SURGENT: A Surgical Multi-Agent Assistance System Across the Perioperative Workflow
Pith reviewed 2026-06-29 08:12 UTC · model grok-4.3
The pith
SURGENT combines Tree-of-Thought planning, multi-department agents, retrieval, and dual memory to outperform baseline LLMs on five perioperative tasks with outputs more aligned to patient histories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
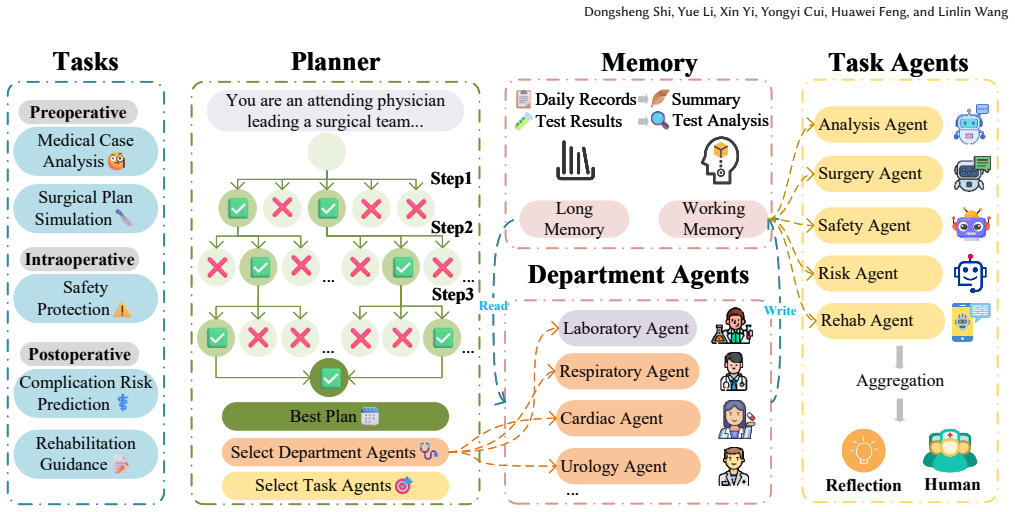
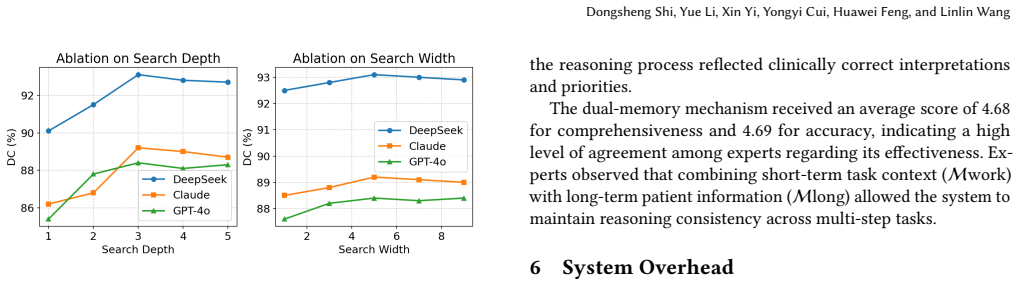
SURGENT integrates a Tree-of-Thought planner, agents from multiple clinical departments, retrieval over guidelines and literature, and a memory design that stores long-term patient histories separately from short-term working summaries. On the five tasks of case analysis, surgical plan simulation, safety monitoring, complication risk assessment, and rehabilitation guidance, this architecture yields recommendations more closely aligned with patient histories than baseline LLMs or prior medical multi-agent systems. The same components support local deployment with DeepSeek, avoiding reliance on external services.
What carries the argument
The novel memory design that separately stores long-term patient histories and short-term working summaries, allowing the system to maintain both complete context and focused current reasoning.
If this is right
- Recommendations on case analysis, plan simulation, safety monitoring, risk assessment, and rehabilitation guidance track patient histories more closely.
- Local deployment with a model such as DeepSeek removes dependence on centralized cloud services.
- Reasoning steps become traceable through the planner, agent exchanges, and retrieved sources.
- Collaboration across departments occurs via the specialized agents without requiring a single monolithic model.
Where Pith is reading between the lines
- The same memory split could be tested in non-surgical settings that also combine long records with immediate decisions, such as chronic disease management.
- Whether the alignment gains reduce actual clinical errors or delays would require outcome-linked trials beyond the current task metrics.
- Hospitals could explore feeding live electronic records directly into the long-term memory to cut manual input time.
Load-bearing premise
The measured gains on the five tasks come from the Tree-of-Thought planner, department agents, retrieval, and memory design rather than from unstated differences in prompting, task selection, or scoring methods.
What would settle it
A controlled re-run of the five tasks that keeps the same prompts, data, and metrics but removes or equalizes the planner, agents, retrieval, and memory components, and finds no advantage for SURGENT, would falsify the claim that those components drive the reported alignment improvement.
Figures

read the original abstract
The intricate nature of modern surgical care necessitates intelligent systems that can synthesize extensive patient records, support collaborative decision-making, and provide transparent, auditable reasoning across the entire perioperative workflow. Although web-based Large Language Models (LLMs) possess advanced reasoning capabilities, they are ill-equipped for surgical applications due to critical limitations: input length constraints, incomplete memory management, and limited traceability. To address this issue, we present SURGENT, a surgical multi-agent assistance system that combines a Tree-of-Thought planner, multi-department collaboration agents, and retrieval-augmented reasoning with clinical guidelines and biomedical literature. SURGENT features a novel memory design that manages both long-term patient histories and short-term working summaries, enabling more complete, contextualized, and consistent reasoning. Experimental evaluations across five key perioperative tasks - case analysis, surgical plan simulation, safety monitoring, complication risk assessment, and rehabilitation guidance - show that SURGENT outperforms baseline LLMs and existing medical multi-agent frameworks, yielding recommendations more closely aligned with patient histories. Ablation studies further highlight the advantage of DeepSeek as a locally deployable backbone model, enabling privacy-preserving deployment without reliance on centralized services. These results position SURGENT as a practical and trustworthy advancement toward intelligent, equitable, and secure surgical assistance systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SURGENT, a multi-agent LLM system for perioperative surgical assistance. It combines a Tree-of-Thought planner, multi-department collaboration agents, retrieval-augmented reasoning over clinical guidelines and biomedical literature, and a novel memory architecture managing long-term patient histories alongside short-term working summaries. The central claim is that the system outperforms baseline LLMs and prior medical multi-agent frameworks across five tasks (case analysis, surgical plan simulation, safety monitoring, complication risk assessment, and rehabilitation guidance), producing recommendations more closely aligned with patient histories; ablation studies are cited to support DeepSeek as a locally deployable backbone enabling privacy-preserving use.
Significance. If supported by properly reported quantitative results, the work could contribute to practical multi-agent systems for high-stakes clinical workflows by tackling LLM limitations in context length, memory consistency, and traceability. The emphasis on local deployment and collaborative agents across surgical departments addresses real deployment constraints in medicine. The current text, however, supplies no metrics or protocols, so significance cannot yet be assessed.
major comments (2)
- [Abstract] Abstract: the assertion that 'SURGENT outperforms baseline LLMs and existing medical multi-agent frameworks' is presented without any numerical results, datasets, statistical tests, or evaluation protocols, so the headline experimental claim cannot be evaluated.
- [Experimental evaluations section] Experimental evaluations section: no details are supplied on patient cohort size or selection, the metric used to quantify 'more closely aligned with patient histories,' baseline prompting strategies, or inter-rater/blinding procedures; therefore it is impossible to attribute any observed gains to the Tree-of-Thought planner, multi-department agents, retrieval component, or novel memory design rather than unstated differences in prompting or case choice.
minor comments (1)
- [Abstract] Abstract: the phrase 'yielding recommendations more closely aligned with patient histories' is imprecise without naming the alignment metric or measurement method.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive feedback on the reporting of our experimental claims and protocols. We agree that greater transparency is needed and will revise the manuscript to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'SURGENT outperforms baseline LLMs and existing medical multi-agent frameworks' is presented without any numerical results, datasets, statistical tests, or evaluation protocols, so the headline experimental claim cannot be evaluated.
Authors: We agree the abstract claim requires supporting quantitative evidence for proper evaluation. In revision we will add concise numerical highlights (e.g., task-specific accuracy or alignment improvements) drawn from the experimental results, while preserving brevity; full datasets, metrics, and protocols will remain detailed in the body. revision: yes
-
Referee: [Experimental evaluations section] Experimental evaluations section: no details are supplied on patient cohort size or selection, the metric used to quantify 'more closely aligned with patient histories,' baseline prompting strategies, or inter-rater/blinding procedures; therefore it is impossible to attribute any observed gains to the Tree-of-Thought planner, multi-department agents, retrieval component, or novel memory design rather than unstated differences in prompting or case choice.
Authors: The referee correctly notes that additional methodological specifics are required. We will expand the experimental evaluations section to report patient cohort size and selection criteria, the precise metric(s) for history alignment, baseline prompting details, and evaluation procedures including inter-rater reliability and blinding. These additions will enable clearer attribution of gains to the individual system components. revision: yes
Circularity Check
No circularity in derivation chain; empirical system paper with no reductions to self-defined inputs
full rationale
The paper describes a multi-agent surgical assistance system and reports experimental outperformance on five perioperative tasks. No equations, derivations, fitted parameters, or predictions appear in the provided text. The central claim rests on empirical comparisons rather than any self-definitional, fitted-input, or self-citation reduction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in a way that collapses the result to its own inputs by construction. This matches the default case of a non-circular empirical systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Lisa Adams, Felix Busch, Tianyu Han, Jean-Baptiste Excoffier, Matthieu Ortala, Alexander Löser, Hugo JWL Aerts, Jakob Nikolas Kather, Daniel Truhn, and Keno Bressem. 2025. Longhealth: A question answering benchmark with long clinical documents. Journal of Healthcare Informatics Research (2025), 1–17
2025
- [3]
-
[4]
Anthropic. 2024. Introducing the next generation of Claude . https://www. anthropic.com/news/claude-3-family
2024
-
[5]
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural ma- chine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[6]
Kiruthika Balakrishnan, Durgadevi Velusamy, Hana E Hinkle, Zhi Li, Karthikeyan Ramasamy, Hikmat Khan, Srini Ramaswamy, and Pir Masoom Shah. 2025. Arti- ficial Intelligence in Rural Healthcare Delivery: Bridging Gaps and Enhancing Equity through Innovation. arXiv preprint arXiv:2508.11738 (2025)
-
[7]
Ma Chang, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. 2024. Agentboard: An analyti- cal evaluation board of multi-turn llm agents. Advances in neural information processing systems 37 (2024), 74325–74362
2024
-
[8]
Justin Chen, Swarnadeep Saha, and Mohit Bansal. 2024. ReConcile: Round- Table Conference Improves Reasoning via Consensus among Diverse LLMs. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) . 7066–7085
2024
-
[9]
Tobias Czempiel, Magdalini Paschali, Matthias Keicher, Walter Simson, Hubertus Feussner, Seong Tae Kim, and Nassir Navab. 2020. Tecno: Surgical phase recog- nition with multi-stage temporal convolutional networks. In International con- ference on medical image computing and computer-assisted intervention . Springer, 343–352
2020
-
[10]
Fabio Dennstädt, Janna Hastings, Paul Martin Putora, Max Schmerder, and Nikola Cihoric. 2025. Implementing large language models in healthcare while balancing control, collaboration, costs and security. NPJ digital medicine 8, 1 (2025), 143
2025
-
[11]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch
-
[12]
In Forty-first International Conference on Machine Learning
Improving factuality and reasoning in language models through multiagent debate. In Forty-first International Conference on Machine Learning
-
[13]
Andreas Frodl, Andreas Fuchs, Tayfun Yilmaz, Kaywan Izadpanah, Hagen Schmal, and Markus Siegel. 2024. ChatGPT as a Source for Patient Information on Patellofemoral Surgery—A Comparative Study Amongst Laymen, Doctors, and Experts. Clinics and Practice 14, 6 (2024), 2376–2384
2024
-
[14]
Xiaojie Gao, Yueming Jin, Yonghao Long, Qi Dou, and Pheng-Ann Heng. 2021. Trans-svnet: Accurate phase recognition from surgical videos via hybrid em- bedding aggregation transformer. In International conference on medical image computing and computer-assisted intervention . Springer, 593–603
2021
-
[15]
Omid Kohandel Gargari and Gholamreza Habibi. 2025. Enhancing medical AI with retrieval-augmented generation: A mini narrative review. Digital health 11 (2025), 20552076251337177
2025
-
[16]
Jonathan Gruber, Mengyun Lin, Hanmo Yang, and Junjian Yi. 2025. China’s social health insurance in the era of rapid population aging. In JAMA Health Forum, Vol. 6. American Medical Association, e251105–e251105
2025
-
[17]
Lakshitha Gunasekara, Nicole El-Haber, Swati Nagpal, Harsha Moraliyage, Za- far Issadeen, Milos Manic, and Daswin De Silva. 2025. A Systematic Review of Responsible Artificial Intelligence Principles and Practice. Applied System Innovation 8, 4 (2025), 97
2025
-
[18]
Ahmad Guni, Piyush Varma, Joe Zhang, Matyas Fehervari, and Hutan Ashrafian
-
[19]
European Surgical Research 65, 1 (2024), 22–39
Artificial intelligence in surgery: the future is now. European Surgical Research 65, 1 (2024), 22–39
2024
-
[20]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Mohammad Junayed Hasan, Suhra Noor, and Mohammad Ashrafuzzaman Khan
-
[22]
arXiv preprint arXiv:2311.01571 (2023)
Preserving the knowledge of long clinical texts using aggregated ensembles of large language models. arXiv preprint arXiv:2311.01571 (2023)
-
[23]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al
-
[24]
International Conference on Learning Representations, ICLR
MetaGPT: Meta programming for a multi-agent collaborative framework. International Conference on Learning Representations, ICLR
-
[25]
Peyman Hosseini, Ignacio Castro, Iacopo Ghinassi, and Matthew Purver. 2024. Efficient solutions for an intriguing failure of llms: Long context window does not mean llms can analyze long sequences flawlessly.arXiv preprint arXiv:2408.01866 (2024). Dongsheng Shi, Yue Li, Xin Yi, Yongyi Cui, Huawei Feng, and Linlin Wang
-
[26]
Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik S Chan, Xuhai Xu, Daniel Mc- Duff, Hyeonhoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae W Park
-
[27]
Advances in Neural Information Processing Systems 37 (2024), 79410–79452
Mdagents: An adaptive collaboration of llms for medical decision-making. Advances in Neural Information Processing Systems 37 (2024), 79410–79452
2024
-
[28]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33 (2020), 9459–9474
2020
-
[29]
Lele Li, Tiantian Du, and Yanping Hu. 2020. The effect of population aging on healthcare expenditure from a healthcare demand perspective among different age groups: Evidence from Beijing City in the People’s Republic of China.Risk Management and Healthcare Policy (2020), 1403–1412
2020
-
[30]
Yue Li, Xin Yi, Dongsheng Shi, Gerard De Melo, Xiaoling Wang, and Linlin Wang
-
[31]
In Findings of the Association for Computational Linguistics: ACL 2025
Hierarchical safety realignment: Lightweight restoration of safety in pruned large vision-language models. In Findings of the Association for Computational Linguistics: ACL 2025. 7600–7612
2025
-
[32]
Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie-Yan Liu. 2022. BioGPT: generative pre-trained transformer for biomedical text generation and mining. Briefings in bioinformatics 23, 6 (2022), bbac409
2022
-
[33]
Ismael Martinez-Nicolas, Daniel Arnal-Velasco, Eva Romero-García, Neus Fabre- gas, Yolanda Sanduende Otero, Irene Leon, Ashish A Bartakke, Javier Silva-Garcia, Anna Rodriguez, Claudia Valli, et al. 2024. Perioperative patient safety recom- mendations: systematic review of clinical practice guidelines.BJS open 8, 6 (2024), zrae143
2024
-
[34]
Arnaud Romeo Mbadjeu Hondjeu, Zi Ying Zhao, Luka Newton, Anass Ajenkar, Emily Hladkowicz, Karim Ladha, Duminda N Wijeysundera, and Daniel I McIsaac
-
[35]
Canadian Journal of Anesthesia/Journal canadien d’anesthésie(2025), 1–15
Large language models in perioperative medicine—applications and future prospects: a narrative review: AR Mbadjeu Hondjeu et al. Canadian Journal of Anesthesia/Journal canadien d’anesthésie(2025), 1–15
2025
-
[36]
Microsoft. 2024. Responsible AI Principles and Approach. https://www.microsoft. com/en/ai/principles-and-approach
2024
-
[37]
Harsha Nori, Yin Tat Lee, Sheng Zhang, Dean Carignan, Richard Edgar, Nicolo Fusi, Nicholas King, Jonathan Larson, Yuanzhi Li, Weishung Liu, et al. 2023. Can generalist foundation models outcompete special-purpose tuning? case study in medicine. arXiv preprint arXiv:2311.16452 (2023)
-
[38]
Chin Siang Ong, Nicholas T Obey, Yanan Zheng, Arman Cohan, and Eric B Schneider. 2024. SurgeryLLM: a retrieval-augmented generation large language model framework for surgical decision support and workflow enhancement. npj Digital Medicine 7, 1 (2024), 364
2024
-
[39]
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems. arXiv preprint arXiv:2310.08560 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Jodyn Platt, Paige Nong, Renée Smiddy, Reema Hamasha, Gloria Carmona Clavijo, Joshua Richardson, and Sharon LR Kardia. 2024. Public comfort with the use of ChatGPT and expectations for healthcare. Journal of the American Medical Informatics Association 31, 9 (2024), 1976–1982
2024
-
[41]
Lars Riedemann, Maxime Labonne, and Stephen Gilbert. 2024. The path forward for large language models in medicine is open. npj Digital Medicine 7, 1 (2024), 339
2024
-
[42]
Ahmad Y Sheikh and James I Fann. 2019. Artificial intelligence: can information be transformed into intelligence in surgical education? Thoracic surgery clinics 29, 3 (2019), 339–350
2019
-
[43]
Dongsheng Shi, Xin Yi, Yue Li, and Linlin Wang. 2026. Benchmarking Large Lan- guage Models for End-to-End Clinical Support in Traditional Chinese Medicine. Expert Systems with Applications (2026), 132267
2026
-
[44]
Significant-Gravitas. 2023. AutoGPT: Build, Deploy, and Run AI Agents. https: //github.com/Significant-Gravitas/AutoGPT. GitHub repository
2023
-
[45]
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al . 2025. Toward expert-level medical question answering with large language models. Nature Medicine 31, 3 (2025), 943–950
2025
-
[46]
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. Advances in neural information processing systems 27 (2014)
2014
-
[47]
Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, and Mark Gerstein. 2024. MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning. In Findings of the Association for Computational Linguistics ACL 2024 . 599–621
2024
-
[48]
XAgent Team. 2023. XAgent: An Autonomous Agent for Complex Task Solving
2023
-
[49]
Andru P Twinanda, Didier Mutter, Jacques Marescaux, Michel de Mathelin, and Nicolas Padoy. 2016. Single-and multi-task architectures for surgical workflow challenge at M2CAI 2016. arXiv preprint arXiv:1610.08844 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[50]
Leyao Wang, Zhiyu Wan, Congning Ni, Qingyuan Song, Yang Li, Ellen Clayton, Bradley Malin, and Zhijun Yin. 2024. Applications and concerns of ChatGPT and other conversational large language models in health care: systematic review. Journal of Medical Internet Research 26 (2024), e22769
2024
-
[51]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[52]
Yueyue Wang, Yuyang Li, Shangren Qin, Yuanfeng Kong, Xiyang Yu, Keqiang Guo, and Jiayu Meng. 2020. The disequilibrium in the distribution of the primary health workforce among eight economic regions and between rural and urban areas in China. International Journal for equity in health 19, 1 (2020), 28
2020
-
[53]
Zixiang Wang, Yinghao Zhu, Huiya Zhao, Xiaochen Zheng, Dehao Sui, Tian- long Wang, Wen Tang, Yasha Wang, Ewen Harrison, Chengwei Pan, et al. 2025. Colacare: Enhancing electronic health record modeling through large language model-driven multi-agent collaboration. In Proceedings of the ACM on Web Con- ference 2025. 2250–2261
2025
-
[54]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models. Advances in neural information processing systems 35 (2022), 24824–24837
2022
-
[55]
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. 2023. C-Pack: Packaged Resources To Advance General Chinese Embedding. arXiv:2309.07597 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [56]
-
[57]
Rui Yang, Yilin Ning, Emilia Keppo, Mingxuan Liu, Chuan Hong, Danielle S Bitterman, Jasmine Chiat Ling Ong, Daniel Shu Wei Ting, and Nan Liu. 2025. Retrieval-augmented generation for generative artificial intelligence in health care. npj Health Systems 2, 1 (2025), 2
2025
-
[58]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems 36 (2023), 11809–11822
2023
-
[59]
Xin Yi, Yue Li, Dongsheng Shi, Linlin Wang, Xiaoling Wang, and Liang He. 2025. Latent-space adversarial training with post-aware calibration for defending large language models against jailbreak attacks. Expert Systems with Applications (2025), 129101
2025
- [60]
-
[61]
Xuexin Yu, Wei Zhang, and Jersey Liang. 2021. Physician distribution across China’s cities: regional variations. International Journal for Equity in Health 20, 1 (2021), 162
2021
-
[62]
A Zambouri. 2007. Preoperative evaluation and preparation for anesthesia and surgery. Hippokratia 11, 1 (2007), 13
2007
-
[63]
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. 2025. A survey on the memory mechanism of large language model-based agents. ACM Transactions on Information Systems 43, 6 (2025), 1–47
2025
-
[64]
Yanli Zheng, Fuhai Han, Shuyu Li, and Wenxing Su. 2024. Current Applications and Future Prospects of Large AI Models in the Medical Field. Journal of Medical Informatics 45, 6 (2024), 24–29. A Scoring Criteria for Expert Evaluation To ensure a consistent and interpretable assessment of the proposed surgical multi-agent collaboration framework, experts eva...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.