GrepSeek: Training Search Agents for Direct Corpus Interaction
Pith reviewed 2026-06-29 07:53 UTC · model grok-4.3
The pith
An LLM search agent trained to issue shell commands directly on the raw corpus outperforms retriever-based systems on seven open-domain QA benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
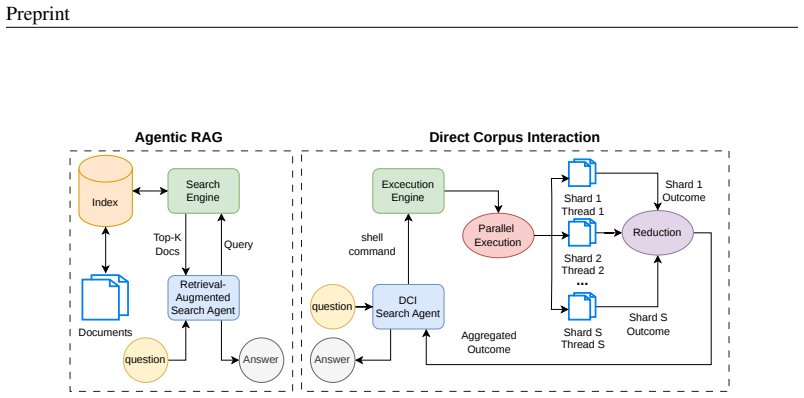
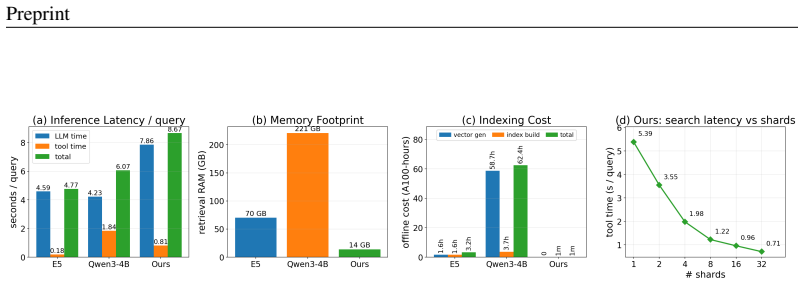
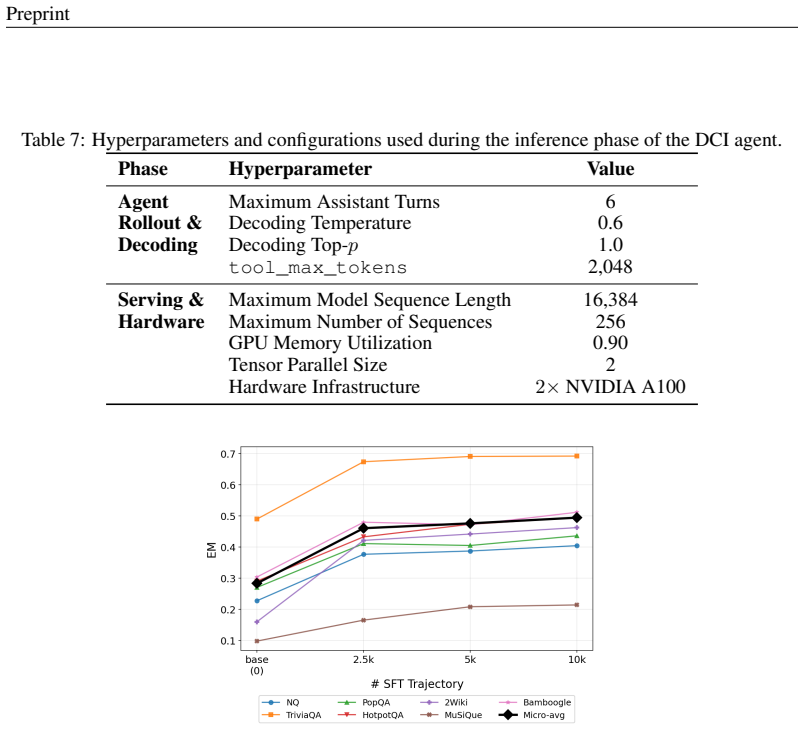
GrepSeek trains a compact policy to find, filter, and compose evidence from large text corpora by issuing executable shell commands. A cold-start dataset is built from verified trajectories produced by an answer-aware Tutor and an answer-blind Planner; the policy is then refined with Group Relative Policy Optimization on the live corpus. A semantics-preserving sharded-parallel execution engine accelerates retrieval up to 7.6 times. Across seven open-domain question-answering benchmarks the resulting agent records the highest overall token-level F1 and Exact Match.
What carries the argument
Two-stage training pipeline that first builds a cold-start dataset via Tutor/Planner trajectory generation and then applies Group Relative Policy Optimization directly on the corpus.
If this is right
- Direct corpus interaction via shell commands can achieve stronger token-level F1 and Exact Match than retriever-based agents on standard open-domain QA tasks.
- The sharded-parallel executor makes byte-exact shell-based search practical at corpus scale by delivering up to 7.6 times speedup.
- Purely lexical commands show clear limits on queries with substantial surface-form variation, indicating that DCI works best when surface matches are reliable.
- DCI supplies a complementary retrieval method that can be combined with existing index-based systems in deployed search agents.
Where Pith is reading between the lines
- The same two-stage recipe could be tested on corpora an order of magnitude larger to check whether the stability benefit persists.
- Replacing the lexical command set with a small set of semantic operators might reduce the surface-form limitation without losing the direct-interaction advantage.
- Because the agent never builds an index, the approach may be especially useful for rapidly changing or permission-restricted document collections.
- The Tutor/Planner cold-start technique might transfer to other agent domains that currently suffer from unstable early reinforcement learning.
Load-bearing premise
The two-stage pipeline of cold-start trajectory collection followed by GRPO refinement is enough to stabilize reinforcement learning on a large raw corpus.
What would settle it
Training the same base model with pure reinforcement learning from scratch on the same corpora and observing whether performance collapses or remains unstable on the seven benchmarks.
Figures










read the original abstract
Large Language Model (LLM) search agents have shown strong promise for knowledge-intensive language tasks through multiple rounds of reasoning and information retrieval. Most existing systems access information using a retriever that takes a keyword or natural language query and returns a ranked list of documents using an index of pre-computed document representations. In this work, we explore a complementary perspective in which the search agent treats the corpus itself as the search environment and finds evidence by issuing executable shell commands. We introduce GrepSeek, an optimized direct corpus interaction (DCI) search agent that trains a compact search agent to find, filter, and compose evidence from large text corpora. To address the instability of learning behavior directly with reinforcement learning on large corpora, we propose a two-stage training pipeline. First, we construct a cold-start dataset using an answer-aware Tutor and answer-blind Planner to generate verified, causally grounded search trajectories. Second, we refine the initialized policy with Group Relative Policy Optimization (GRPO), allowing the agent to improve its task-oriented search behavior through direct interaction with the corpus. To make DCI practical at scale, we further use a semantics-preserving sharded-parallel execution engine that accelerates shell-based retrieval by up to $7.6\times$ while preserving byte-exact equivalence with sequential execution of the shell command. Experiments across seven open-domain question answering benchmarks show that GrepSeek achieves the strongest overall token-level $F_1$ and Exact Match. Our analysis also highlights the limitations of purely lexical interaction on queries with substantial surface-form variation, suggesting DCI as a practical and competitive method for search agents that can complement existing retrieval paradigms in the real world.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GrepSeek, a compact LLM-based search agent that performs direct corpus interaction (DCI) by issuing executable shell commands (e.g., grep) to locate, filter, and compose evidence from large text corpora, rather than relying on pre-indexed retrievers. To stabilize training, it uses a two-stage pipeline: (1) cold-start trajectory generation via an answer-aware Tutor and answer-blind Planner, followed by (2) refinement with Group Relative Policy Optimization (GRPO). A semantics-preserving sharded-parallel execution engine is proposed to accelerate shell-based retrieval by up to 7.6×. Experiments on seven open-domain QA benchmarks are reported to yield the strongest overall token-level F1 and Exact Match.
Significance. If the headline results hold after proper controls, the work supplies a practical alternative paradigm for search agents that can complement retrieval-based systems, especially where byte-exact or lexical precision is valuable. The sharded execution engine is a concrete engineering contribution with measurable speedup while preserving equivalence. The limitation analysis on surface-form variation is a useful caveat. However, the absence of ablations for the core stabilization claim limits attribution of gains to the proposed method.
major comments (1)
- [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): the central claim that GrepSeek achieves the strongest F1/EM rests on the two-stage Tutor/Planner + GRPO pipeline being required to stabilize direct RL on large corpora. No comparison is reported against (a) GRPO initialized from scratch or (b) a single-stage supervised baseline using the same corpus, command vocabulary, and sharded engine. This ablation is load-bearing for the methodological contribution.
minor comments (2)
- [Abstract] Abstract: the performance claim is stated without naming the competing systems, reporting statistical tests, or indicating whether gains are consistent across all seven benchmarks.
- [Method (execution engine)] The description of the sharded execution engine would benefit from an explicit statement of the equivalence invariant (byte-exact output) and any edge cases where sharding could alter command semantics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We agree that the requested ablations are important for strengthening the attribution of gains to the two-stage pipeline and will incorporate them in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): the central claim that GrepSeek achieves the strongest F1/EM rests on the two-stage Tutor/Planner + GRPO pipeline being required to stabilize direct RL on large corpora. No comparison is reported against (a) GRPO initialized from scratch or (b) a single-stage supervised baseline using the same corpus, command vocabulary, and sharded engine. This ablation is load-bearing for the methodological contribution.
Authors: We agree that direct comparisons to GRPO initialized from scratch and to a single-stage supervised baseline (using identical corpus, command vocabulary, and sharded engine) are necessary to substantiate the claim that the two-stage Tutor/Planner + GRPO pipeline is required for stable training. In the revised manuscript we will add these ablations in §4, reporting the resulting F1/EM scores and training dynamics under the same experimental conditions. This will allow readers to assess the contribution of the proposed stabilization method more precisely. revision: yes
Circularity Check
No significant circularity; results on external benchmarks
full rationale
The paper evaluates GrepSeek on seven independent open-domain QA benchmarks using token-level F1 and Exact Match, quantities defined externally rather than by the method. The two-stage pipeline (cold-start via Tutor/Planner then GRPO) is motivated by an assumption about pure RL instability on large corpora, but this assumption is not derived from or equivalent to the reported performance metrics. No self-citations, fitted parameters renamed as predictions, or equations reducing outputs to inputs by construction appear in the abstract or described claims. The sharded execution engine is presented as an engineering optimization preserving byte-exact equivalence, which is independently verifiable.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Optimizing CUDA like a Human: Micro-Profiling Tools as Expert Surrogates for LLM-Based GPU Kernel Optimization
KernelPro combines LLM code generation, roofline-guided tool orchestration, and domain-adapted MCTS to produce GPU kernels that outperform prior automated and some hand-tuned baselines on KernelBench and VeOmni workloads.
Reference graph
Works this paper leans on
-
[1]
Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction
Association for Computational Linguistics. doi: 10.18653/v1/P17-1147. URL https: //aclanthology.org/P17-1147/. 14 Preprint Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 conference on empirical methods i...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/p17-1147 2020
-
[2]
In: Proceedings of the 2018 Conference on Empirical Methods in Natu- ral Language Processing
URLhttps://aclanthology.org/2023.acl-long.557/. Baoyi Wang, Xingliang Wang, Guochang Li, Chen Zhi, Junxiao Han, Xinkui Zhao, Nan Wang, Shuiguang Deng, and Jianwei Yin. Greprag: An empirical study and optimization of grep-like retrieval for code completion, 2026. URLhttps://arxiv.org/abs/2601.23254. Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linju...
-
[3]
born" to quickly locate the specific biographical details. $ rg -F
was a world-renowned scholar and translator of Russian, German and Polish. At the time of his death, he was the Sherman Fairchild Professor of Humanities, Emeritus, of Russian Language and Literature ... answer:(no answer) Why:Exact full-name match pins the right entity; dense similarity conflates two near-identically named people, and the agent loops to ...
1905
-
[4]
Edouard Vaillant et la création de l’unité socialiste en Fr ... [think]The previous searches for
Howorth’s first book, "Edouard Vaillant et la création de l’unité socialiste en Fr ... [think]The previous searches for "Édouard Vaillant" in the corpus did not return a direct biographical entry, but the question implies a specific fact is available. Since the corpus likely contains the answer in a different context or the entry was not captured by the i...
1915
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.