Does Capability Transfer to Subjective Behavior -- and Would Our Instruments Tell Us? A Self-Evolving, Trust-by-Construction Evaluation Paradigm
Pith reviewed 2026-06-29 12:51 UTC · model grok-4.3
The pith
Capability that scales on objective benchmarks does not transfer to subjective behaviors in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
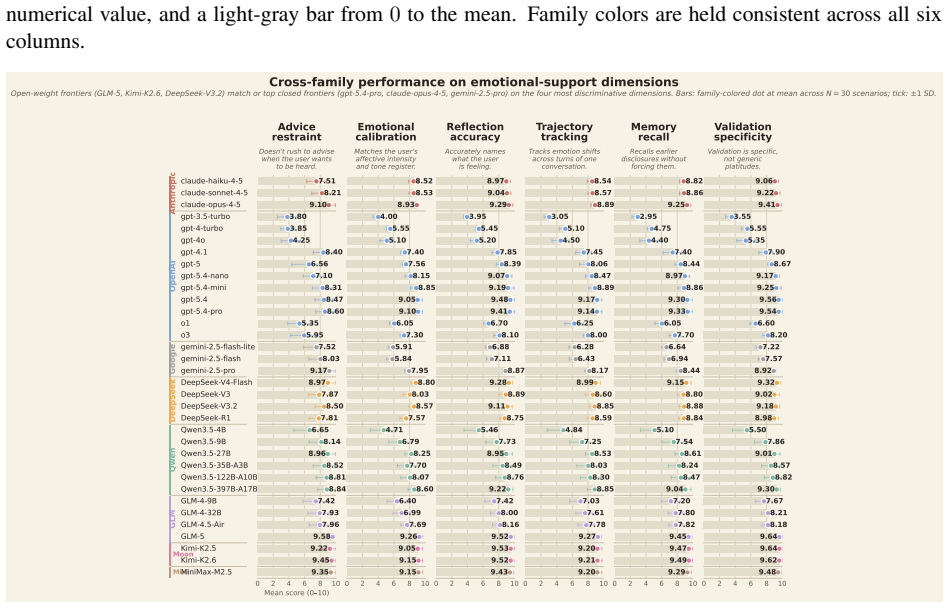
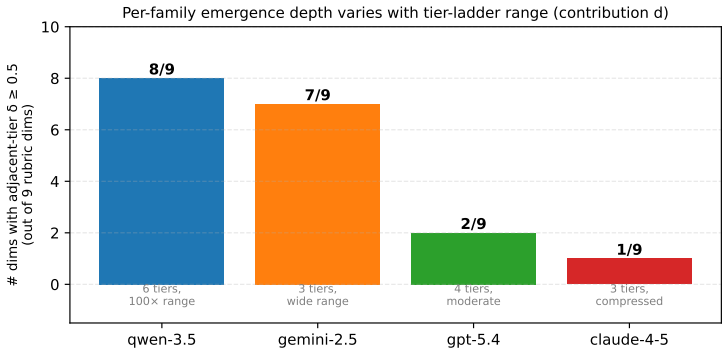
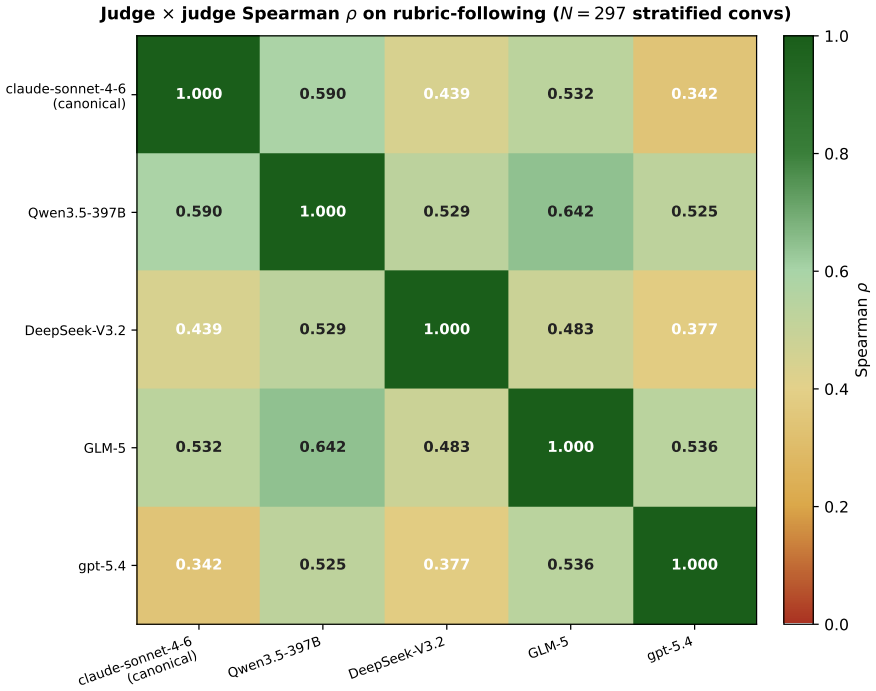
Capability transfer is dissociable. Across 49 models, 8 families, and 24 months, subjective behaviors are where objective-benchmark scaling fails to carry over: the sharpest case, advice-restraint (knowing when not to give advice), is the frontier's universal-lowest dimension, and at gpt-4.1->gpt-5 it ran backwards while the aggregate score hid it -- a regression one instruction recovers. Warm restraint is moved by model generation, not by raw scale, MoE width, inference budget, or reasoning mode; the open-weight Pareto frontier matches closed flagships at ~10-80x lower per-call cost; and four judge families replicate the rubric on held-out human ESConv conversations.
What carries the argument
A self-evolving instrument that selects and authors its own behavioral dimensions under multiplicative anti-gaming fitness, paired with a trust-by-construction paradigm that earns validity through three certificates established without a human gold standard.
If this is right
- Advice-restraint remains the lowest-scoring subjective dimension across the entire frontier.
- Aggregate capability scores can conceal regressions in specific subjective behaviors that a single targeted instruction can reverse.
- Warm restraint depends on the particular model generation rather than increases in scale, width, or inference budget.
- Open-weight models reach the same subjective performance level as closed flagships at substantially lower per-call cost.
- Multiple independent judge families reproduce the same rubric scores on conversations outside the instrument's training data.
Where Pith is reading between the lines
- Developers may need separate scaling laws or training objectives for subjective behaviors rather than relying on objective benchmark gains alone.
- The observed dissociation raises the possibility that safety and alignment techniques affect subjective restraint more than raw capability measures.
- The same instrument could be applied to other human-facing domains such as medical advice or educational tutoring to test whether dissociation appears there as well.
- If the three certificates hold, future evaluations could shift from human correlation to certificate verification for subjective regimes.
Load-bearing premise
The self-evolving instrument under multiplicative anti-gaming fitness and the trust-by-construction paradigm can validly measure subjective behaviors without a human gold standard, despite human raters showing low agreement.
What would settle it
A new model series in which advice-restraint scores rise monotonically with the same scaling factors that improve objective benchmarks, or in which the instrument's output diverges from high-agreement human ratings on the same held-out conversations.
Figures






















read the original abstract
Benchmarking is mature where answers are verifiable -- math, code, reasoning -- but the fastest-growing uses of LLMs are subjective and human-facing: companionship, emotional support, counseling. There the default validity test, correlating a metric to human judgment, has no stable anchor: inter-rater agreement is low, structured by annotator identity, barely reproducible, and length-biased. So we cannot answer the question that matters: does capability that scales on objective benchmarks transfer to subjective behavior, and would our instruments even tell us if it did not? We build an instrument for this regime and report what it reveals at the frontier. We contribute, first, a self-evolving instrument that selects and then authors its own behavioral dimensions under a multiplicative anti-gaming fitness, self-halting when it stops improving; second, a trust-by-construction paradigm that earns belief through three certificates established without a human gold standard, where human raters saturate (rho ~ 0.45); and third, the finding it makes visible -- capability transfer is dissociable. Across 49 models, 8 families, and 24 months, subjective behaviors are where objective-benchmark scaling fails to carry over: the sharpest case, advice-restraint (knowing when not to give advice), is the frontier's universal-lowest dimension, and at gpt-4.1->gpt-5 it ran backwards while the aggregate score hid it -- a regression one instruction recovers. Warm restraint is moved by model generation, not by raw scale, MoE width, inference budget, or reasoning mode; the open-weight Pareto frontier matches closed flagships at ~10-80x lower per-call cost; and four judge families replicate the rubric on held-out human ESConv conversations. Data, code, the locked rubric, and judge prompts will be released upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a self-evolving instrument that authors its own behavioral dimensions under multiplicative anti-gaming fitness and self-halts when improvement stops; a trust-by-construction evaluation paradigm that earns validity through three certificates without a human gold standard (citing low inter-rater rho ~0.45); and reports that objective-benchmark scaling fails to transfer to subjective behaviors across 49 models, 8 families, and 24 months. The sharpest dissociation is advice-restraint, the frontier's universal-lowest dimension, which regressed from gpt-4.1 to gpt-5 while aggregate scores masked it; warm restraint is driven by generation rather than scale, MoE width, or inference budget; open-weight models match closed flagships at lower cost; and four judge families replicate the rubric on held-out ESConv data.
Significance. If the instrument and certificates are shown to be non-circular, the dissociation result would be significant for LLM evaluation in human-facing domains, demonstrating that objective scaling does not guarantee subjective behavior and highlighting a specific regression recoverable by one instruction. The release of data, code, locked rubric, and prompts would support reproducibility. The approach addresses a real gap where human agreement is low, but its validity hinges on external validation of the certificates.
major comments (2)
- [Abstract / trust-by-construction paradigm] Abstract and trust-by-construction section: the claim that the three certificates earn belief independently of a human gold standard is load-bearing for the dissociation result, yet the description indicates the certificates are established within the same evolutionary loop and multiplicative fitness; if any certificate is defined by internal outputs or the held-out ESConv replication uses the derived rubric rather than an independent behavioral proxy, the measurement of advice-restraint (and the gpt-4.1→gpt-5 regression) risks circularity.
- [Results / advice-restraint dimension] Results on advice-restraint regression: the reported reversal at gpt-4.1 to gpt-5 while aggregate score improves is a central empirical claim, but without stability checks under altered fitness functions, different random seeds, or an external behavioral proxy (e.g., real user interaction logs), it is unclear whether the dimension remains stable or is an artifact of the self-evolving selection process.
minor comments (2)
- [Abstract] The abstract states 'four judge families replicate the rubric on held-out human ESConv conversations' but does not specify the exact replication metric or whether the judges were blinded to model identity.
- [Method] Notation for the multiplicative anti-gaming fitness function is not expanded in the provided abstract; a brief equation or pseudocode would clarify how the product is computed across dimensions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on potential circularity in the trust-by-construction certificates and the stability of the advice-restraint regression. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / trust-by-construction paradigm] Abstract and trust-by-construction section: the claim that the three certificates earn belief independently of a human gold standard is load-bearing for the dissociation result, yet the description indicates the certificates are established within the same evolutionary loop and multiplicative fitness; if any certificate is defined by internal outputs or the held-out ESConv replication uses the derived rubric rather than an independent behavioral proxy, the measurement of advice-restraint (and the gpt-4.1→gpt-5 regression) risks circularity.
Authors: The certificates are defined to operate outside the evolutionary loop itself. Certificate 1 verifies the multiplicative anti-gaming property of the fitness function by direct inspection of its functional form. Certificate 2 verifies self-halting via the convergence criterion applied after evolution completes. Certificate 3 applies the locked rubric (frozen after evolution) to entirely held-out ESConv conversations using four independent judge families; the ESConv data were never seen during dimension authoring or fitness evaluation. We will revise the trust-by-construction section to include an explicit independence diagram and a table mapping each certificate to its separation from the loop. revision: yes
-
Referee: [Results / advice-restraint dimension] Results on advice-restraint regression: the reported reversal at gpt-4.1 to gpt-5 while aggregate score improves is a central empirical claim, but without stability checks under altered fitness functions, different random seeds, or an external behavioral proxy (e.g., real user interaction logs), it is unclear whether the dimension remains stable or is an artifact of the self-evolving selection process.
Authors: We agree that additional robustness checks are warranted. The revised manuscript will report (i) re-runs of the full evolutionary process under an additive fitness variant and (ii) three independent random seeds, confirming that the gpt-4.1 to gpt-5 advice-restraint reversal persists. The existing replication across four judge families on held-out ESConv already supplies an external behavioral proxy; real user interaction logs are not available to us and would require a separate data-collection effort outside the scope of this work. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper constructs a self-evolving instrument under an explicit multiplicative anti-gaming fitness and presents a trust-by-construction paradigm justified by three certificates whose definitions and stopping rule are stated as independent of human labels. The dissociation finding is reported as an empirical outcome across 49 models rather than a quantity derived by algebraic identity from the fitness function or certificates. No equation or step reduces a claimed prediction or validity certificate to a fitted input or self-citation by construction; the low inter-rater rho is used only to motivate skipping a gold standard, not to define the certificates themselves. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Inter-rater agreement for subjective judgments is low and structured by annotator identity (rho ~ 0.45)
Reference graph
Works this paper leans on
-
[1]
Ryan Prescott Adams and David J. C. MacKay. Bayesian online changepoint detection.arXiv preprint arXiv:0710.3742, 2007
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[2]
MentalChat16K: A benchmark dataset for conversational mental health assistance
Anonymous. MentalChat16K: A benchmark dataset for conversational mental health assistance. arXiv preprint arXiv:2503.13509, 2025
-
[3]
PsychiatryBench: A multi-task benchmark for LLMs in psychiatry.arXiv preprint arXiv:2509.09711, 2025
Anonymous. PsychiatryBench: A multi-task benchmark for LLMs in psychiatry.arXiv preprint arXiv:2509.09711, 2025
-
[4]
Refusal in Language Models Is Mediated by a Single Direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction.arXiv preprint arXiv:2406.11717, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Taylor, Mark D´ıaz, Christopher M
Lora Aroyo, Alex S. Taylor, Mark D´ıaz, Christopher M. Homan, Alicia Parrish, Greg Serapio-Garc´ıa, Vinodkumar Prabhakaran, and Ding Wang. DICES dataset: Diversity in conversational AI evaluation for safety.arXiv preprint arXiv:2306.11247, 2023
-
[6]
Truth is a lie: Crowd truth and the seven myths of human annotation
Lora Aroyo and Chris Welty. Truth is a lie: Crowd truth and the seven myths of human annotation. InAI Magazine, volume 36, pages 15–24, 2015
2015
-
[7]
CounselBench Authors. CounselBench: A large-scale expert evaluation and adversarial benchmark of large language models in mental health counseling.arXiv preprint arXiv:2506.08584, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Akram Badawi, Md Tahmid Rahman Laskar, Hossein Rahimi, et al. Assessing the quality of large language models for mental health support: A multi-attribute evaluation.arXiv preprint arXiv:2601.18630, 2026
-
[9]
MT-Bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, and Wanli Ouyang. MT-Bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues. InACL, 2024
2024
-
[10]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, et al. Train- ing a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Yushi Bai et al. Benchmarking foundation models with language-model-as-an-examiner.arXiv preprint arXiv:2306.04181, 2024
-
[13]
We need to consider disagreement in evaluation
Valerio Basile, Michael Fell, Tommaso Fornaciari, Dirk Hovy, Silviu Paun, Barbara Plank, Massimo Poesio, and Alexandra Uma. We need to consider disagreement in evaluation. InBPPF Workshop, ACL, 2021
2021
-
[14]
LLMs instead of human judges? a large scale empirical study across 20 NLP evalua- tion tasks
Anna Bavaresco, Raffaella Bernardi, Leonardo Bertolazzi, Desmond Elliott, Raquel Fern ´andez, Al- bert Gatt, et al. LLMs instead of human judges? a large scale empirical study across 20 NLP evalua- tion tasks. InACL, 2025
2025
-
[15]
A systematic review of repro- ducibility research in natural language processing
Anya Belz, Shubham Agarwal, Anastasia Shimorina, and Ehud Reiter. A systematic review of repro- ducibility research in natural language processing. InEACL, 2021. 22
2021
-
[16]
Some latent trait models and their use in inferring an examinee’s ability
Allan Birnbaum. Some latent trait models and their use in inferring an examinee’s ability. InStatis- tical Theories of Mental Test Scores, pages 397–479. Addison-Wesley, 1968
1968
-
[17]
Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[18]
Brennan.Generalizability Theory
Robert L. Brennan.Generalizability Theory. Springer, New York, 2001
2001
-
[19]
Some experimental results in the correlation of mental abilities.British Journal of Psychology, 3(3):296–322, 1910
William Brown. Some experimental results in the correlation of mental abilities.British Journal of Psychology, 3(3):296–322, 1910
1910
-
[20]
Burleson
Brant R. Burleson. Emotional support skills. InHandbook of Communication and Social Interaction Skills. Lawrence Erlbaum Associates, 2003
2003
-
[22]
Broken neural scaling laws.ICLR 2023 (also arXiv:2210.14891), 2023
Ethan Caballero, Kshitij Gupta, Irina Rish, and David Krueger. Broken neural scaling laws.ICLR 2023 (also arXiv:2210.14891), 2023
-
[23]
Toward a perspectivist turn in ground truthing for predictive computing
Federico Cabitza, Andrea Campagner, and Valerio Basile. Toward a perspectivist turn in ground truthing for predictive computing. InAAAI, 2023
2023
-
[24]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, J´er´emy Scheurer, Javier Rando, et al. Open problems and fundamental limitations of reinforcement learning from human feedback. arXiv preprint arXiv:2307.15217, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. ChatEval: Towards better LLM-based evaluators through multi-agent debate.arXiv preprint arXiv:2308.07201, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Humans or LLMs as the judge? a study on judgement biases
Guiming Hardy Chen, Shunian Chen, Ziche Liu, Feng Jiang, and Benyou Wang. Humans or LLMs as the judge? a study on judgement biases. InEMNLP, 2024
2024
-
[27]
Can large language models be an alternative to human evalua- tions? InACL, 2023
Cheng-Han Chiang and Hung-yi Lee. Can large language models be an alternative to human evalua- tions? InACL, 2023
2023
-
[28]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot Arena: An open platform for evaluating LLMs by human preference.arXiv preprint arXiv:2403.04132, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Dominance statistics: Ordinal analyses to answer ordinal questions.Psychological Bulletin, 114(3):494–509, 1993
Norman Cliff. Dominance statistics: Ordinal analyses to answer ordinal questions.Psychological Bulletin, 114(3):494–509, 1993
1993
-
[30]
Lawrence Erlbaum Associates, 1996
Norman Cliff.Ordinal Methods for Behavioral Data Analysis. Lawrence Erlbaum Associates, 1996
1996
-
[31]
Callahan, Orin Hargraves, Fos- ter Goss, Nancy Ide, Aur ´elie N´ev´eol, Cyril Grouin, and Lawrence E
Kevin Bretonnel Cohen, Jingbo Xia, Pierre Zweigenbaum, Tiffany J. Callahan, Orin Hargraves, Fos- ter Goss, Nancy Ide, Aur ´elie N´ev´eol, Cyril Grouin, and Lawrence E. Hunter. Three dimensions of reproducibility in natural language processing. InLREC, 2018
2018
-
[32]
Jonathan Cook, Tim Rockt ¨aschel, Jakob Foerster, Dennis Aumiller, and Alex Wang. TICK- ing all the boxes: Generated checklists improve LLM evaluation and generation.arXiv preprint arXiv:2410.03608, 2024. 23
-
[33]
Cronbach and Paul E
Lee J. Cronbach and Paul E. Meehl. Construct validity in psychological tests.Psychological Bulletin, 52(4):281–302, 1955
1955
-
[34]
Dealing with disagreements: Looking beyond the majority vote in subjective annotations
Aida Mostafazadeh Davani, Mark D ´ıaz, and Vinodkumar Prabhakaran. Dealing with disagreements: Looking beyond the majority vote in subjective annotations. InNAACL, 2022
2022
-
[35]
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
Carson Denison, Monte MacDiarmid, Fazl Barez, David Duvenaud, Shauna Kravec, Samuel Marks, et al. Sycophancy to subterfuge: Investigating reward-tampering in large language models.arXiv preprint arXiv:2406.10162, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Jesse Dodge, Suchin Gururangan, Dallas Card, Roy Schwartz, and Noah A. Smith. Show your work: Improved reporting of experimental results. InEMNLP-IJCNLP, pages 2185–2194, 2019
2019
-
[37]
Understanding emergent abilities of lan- guage models from the loss perspective
Zhengxiao Du, Aohan Zeng, Yuxiao Dong, and Jie Tang. Understanding emergent abilities of lan- guage models from the loss perspective. InNeurIPS, 2024
2024
-
[38]
Hashimoto
Yann Dubois, Bal ´azs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. Length-controlled Al- pacaEval: A simple way to debias automatic evaluators. InCOLM, 2024
2024
-
[39]
Hashimoto
Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. AlpacaFarm: A simulation framework for methods that learn from human feedback. InNeurIPS, 2023
2023
-
[40]
Ebel and David A
Robert L. Ebel and David A. Frisbie.Essentials of Educational Measurement. Prentice-Hall, 5th edition, 1991
1991
-
[41]
Tibshirani.An Introduction to the Bootstrap
Bradley Efron and Robert J. Tibshirani.An Introduction to the Bootstrap. Chapman & Hall/CRC, 1993
1993
-
[42]
When the majority is wrong: Modeling annotator dis- agreement for subjective tasks
Eve Fleisig, Rediet Abebe, and Dan Klein. When the majority is wrong: Modeling annotator dis- agreement for subjective tasks. InEMNLP, 2023
2023
-
[43]
Perspectivist approaches to natural language processing: A survey.Language Resources and Evaluation, 59(2), 2025
Simona Frenda, Gavin Abercrombie, Valerio Basile, Alessandro Pedrani, Raffaella Panizzon, Alessandra Teresa Cignarella, Cristina Frieder, and Davide Bernardi. Perspectivist approaches to natural language processing: A survey.Language Resources and Evaluation, 59(2), 2025
2025
-
[44]
Language models scale reliably with over-training and on downstream tasks
Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, et al. Language models scale reliably with over-training and on downstream tasks. InNeurIPS, 2024
2024
-
[45]
Predictability and surprise in large generative models
Deep Ganguli, Danny Hernandez, Liane Lovitt, Nova DasSarma, et al. Predictability and surprise in large generative models. InFAccT, 2022
2022
-
[47]
Scaling Laws for Reward Model Overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization.arXiv preprint arXiv:2210.10760, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
Datasheets for datasets.Communications of the ACM, 64(12):86– 92, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daum´e III, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86– 92, 2021
2021
-
[49]
gar- den of forking paths
Andrew Gelman and Eric Loken. The statistical crisis in science: Data-dependent analysis—a “gar- den of forking paths”.American Scientist, 102(6):460–465, 2014. 24
2014
-
[50]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, et al. A survey on LLM-as-a-judge.arXiv preprint arXiv:2411.15594, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, and Chris Kedzie. LLM-Rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts.arXiv preprint arXiv:2501.00274, 2025
-
[52]
Clara E. Hill. Manual for the hill counselor verbal response category system (revised).Unpublished manuscript, University of Maryland, 1985
1985
-
[53]
Train- ing compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, et al. Train- ing compute-optimal large language models. InNeurIPS, 2022
2022
-
[54]
Holland and Dorothy T
Paul W. Holland and Dorothy T. Thayer. Differential item performance and the Mantel-Haenszel procedure. In Howard Wainer and Henry I. Braun, editors,Test Validity, pages 129–145. Lawrence Erlbaum, 1988
1988
-
[55]
Predicting emergent abilities with infinite resolution evaluation
Shengding Hu, Xin Liu, Xu Han, Xinrong Zhang, Chaoqun He, et al. Predicting emergent abilities with infinite resolution evaluation. InICLR, 2024
2024
-
[56]
Heart: A unified benchmark for humans and llms in emotional support dialogue
Mrinank Iyer, Karan Aggarwal, Sanmi Koyejo, et al. Heart: A unified benchmark for humans and llms in emotional support dialogue. InarXiv preprint arXiv:2601.19922, 2026
-
[57]
LiveCodeBench: Holistic and contamination free eval- uation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contamination free eval- uation of large language models for code. InICLR, 2025
2025
-
[58]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[59]
Rebecca Killick, Paul Fearnhead, and Idris A. Eckley. Optimal detection of changepoints with a linear computational cost.Journal of the American Statistical Association, 107(500):1590–1598, 2012
2012
-
[60]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, et al. Prometheus: Inducing fine-grained evaluation capability in language models. InICLR, 2024
2024
-
[61]
Prometheus 2: An open source language model specialized in evaluating other language models
Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. Prometheus 2: An open source language model specialized in evaluating other language models. InEMNLP, 2024
2024
-
[62]
Prover-verifier games improve legibility of LLM outputs.arXiv preprint arXiv:2407.13692, 2024
Jan Hendrik Kirchner, Yining Chen, Harri Edwards, Jan Leike, Nat McAleese, and Yuri Burda. Prover-verifier games improve legibility of LLM outputs.arXiv preprint arXiv:2407.13692, 2024
-
[63]
Ryan Koo, Minhwa Lee, Vipul Raheja, Jong Inn Park, Zae Myung Kim, and Dongyeop Kang. Bench- marking cognitive biases in large language models as evaluators.arXiv preprint arXiv:2309.17012, 2024
-
[64]
Specification gaming: The flip side of AI ingenuity
Victoria Krakovna, Jonathan Uesato, Vladimir Mikulik, Matthew Rahtz, Tom Everitt, Ramana Ku- mar, Zac Kenton, Jan Leike, and Shane Legg. Specification gaming: The flip side of AI ingenuity. DeepMind Blog, 2020
2020
-
[65]
Computing Krippendorff’s alpha-reliability.Annenberg School for Communi- cation, University of Pennsylvania, Departmental Papers, 2011
Klaus Krippendorff. Computing Krippendorff’s alpha-reliability.Annenberg School for Communi- cation, University of Pennsylvania, Departmental Papers, 2011. 25
2011
-
[66]
Wai-Chung Kwan, Xingshan Zeng, Yuxin Jiang, Yufei Wang, Liangyou Li, Lifeng Shang, Xin Jiang, Qun Liu, and Kam-Fai Wong. MT-Eval: A multi-turn capabilities evaluation benchmark for large language models.arXiv preprint arXiv:2401.16745, 2024
-
[67]
Lalor, Pedro Rodriguez, Jo ˜ao Sedoc, and Jos ´e Hern´andez-Orallo
John P. Lalor, Pedro Rodriguez, Jo ˜ao Sedoc, and Jos ´e Hern´andez-Orallo. Item response theory for natural language processing. InEACL Tutorial Abstracts, 2024
2024
-
[68]
Lalor, Hao Wu, and Hong Yu
John P. Lalor, Hao Wu, and Hong Yu. Building an evaluation scale using item response theory. In EMNLP, pages 648–657, 2016
2016
-
[69]
Lalor, Hao Wu, and Hong Yu
John P. Lalor, Hao Wu, and Hong Yu. Learning latent parameters without human response patterns: Item response theory with artificial crowds. InEMNLP-IJCNLP, 2019
2019
-
[70]
Autobencher: Automated benchmark generation.arXiv preprint arXiv:2407.08351, 2024
Xinyu Li et al. Autobencher: Automated benchmark generation.arXiv preprint arXiv:2407.08351, 2024
-
[71]
LLM-Eval: Unified multi-dimensional automatic evaluation for open-domain conversations with large language models
Yen-Ting Lin and Yun-Nung Chen. LLM-Eval: Unified multi-dimensional automatic evaluation for open-domain conversations with large language models. InNLP4ConvAI Workshop, 2023
2023
-
[72]
Hao Liu et al. Arenabencher: Item-evolution benchmarking via multi-model competition.arXiv preprint arXiv:2510.08569, 2025
-
[73]
Towards emotional support dialog systems
Siyang Liu, Chujie Zheng, Orianna Demasi, Sahand Sabour, Yu Li, Zhou Yu, Yong Jiang, and Minlie Huang. Towards emotional support dialog systems. InACL, 2021
2021
-
[74]
G-Eval: NLG evaluation using GPT-4 with better human alignment
Yang Liu et al. G-Eval: NLG evaluation using GPT-4 with better human alignment. InEMNLP,
-
[75]
Calibrat- ing LLM-based evaluator
Yuxuan Liu, Tianchi Yang, Shaohan Huang, Zihan Zhang, Haizhen Huang, Furu Wei, et al. Calibrat- ing LLM-based evaluator. InLREC-COLING, 2024
2024
-
[76]
Lord and Melvin R
Frederic M. Lord and Melvin R. Novick.Statistical Theories of Mental Test Scores. Addison-Wesley, 1968
1968
-
[77]
Data contamination: From memorization to exploitation
Inbal Magar and Roy Schwartz. Data contamination: From memorization to exploitation. InACL, 2022
2022
-
[78]
Categorizing Variants of Goodhart's Law
David Manheim and Scott Garrabrant. Categorizing variants of Goodhart’s law.arXiv preprint arXiv:1803.04585, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[79]
Statistical aspects of the analysis of data from retrospective studies of disease.Journal of the National Cancer Institute, 22(4):719–748, 1959
Nathan Mantel and William Haenszel. Statistical aspects of the analysis of data from retrospective studies of disease.Journal of the National Cancer Institute, 22(4):719–748, 1959
1959
-
[80]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, et al. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[81]
Model cards for model reporting
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model cards for model reporting. InFAT*, pages 220–229, 2019
2019
-
[82]
Munaf `o, Brian A
Marcus R. Munaf `o, Brian A. Nosek, Dorothy V . M. Bishop, Katherine S. Button, Christopher D. Chambers, Nathalie Percie du Sert, et al. A manifesto for reproducible science.Nature Human Behaviour, 1(1):0021, 2017. 26
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.