Beyond Recall: Behavioral Specification as an Interpretive Layer for AI Personalization
Pith reviewed 2026-06-29 12:44 UTC · model grok-4.3
The pith
A behavioral specification compresses personal data into interpretive patterns that raise AI representational accuracy beyond raw corpus or facts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the Behavioral Specification, when served as context, increases representational accuracy on held-out behavioral predictions scored by a 5-judge LLM panel, outperforming or matching full raw corpora, extracted facts, and commercial memory systems while using far less context; the lift occurs across subjects and is largest where pretraining baselines are lowest, with particular strength on interpretation tasks.
What carries the argument
The Behavioral Specification, which compresses autobiographical data into interpretive patterns for use as model context.
If this is right
- The specification lifts subjects toward a common predictive level regardless of pretraining baseline.
- The largest absolute gains occur on interpretation-required questions.
- On recall-required questions the layer can interfere rather than help.
- Representational accuracy is distinct from recall and makes human-AI alignment testable.
Where Pith is reading between the lines
- The approach could extend to non-text personal data sources such as interaction logs or preference signals.
- Hybrid systems might combine the specification with selective raw fact retrieval for recall-heavy tasks.
- Users whose backgrounds are sparsely represented in pretraining data would see the largest practical benefit.
Load-bearing premise
The 5-judge LLM panel is calibrated and provides reliable, unbiased scores for held-out behavioral predictions that validly measure representational accuracy.
What would settle it
Re-running the held-out behavioral prediction evaluations with human judges instead of the LLM panel and observing no accuracy improvement or continued hedging would falsify the claim.
Figures

read the original abstract
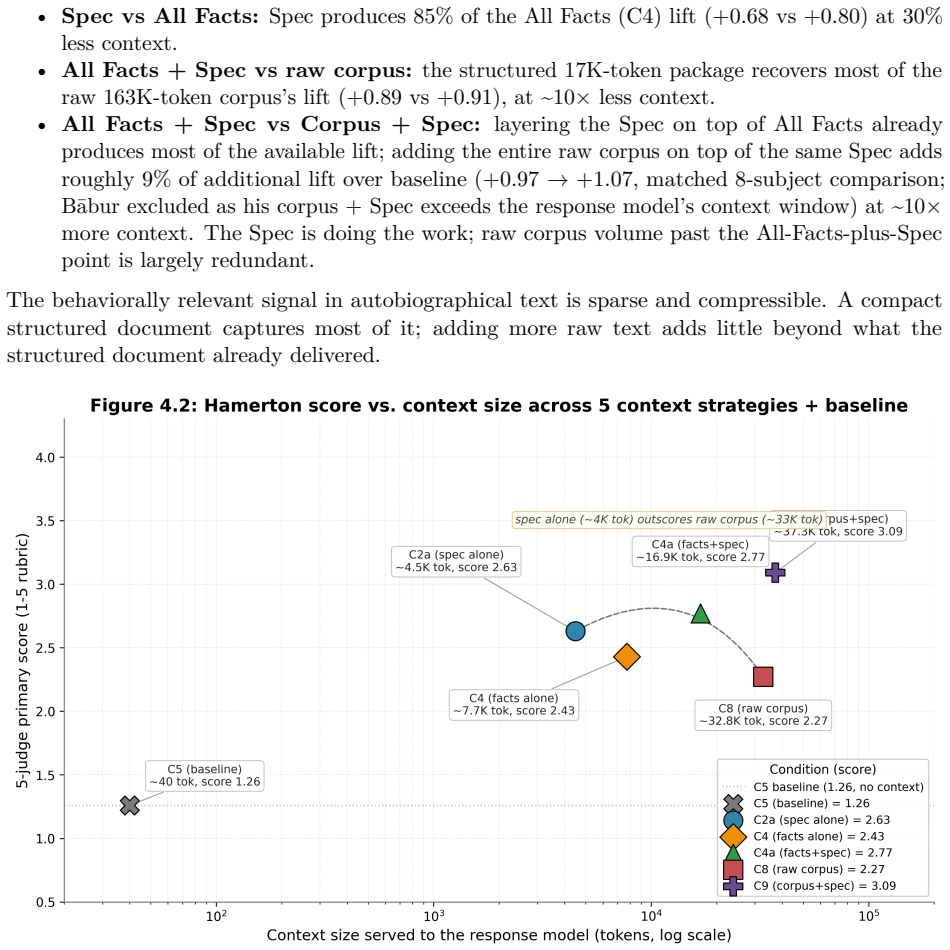
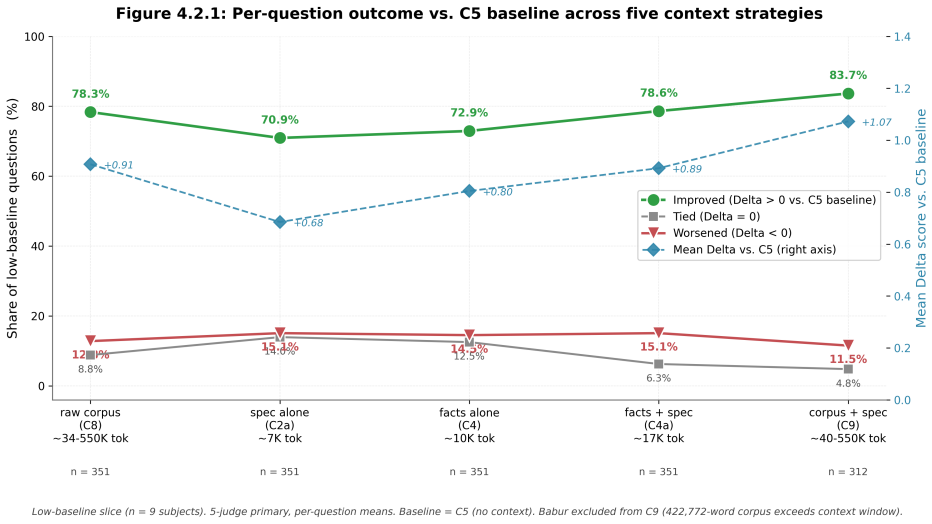
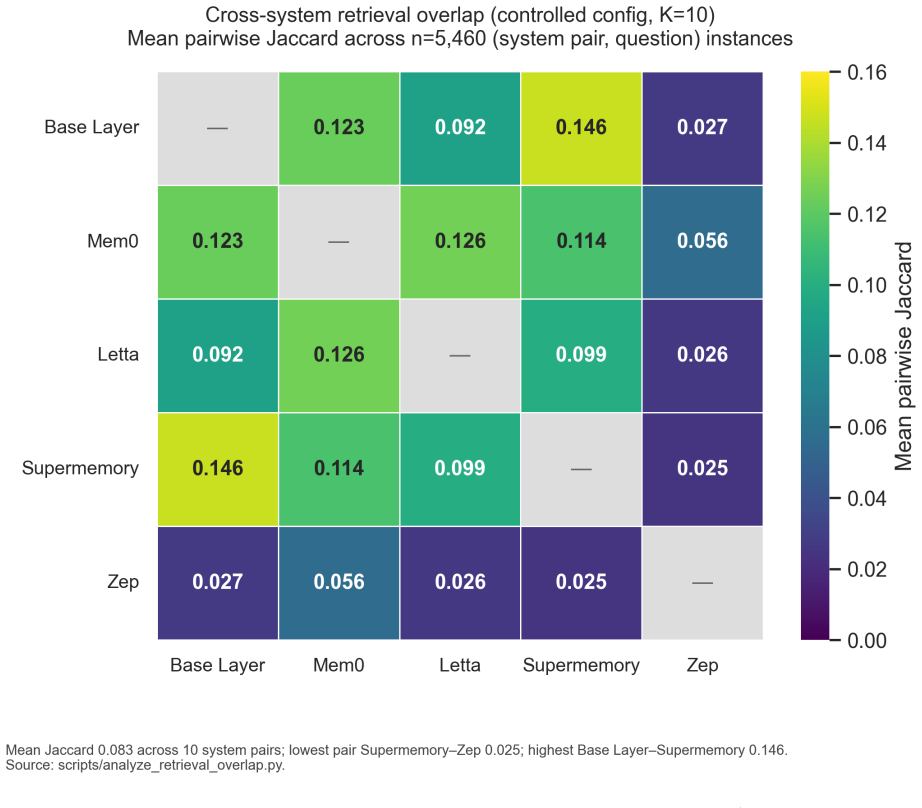
If an AI agent makes decisions on a person's behalf, those decisions must align with its user. We introduce representational accuracy to measure how faithfully a system captures a person's interpretation. An interpretive layer is operationalized as a Behavioral Specification. Our reference implementation aggressively compresses a person's data into interpretive patterns, served as context to a language model. We evaluate the Specification on a prototype benchmark of held-out behavioral predictions scored by a calibrated 5-judge LLM panel. We test it independently and in composition with a range of context conditions: full raw corpus, full extracted facts, and four commercial memory systems (Mem0, Letta, Supermemory, Zep). Across 14 public-domain autobiographical corpora, the Specification lifts representational accuracy in aggregate and nearly eliminates model hedging. It recovers most of what the raw corpus delivers, at ~25x less context cost. The Specification lifts subjects toward a common predictive level regardless of pretraining baseline; the lift in absolute points is therefore largest where the baseline is lowest, suggesting the population of relevance is anyone not adequately represented in pretraining. Lift is greatest on interpretation-required questions, where providing an interpretive layer enables model behavior that extracted facts or raw corpus do not. Conversely, on recall-required questions, this layer can interfere rather than help. We conclude that representational accuracy is distinct from recall and that human-AI alignment is dependent on how accurately the user is represented. Representational accuracy makes that alignment testable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 'representational accuracy' as a metric for how faithfully AI systems capture a user's interpretive framework for decision-making. It introduces the 'Behavioral Specification' as a compressed interpretive layer extracted from personal autobiographical data, which is provided as context to LLMs. The evaluation involves 14 public-domain autobiographical corpora, where the Specification is tested against full raw corpus, extracted facts, and commercial memory systems (Mem0, Letta, Supermemory, Zep) using held-out behavioral predictions scored by a calibrated 5-judge LLM panel. The paper claims that the Specification improves aggregate representational accuracy, nearly eliminates hedging, recovers most raw-corpus performance at approximately 25x lower context cost, and equalizes predictive performance across different model baselines, with greater benefits on interpretation-required questions.
Significance. If the LLM-judge based evaluation is shown to be reliable and unbiased, this work could significantly advance the field of AI personalization by shifting focus from mere recall of facts to accurate representation of user interpretations. The compression efficiency and the finding that it helps under-represented users are potentially impactful. The distinction between recall and interpretation is a useful conceptual contribution, and the use of multiple corpora provides some breadth. However, the lack of details on the evaluation protocol currently limits the strength of these claims.
major comments (3)
- [Abstract] The description of the evaluation relies on a 'calibrated 5-judge LLM panel' scoring held-out behavioral predictions, yet no details are given on the calibration procedure, inter-judge agreement, or any human validation set. This is load-bearing for the central claim as all quantitative results (lifts in representational accuracy, hedging reduction, comparisons to Mem0/Letta) depend on the reliability of these scores.
- [Evaluation] The construction of the prototype benchmark, including how behavioral predictions are generated, how 'interpretation-required' questions are distinguished from 'recall-required', and any statistical tests for the reported aggregate lifts, is not described. Without this, it is not possible to determine if the data supports the claims of recovering most raw-corpus performance at 25x compression.
- [Results and Discussion] The potential for circularity in using LLM judges to evaluate LLM-based systems is not addressed; if the judges share architecture or training data with the evaluated models, the measured lifts may reflect internal consistency rather than true representational accuracy. Explicit disclosure of judge models and bias controls are needed.
minor comments (2)
- [Abstract] The abstract introduces 'representational accuracy' and 'Behavioral Specification' as new terms; providing a brief formal definition or reference to their operationalization in the main text would improve accessibility.
- [Abstract] The claim of '~25x less context cost' would benefit from specifying the exact context lengths measured (e.g., tokens in Specification vs raw corpus) to allow replication.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for improving the clarity and rigor of our evaluation protocol. We address each major comment below, indicating the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] The description of the evaluation relies on a 'calibrated 5-judge LLM panel' scoring held-out behavioral predictions, yet no details are given on the calibration procedure, inter-judge agreement, or any human validation set. This is load-bearing for the central claim as all quantitative results (lifts in representational accuracy, hedging reduction, comparisons to Mem0/Letta) depend on the reliability of these scores.
Authors: We agree that the lack of details on the LLM judge panel calibration limits the interpretability of our results. In the revised manuscript, we will add a dedicated subsection under Evaluation describing the full calibration procedure, the human validation set (including its size and annotation protocol), inter-judge agreement metrics (e.g., Fleiss' kappa), and how calibration was performed to align LLM scores with human judgments. This will directly support the reliability of the reported lifts and comparisons. revision: yes
-
Referee: [Evaluation] The construction of the prototype benchmark, including how behavioral predictions are generated, how 'interpretation-required' questions are distinguished from 'recall-required', and any statistical tests for the reported aggregate lifts, is not described. Without this, it is not possible to determine if the data supports the claims of recovering most raw-corpus performance at 25x compression.
Authors: The referee correctly identifies that these methodological details are missing from the current draft. We will revise the Evaluation section to include: (1) the exact procedure for generating held-out behavioral predictions from each corpus, (2) the decision criteria and examples used to classify questions as interpretation-required versus recall-required (with inter-rater reliability if multiple annotators were involved), and (3) the statistical tests applied (including p-values, confidence intervals, and effect sizes) for the aggregate lifts and the 25x compression claim. These additions will allow readers to evaluate the strength of the evidence. revision: yes
-
Referee: [Results and Discussion] The potential for circularity in using LLM judges to evaluate LLM-based systems is not addressed; if the judges share architecture or training data with the evaluated models, the measured lifts may reflect internal consistency rather than true representational accuracy. Explicit disclosure of judge models and bias controls are needed.
Authors: We acknowledge the validity of this concern about potential circularity and bias. In the revision, we will expand the Results and Discussion sections to explicitly name the judge models (with architecture and training details where available), describe any overlaps with the evaluated systems, and detail bias controls such as model diversity, human cross-validation, and blinding procedures. We will also add a limitations paragraph discussing how these measures reduce the risk that lifts reflect internal consistency rather than representational accuracy. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces representational accuracy as a new metric, operationalizes it via Behavioral Specification, and evaluates via held-out behavioral predictions scored by a 5-judge LLM panel. No equations, parameter fits, or derivations are described that reduce by construction to the inputs. No self-citations, uniqueness theorems, or ansatzes are referenced in the provided text. The evaluation is presented as an independent benchmark against raw corpus, facts, and commercial systems. This matches the default case of a self-contained presentation against external benchmarks with no load-bearing reductions to the paper's own fitted values or definitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- compression aggressiveness
axioms (1)
- domain assumption A calibrated 5-judge LLM panel can reliably score held-out behavioral predictions as a proxy for representational accuracy
invented entities (2)
-
representational accuracy
no independent evidence
-
Behavioral Specification
no independent evidence
Reference graph
Works this paper leans on
-
[1]
F. C. Bartlett. Remembering: A Study in Experimental and Social Psychology. Cambridge University Press, 1932
1932
-
[2]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. Persona vectors: Monitoring and controlling character traits in language models. arXiv preprint arXiv:2507.21509, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara et al. Mem0: Building production-ready AI agents with scalable long-term memory. arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. In NIPS Deep Learning and Representation Learning Workshop , 2015. arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
Interaction context often increases sycophancy in LLMs
Sahaj Jain et al. Interaction context often increases sycophancy in LLMs . arXiv preprint arXiv:2509.12517, 2025
-
[6]
Bowen Jiang et al. Know me, respond to me: Benchmarking LLMs for dynamic user profiling and personalized responses at scale. In Conference on Language Modeling ( COLM ) 2025 , 2025. arXiv:2504.14225
-
[7]
The assistant axis: Situating and stabilizing the default persona of language models
Chris Lu et al. The assistant axis: Situating and stabilizing the default persona of language models. arXiv preprint arXiv:2601.10387, 2026
-
[8]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana et al. Evaluating very long-term conversational memory of LLM agents. In Annual Meeting of the Association for Computational Linguistics ( ACL ) 2024 , 2024. arXiv:2402.17753
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
MemGPT: Towards LLMs as Operating Systems
Charles Packer et al. MemGPT : Towards LLMs as operating systems. arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen et al. Zep : A temporal knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
PersonaGym : Evaluating persona agents and LLMs
Vinay Samuel et al. PersonaGym : Evaluating persona agents and LLMs . In Findings of the Association for Computational Linguistics: EMNLP 2025 , 2025. arXiv:2407.18416
-
[12]
Towards Understanding Sycophancy in Language Models
Mrinank Sharma et al. Towards understanding sycophancy in language models. arXiv preprint arXiv:2310.13548, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Olivier Toubia et al. Twin-2K-500 : A dataset for building digital twins of over 2 , 000 people based on their answers to over 500 questions. arXiv preprint arXiv:2505.17479, 2025
-
[14]
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
Pat Verga et al. Replacing judges with juries: Evaluating LLM generations with a panel of diverse models. arXiv preprint arXiv:2404.18796, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu et al. LongMemEval : Benchmarking chat assistants on long-term interactive memory. In International Conference on Learning Representations ( ICLR ) 2025 , 2025. arXiv:2410.10813
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
AlpsBench: An LLM Personalization Benchmark for Real-Dialogue Memorization and Preference Alignment
Jingxuan Xiao et al. AlpsBench : An LLM personalization benchmark for real-dialogue memorization and preference alignment. arXiv preprint arXiv:2603.26680, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng et al. Judging LLM-as-a-judge with MT-Bench and chatbot arena. In Advances in Neural Information Processing Systems ( NeurIPS ) 2023, Datasets and Benchmarks Track , 2023. arXiv:2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.