When Think-with-Image Meets Safety: What Determines Multimodal Jailbreak Robustness?
Pith reviewed 2026-06-29 13:54 UTC · model grok-4.3
The pith
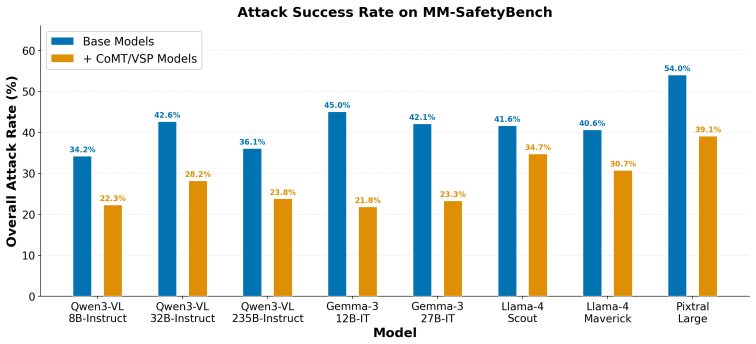
Explicit image-tool interaction in vision-language models reduces multimodal jailbreak success by about 30% on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
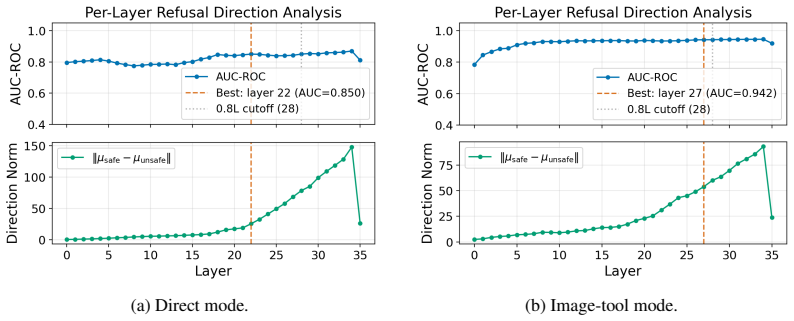
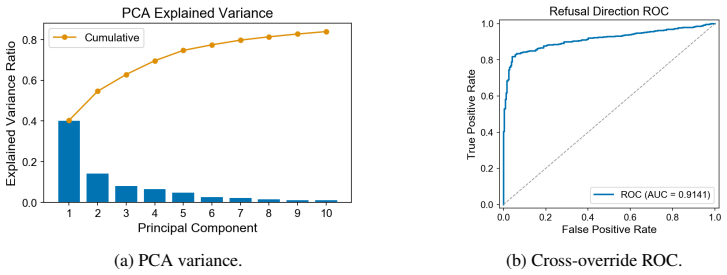
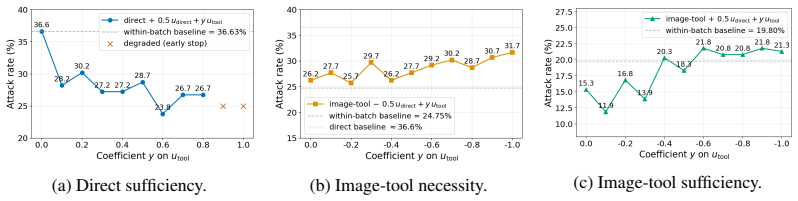
Explicit image-tool interaction yields the lowest attack success rates, reducing jailbreak success by around 30% relative on average across the evaluated models. This lower ASR is not explained by benign returned-image semantics or by the textual image-tool trace alone. The image-tool safety vector framework models image-tool invocation as a residual shift in hidden representations toward a safety-relevant direction. Representation-level analyses and activation interventions support this account.
What carries the argument
The image-tool safety vector framework, which models image-tool invocation as a residual shift in hidden representations toward a safety-relevant direction.
If this is right
- Explicit image-tool interaction improves jailbreak robustness across multiple vision-language models.
- The safety benefit holds even when the returned image is manually overridden or unsafe-looking.
- Text-only prior turn controls do not produce comparable reductions in attack success rates.
- Different think-with-image process designs require pipeline-specific safety evaluation.
Where Pith is reading between the lines
- Model pipelines could insert image-tool steps by default to gain safety margins without extra training data.
- The same representational mechanism might affect other safety properties such as hallucination resistance or bias reduction.
- Extending the controls to additional attack methods and model scales would test whether the shift generalizes.
Load-bearing premise
The lower attack success rate under explicit image-tool interaction is caused by a residual shift in hidden representations toward a safety-relevant direction rather than by properties of the returned image content or the textual trace of the tool call.
What would settle it
An intervention that removes the representational shift (for example by targeted activation patching during image-tool calls) while preserving the interaction itself would eliminate the observed ASR reduction if the account is correct.
Figures

read the original abstract
Think-with-image reasoning is emerging as a new inference paradigm for large vision-language models, but its safety implications remain poorly understood. Existing systems already span multiple process designs, including direct response generation, text-only prior turn, visual-state manipulation, and explicit external image-tool invocation. In this paper, we ask which of these evaluated paradigms improves multimodal jailbreak robustness, and why. Across multiple vision-language models, explicit image-tool interaction yields the lowest attack success rates in our experiments, reducing jailbreak success by around 30% relative on average across the evaluated models. This finding is initially surprising: ASR remains low even when the returned image-tool output is manually overridden or itself unsafe-looking, but returns near direct-answering levels under text-only prior turn controls. These results indicate that the lower ASR is not explained by benign returned-image semantics or by the textual image-tool trace alone. To explain the pattern, we introduce an image-tool safety vector framework that models image-tool invocation as a residual shift in hidden representations toward a safety-relevant direction. Representation-level analyses and activation interventions support this account. Overall, our results suggest that explicit image-tool interaction is a promising design pattern for improving jailbreak robustness, while also motivating pipeline-specific safety evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines the safety implications of different think-with-image paradigms in vision-language models for multimodal jailbreak robustness. It compares direct response generation, text-only prior turn, visual-state manipulation, and explicit external image-tool invocation across multiple models. The central claim is that explicit image-tool interaction produces the lowest attack success rates, with an average relative reduction of around 30%. Controls (manual image override, unsafe-looking outputs, text-only baseline) indicate the effect is not due to returned image semantics or textual traces alone. The authors introduce an image-tool safety vector framework, supported by representation analyses and activation interventions, to explain the pattern as a residual shift in hidden representations toward a safety-relevant direction.
Significance. If the empirical pattern and mechanistic account hold, the work identifies explicit image-tool interaction as a design pattern that can improve jailbreak robustness in multimodal systems independently of content filtering. The safety-vector framework offers a representation-level explanation that could inform targeted interventions. Strengths include the use of multiple controls to isolate the mechanism and the combination of behavioral results with representation analyses and activation interventions, providing convergent evidence rather than relying on a single method.
major comments (3)
- [Abstract] Abstract: The central claim of an approximately 30% relative reduction in jailbreak success is presented without baseline ASR values, the number or identities of evaluated models, attack methods, dataset sizes, or any statistical tests. These details are load-bearing for assessing the magnitude, reliability, and generalizability of the finding.
- [Abstract / Results] Controls description: The abstract states that ASR remains low under manual image override and unsafe-looking outputs but returns to direct-answering levels under text-only prior-turn controls. Without the specific ASR numbers for each control condition and the direct-answering baseline, it is not possible to verify how completely the effect is isolated to the tool invocation itself.
- [Safety-vector framework] Safety-vector framework and activation interventions: The framework is introduced to model image-tool invocation as a residual shift toward a safety-relevant direction, with representation analyses and interventions cited as support. A concrete test of the causal account would be to report whether the magnitude of the representational shift predicts the size of the ASR reduction across models or conditions; this correlation or intervention effect size is not provided.
minor comments (2)
- [Introduction] Introduction: The term 'think-with-image' and the four process designs should be defined with a brief example or diagram at first mention to aid readers unfamiliar with the paradigm.
- [Abstract] Notation: ASR is used repeatedly before any expansion; ensure the first occurrence includes the full term 'attack success rate'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the manuscript accordingly to improve clarity and strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of an approximately 30% relative reduction in jailbreak success is presented without baseline ASR values, the number or identities of evaluated models, attack methods, dataset sizes, or any statistical tests. These details are load-bearing for assessing the magnitude, reliability, and generalizability of the finding.
Authors: We agree that the abstract would benefit from these specifics to allow better assessment of the claims. In the revised version, we will expand the abstract to report baseline ASR values, list the evaluated models and attack methods, specify dataset sizes, and include relevant statistical test results. revision: yes
-
Referee: [Abstract / Results] Controls description: The abstract states that ASR remains low under manual image override and unsafe-looking outputs but returns to direct-answering levels under text-only prior-turn controls. Without the specific ASR numbers for each control condition and the direct-answering baseline, it is not possible to verify how completely the effect is isolated to the tool invocation itself.
Authors: We acknowledge the value of including numerical values for the controls in the abstract itself. While the full results section contains these ASR numbers with tables, we will add the specific values for the direct-answering baseline and all control conditions to the abstract in the revision. revision: yes
-
Referee: [Safety-vector framework] Safety-vector framework and activation interventions: The framework is introduced to model image-tool invocation as a residual shift toward a safety-relevant direction, with representation analyses and interventions cited as support. A concrete test of the causal account would be to report whether the magnitude of the representational shift predicts the size of the ASR reduction across models or conditions; this correlation or intervention effect size is not provided.
Authors: This suggestion would provide a useful additional test of the framework. Our current work includes representation analyses and interventions but does not report the cross-model correlation between shift magnitude and ASR reduction. We will compute and include this correlation (along with intervention effect sizes) from our existing data in the revised manuscript. revision: partial
Circularity Check
No significant circularity; derivation relies on empirical controls and analyses
full rationale
The abstract and provided text describe experimental results across models showing lower ASR for explicit image-tool interaction, with controls (manual override, unsafe outputs, text-only baselines) ruling out image semantics or textual trace as explanations. The safety-vector framework is introduced post-observation and supported by separate representation analyses and interventions. No equations, self-citations, fitted parameters renamed as predictions, or self-definitional steps are present that reduce claims to inputs by construction. The chain is self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pravesh Agrawal, Szymon Antoniak, Emma Bou Hanna, Baptiste Bout, Devendra Chaplot, Jessica Chudnovsky, Diogo Costa, et al. Pixtral 12B.arXiv preprint arXiv:2410.07073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
10 Carlos Hinojosa, Clemens Grange, and Bernard Ghanem. SA VeS: Steering safety judgments in vision-language models via semantic cues.arXiv preprint arXiv:2603.19092,
-
[5]
Weidi Luo, Siyuan Ma, Xiaogeng Liu, Xiaoyu Guo, and Chaowei Xiao. JailBreakV: A benchmark for assessing the robustness of MultiModal large language models against jailbreak attacks.arXiv preprint arXiv:2404.03027,
-
[6]
Jailbreaks on vision language model via multimodal reasoning
Aarush Noheria and Yuguang Yao. Jailbreaks on vision language model via multimodal reasoning. arXiv preprint arXiv:2601.22398,
-
[7]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world.arXiv preprint arXiv:2306.14824,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
11 Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, Linjie Li, Yu Cheng, Heng Ji, Junxian He, and Yi R. Fung. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918, 2025a. Zhaochen Su et al. OpenThinkIMG: Learning to thin...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Vi- sual ChatGPT: Talking, drawing and editing with visual foundation models.arXiv preprint arXiv:2303.04671,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in GPT-4V.arXiv preprint arXiv:2310.11441, 2023a. Jiaxi Yang, Shicheng Liu, Yuchen Yang, and Dongwon Lee. Steering to say no: Configurable refusal via activation steering in vision language models.arXiv preprint arXiv...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. MM-ReAct: Prompting ChatGPT for multimodal reasoning and action.arXiv preprint arXiv:2303.11381, 2023b. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reason...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL 2024,
2024
-
[13]
Wei Zhao, Zhe Li, Peixin Zhang, and Jun Sun. ClawGuard: A runtime security framework for tool-augmented LLM agents against indirect prompt injection.arXiv preprint arXiv:2604.11790,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Each instance pairs a harmful question with an image generated by a typographic attack or by Stable Diffusion [Rombach et al., 2022]
13 Appendix A MM-SafetyBench Category Composition MM-SafetyBench [Liu et al., 2024] organizes adversarial image-text pairs into 13 safety-sensitive categories. Each instance pairs a harmful question with an image generated by a typographic attack or by Stable Diffusion [Rombach et al., 2022]. To keep think-with-image evaluation tractable, we draw a 202-qu...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.