Prefix-Safe Bayesian Belief Tracking for LLM Reasoning Reliability:Separating Calibration from Ranking
Pith reviewed 2026-06-29 16:55 UTC · model grok-4.3
The pith
Sequential Bayesian Belief Tracking separates calibration quality from ranking performance using prefix-safe observations in LLM reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
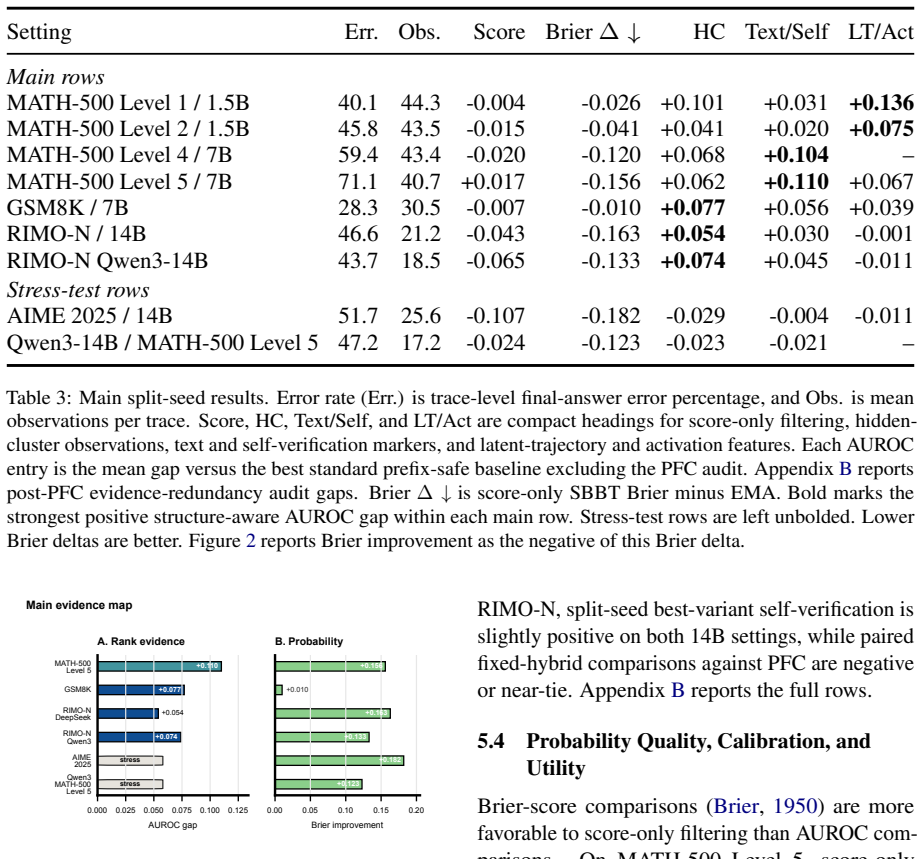
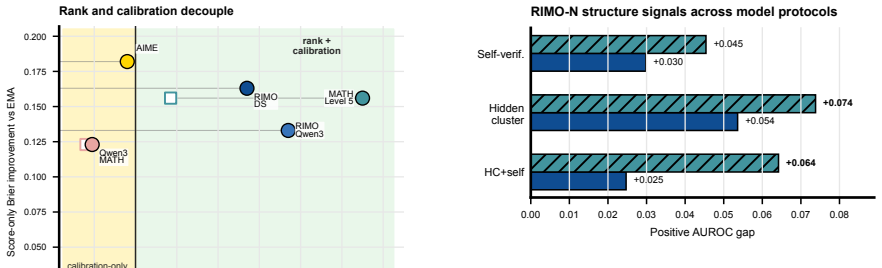
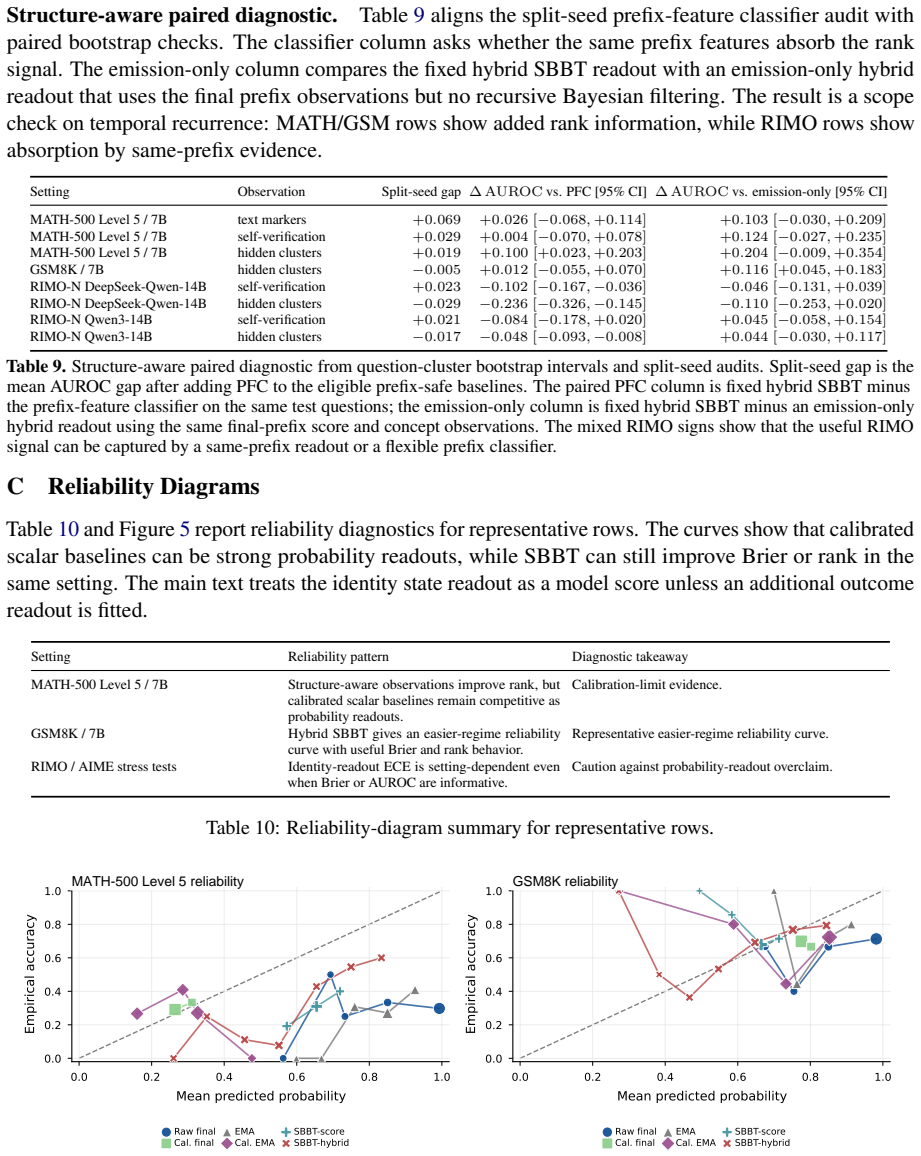
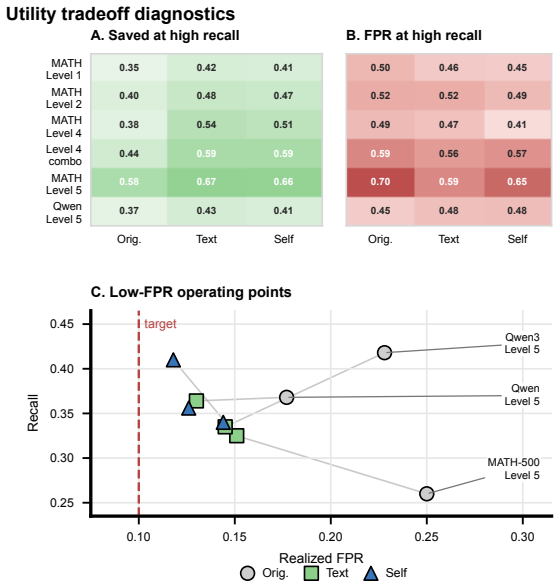
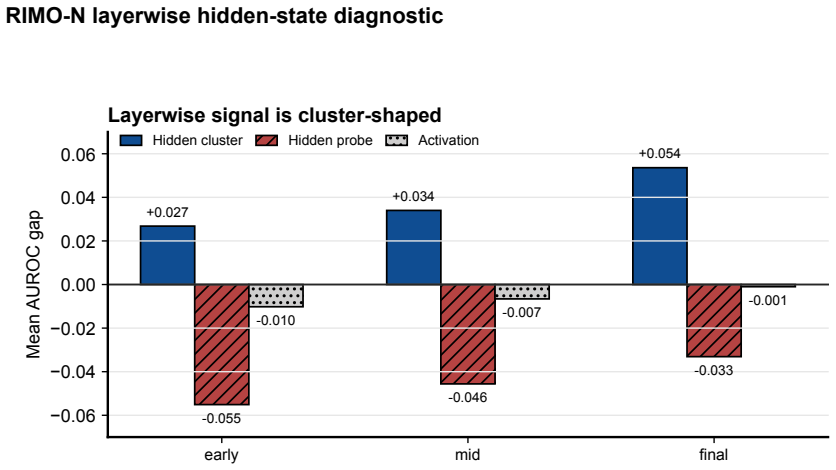
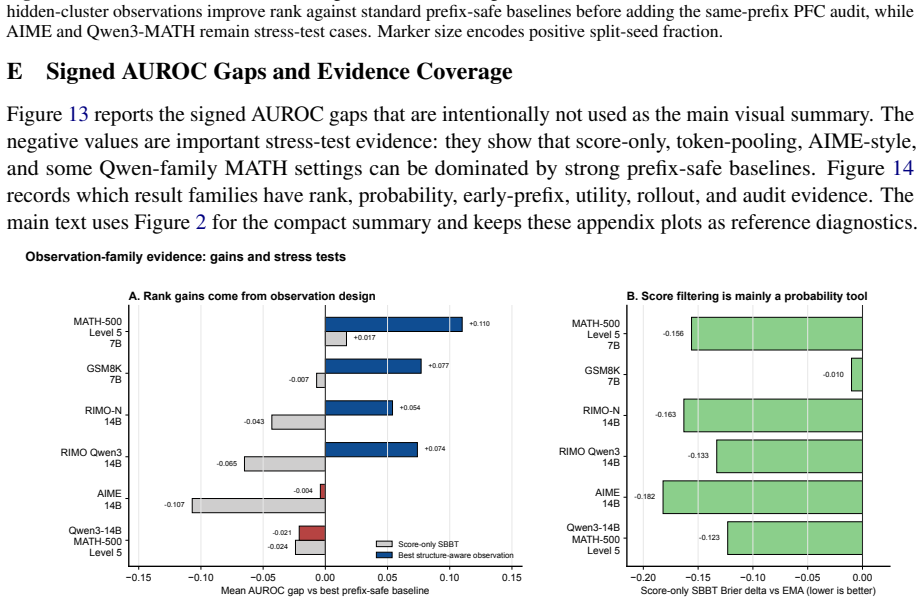
Sequential Bayesian Belief Tracking (SBBT) calibrates observation likelihoods and recursively updates a two-state belief for prefix-conditioned eventual-success estimation. Score-only SBBT improves Brier score for probability quality, while structure-aware observations deliver AUROC gains up to +0.110 against strong prefix-safe baselines on hard math traces; text markers and self-verification signals remain positive under same-prefix audits.
What carries the argument
Sequential Bayesian Belief Tracking (SBBT): a recursive two-state belief updater whose observation likelihoods are calibrated in advance.
If this is right
- Score-only SBBT improves probability quality measured by Brier score.
- Structure-aware observations produce AUROC gains that scalar scores alone do not achieve.
- SBBT unifies tracking for scalar scores, text markers, self-verification, hidden clusters, token-pooling probes, and latent-trajectory features.
- MATH-500 text markers and RIMO-N self-verification signals remain positive under same-prefix classifier audit.
- Scalar scores mainly aid calibration while structure-aware signals aid ranking only when baselines have not already captured the rank evidence.
Where Pith is reading between the lines
- Real-time reliability monitoring during generation becomes feasible without waiting for the completed trace.
- Effort on new prefix-safe probes should target structural features rather than additional scalar scores to improve ranking decisions.
- The calibration-ranking split may appear in other sequential estimation settings where only partial observations are available.
- Deployed systems could route traces differently based on which observation type drives their reliability estimate.
Load-bearing premise
The chosen observations must stay strictly prefix-safe and add no information about the final answer beyond what the prefix already contains.
What would settle it
Showing that any structure-aware observation used for the AUROC gains actually leaks information about the eventual answer would eliminate the claimed ranking improvement.
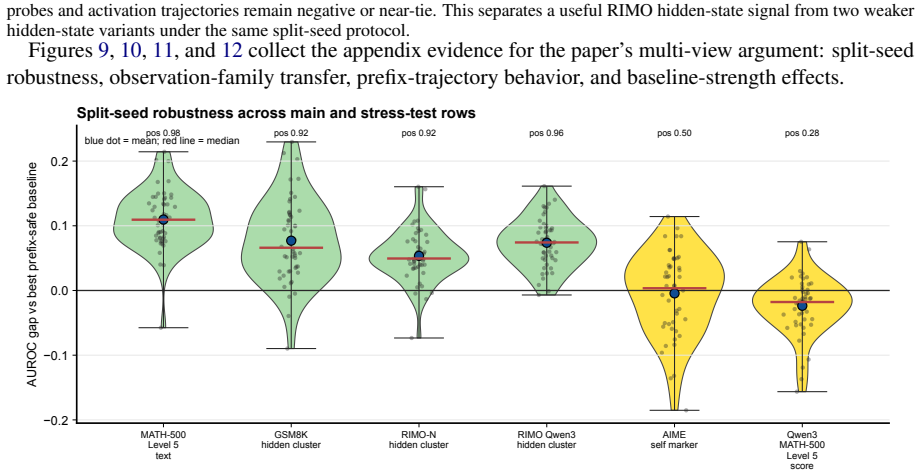
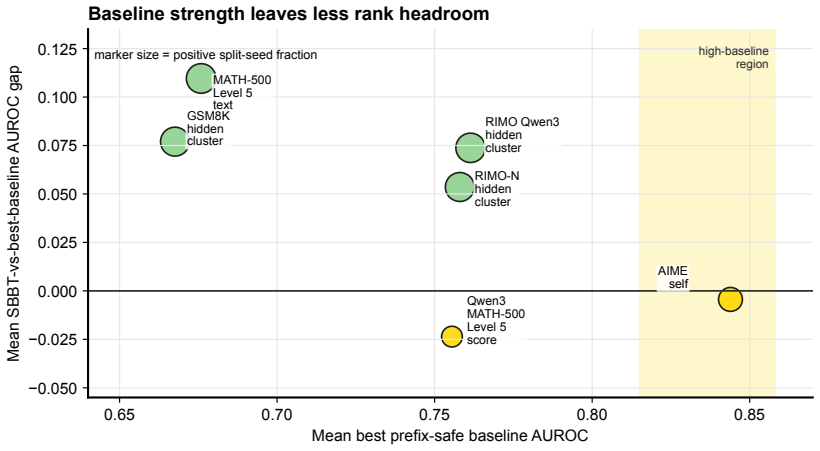
Figures





read the original abstract
Long reasoning traces need reliability estimates before final answers are known. We study prefix-conditioned eventual-success estimation, $P(y=1 \mid o_{1:t})$, using prefix-safe observations. Sequential Bayesian Belief Tracking (SBBT) calibrates observation likelihoods and recursively updates a two-state belief, providing a common tracker for scalar scores, text and self-verification markers, hidden clusters, token-pooling probes, and latent-trajectory features. Across generated open-weight traces on MATH-500, GSM8K, AIME 2025, and RIMO-N, probability quality and ranking separate: score-only SBBT often improves Brier, while AUROC gains require structure-aware evidence beyond strong prefix-safe baselines. In the strongest hard math setting, structure-aware observations reach +0.110 AUROC against standard prefix-safe baselines. Under a same-prefix classifier audit, MATH-500 text markers and RIMO-N self-verification signals remain positive. Together, these findings support SBBT as a calibration-aware online inference framework and expose an evidence regime: scalar scores mainly support probability quality, while structure-aware prefix signals support ranking only when strong prefix-safe baselines have not already absorbed the rank evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Sequential Bayesian Belief Tracking (SBBT) for prefix-conditioned eventual-success estimation in LLM reasoning using prefix-safe observations. It separates probability quality (Brier score improvements from score-only SBBT) from ranking (AUROC gains up to +0.110 from structure-aware observations) across MATH-500, GSM8K, AIME 2025, and RIMO-N, with validation via same-prefix classifier audit confirming positive contributions from text markers and self-verification signals.
Significance. If the results hold, the contribution lies in providing a recursive Bayesian framework that distinguishes calibration effects from ranking performance in online settings. The direct audit of the prefix-safety assumption is a notable strength, supporting the claim that structure-aware evidence adds value beyond strong baselines only when not already absorbed.
minor comments (2)
- [Abstract] Reporting the +0.110 AUROC gain without error bars or details on experimental variance limits the ability to gauge result stability.
- [Abstract] Additional information on how likelihood calibration is performed and the train/test splits would help confirm the out-of-sample nature of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the manuscript and the recommendation for minor revision. We appreciate the recognition that the direct audit of the prefix-safety assumption strengthens the claim regarding structure-aware evidence, and that the framework usefully separates calibration from ranking in online settings.
Circularity Check
No significant circularity identified
full rationale
The paper defines SBBT as a recursive two-state Bayesian update that takes calibrated observation likelihoods as input and produces prefix-conditioned success probabilities. The abstract and skeptic analysis indicate that likelihood calibration is performed as part of the method, with explicit same-prefix classifier audits and separation of Brier vs. AUROC metrics reported on held-out generated traces. No equations or steps reduce by construction to the evaluation metrics themselves; the +0.110 AUROC gain is presented as an empirical outcome under the prefix-safety assumption that the paper directly tests. The derivation chain remains self-contained against external benchmarks with no load-bearing self-citations or fitted-input renamings.
Axiom & Free-Parameter Ledger
free parameters (1)
- observation likelihoods
axioms (2)
- domain assumption Two-state belief model suffices to capture eventual success
- domain assumption Observations can be treated as conditionally independent given the latent state
Reference graph
Works this paper leans on
-
[1]
Guillaume Alain and Yoshua Bengio. 2018. https://arxiv.org/abs/1610.01644 Understanding intermediate layers using linear classifier probes . Preprint, arXiv:1610.01644
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster
Anastasios N. Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster. 2025. https://arxiv.org/abs/2208.02814 Conformal risk control . Preprint, arXiv:2208.02814
-
[3]
Baum, Ted Petrie, George Soules, and Norman Weiss
Leonard E. Baum, Ted Petrie, George Soules, and Norman Weiss. 1970. http://www.jstor.org/stable/2239727 A maximization technique occurring in the statistical analysis of probabilistic functions of markov chains . The Annals of Mathematical Statistics, 41(1):164--171
-
[4]
Yonatan Belinkov. 2021. https://arxiv.org/abs/2102.12452 Probing classifiers: Promises, shortcomings, and advances . Preprint, arXiv:2102.12452
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Glenn W. Brier. 1950. https://doi.org/10.1175/1520-0493(1950)078<0001:VOFEIT>2.0.CO;2 Verification of forecasts expressed in terms of probability . Monthly Weather Review, 78(1):1--3
-
[6]
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. 2024. https://arxiv.org/abs/2212.03827 Discovering latent knowledge in language models without supervision . Preprint, arXiv:2212.03827
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Lingjiao Chen, Matei Zaharia, and James Zou. 2023. https://arxiv.org/abs/2305.05176 Frugalgpt: How to use large language models while reducing cost and improving performance . Preprint, arXiv:2305.05176
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [8]
-
[9]
Maciej Chrabaszcz, Aleksander Szymczyk, Marcin Sendera, Tomasz Trzcinski, and Sebastian Cygert. 2026. https://arxiv.org/abs/2605.18549 Monitoring the internal monologue: Probe trajectories reveal reasoning dynamics . Preprint, arXiv:2605.18549
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. https://arxiv.org/abs/2110.14168 Training verifiers to solve math word problems . Preprint, arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Jasper Dekoninck, Nikola Jovanovic, Tim Gehrunger, Kari Rognvaldsson, Ivo Petrov, Chenhao Sun, and Martin Vechev. 2026. https://arxiv.org/abs/2605.00674 Beyond benchmarks: Matharena as an evaluation platform for mathematics with llms . Preprint, arXiv:2605.00674
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [12]
-
[13]
Shrey Desai and Greg Durrett. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.21 Calibration of pre-trained transformers . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 295--302, Online. Association for Computational Linguistics
- [14]
-
[15]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and 1 others. 2024. https://doi.org/10.1038/s41586-024-07421-0 Detecting hallucinations in large language models using semantic entropy . Nature, 630:625--630
-
[16]
Tom Fawcett. 2006. https://doi.org/10.1016/j.patrec.2005.10.010 An introduction to roc analysis . Pattern Recognition Letters, 27(8):861--874. ROC Analysis in Pattern Recognition
-
[17]
Yonatan Geifman and Ran El-Yaniv. 2019. https://proceedings.mlr.press/v97/geifman19a.html S elective N et: A deep neural network with an integrated reject option . In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2151--2159. PMLR
2019
-
[18]
Tilmann Gneiting and Adrian E Raftery. 2007. Strictly proper scoring rules, prediction, and estimation. Journal of the American statistical Association, 102(477):359--378
2007
-
[19]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. 2017. https://proceedings.mlr.press/v70/guo17a.html On calibration of modern neural networks . In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1321--1330. PMLR
2017
-
[21]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, and 175 others. 2025. https://doi.org/10.1038/s41586-025-09422-z Deepseek-r1 incentivizes reasoning in llms through reinforcement lear...
-
[22]
David J. Hand and Robert J. Till. 2001. https://doi.org/10.1023/A:1010920819831 A simple generalisation of the area under the roc curve for multiple class classification problems . Machine Learning, 45(2):171--186
-
[23]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. https://openreview.net/forum?id=7Bywt2mQsCe Measuring mathematical problem solving with the MATH dataset . In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
2021
-
[24]
Hugging Face H4 . 2023. https://huggingface.co/datasets/HuggingFaceH4/MATH-500 MATH-500 . Hugging Face dataset
2023
-
[25]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, and 17 others. 2022. https://arxiv.org/abs/2207.05221 Language models (mostly...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. https://arxiv.org/abs/2305.20050 Let's verify step by step . Preprint, arXiv:2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. https://arxiv.org/abs/2205.14334 Teaching models to express their uncertainty in words . Preprint, arXiv:2205.14334
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, and Abhinav Rastogi. 2024. https://arxiv.org/abs/2406.06592 Improve mathematical reasoning in language models by automated process supervision . Preprint, arXiv:2406.06592
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
MathArena . 2025. https://huggingface.co/datasets/MathArena/aime_2025 AIME 2025 . Hugging Face dataset
2025
-
[30]
L.R. Rabiner. 1989. https://doi.org/10.1109/5.18626 A tutorial on hidden markov models and selected applications in speech recognition . Proceedings of the IEEE, 77(2):257--286
-
[31]
Simo Sarkka and Lennart Svensson. 2023. Bayesian Filtering and Smoothing, 2 edition. Institute of Mathematical Statistics Textbooks. Cambridge University Press
2023
-
[32]
Tran, Yi Tay, and Donald Metzler
Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Q. Tran, Yi Tay, and Donald Metzler. 2022. https://arxiv.org/abs/2207.07061 Confident adaptive language modeling . Preprint, arXiv:2207.07061
-
[33]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher Manning. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.330 Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback . In Proceedings of the 2023 Conference on Em...
-
[34]
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. 2022. https://arxiv.org/abs/2211.14275 Solving math word problems with process- and outcome-based feedback . Preprint, arXiv:2211.14275
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Vilas, Safoora Yousefi, Besmira Nushi, Eric Horvitz, and Vidhisha Balachandran
Martina G. Vilas, Safoora Yousefi, Besmira Nushi, Eric Horvitz, and Vidhisha Balachandran. 2025. https://arxiv.org/abs/2510.10494 Tracing the traces: Latent temporal signals for efficient and accurate reasoning . Preprint, arXiv:2510.10494
-
[36]
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. 2024. https://doi.org/10.18653/v1/2024.acl-long.510 Math-shepherd: Verify and reinforce LLM s step-by-step without human annotations . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages...
-
[37]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://arxiv.org/abs/2203.11171 Self-consistency improves chain of thought reasoning in language models . Preprint, arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. https://arxiv.org/abs/2201.11903 Chain-of-thought prompting elicits reasoning in large language models . Preprint, arXiv:2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [39]
-
[40]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025 a . https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. 2024. https://arxiv.org/abs/2409.12122 Qwen2.5-math technical report: Toward mathematical expert model via self-improvement . Preprint, arXiv:2409.12122
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [42]
- [43]
- [44]
-
[45]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[46]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.