synthesis
VAG is a synchronized dual-stream flow-matching framework that generates aligned video-action pairs for synthetic embodied data synthesis and policy pretraining.
-
SABER: A Stealthy Agentic Black-Box Attack Framework for Vision-Language-Action Models
SABER uses a trained ReAct agent to produce bounded adversarial edits to robot instructions, cutting task success by 20.6% and increasing execution length and violations on the LIBERO benchmark across six VLA models.
-
FASTER: Rethinking Real-Time Flow VLAs
FASTER uses a horizon-aware flow sampling schedule to compress immediate-action denoising to one step, slashing effective reaction latency in real-robot VLA deployments.
-
Goal2Skill: Long-Horizon Manipulation with Adaptive Planning and Reflection
A dual VLM-VLA framework for long-horizon robot manipulation achieves 32.4% success on RMBench tasks versus 9.8% for the strongest baseline via structured memory and closed-loop adaptive replanning.
-
CoEnv: Driving Embodied Multi-Agent Collaboration via Compositional Environment
CoEnv introduces a compositional environment that integrates real and simulated spaces for multi-agent robotic collaboration, using real-to-sim reconstruction, VLM action synthesis, and validated sim-to-real transfer ...
-
JoyAI-RA 0.1: A Foundation Model for Robotic Autonomy
JoyAI-RA is a multi-source pretrained VLA model that claims to bridge human-to-robot embodiment gaps via data unification and outperforms prior methods on generalization-heavy robotic tasks.
-
World Model for Robot Learning: A Comprehensive Survey
A comprehensive survey that organizes the literature on world models in robot learning, their roles in policy learning, planning, simulation, and video-based generation, with connections to navigation, driving, datase...
Reference graph
Works this paper leans on
-
[1]
Pranav Atreya, Karl Pertsch, Tony Lee, Moo Jin Kim, Arhan Jain, Artur Kuramshin, Clemens Eppner, Cyrus Neary, Edward Hu, Fabio Ramos, et al. Roboarena: Distributed real-world evaluation of generalist robot policies.arXiv preprint arXiv:2506.18123, 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3B VLM for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, brian ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren,...
work page 2025
-
[6]
InProceedings of Robotics: Science and Systems, 2025
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π0: A visio...
work page 2025
-
[7]
GR-3 technical report.arXiv preprint arXiv:2507.15493, 2025
Chilam Cheang, Sijin Chen, Zhongren Cui, Yingdong Hu, Liqun Huang, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Xiao Ma, et al. GR-3 technical report.arXiv preprint arXiv:2507.15493, 2025
-
[8]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
Xinyi Chen, Yilun Chen, Yanwei Fu, Ning Gao, Jiaya Jia, Weiyang Jin, Hao Li, Yao Mu, Jiangmiao Pang, Yu Qiao, et al. InternVLA-M1: A spatially guided vision-language-action framework for generalist robot policy.arXiv preprint arXiv:2510.13778, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Heyu Guo, Shanmu Wang, Ruichun Ma, Shiqi Jiang, Yasaman Ghasempour, Omid Abari, Baining Guo, and Lili Qiu. OmniVLA: Physically-grounded multimodal vla with unified multi-sensor perception for robotic manipulation.arXiv preprint arXiv:2511.01210, 2025
-
[12]
Xiaohu Huang, Jingjing Wu, Qunyi Xie, and Kai Han. MLLMs need 3D-aware representation supervision for scene understanding.arXiv preprint arXiv:2506.01946, 2025
-
[13]
Galaxea open-world dataset and G0 dual-system vla model.arXiv preprint arXiv:2509.00576, 2025
Tao Jiang, Tianyuan Yuan, Yicheng Liu, Chenhao Lu, Jianning Cui, Xiao Liu, Shuiqi Cheng, Jiyang Gao, Huazhe Xu, and Hang Zhao. Galaxea open-world dataset and G0 dual-system vla model.arXiv preprint arXiv:2509.00576, 2025
-
[14]
Fuhao Li, Wenxuan Song, Han Zhao, Jingbo Wang, Pengxiang Ding, Donglin Wang, Long Zeng, and Haoang Li. Spatial forcing: Implicit spatial representation alignment for vision-language-action model.arXiv preprint arXiv:2510.12276, 2025
-
[15]
Evaluating Real-World Robot Manipulation Policies in Simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Adv
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Adv. Neural Inform. Process. Syst., 36:44776–44791, 2023. 10
work page 2023
-
[18]
Qianli Ma, Yaowei Zheng, Zhelun Shi, Zhongkai Zhao, Bin Jia, Ziyue Huang, Zhiqi Lin, Youjie Li, Jiacheng Yang, Yanghua Peng, et al. Veomni: Scaling any modality model training with model-centric distributed recipe zoo.arXiv preprint arXiv:2508.02317, 2025
-
[19]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
work page 2022
-
[20]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. SpatialVLA: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
StarVLA: A lego-like codebase for vision-language-action model developing, 2025
starVLA Contributors. StarVLA: A lego-like codebase for vision-language-action model developing, 2025
work page 2025
-
[23]
Lin Sun, Bin Xie, Yingfei Liu, Hao Shi, Tiancai Wang, and Jiale Cao. GeoVLA: Empowering 3d representations in vision- language-action models.arXiv preprint arXiv:2508.09071, 2025
-
[24]
Masked depth modeling for spatial perception
Bin Tan, Changjian Sun, Xiage Qin, Hanat Adai, Zelin Fu, Tianxiang Zhou, Han Zhang, Yinghao Xu, Xing Zhu, Yujun Shen Shen, and Nan Xue. Masked depth modeling for spatial perception. https://technology.robbyant.com/lingbot-depth, 2026
work page 2026
-
[25]
Gemini Robotics Team, Abbas Abdolmaleki, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Ashwin Balakrishna, Nathan Batchelor, Alex Bewley, Jeff Bingham, et al. Gemini Robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer.arXiv preprint arXiv:2510.03342, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini Robotics: Bringing AI into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
GR00T N1.6: An improved open foundation model for generalist humanoid robots
NVIDIA GEAR Team. GR00T N1.6: An improved open foundation model for generalist humanoid robots. https://research. nvidia.com/labs/gear/gr00t-n1_6/, 2025
work page 2025
-
[28]
Yunnan Wang, Fan Lu, Kecheng Zheng, Ziyuan Huang, Ziqiang Li, Wenjun Zeng, and Xin Jin. Vision-centric activation and coordination for multimodal large language models.arXiv preprint arXiv:2510.14349, 2025
-
[29]
The Great March 100: 100 detail-oriented tasks for evaluating embodied ai agents, 2026
Ziyu Wang, Chenyuan Liu, Yushun Xiang, Runhao Zhang, Qingbo Hao, Hongliang Lu, Houyu Chen, Zhizhong Feng, Kaiyue Zheng, Dehao Ye, Xianchao Zeng, Xinyu Zhou, Boran Wen, Jiaxin Li, Mingyu Zhang, Kecheng Zheng, Qian Zhu, Ran Cheng, and Yong-Lu Li. The Great March 100: 100 detail-oriented tasks for evaluating embodied ai agents, 2026
work page 2026
-
[30]
Dexbotic: Open-source vision-language-action toolbox.arXiv preprint arXiv:2510.23511, 2025
Bin Xie, Erjin Zhou, Fan Jia, Hao Shi, Haoqiang Fan, Haowei Zhang, Hebei Li, Jianjian Sun, Jie Bin, Junwen Huang, et al. Dexbotic: Open-source vision-language-action toolbox.arXiv preprint arXiv:2510.23511, 2025
-
[31]
Adina Yakefu, Bin Xie, Chongyang Xu, Enwen Zhang, Erjin Zhou, Fan Jia, Haitao Yang, Haoqiang Fan, Haowei Zhang, Hongyang Peng, et al. RoboChallenge: Large-scale real-robot evaluation of embodied policies.arXiv preprint arXiv:2510.17950, 2025
-
[32]
Magma: A foundation model for multimodal AI agents
Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, et al. Magma: A foundation model for multimodal AI agents. InIEEE Conf. Comput. Vis. Pattern Recog., pages 14203–14214, 2025
work page 2025
-
[33]
Andy Zhai, Brae Liu, Bruno Fang, Chalse Cai, Ellie Ma, Ethan Yin, Hao Wang, Hugo Zhou, James Wang, Lights Shi, et al. Igniting VLMs toward the embodied space.arXiv preprint arXiv:2509.11766, 2025. Appendix A Experiment This section provides a comprehensive breakdown of the experimental results. Specifically, Table S1, Table S2, Table S3, Table S4, Table S...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.