Beyond Binary: Sim-to-Real Dexterous Manipulation with Physics-Grounded Contact Representation
Pith reviewed 2026-06-29 11:27 UTC · model grok-4.3
The pith
Center-of-Pressure representation enables zero-shot sim-to-real transfer for contact-rich manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
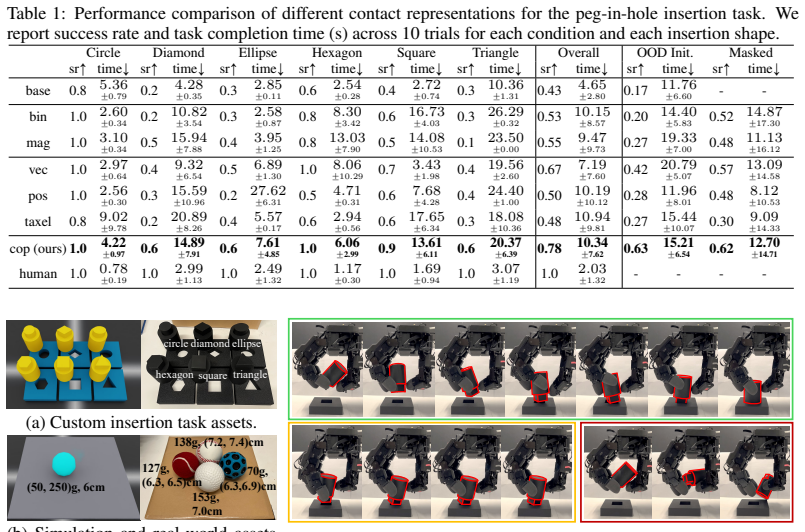
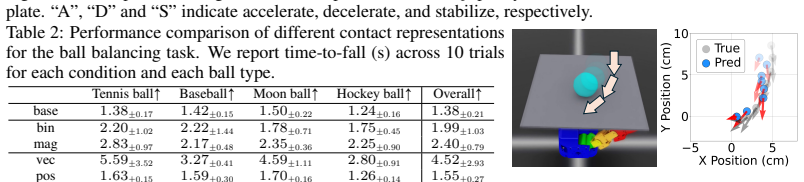
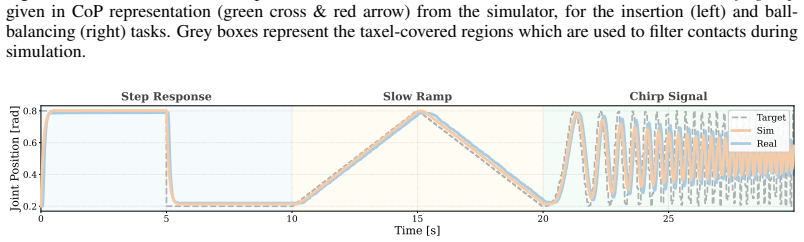
The central discovery is that conditioning reinforcement learning policies on Center-of-Pressure signals from tactile sensors allows zero-shot sim-to-real transfer on challenging contact-rich tasks. This representation preserves dense contact information in a form that bridges the simulation-reality gap better than coarser alternatives. A supporting calibration technique estimates taxel orientations via differentiable dynamics without requiring force measurements. Policies using this input outperform binary-contact and raw-taxel baselines on peg-in-hole and ball balancing with a multi-fingered hand, and appear to learn representations of object mass as a side effect of successful control.
What carries the argument
Center-of-Pressure (CoP), the weighted average position of contact forces across sensor taxels, computed from the pressure distribution.
If this is right
- Policies achieve zero-shot transfer to real hardware on two contact-rich tasks without fine-tuning.
- CoP outperforms both binary-contact and raw-taxel representations in transfer success rate.
- Policies encode task-relevant physical properties such as object mass as an emergent byproduct of control.
- The differentiable calibration enables taxel orientation estimation without force ground truth.
Where Pith is reading between the lines
- The calibration approach may allow new tactile hardware to be used in simulation without extensive real force testing.
- Similar physics-grounded features could be explored for other sensory modalities in sim-to-real settings.
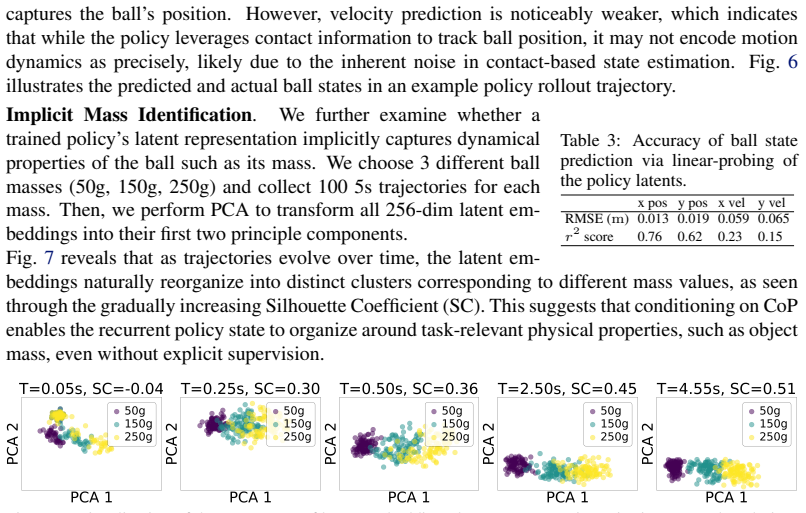
- Emergent encoding of mass suggests the representation may support adaptation to varying object properties during deployment.
Load-bearing premise
The Center-of-Pressure values computed in simulation accurately match the physical behavior of real tactile sensors after the differentiable-dynamics calibration, without requiring ground-truth force measurements for validation.
What would settle it
Direct measurement of CoP values on the real sensor versus the simulated model for the same contact events would show large mismatch if the representation fails to transfer.
Figures








read the original abstract
A primary bottleneck in contact-rich manipulation is the difficulty of collecting real-world data. Sim-to-real reinforcement learning offers a scalable alternative, but the simulation-reality gap prevents information-dense modalities like touch from being effectively used. Existing sim-to-real methods often mitigate this gap by simplifying tactile data into coarse low-dimensional features -- sacrificing the richness required for complex manipulation. In this work, we introduce Center-of-Pressure (CoP), an effective tactile representation grounded in physical principles that preserves dense contact information while maintaining robustness for sim-to-real transfer. To support this representation, we propose a sensor calibration scheme based on differentiable dynamics, enabling the estimation of taxel orientations without requiring ground-truth force measurements. We evaluate CoP on two blind, challenging contact-rich manipulation tasks: peg-in-hole insertion and ball balancing. Across both tasks, policies conditioned on CoP achieve zero-shot sim-to-real transfer on a multi-fingered hand, and outperform both coarse binary-contact and raw-taxel baselines. Analysis of learned policy states further suggests that CoP-conditioned policies encode task-relevant physical properties, such as object mass, as an emergent byproduct of control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Center-of-Pressure (CoP) as a physics-grounded tactile representation that preserves dense contact information for sim-to-real reinforcement learning in dexterous manipulation. It proposes a differentiable-dynamics calibration scheme to estimate taxel orientations without ground-truth force measurements. The method is evaluated on two blind contact-rich tasks (peg-in-hole insertion and ball balancing) using a multi-fingered hand, claiming zero-shot sim-to-real transfer and outperformance over coarse binary-contact and raw-taxel baselines. Policy analysis is said to show emergent encoding of task-relevant properties such as object mass.
Significance. If the central claims hold after validation, the work would provide a practical, physics-derived alternative to simplified tactile features that still supports information-rich contact-rich policies in simulation. The calibration approach's avoidance of force-torque ground truth would be a useful engineering contribution for scaling tactile RL.
major comments (2)
- [Abstract] Abstract: The sensor calibration scheme is presented as enabling CoP computation via differentiable dynamics without ground-truth force measurements, yet no quantitative validation (force-torque sensor comparisons, controlled indentation tests, or error metrics on contact location/pressure) is reported to confirm fidelity to real taxels. This directly underpins the zero-shot transfer claim; residual mismatch would falsify the headline result.
- [Abstract] Abstract: Outperformance on the two tasks is asserted without any quantitative results, error bars, baseline implementation details, or ablation studies on the calibration step. This prevents assessment of whether the reported gains are statistically meaningful or sensitive to the calibration procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the calibration validation and the need for quantitative results. We address each major comment below and will revise the manuscript to incorporate additional details and metrics.
read point-by-point responses
-
Referee: [Abstract] Abstract: The sensor calibration scheme is presented as enabling CoP computation via differentiable dynamics without ground-truth force measurements, yet no quantitative validation (force-torque sensor comparisons, controlled indentation tests, or error metrics on contact location/pressure) is reported to confirm fidelity to real taxels. This directly underpins the zero-shot transfer claim; residual mismatch would falsify the headline result.
Authors: We agree that explicit quantitative validation of the calibration would strengthen the zero-shot transfer claims. The current manuscript relies on end-task performance as indirect evidence of calibration fidelity, but we will add direct comparisons against force-torque sensor readings and controlled indentation error metrics in the revised version. revision: yes
-
Referee: [Abstract] Abstract: Outperformance on the two tasks is asserted without any quantitative results, error bars, baseline implementation details, or ablation studies on the calibration step. This prevents assessment of whether the reported gains are statistically meaningful or sensitive to the calibration procedure.
Authors: We will include quantitative success rates with error bars, full baseline implementation details, and an ablation study isolating the calibration step in the revised manuscript to enable statistical evaluation of the performance gains. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The abstract and provided text present CoP as a physics-grounded tactile representation derived from physical principles, supported by a differentiable-dynamics calibration scheme for taxel orientations. Performance claims rest on empirical zero-shot sim-to-real evaluation across peg-in-hole and ball-balancing tasks, with explicit comparisons to binary-contact and raw-taxel baselines. No equations, self-citations, or derivations are exhibited that reduce any claimed result to its inputs by construction, nor is any fitted parameter renamed as a prediction. The central results are externally falsifiable via task success rates and remain independent of internal self-referential definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Cheng, J
X. Cheng, J. Li, S. Yang, G. Yang, and X. Wang. Open-television: Teleoperation with im- mersive active visual feedback. InConference on Robot Learning, pages 2729–2749. PMLR, 2025
2025
-
[3]
Zhang, C
D. Zhang, C. Yuan, C. Wen, H. Zhang, J. Zhao, and Y . Gao. Kinedex: Learning tactile- informed visuomotor policies via kinesthetic teaching for dexterous manipulation. InConfer- ence on Robot Learning, pages 4123–4138. PMLR, 2025
2025
-
[4]
Solving Rubik's Cube with a Robot Hand
I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, R. Ribas, et al. Solving rubik’s cube with a robot hand.arXiv preprint arXiv:1910.07113, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[5]
Handa, A
A. Handa, A. Allshire, V . Makoviychuk, A. Petrenko, R. Singh, J. Liu, D. Makoviichuk, K. Van Wyk, A. Zhurkevich, B. Sundaralingam, et al. Dextreme: Transfer of agile in-hand manipulation from simulation to reality. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5977–5984. IEEE, 2023
2023
-
[6]
T. Chen, J. Xu, and P. Agrawal. A system for general in-hand object re-orientation. InConfer- ence on Robot Learning, pages 297–307. PMLR, 2022
2022
-
[7]
Lin, Z.-H
T. Lin, Z.-H. Yin, H. Qi, P. Abbeel, and J. Malik. Twisting lids off with two hands. In Conference on Robot Learning, pages 5220–5235. PMLR, 2024
2024
-
[8]
T. Lin, K. Sachdev, L. Fan, J. Malik, and Y . Zhu. Sim-to-real reinforcement learning for vision-based dexterous manipulation on humanoids. InConference on Robot Learning, pages 4926–4940. PMLR, 2025
2025
-
[9]
Miller, T
E. Miller, T. McInroe, D. Abel, O. Mac Aodha, and S. Vijayakumar. Enhancing tactile-based reinforcement learning for robotic control. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[10]
Z.-H. Yin, B. Huang, Y . Qin, Q. Chen, and X. Wang. Rotating without seeing: Towards in-hand dexterity through touch. InRobotics: Science and Systems, 2023
2023
-
[11]
H. Qi, B. Yi, S. Suresh, M. Lambeta, Y . Ma, R. Calandra, and J. Malik. General in-hand object rotation with vision and touch. InConference on Robot Learning, pages 2549–2564. PMLR, 2023
2023
-
[12]
Higuera, A
C. Higuera, A. Sharma, T. Fan, C. K. Bodduluri, B. Boots, M. Kaess, M. Lambeta, T. Wu, Z. Liu, F. R. Hogan, et al. Tactile beyond pixels: Multisensory touch representations for robot manipulation. InConference on Robot Learning, pages 105–123. PMLR, 2025
2025
-
[13]
Sharma, C
A. Sharma, C. Higuera, C. K. Bodduluri, Z. Liu, T. Fan, T. Hellebrekers, M. Lambeta, B. Boots, M. Kaess, T. Wu, et al. Self-supervised perception for tactile skin covered dexterous hands. In Conference on Robot Learning, pages 2311–2328. PMLR, 2025
2025
-
[14]
J. Yin, H. Qi, J. Malik, J. Pikul, M. Yim, and T. Hellebrekers. Learning in-hand translation using tactile skin with shear and normal force sensing. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 5850–5856. IEEE, 2025
2025
-
[15]
R. Chen, M. Mukadam, M. Kaess, T. Wu, F. R. Hogan, J. Malik, and A. Sharma. Ptld: Sim-to-real privileged tactile latent distillation for dexterous manipulation.arXiv preprint arXiv:2603.04531, 2026. 9
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Y . Chen, M. Van der Merwe, A. Sipos, and N. Fazeli. Visuo-tactile transformers for manipula- tion. InConference on Robot Learning, pages 2026–2040. PMLR, 2023
2026
-
[17]
L. Heng, H. Geng, K. Zhang, P. Abbeel, and J. Malik. Vitacformer: Learning cross-modal representation for visuo-tactile dexterous manipulation. InRobotics: Science and Systems, 2026
2026
-
[18]
Sferrazza, Y
C. Sferrazza, Y . Seo, H. Liu, Y . Lee, and P. Abbeel. The power of the senses: Generalizable manipulation from vision and touch through masked multimodal learning. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9698–9705. IEEE, 2024
2024
-
[19]
H. Qi, A. Kumar, R. Calandra, Y . Ma, and J. Malik. In-hand object rotation via rapid motor adaptation. InConference on Robot Learning, pages 1722–1732. PMLR, 2023
2023
-
[20]
T. Chen, M. Tippur, S. Wu, V . Kumar, E. Adelson, and P. Agrawal. Visual dexterity: In-hand reorientation of novel and complex object shapes.Science Robotics, 8(84):eadc9244, 2023
2023
-
[21]
M. Yang, A. Church, Y . Lin, C. J. Ford, H. Li, E. Psomopoulou, D. A. Barton, N. F. Lepora, et al. Anyrotate: Gravity-invariant in-hand object rotation with sim-to-real touch. InConfer- ence on Robot Learning, pages 4727–4747. PMLR, 2025
2025
-
[22]
E. Hsieh, W.-H. Hsieh, Y .-J. Wang, T. Lin, J. Malik, K. Sreenath, and H. Qi. Learning dexterous manipulation skills from imperfect simulations.arXiv preprint arXiv:2512.02011, 2025
-
[23]
T. Lin, Y . Zhang, Q. Li, H. Qi, B. Yi, S. Levine, and J. Malik. Learning visuotactile skills with two multifingered hands. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 5637–5643. IEEE, 2025
2025
-
[24]
P. Wu, Y . Shentu, Z. Yi, X. Lin, and P. Abbeel. Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12156–12163. IEEE, 2024
2024
-
[25]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems, 2023
2023
-
[26]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
- [27]
-
[28]
T. Z. Zhao, J. Tompson, D. Driess, P. Florence, S. K. S. Ghasemipour, C. Finn, and A. Wahid. Aloha unleashed: A simple recipe for robot dexterity. InConference on Robot Learning, pages 1910–1924. PMLR, 2025
1910
-
[29]
Levine, P
S. Levine, P. Pastor, A. Krizhevsky, J. Ibarz, and D. Quillen. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection.The International Journal of Robotics Research, 37(4-5):421–436, 2018
2018
-
[30]
F. Lin, Y . Hu, P. Sheng, C. Wen, J. You, and Y . Gao. Data scaling laws in imitation learning for robotic manipulation. InThe Thirteenth International Conference on Learning Represen- tations, 2024
2024
-
[31]
Y . Chen, C. Wang, L. Fei-Fei, and K. Liu. Sequential dexterity: Chaining dexterous policies for long-horizon manipulation. InConference on Robot Learning, pages 3809–3829. PMLR, 2023. 10
2023
- [32]
-
[33]
Isaac sim
NVIDIA. Isaac sim. URLhttps://github.com/isaac-sim/IsaacSim
-
[34]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–
2012
-
[35]
T. P. Tomo, W. K. Wong, A. Schmitz, H. Kristanto, A. Sarazin, L. Jamone, S. Somlor, and S. Sugano. A modular, distributed, soft, 3-axis sensor system for robot hands. In2016 IEEE- RAS 16th International Conference on Humanoid Robots (Humanoids), pages 454–460. IEEE, 2016
2016
-
[36]
H. Lee, Y . Kim, V . M. Staven, and C. Sloth. Trajectory optimization for in-hand manipulation with tactile force control. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 21773–21779. IEEE, 2025
2025
-
[37]
D. Shepard. A two-dimensional interpolation function for irregularly-spaced data. InProceed- ings of the 1968 23rd ACM National Conference, pages 517–524, 1968
1968
-
[38]
A. R. Geist, J. Frey, M. Zhobro, A. Levina, and G. Martius. Learning with 3d rotations, a hitchhiker’s guide to so (3). InInternational Conference on Machine Learning, pages 15331– 15350. PMLR, 2024
2024
-
[39]
Huang, H
T. Huang, H. Liu, and D. Chetwynd. Generalized jacobian analysis of lower mobility manipu- lators.Mechanism and Machine Theory, 46(6):831–844, 2011
2011
-
[40]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Munoz, X. Yao, R. Zurbr ¨ugg, N. Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi- modal robot learning.arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [41]
-
[42]
Rsl-rl: A learning library for robotics research,
C. Schwarke, M. Mittal, N. Rudin, D. Hoeller, and M. Hutter. Rsl-rl: A learning library for robotics research.arXiv preprint arXiv:2509.10771, 2025
-
[43]
L. Su, Z. Peng, R. Ren, S. Mao, J. Du, K. Zhang, and X. Zhu. Tacmap: Bridging the tactile sim- to-real gap via geometry-consistent penetration depth map.arXiv preprint arXiv:2602.21625, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
B. B. de Langhe, S. Puntoni, and R. P. Larrick. Linear thinking in a nonlinear world.Harvard Business Review, 95(3):130–139, 2017
2017
-
[45]
Tsutsui, K
K. Tsutsui, K. Fujii, K. Kudo, and K. Takeda. Flexible prediction of opponent motion with in- ternal representation in interception behavior.Biological Cybernetics, 115(5):473–485, 2021
2021
-
[46]
Zhong, T
S. Zhong, T. Power, A. Gupta, and P. Mitrano. PyTorch Kinematics, Feb. 2024
2024
-
[47]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[48]
Freud, Y
K. Freud, Y . Lin, and N. F. Lepora. Simshear: Sim-to-real shear-based tactile servoing. In9th Annual Conference on Robot Learning, 2025
2025
- [49]
-
[50]
Chelly, A
E. Chelly, A. Cherubini, P. Fraisse, F. B. Amar, and M. Khoramshahi. Tactile-based force esti- mation for interaction control with robot fingers. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 15800–15807. IEEE, 2025
2025
-
[51]
regularizer
Y . Kim, J. Kim, A. H. Li, A. D. Ames, and C. Sloth. Robust adaptive safe robotic grasping with tactile sensing. In2025 European Control Conference (ECC), pages 2531–2538. IEEE, 2025. 12 Appendix A Taxel Orientation Learning - Implementation & Training We implement the forward pass calculations based on [46] which provides differentiable imple- mentations...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.