EAPO: Entropy-Driven Adaptive Positive-Negative Sample Weighting for Policy Optimization in Open-Ended QA
Pith reviewed 2026-06-29 12:55 UTC · model grok-4.3
The pith
EAPO uses the ratio of current to initial policy entropy to adaptively weight positive samples, improving diversity and stability over fixed-weight methods in open-ended QA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
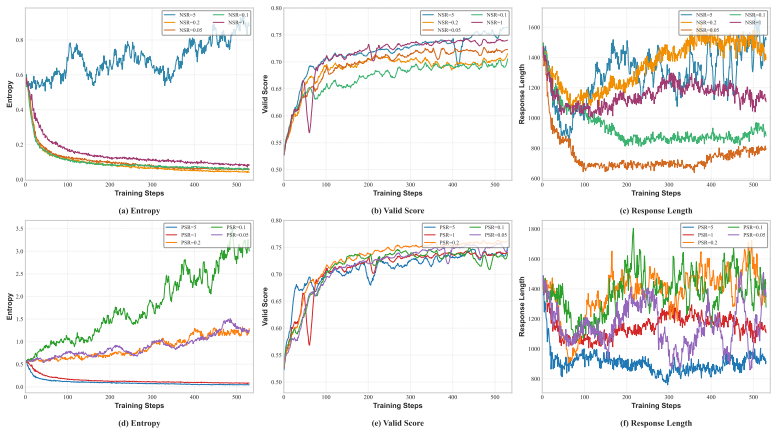
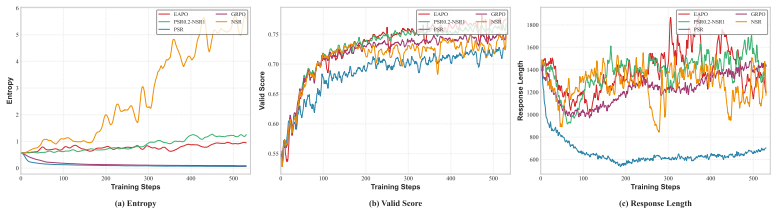
Negative samples predominantly govern response diversity and the performance upper bound, whereas positive samples primarily determine response quality and convergence stability. EAPO therefore computes an adaptive coefficient for positive samples equal to the ratio of current policy entropy to initial entropy; this coefficient is lowered during the entropy-decreasing phase to preserve exploration and raised during the entropy-increasing phase to reinforce stability, thereby mitigating entropy collapse.
What carries the argument
The entropy-ratio coefficient (current policy entropy divided by initial entropy) that dynamically scales the weight given to positive samples inside the policy-gradient objective.
If this is right
- Response diversity is maintained by deliberately lowering positive-sample weight whenever entropy begins to fall.
- Training stability improves when positive-sample weight is increased during periods of rising entropy.
- The adaptive scheme prevents the entropy collapse that fixed positive-negative weights commonly produce in open-ended QA.
- The performance upper bound set by negative samples is reached more reliably because exploration is preserved longer.
Where Pith is reading between the lines
- The same entropy-ratio rule could be tested on non-medical open-ended tasks such as creative writing or code generation to check whether the positive-negative division of labor holds outside medicine.
- Combining the EAPO coefficient with existing entropy-regularization terms in PPO-style algorithms might yield a parameter-free way to control collapse without extra hyperparameters.
- If the entropy trajectory is measured on a held-out validation set rather than the training batch, the method could be made more robust to noisy reward signals.
Load-bearing premise
Negative samples control diversity and the performance ceiling while positive samples control quality and stability.
What would settle it
Running the same medical QA experiments with the identical reward function and finding that EAPO produces no measurable gain in response diversity or training stability relative to the fixed-weight baselines would falsify the central claim.
Figures


read the original abstract
Large Reasoning Models are typically trained via reinforcement learning from verifiable rewards (RLVR). However, existing approaches adopt fixed weights for positive and negative samples, and the conclusions hardly generalize to open-ended question answering (QA). In this paper, we systematically investigate the roles of positive and negative samples in reinforcement learning for open-ended QA. We propose a reward-mean-based strategy for distinguishing positive from negative samples, and observe that negative samples predominantly govern response diversity and the performance upper bound, whereas positive samples primarily determine response quality and convergence stability. Building on these observations, we propose EAPO, an Entropy-driven Adaptive Policy Optimization method that adaptively computes the weighting coefficients of positive samples based on the ratio of the current policy entropy to the initial entropy. During the entropy-decreasing phase, the weight assigned to positive samples is reduced to preserve exploration, whereas during the entropy-increasing phase it is amplified to reinforce stability, thereby mitigating entropy collapse. Experiments on two publicly available open-ended medical QA datasets demonstrate that EAPO consistently and substantially outperforms fixed-weight baselines in both response diversity and stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in RLVR for open-ended QA, negative samples predominantly control response diversity and the performance upper bound while positive samples control response quality and convergence stability. It introduces a reward-mean strategy to label samples and proposes EAPO, which adaptively sets positive-sample weights from the ratio of current policy entropy to initial entropy (reducing the weight during entropy decrease to preserve exploration and increasing it during entropy increase to reinforce stability). Experiments on two public open-ended medical QA datasets are reported to show that EAPO substantially outperforms fixed-weight baselines on both diversity and stability metrics.
Significance. If the empirical results hold, EAPO supplies a concrete, falsifiable heuristic for adaptive weighting that directly addresses the failure of fixed-weight RLVR on open-ended tasks. The work is grounded in an explicit observation about differential sample roles and includes reproducible experiments on public datasets, which strengthens its contribution to training stability and diversity in reasoning models for domains such as medical QA.
minor comments (1)
- [Abstract] Abstract: the performance claims are stated qualitatively ('consistently and substantially outperforms') without any numerical deltas, error bars, or dataset identifiers; adding these would improve readability while remaining a presentation issue.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the clear summary of our contributions, and the recommendation for minor revision. We are pleased that the empirical grounding on public datasets and the explicit observations on positive/negative sample roles were viewed favorably.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's claims rest on empirical observations from RL training runs and a concrete heuristic (entropy-ratio weighting) whose validity is tested directly via experiments on two public datasets. No equations reduce a prediction to a fitted input by construction, no self-citations are invoked as load-bearing uniqueness theorems, and the adaptive rule is presented as an externally falsifiable design choice rather than a self-referential definition. The central result (outperformance in diversity and stability) is therefore independent of the method's internal construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reward-mean-based strategy reliably distinguishes positive from negative samples in open-ended QA.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems, 38:9640–9664
Asymmetric reinforce for off-policy reinforcement learning: Balancing positive and negative rewards. Advances in Neural Information Processing Systems, 38:9640–9664. Peter Chen, Xiaopeng Li, Ziniu Li, Wotao Yin, Xi Chen, and Tianyi Lin. 2025a. Exploration vs exploitation: Rethinking rlvr through clipping, entropy, and spuri- ous reward.arXiv preprint arXi...
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948. Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Yash Ingle, Jaival Chauhan, Ankit Yadav, and Sudhakar Mishra
On the direction of rlvr updates for llm reason- ing: Identification and exploitation.arXiv preprint arXiv:2603.22117. Yash Ingle, Jaival Chauhan, Ankit Yadav, and Sudhakar Mishra
-
[4]
Adaptive negative reinforcement for llm reasoning: Dynamically balancing correction and diversity in rlvr.arXiv preprint arXiv:2605.07137. Shiwei Lyu, Chenfei Chi, Hongbo Cai, Lei Shi, Xiaoyan Yang, Lei Liu, Xiang Chen, Deng Zhao, Zhiqiang Zhang, Xianguo Lyu, Ming Zhang, Fangzhou Li, Xiaowei Ma, Yue Shen, Jinjie Gu, Wei Xue, and Yiran Huang
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Rjua-qa: A comprehensive qa dataset for urology.Preprint, arXiv:2312.09785. Iman Mirzadeh, Keivan Alizadeh-Vahid, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar
-
[6]
InInternational Conference on Learn- ing Representations, volume 2025, pages 94743– 94765
Gsm-symbolic: Understanding the limitations of mathematical reasoning in large lan- guage models. InInternational Conference on Learn- ing Representations, volume 2025, pages 94743– 94765. Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, and 1 oth- ers
2025
-
[7]
Humanity’s last exam.arXiv preprint arXiv:2501.14249. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, and 25 oth- ers
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Qwen2.5 technical report.Preprint, arXiv:2412.15115. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Proximal Policy Optimization Algorithms
Proxi- mal policy optimization algorithms.arXiv preprint arXiv:1707.06347. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300. Xinyu Tang, Yuliang Zhan, Zhixun Li, Wayne Xin Zhao, Zhenduo Zhang, Zujie Wen, Zhiqiang Zhang, and Jun Zhou
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Rethinking sample polarity in reinforce- ment learning with verifiable rewards.arXiv preprint arXiv:2512.21625. Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, and 1 others. 9
-
[12]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. Qwen Team
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Qwen3 technical report.Preprint, arXiv:2505.09388. Xueyun Tian, Minghua Ma, Bingbing Xu, Nuoyan Lyu, Wei Li, Heng Dong, Zheng Chu, Yuanzhuo Wang, and Huawei Shen
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Jiakang Wang, Runze Liu, Lei Lin, Wenping Hu, Xiu Li, Fuzheng Zhang, Guorui Zhou, and Kun Gai
Learning from mistakes: Negative reasoning samples enhance out-of-domain generalization.arXiv preprint arXiv:2601.04992. Jiakang Wang, Runze Liu, Lei Lin, Wenping Hu, Xiu Li, Fuzheng Zhang, Guorui Zhou, and Kun Gai
-
[15]
When Importance Sampling Misallocates Credit: Asymmetric Ratios for Outcome-Supervised RL
Aspo: Asymmetric importance sampling policy opti- mization.arXiv preprint arXiv:2510.06062. Peng-Yuan Wang, Tian-Shuo Liu, Chenyang Wang, Ziniu Li, Yidi Wang, Shu Yan, Chengxing Jia, Xu- Hui Liu, Xinwei Chen, Jiacheng Xu, and 1 oth- ers
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Unlocking Exploration in RLVR: Uncertainty-aware Advantage Shaping for Deeper Reasoning
Un- locking exploration in rlvr: Uncertainty-aware advan- tage shaping for deeper reasoning.arXiv preprint arXiv:2510.10649. Huimin Xu, Shuai Zhao, Xiaobao Wu, and Anh Tuan Luu. 2026a. Understanding and preventing entropy collapse in rlvr with on-policy entropy flow optimiza- tion.arXiv preprint arXiv:2605.11491. Ming Xu
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
How You Begin is How You Reason: Driving Exploration in RLVR via Prefix-Tuned Priors
Medical dataset (cmd). https://github.com/Toyhom/ Chinese-medical-dialogue-data. Yifan Xu, Junren Chen, and Yifan Chen. 2026b. How you begin is how you reason: Driving exploration in rlvr via prefix-tuned priors.arXiv preprint arXiv:2605.08817. Yibo Yan, Shen Wang, Jiahao Huo, Jingheng Ye, Zhen- dong Chu, Xuming Hu, Philip S Yu, Carla Gomes, Bart Selman, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Position: Multimodal Large Language Models Can Significantly Advance Scientific Reasoning
Posi- tion: Multimodal large language models can signifi- cantly advance scientific reasoning.arXiv preprint arXiv:2502.02871. Dayu Yang, Tianyang Liu, Daoan Zhang, Antoine Simoulin, Xiaoyi Liu, Yuwei Cao, Zhaopu Teng, Xin Qian, Grey Yang, Jiebo Luo, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 2586–2616
Code to think, think to code: A survey on code- enhanced reasoning and reasoning-driven code in- telligence in llms. InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 2586–2616. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, and 1 others
2025
-
[20]
Group Sequence Policy Optimization
Group sequence policy optimization.arXiv preprint arXiv:2507.18071. Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Provide the diagnostic conclusion together with recommendations for further diagnostic workup or treatment within the<advice>and</advice> tags. Patient consultation: {question} A.2 Evaluation Dimensions on LLM-as-a-Judge We adopt an LLM-as-a-Judge paradigm to score the model’s reasoning content in<think>tag during reinforcement training and the correspond...
-
[22]
W-REINFORCE adopts a fixed positive-sample weight w+ that remains unchanged throughout training; consequently, its final performance is highly sensitive to this hyperparameter: varying w+ alone lifts Rouge-L on RUJA from 0.263 to 0.337 and Reranker on RUJA from 0.903 to 0.983, indicating that an improper choice of w+ can lead to a substantial degradation ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.